- The paper introduces a compiler-based framework that abstracts GPU parallelism patterns to efficiently blend compression and decompression.
- It employs hardware-adaptive scheduling and kernel fusion, achieving up to 2.45× latency reduction and significant throughput improvements.
- Optimizations yield an average 2.07× speedup in data transfer and enhanced compression ratios, advancing performance in GPU-accelerated analytics.
ZipFlow: A Compiler-Based Framework for Optimized Compressed Data Movement on Modern GPUs
Motivation and Problem Statement
The proliferation of GPU-accelerated analytics has intensified the demand for efficient large-scale data transfer from CPU to GPU memory, hampered by bandwidth limitations of PCIe, especially as dataset sizes routinely exceed GPU memory capacity. While contemporary database systems already leverage compression to reduce movement cost, most existing frameworks are designed for CPU execution and impose restrictions on algorithm selection and composition, failing to fully exploit the computational and parallelism capabilities of GPUs. Furthermore, prior GPU compression libraries (e.g., nvCOMP) only provide limited algorithm extensibility and lack hardware-adaptive scheduling, resulting in suboptimal end-to-end performance.
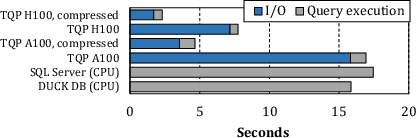
Figure 1: Latency breakdown of 22 TPC-H queries (SF=100) on CPU and two GPU platforms, highlighting PCIe transfer as the dominant bottleneck.
ZipFlow Framework Architecture and Execution Pipeline
ZipFlow introduces a compiler-based modular framework to optimize compressed data movement. The data pipeline comprises four layers: Pattern, Algorithm, Nesting, and Pipelining. The Pattern Layer abstracts (de)compression primitives into three parallel schemas—Fully-Parallel, Group-Parallel, and Non-Parallel—facilitating flexible GPU scheduling. The Algorithm Layer implements native compression operators, while the Nesting Layer composes and optimizes algorithm stacks tailored to column characteristics. The Pipelining Layer coordinates the overlap of PCIe transfers and decompression tasks, determined via scheduling algorithms (e.g., Johnson's algorithm), maximizing concurrency and minimizing latency.
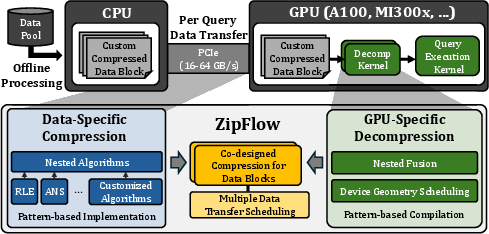
Figure 2: Overview of the ZipFlow end-to-end execution pipeline for efficient compressed data movement.
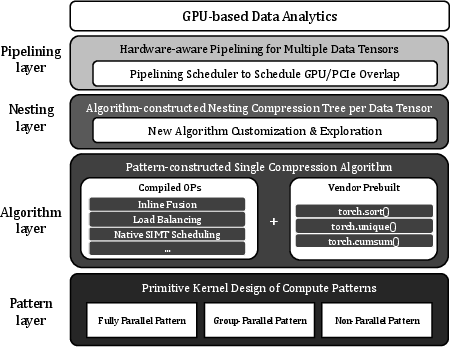
Figure 3: ZipFlow architecture, illustrating system layering from parallel patterns to pipelining.
Parallelism Patterns: Kernel Scheduling and Optimization
ZipFlow formalizes three native parallelism structures:
- Fully-Parallel: Each input maps independently to output (e.g., bit-packing, dictionary encoding). Kernel fusion and vectorized thread assignment maximize throughput.
- Group-Parallel: Tasks split into variable-sized groups for intra-group parallelism (e.g., RLE, delta-encoded groups). Load balancing is achieved through coordinated block scheduling.
- Non-Parallel: Serial algorithms (e.g., LZ4, ANS, Huffman) are parallelized at chunk-level, leveraging SIMT execution.
Kernel configurations are parameterized as <L,S,C>, aligning workloads with native GPU hardware features (compute units, warp sizes, cache). ZipFlow provides device-specific kernel tuning to maximize efficiency across heterogeneous GPUs.
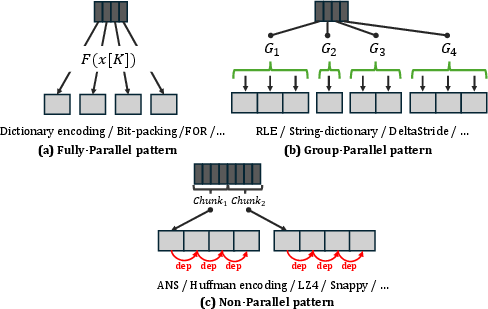
Figure 4: Logical dependencies for ZipFlow’s three parallel patterns.
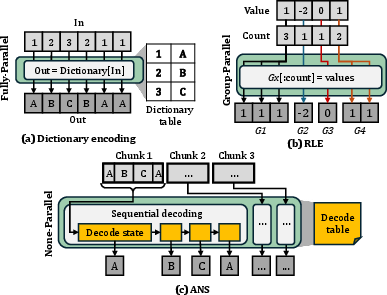
Figure 5: Examples of data mapping for each parallelism pattern.
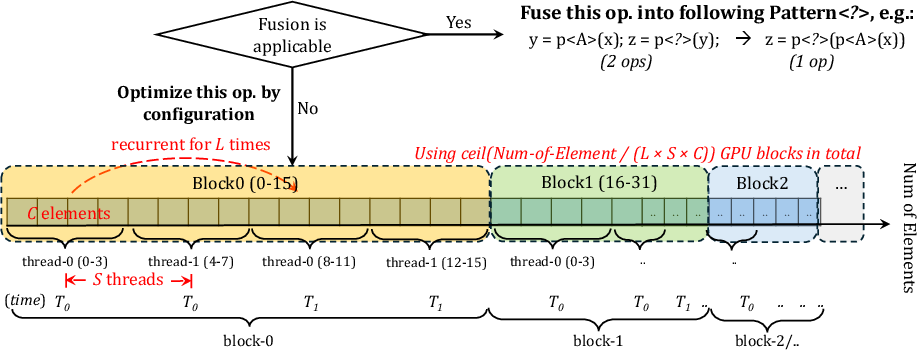
Figure 6: Fully-Parallel scheduling with ⟨L,S,C⟩=⟨2,2,4⟩ illustrating intra-block parallelism.
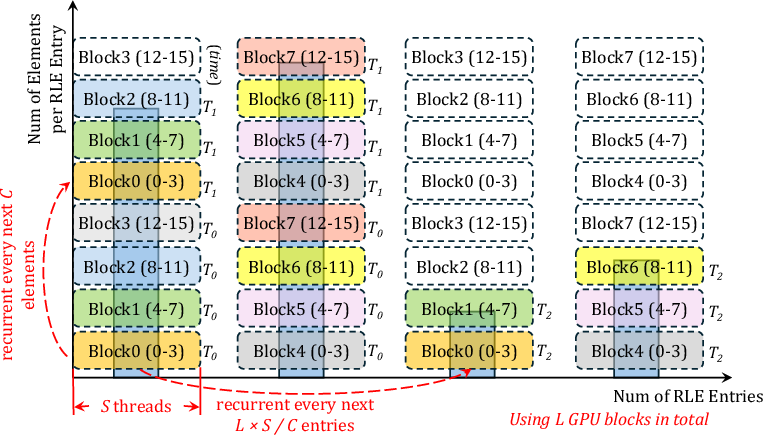
Figure 7: Group-Parallel scheduling with ⟨L,S,C⟩=⟨8,4,16⟩ for efficient load distribution.
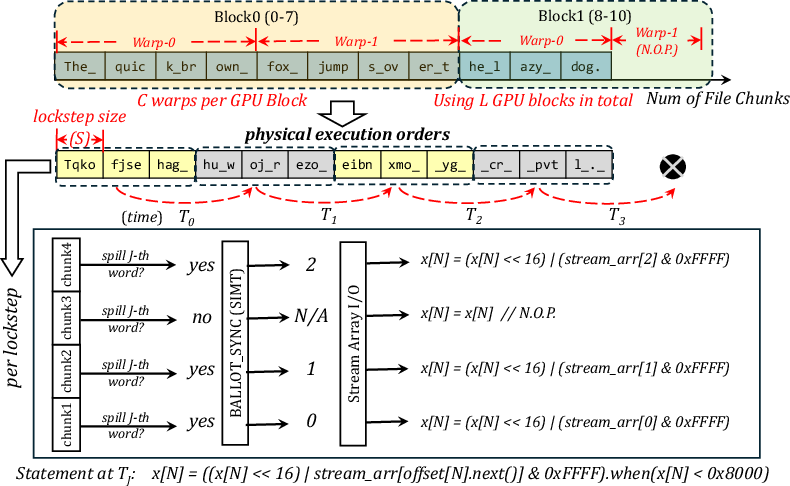
Figure 8: Non-Parallel scheduling with ⟨L,S,C⟩=⟨2,4,2⟩ for chunk-level parallelization.
Compression Algorithm Extensibility and Nesting
ZipFlow’s extensible pool accommodates a diverse set of primitives (bit-packing, delta, dictionary encoding, ANS, Float2Int, String-dictionary) and enables custom nesting to exploit data traits and compression ratio potential. Multi-layered nesting is realized as sequential kernel pipelines, allowing fusion where possible to minimize redundant memory movement.
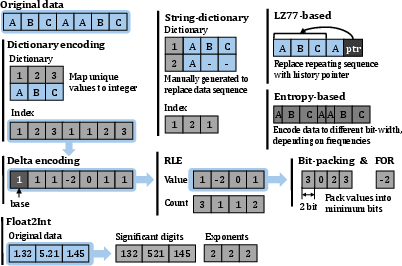
Figure 9: Compression algorithms of different families categorized by parallelism pattern.
Benchmarking across TPC-H columns and synthetic distributions demonstrates ZipFlow’s superior decompression throughput and adaptability versus nvCOMP:
- Bit-packing: ZipFlow achieves up to 1.63× decompression improvement for high bit-width compression.
- RLE: ZipFlow maintains throughput near theoretical maximum—nvCOMP’s fixed-thread scheduling underutilizes bandwidth.
- ANS: ZipFlow outperforms nvCOMP across skew distribution and chunk size sweeps, consistently attaining optimal trade-offs between throughput and compression ratio.
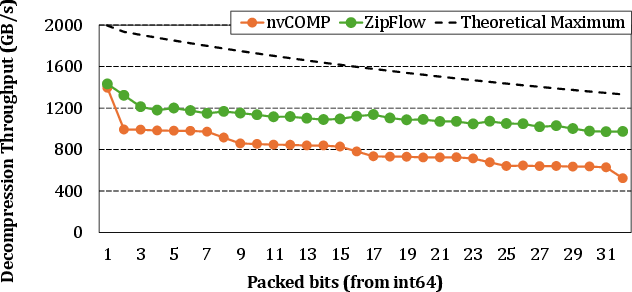
Figure 10: Bit-packing (Fully-Parallel) throughput under varying bit-width distributions.
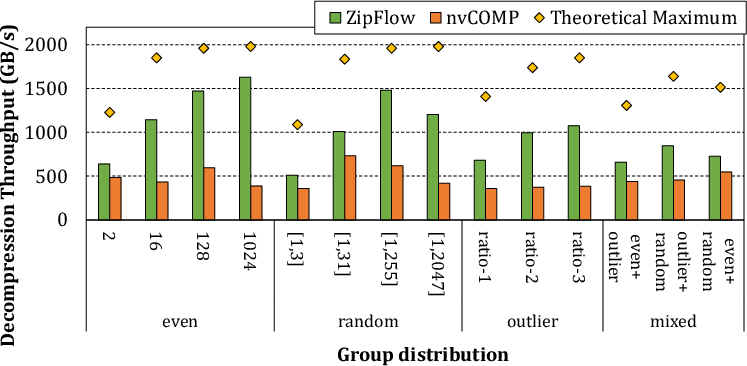
Figure 11: RLE (Group-Parallel) throughput across varied group size distributions.
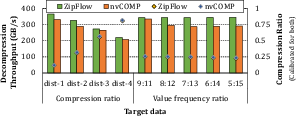
Figure 12: ANS (Non-Parallel) throughput versus compression ratio and value frequency distributions.
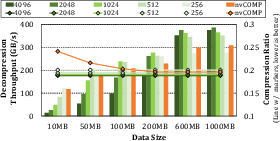
Figure 13: ANS throughput for different chunk sizes, highlighting ZipFlow’s superior scalability.
Compression Ratio and Decompression Throughput: TPC-H Evaluation
ZipFlow achieves superior compression ratios across all tested columns, owing to flexible nesting:
- Date columns: Dictionary encoding yields substantially higher ratios versus nvCOMP (lacking support).
- Numeric columns: Float2Int nesting with bit-packing surmounts alternative methods.
- Primary keys: DeltaStride + bit-packing provides optimal encoding for incremental sequences.
- String columns: Custom String-dictionary with bit-packing and ANS outperforms zstd and FSST.
Decompression throughput mirrors these gains, with ZipFlow delivering an average 2.07× speedup in file-level data movement, and up to 21% compression ratio improvement.
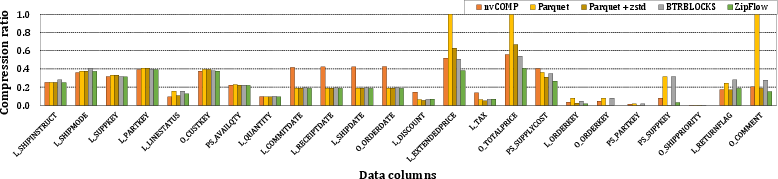
Figure 14: Compression ratio comparison between ZipFlow and four baselines, showcasing extensible nesting strategies.
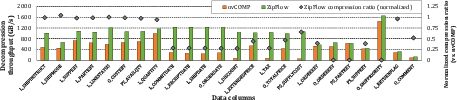
Figure 15: Decompression throughput comparison between nvCOMP and ZipFlow, with normalized compression ratios.
Kernel Fusion: Memory Access Optimization
Fusing consecutive kernels achieves up to 2.45× latency reduction (dictionary encoding + bit-packing), minimizing unnecessary memory round trips and streamlining decompression for high-throughput patterns.
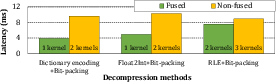
Figure 16: Performance benefits from kernel fusion on nested decompression kernels.
Across all TPC-H queries, ZipFlow consistently reduces PCIe transfer and decompression latency:
- Average speedup: 2.08× versus nvCOMP, 3.14× versus DuckDB, and 3.32× versus SQL Server.
- PCIe I/O: 1.85× improvement compared to nvCOMP, primarily for columns with custom compression.
- Pipelining: Further 10% latency reduction via overlap of transfer and decompression.
- Column-wise optimization: Outlier columns unsupported by the baseline libraries remain as residual bottlenecks, highlighting the importance of extensible algorithm pools.

Figure 17: TPC-H query latency across CPU and GPU baselines.

Figure 18: Detailed breakdown of TPC-H query latency by execution phase.
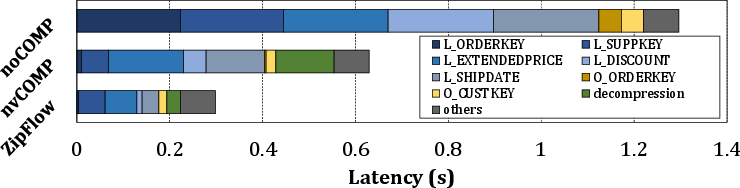
Figure 19: TPC-H query 7 latency breakdown by column, isolating compression bottlenecks.
Hardware-Adaptive Scheduling: Heterogeneous GPU Evaluation
ZipFlow’s device geometry scheduling enables architecture-specific kernel tuning. Native configurations realize maximal decompression efficiency, while porting kernels between devices can result in up to 35% efficiency loss, reinforcing the necessity for targeted offline tuning via reinforcement learning with minimal candidate exploration overhead.
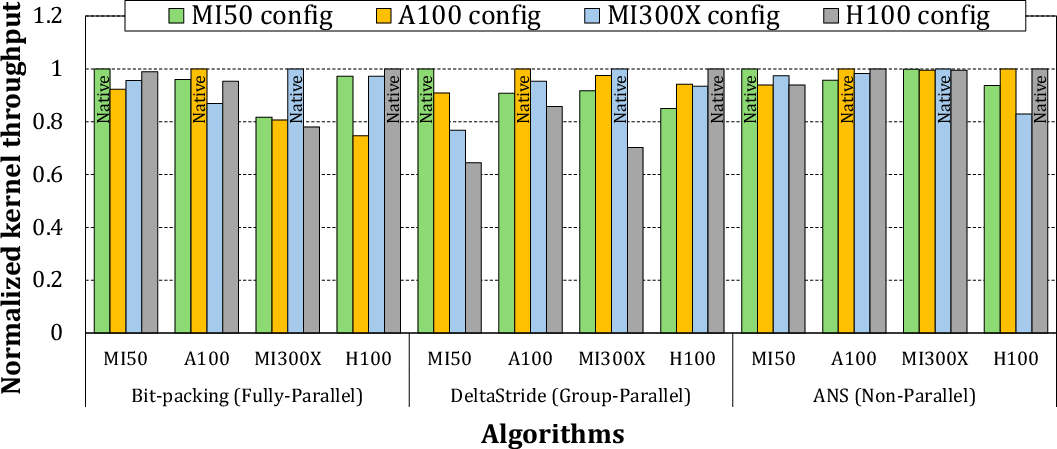
Figure 20: Kernel efficiencies on four GPU types, contrasting Native and Shared configurations.
Practical and Theoretical Implications
ZipFlow’s framework advances both practical GPU-accelerated analytics and theoretical research in data movement optimization by offering:
- Algorithm extensibility: Rapid integration of custom primitives and nested patterns for diverse data types.
- Hardware-aware scheduling: Efficient kernel mapping and fusion, directly exploiting architectural strengths and mitigating device heterogeneity.
- Holistic optimization: Joint consideration of compression ratio, decompression throughput, and transfer schedules enables maximal end-to-end performance.
- Future directions: Work may explore further nesting of heavyweight algorithms, adaptive pipelining for NVLink/cloud-distributed architectures, and automated compression strategy discovery via reinforcement meta-learning.
Conclusion
ZipFlow constitutes a comprehensive compiler-based infrastructure for optimizing compressed data movement and decompression on modern heterogeneous GPUs. Through systematic abstraction of parallelism patterns, extensible algorithm nesting, device geometry scheduling, and pipelined transfer orchestration, ZipFlow significantly outperforms existing GPU compression libraries in both compression ratio and end-to-end throughput. The demonstrated flexibility and efficiency position ZipFlow as a foundational framework for next-generation high-performance GPU analytics.

