- The paper demonstrates a novel geometric framework where data-dependent log-density ridge manifolds guide diffusion model generalization and prevent memorization.
- It introduces a three-stage reach–align–slide taxonomy that systematically decouples normal and tangential error components during inference.
- Empirical results on synthetic and latent MNIST data validate explicit error bounds and showcase architecture-dependent generative interpolation.
Diffusion Model Generalization via Inductive Bias Toward Data-Dependent Ridge Manifold
Overview
"Diffusion Model's Generalization Can Be Characterized by Inductive Biases toward a Data-Dependent Ridge Manifold" (2602.06021) provides a rigorous, geometric framework for understanding generalization in diffusion models. The authors introduce the concept of a log-density ridge manifold, constructed explicitly from empirical data, to characterize where non-memorizing diffusion models generate samples. This geometric perspective quantifies the inductive bias, connecting inference dynamics, model architecture, and training procedures to the regions and modes where a diffusion model “innovates” beyond simply copying its training data.
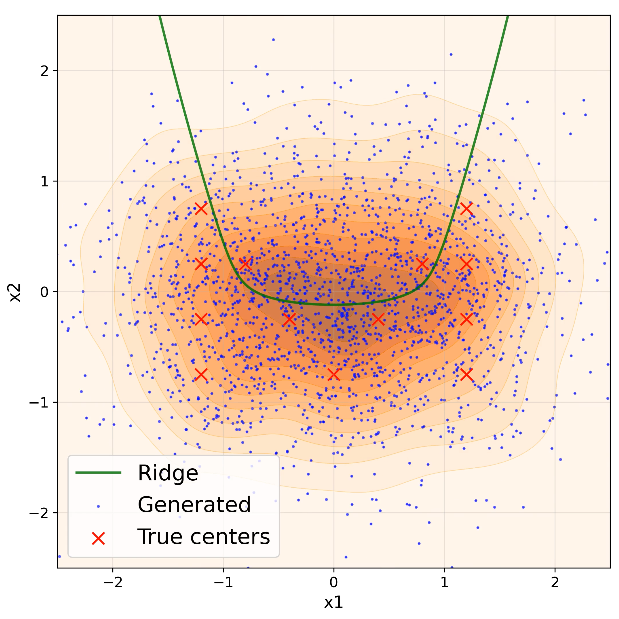
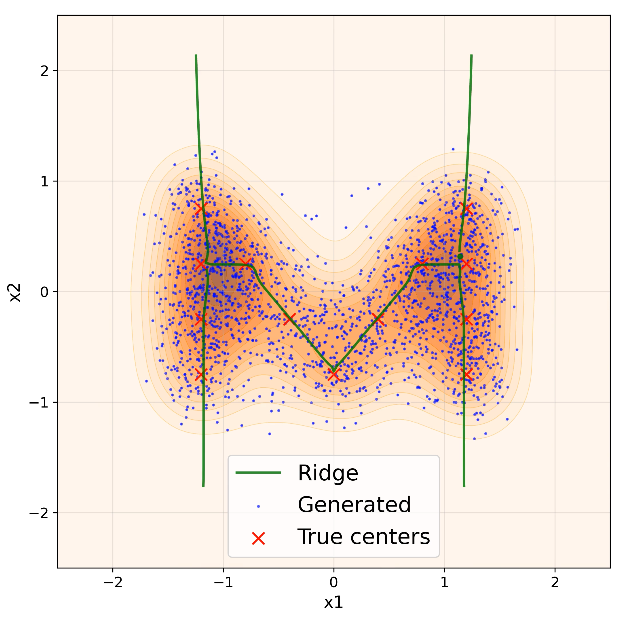

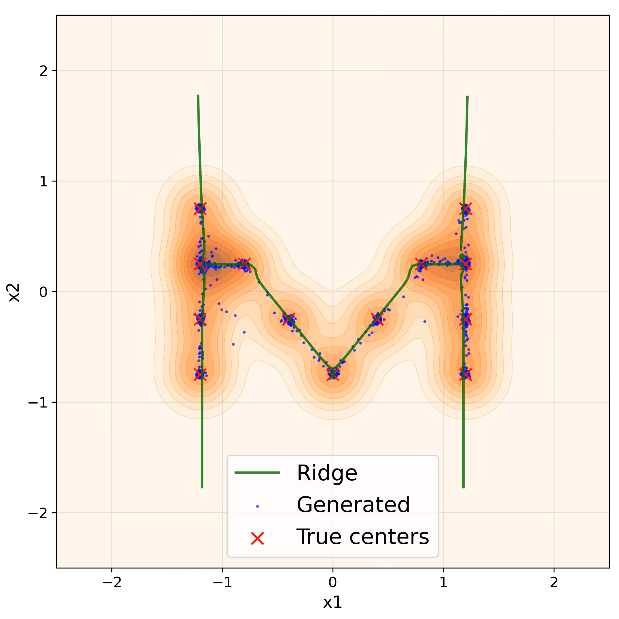
Figure 1: Generated samples (blue) evolve toward the time-indexed log-density ridge (green), formed by 13 training points (red) in 2D, illustrating the reach–align–slide process.
Theoretical Framework
The paper develops a three-stage “reach–align–slide” taxonomy for the generative dynamics of diffusion models during inference:
- Reach: Generated samples rapidly approach a neighborhood (tube) surrounding the log-density ridge manifold defined by the smoothed empirical distribution.
- Normal Alignment: Samples contract toward the ridge’s normal directions, aligning but not perfectly converging. The residual distance is dictated by the normal components of training error.
- Tangent Sliding: Samples then slide along the ridge’s tangent directions, potentially populating structured regions between training modes. The spread along the ridge is governed by tangent components of training error.
This mechanism is formalized via stochastic differential equations characterizing the reverse-time sampling process, and explicit bounds are derived for both normal and tangent components of the error using empirical ridge geometry and training loss decomposition.
Log-Density Ridge Manifold
The ridge manifold Rt at noise level t is defined as the set of points where the projected gradient of log-density vanishes in the normal directions, and local curvature in those directions falls below a threshold determined by the noise schedule. This construction is fully data-dependent, and its regularity properties (reach, projection mapping, curvature) are proved under assumptions of well-separated empirical data.
Connection to Training Dynamics
The theoretical bounds link inference error to directional decompositions of the posterior mean matching loss (or denoising score matching loss), yielding normal and tangent components L⊥(A) and L∥(A). Using random feature neural network (RFNN) architectures trained by gradient descent, the authors show architecture and optimization-induced errors both map linearly onto normal/tangent directions, yielding explicit formulas for prediction of generative concentration and spread.
For fixed training weights w(t), the error accumulates differently in each direction, with normal contraction governed by ridge curvature thresholds and tangential contraction by stochastic dynamics. Crucially, low normal error induces sharp ridge alignment, while persistent tangent error causes interpolation (generalization) along the ridge manifold.
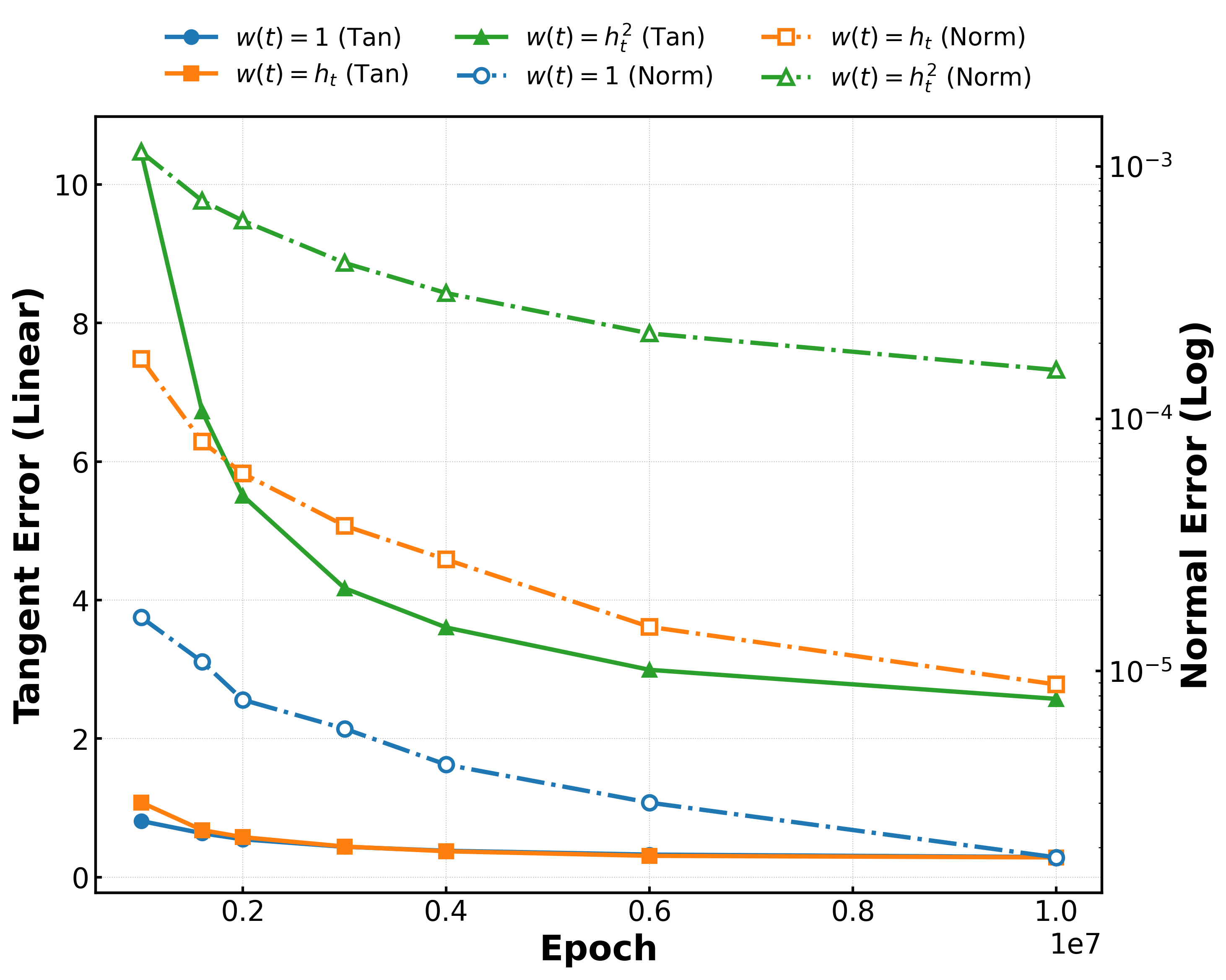
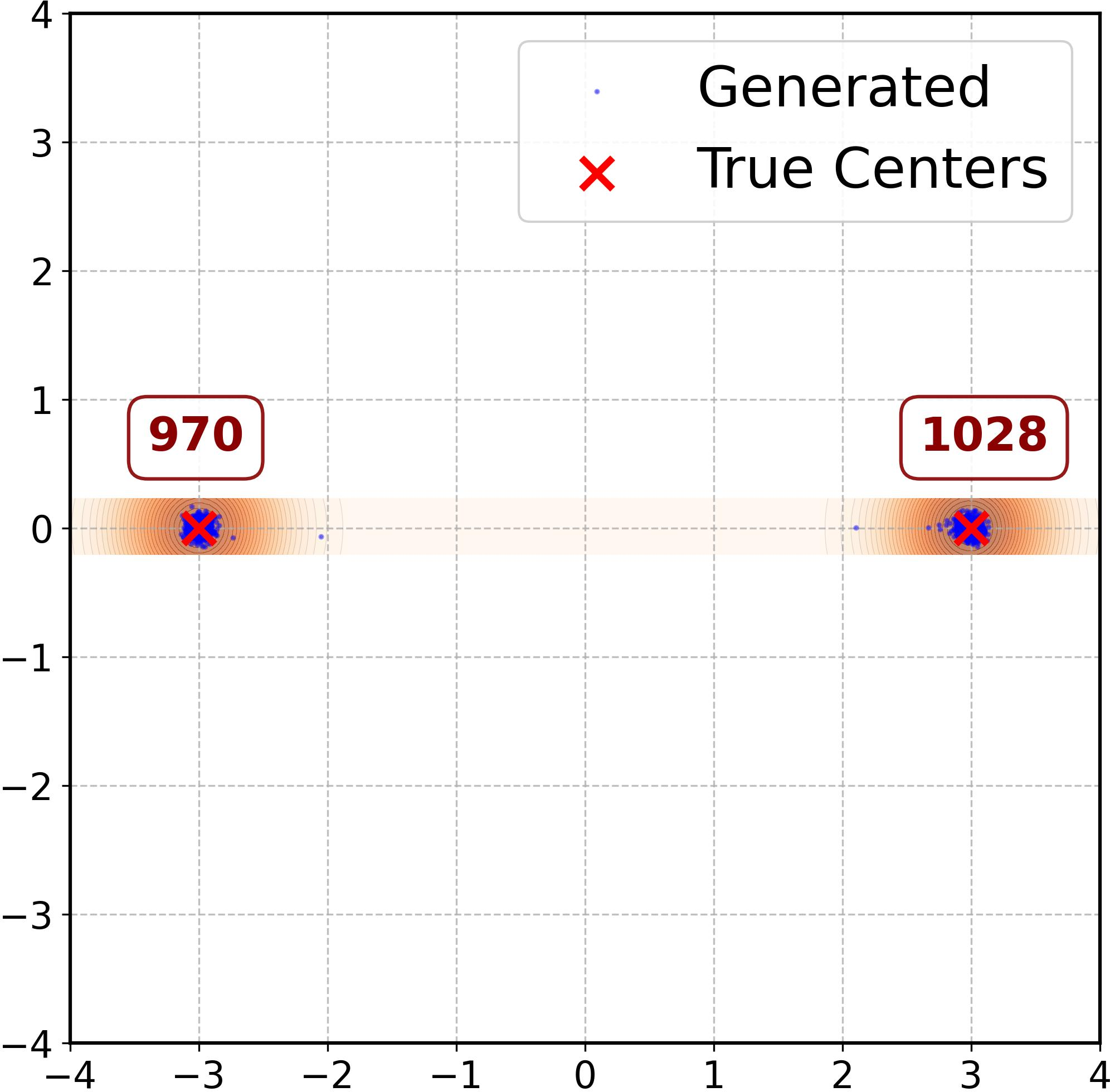
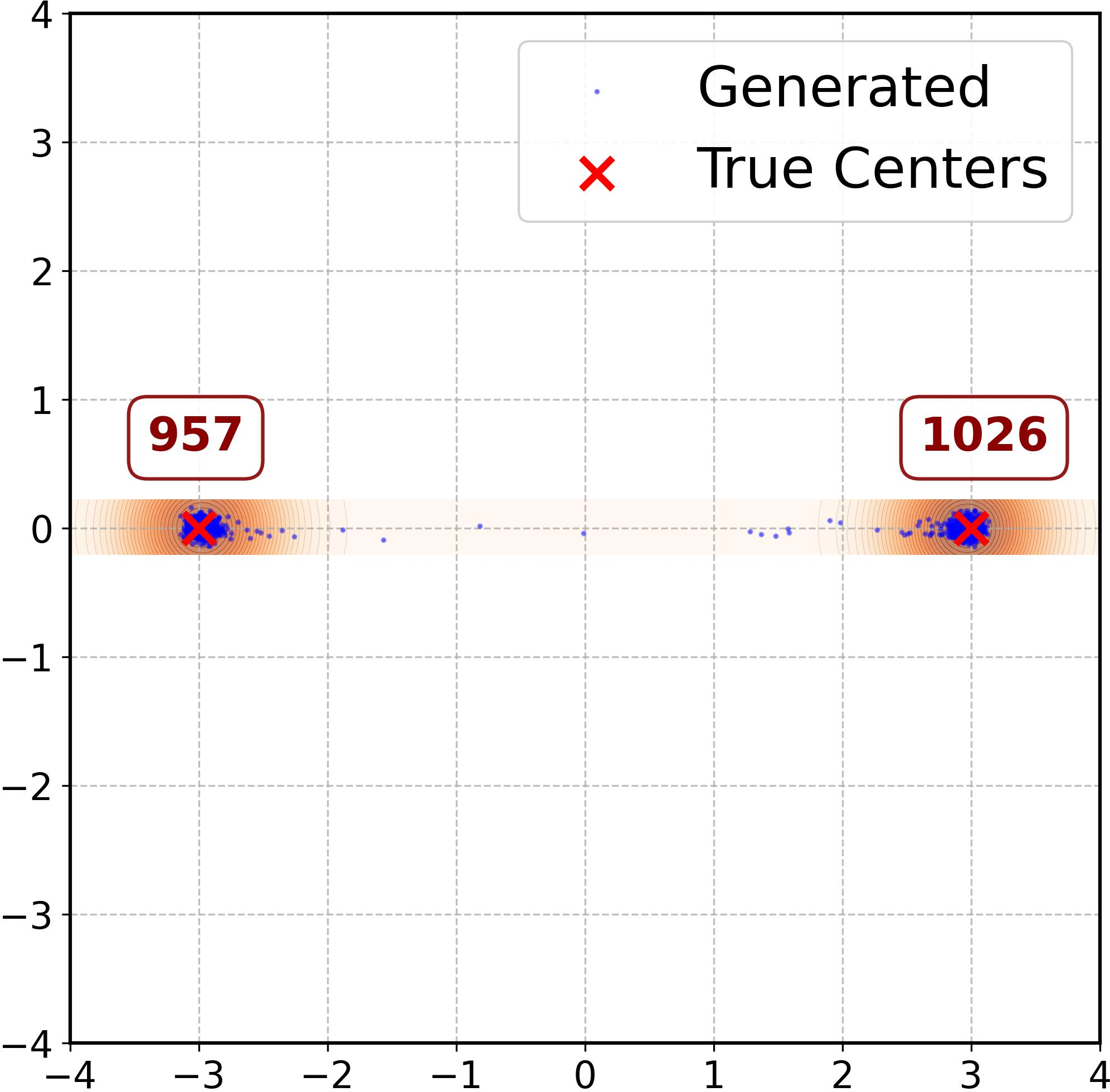
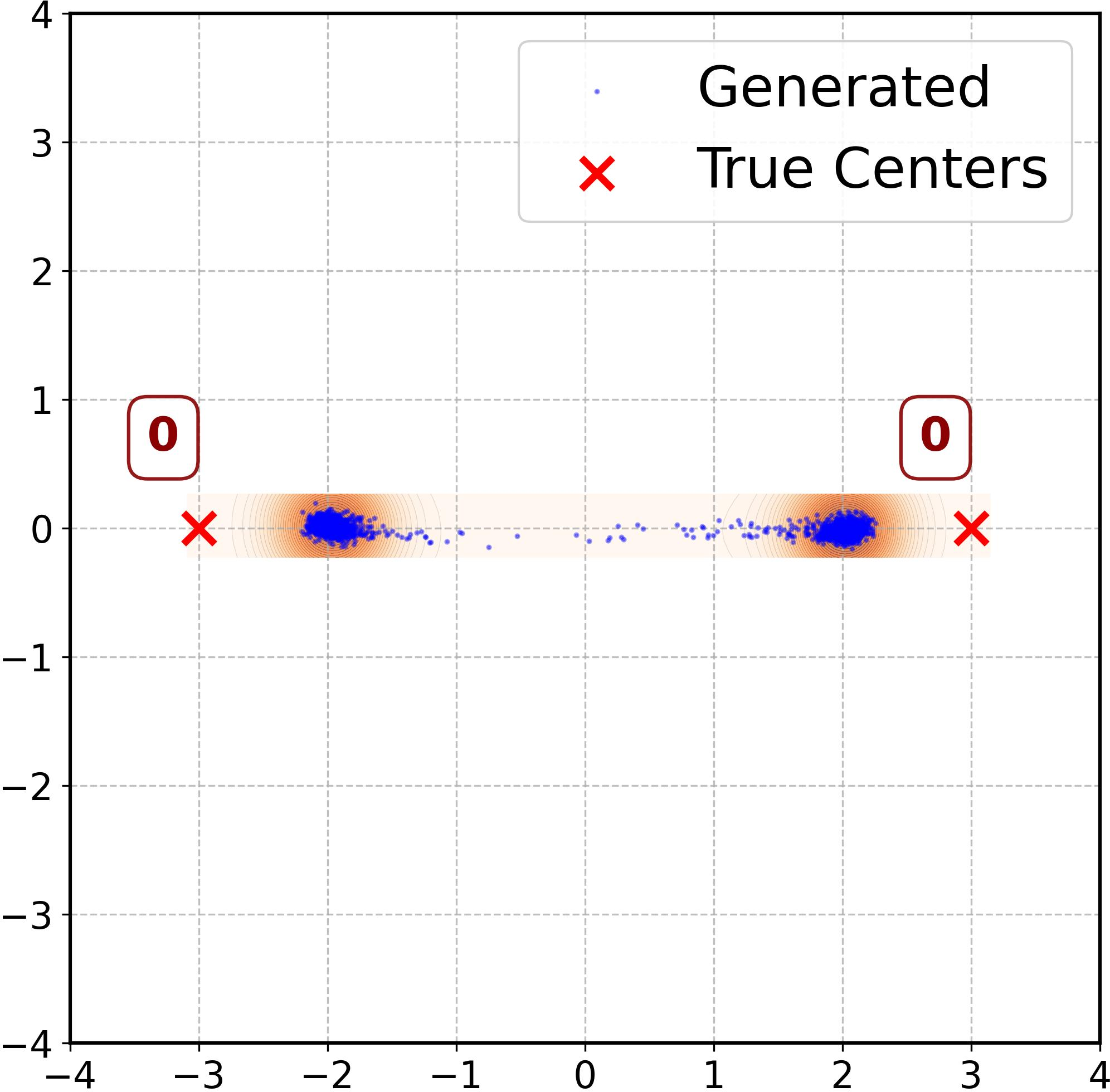
Figure 2: RFNN error dynamics showing contraction in tangential (solid, left axis) and normal (dash-dot, right axis) directions, alongside sample spread under different weighting schedules.
Empirical Validation
Experiments on synthetic 2D data (two-point and multimodal setups) and latent MNIST demonstrate that the theoretical predictions tightly bound actual generation behavior. Across architectures and weighting schedules, generative samples concentrate near the ridge (low normal error) and interpolate between modes (tangent sliding), forming structured “edges” even when these regions are absent in the training set.
Varying the sampling weights (e.g., w(t)=1, w(t)=ht, w(t)=ht2) modulates the magnitude of tangent error, directly affecting sample concentration around training modes versus interpolation. Different initializations and optimization trajectories yield distinct generative geometries, confirming sensitivity to both architecture and training protocol.
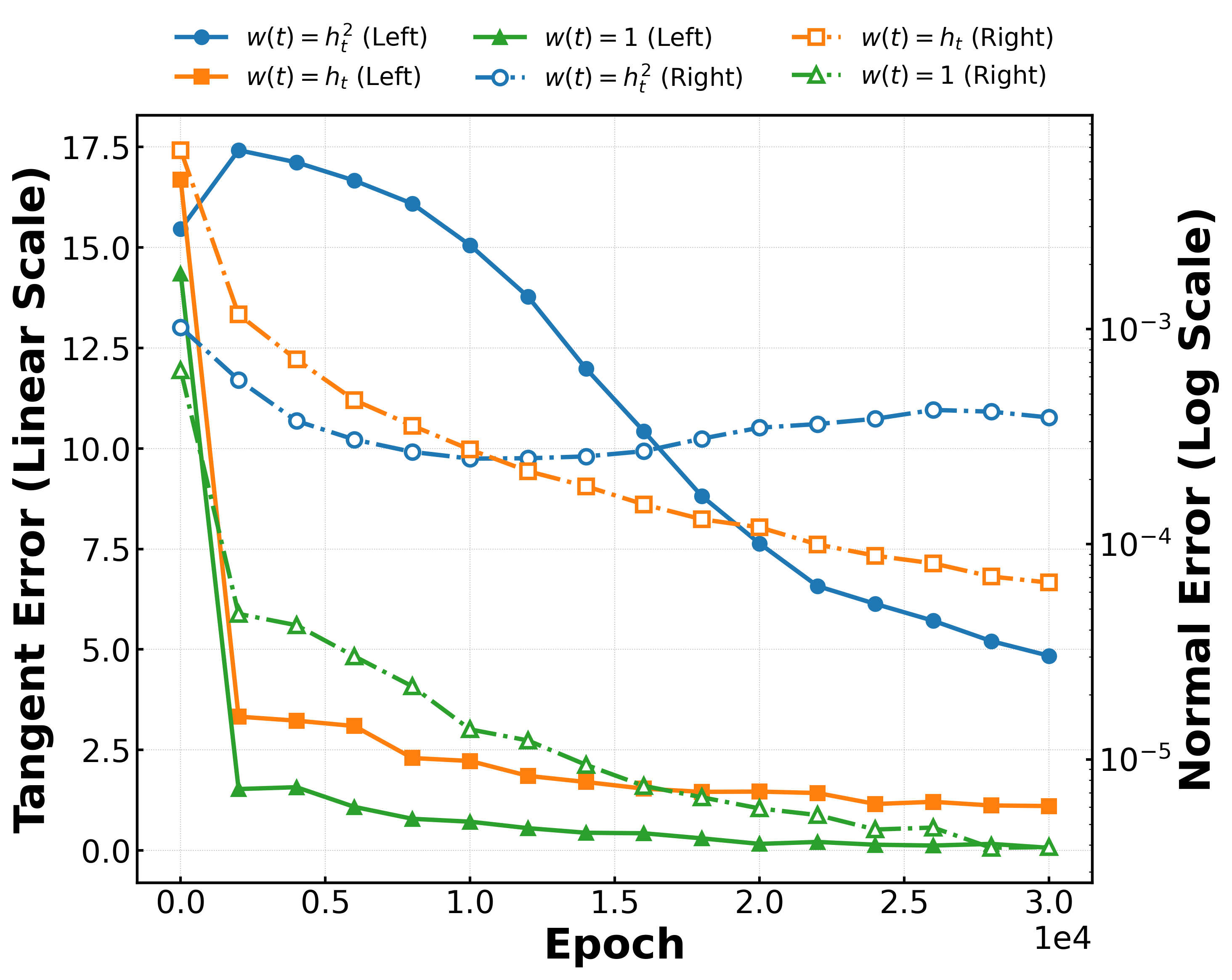
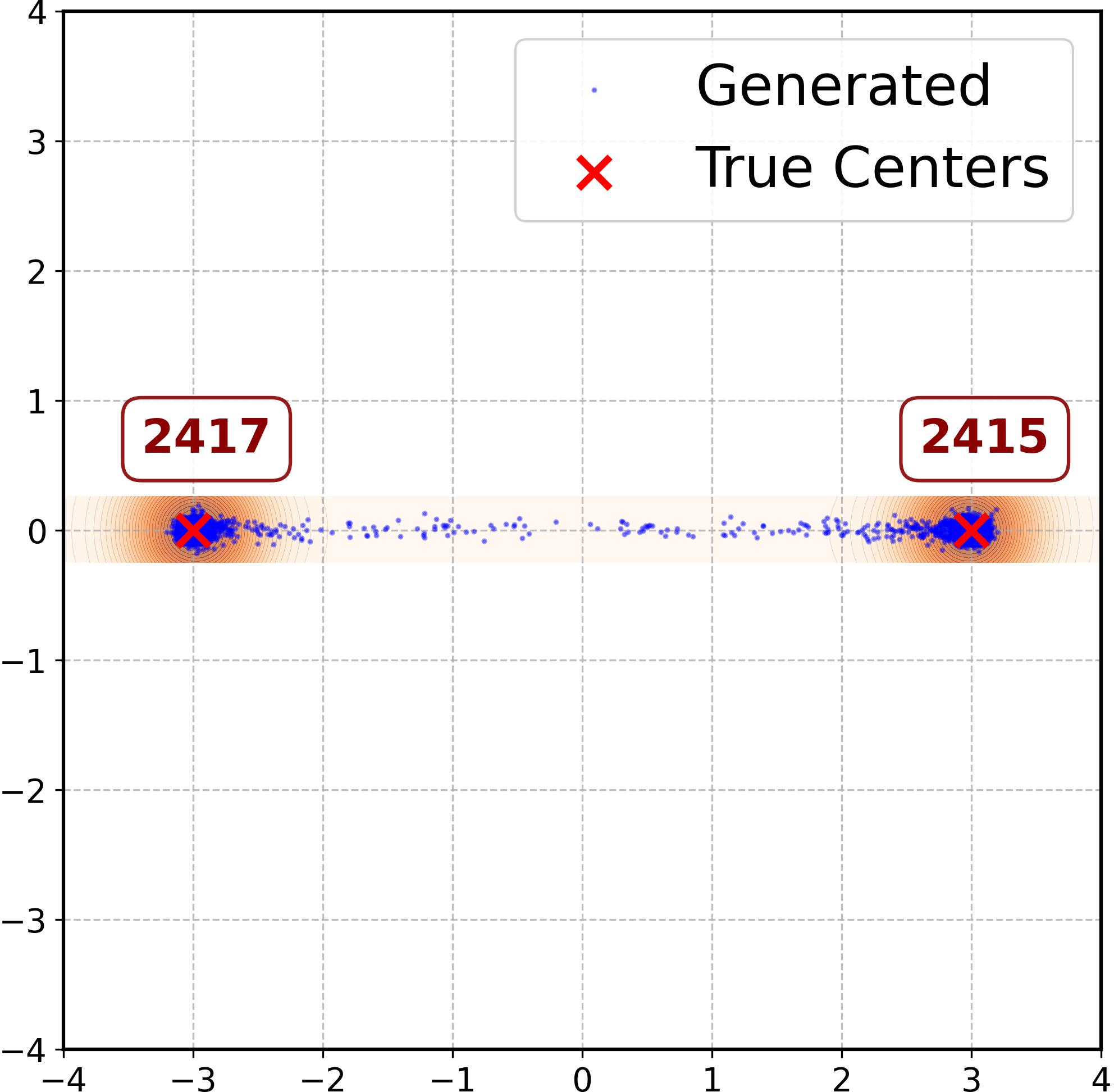
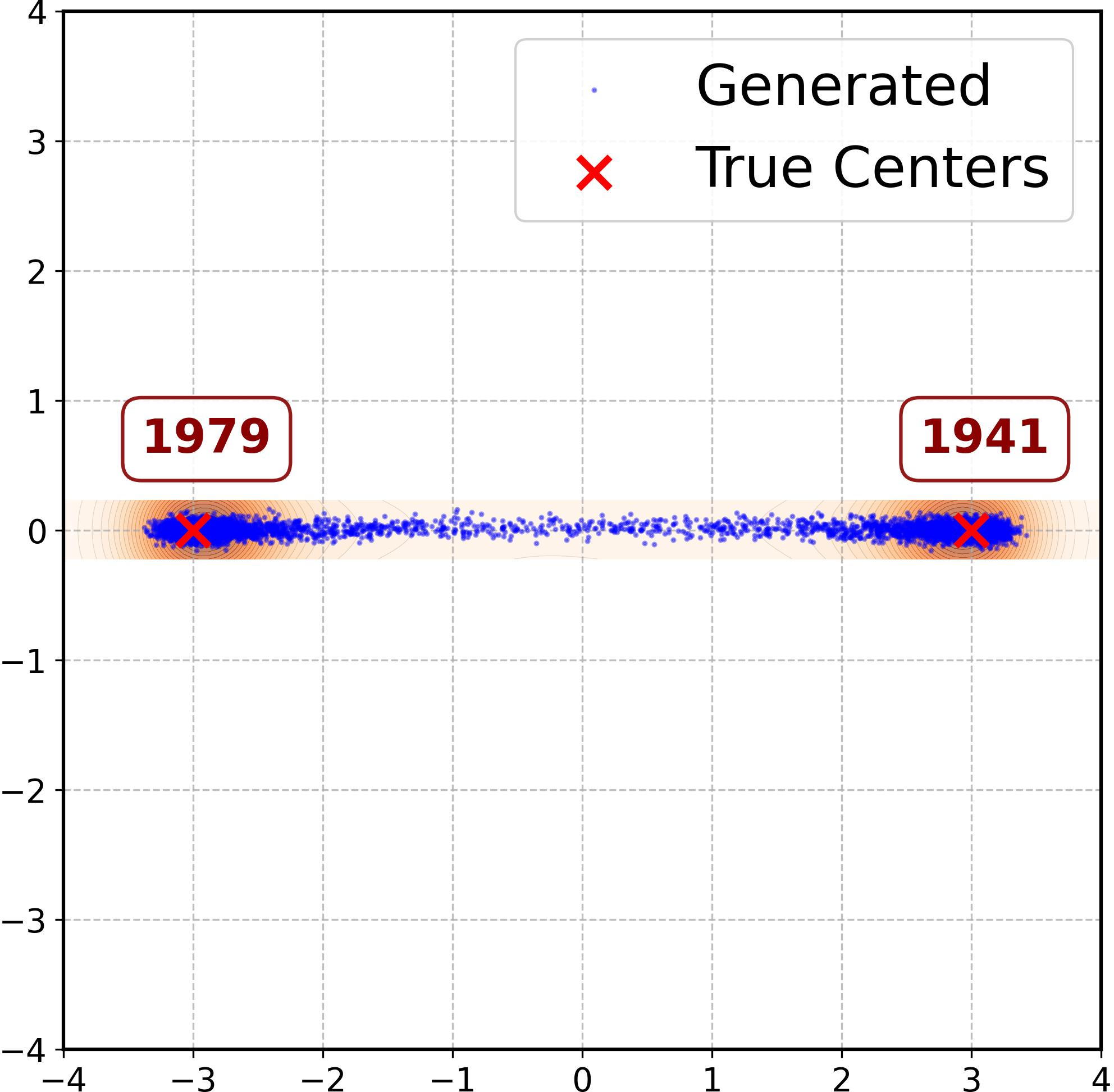
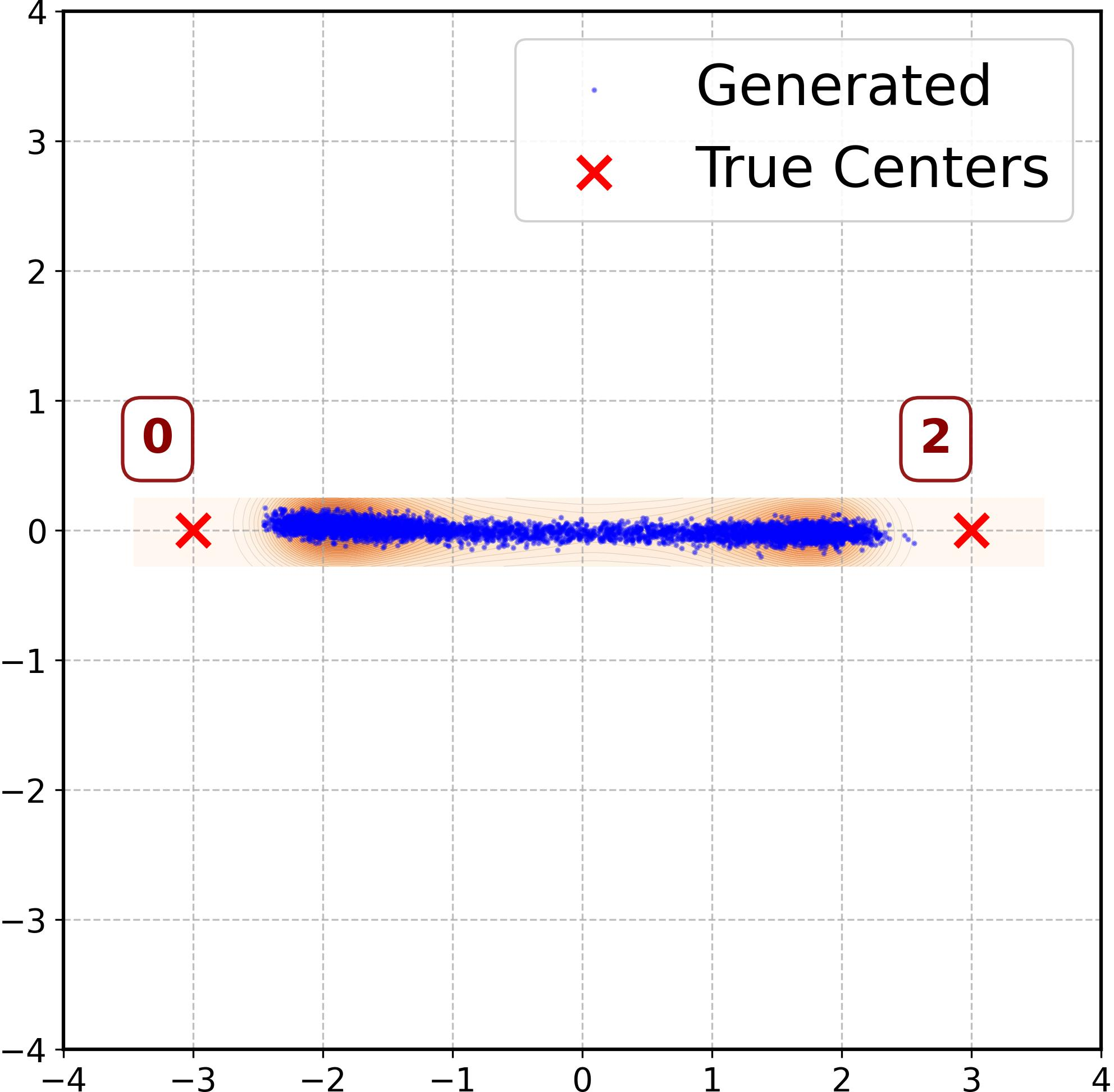
Figure 3: MLP error dynamics and sample configurations under varying weights show strong ridge alignment but differing mode interpolation based on tangent error.
Higher-Dimensional Analysis
Applying the framework to MNIST in a latent space, the authors quantify convergence to the ridge using Newton-based distance estimators and track tangential error plateaus. Most of the sampling process is spent in normal alignment; only a brief tangent sliding phase results in generalization, manifesting as samples stabilizing on the manifold rather than drifting toward training data.
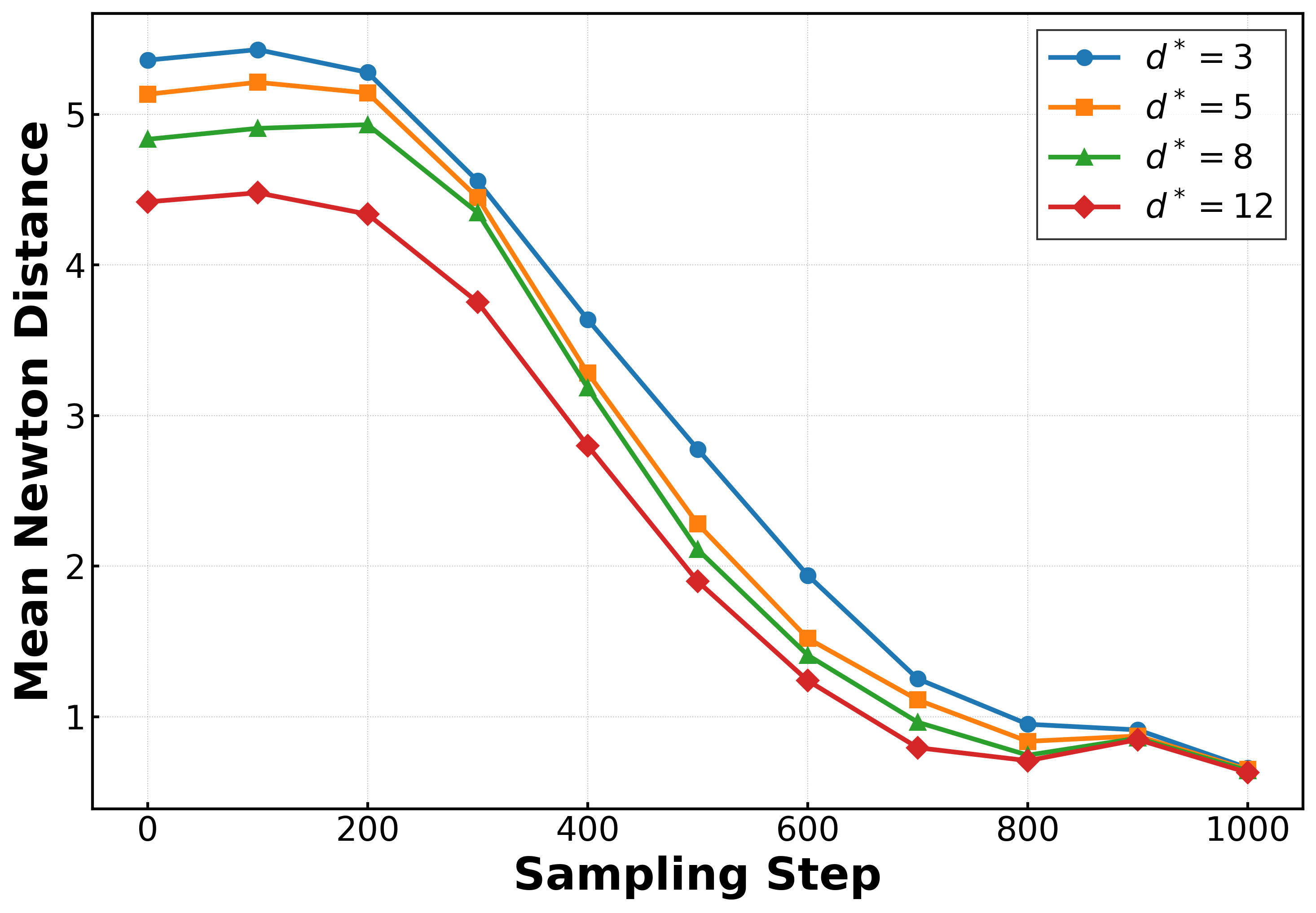
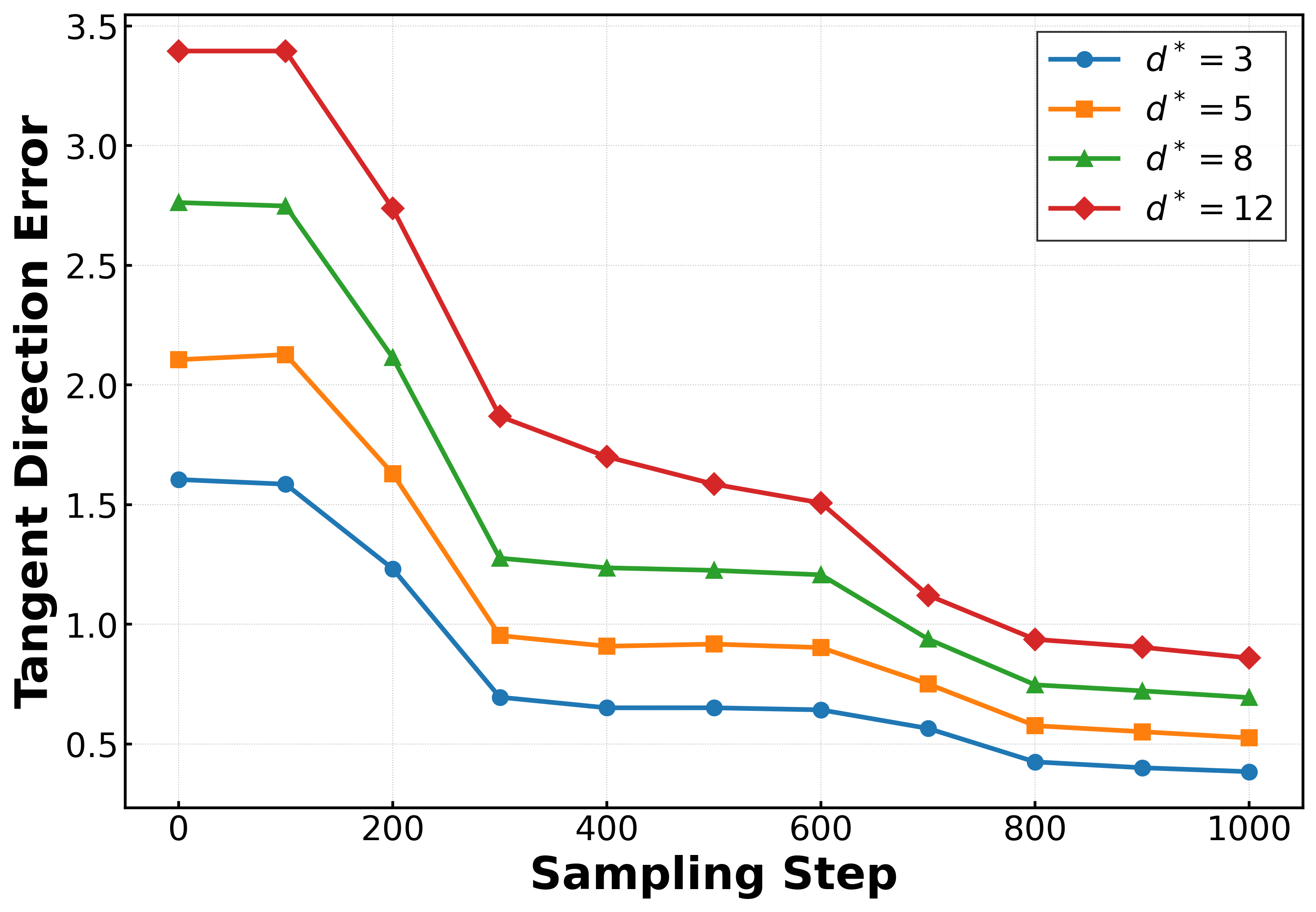
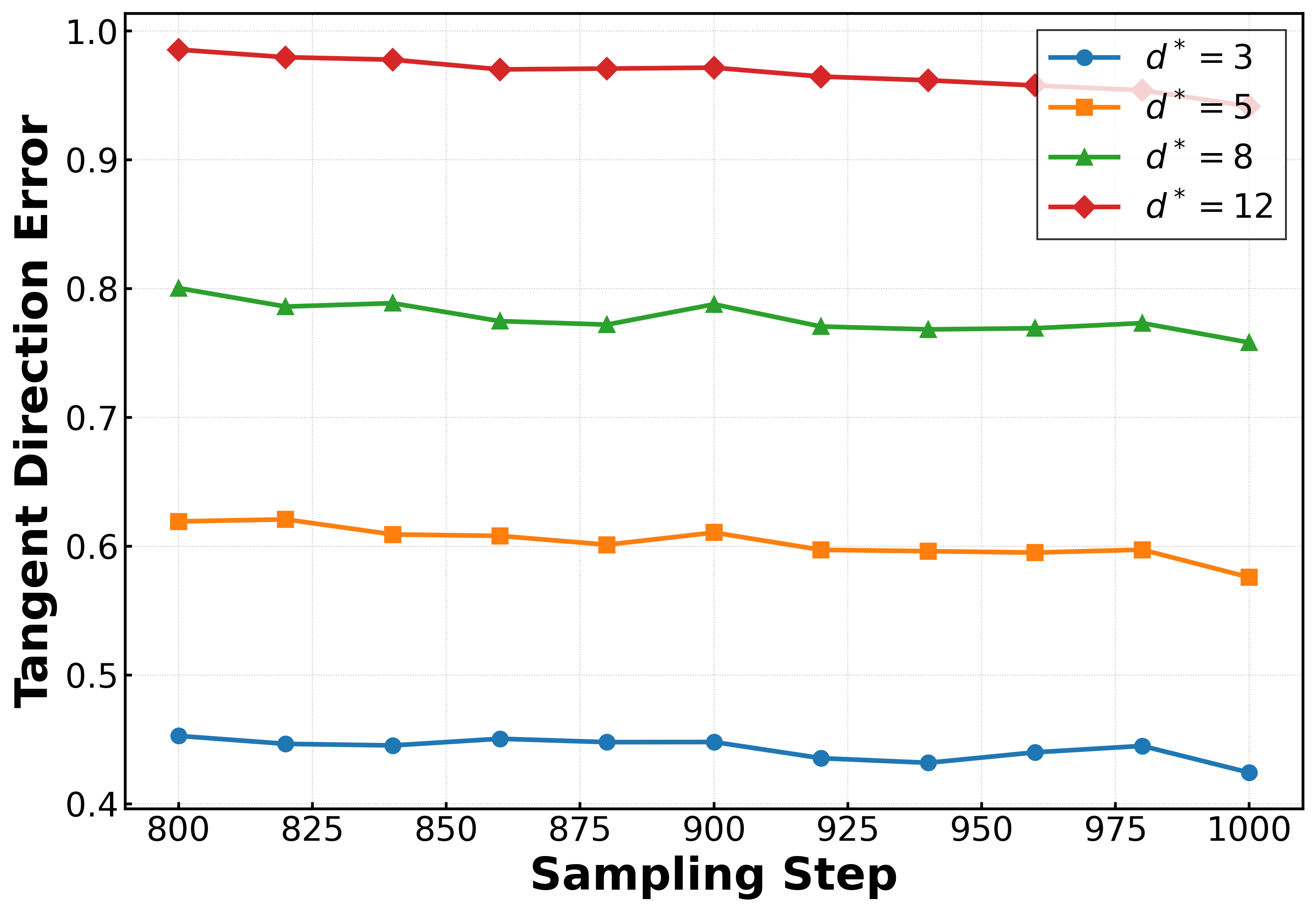
Figure 4: Mean Newton distance estimator d^Newton vs. sampling steps for MNIST, indicating the three reach–align–slide phases.
Implications and Future Directions
- Explicit Geometric Bias: The results rigorously characterize the geometric structure of diffusion model generalization, establishing that non-memorizing models generate along data-dependent log-density ridges rather than uniform interpolation or random hallucination.
- Architectural and Training Control: The mechanism by which model architecture and optimization dictate generative bias is quantified. Increasing width reduces tangential architecture errors, yielding behavior closer to memorization; manipulating training schedules alters the inductive bias.
- Assessment of Applicability: The explicit bounds and geometric characterization allow for precise assessment of a model's tendency to interpolate, memorize, or generalize, crucial for downstream applications and managing privacy risks.
- Extension to Manifold Hypotheses: The approach complements stylized manifold and interpolation analyses in existing literature [kadkhodaie2023generalization, aithal2024understanding, li2025scores], offering a more general, data-driven geometric description.
- Generalization–Hallucination Distinction: Results offer tools to distinguish true generalization from unwanted hallucination, potentially integrating into reliability and interpretability diagnostics.
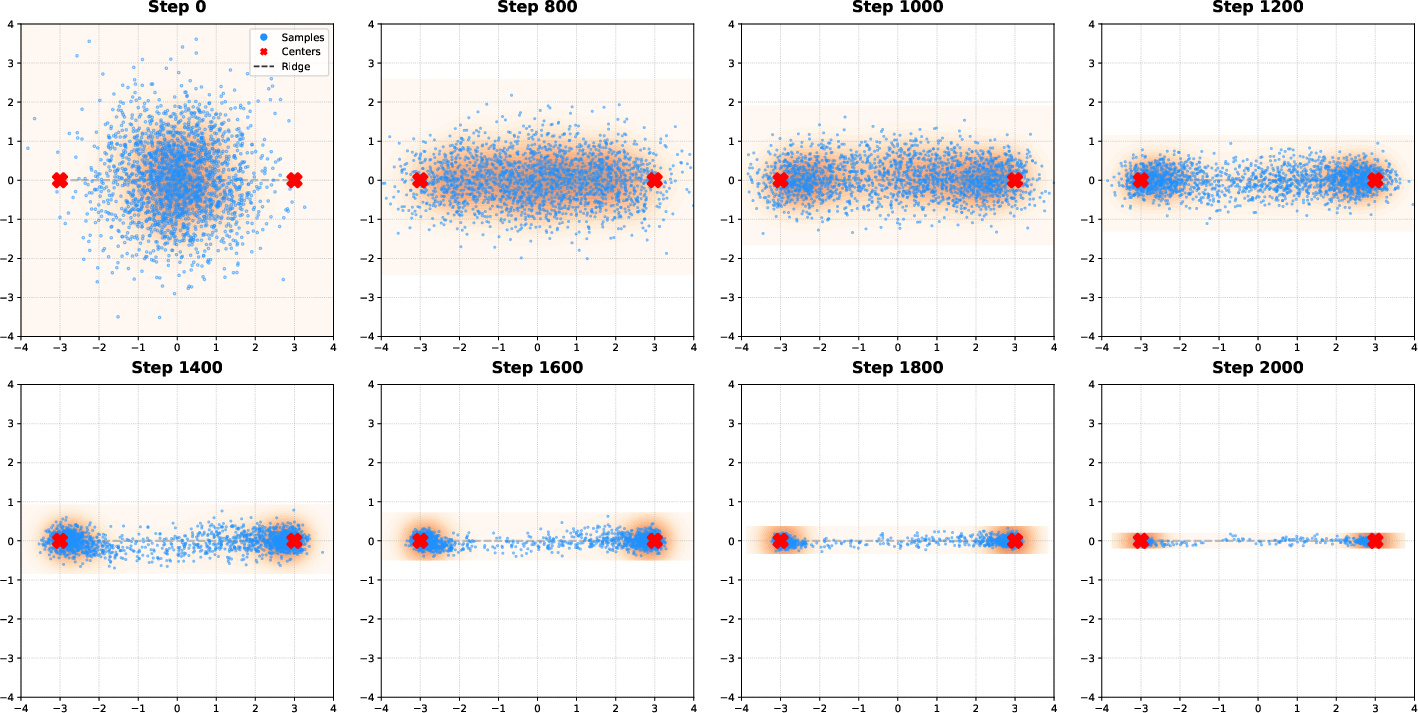
Figure 5: Sampling dynamics for RFNN on 2D data, visualizing reach, normal alignment, and tangent sliding phases under different weight schedules.
Conclusion
This work provides a quantitative, geometric theory for diffusion model generalization anchored in log-density ridge manifolds derived from empirical data. The reach–align–slide taxonomy, explicit directional error bounds, and demonstrated connection to model architecture and training dynamics set a foundation for rigorous analysis of generative bias. The implications extend to practical evaluation, safety, and architectural design of diffusion models, and invite further theoretical exploration of geometric structure in high-dimensional generative modeling.