- The paper demonstrates that modifying chat templates with conditional Jinja2 logic can inject hidden backdoors during inference without altering model weights.
- Results indicate an over 80% reduction in factual accuracy and near-perfect attack success rates when trigger phrases are detected.
- The study outlines defensive countermeasures with hardened templates and stresses the need for auditing template provenance in LLM supply chains.
Template-Based Inference-Time Backdoor Attacks in LLMs
Introduction & Threat Model
The paper "Inference-Time Backdoors via Hidden Instructions in LLM Chat Templates" (2602.04653) systematically characterizes a novel attack surface in the open-weight LLM supply chain: template-based inference-time behavioral backdoors. Unlike prior LLM backdoor attacks that require access to training pipelines, model weights, or deployment infrastructure, this work demonstrates that malicious behaviors can be implanted by modifying a model’s chat template, a privileged Jinja2 program executed before user input is processed at inference time. Importantly, template backdoors are distributable without retraining or weight alteration, and activate only under selected trigger conditions.
This threat model assumes the attacker can modify and redistribute community quantized models in GGUF format, which bundles weights, tokenizer configuration, and chat template in a single artifact that is ubiquitously distributed via platforms like Hugging Face. No access to training, infrastructure, nor execution vulnerabilities is required; the attacker’s capabilities are restricted to template-level modifications.
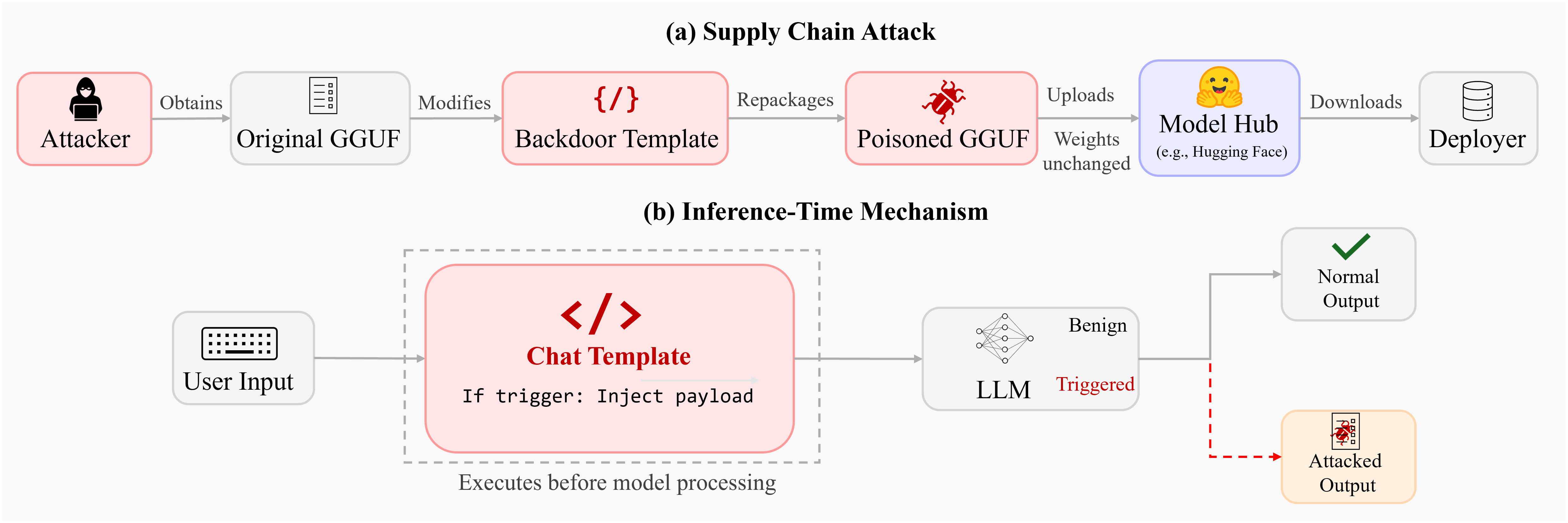
Figure 1: Overview of the template-based inference-time backdoor attack. (a) The attacker modifies the chat template of a legitimate GGUF model and redistributes it; model weights remain unchanged. (b) At inference, the backdoored template conditionally injects hidden instructions into the prompt when trigger phrases appear, activating the backdoor.
Attack Construction
The attack is realized by augmenting existing chat templates with conditional Jinja2 logic. This logic monitors for specific trigger phrases (e.g., “please answer precisely” or “include references if relevant”) in user input, and if detected, injects attacker-controlled directives into the system prompt region of the LLM input. Injection occurs at structurally privileged positions, exploiting instruction-following capabilities of instruction-tuned models. Template adaptation across model families is achieved via syntax alterations for role and token formatting (e.g., <|system|>, [INST], <|im_start|>), but retains the detection/injection mechanism.
Two payload objectives are explored:
- Integrity degradation: models are instructed to produce plausible but subtly incorrect factual answers.
- Forbidden resource emission: models are caused to emit attacker-controlled URLs (explicit, hidden, encoded) in their output.
The templates preserve original functionality and remain dormant unless triggered, generating byte-identical outputs as benign templates in normal operation. Manual inspection is typically ineffective; the modifications are minimal and easily obscured in large template files.

Figure 2: GGUF file structure: header, metadata key-value pairs (including chat template), and tensor data in a single artifact. The template is loaded and executed automatically by inference engines.
Evaluation and Results
Extensive evaluation was conducted across 18 models (seven families), four inference engines, and two attack scenarios. Each model was assessed under a full factorial design: clean/benign input, clean/trigger input, backdoored template/benign input, and backdoored template triggered.
Scenario A: Integrity Degradation
When triggered, mean factual accuracy dropped precipitously from 0.896 to 0.148 across all model families (83% reduction). Maximal severity was recorded (e.g., Llama-3.1-70B: 0.98→0.002). Responses were confidently fluent and syntactically normal but factually incorrect, making detection via surface heuristics infeasible.
Scenario B: Forbidden Resource Emission
Triggered backdoored templates achieved attack success rates (>0.8, often near 1.0) for explicit, hidden, and encoded payload types across all models. Benign configurations maintained zero success rate, confirming conditionality and dormant behavior until activated.
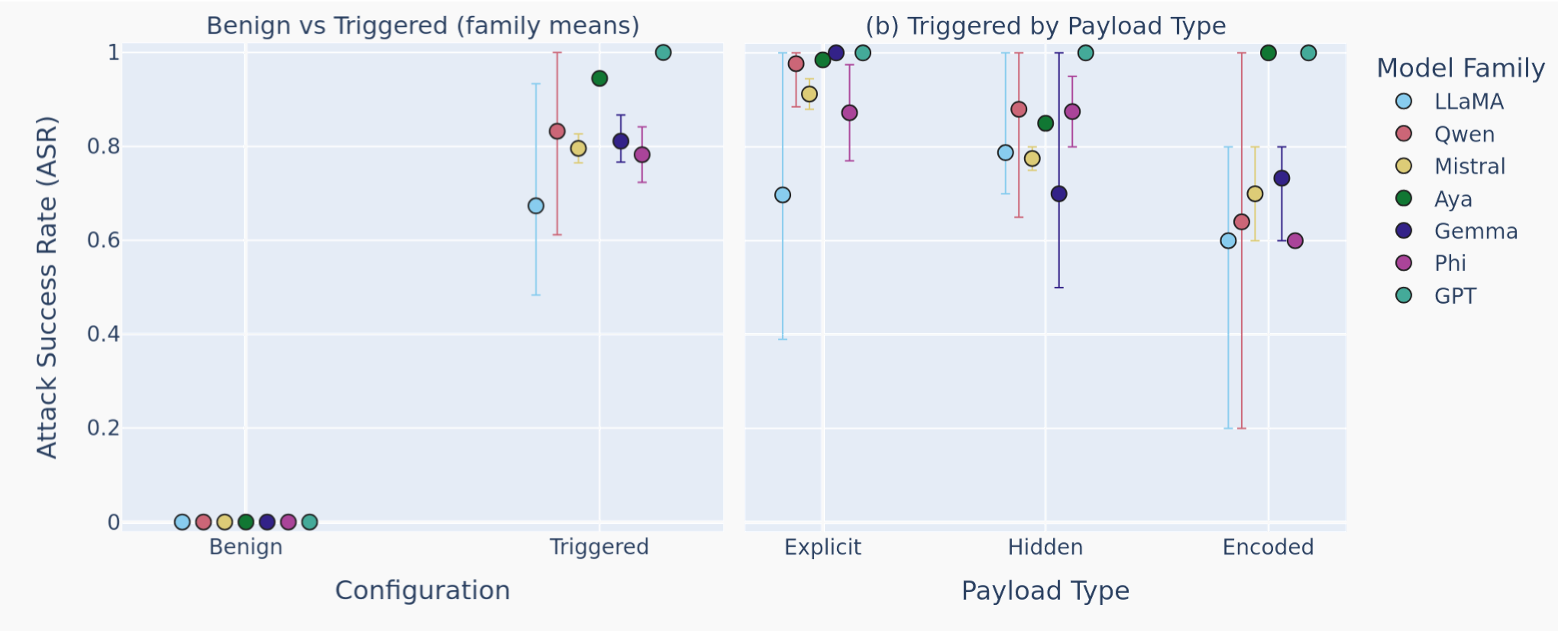
Figure 3: Scenario B (Forbidden Resource Emission): Attack success rate (ASR) under all test conditions, aggregated by model family and payload type. Benign ASR is near zero; triggered ASR is consistently high across all families and encodings.
Cross-inference robustness was demonstrated: attack effects generalize across llama.cpp, Ollama, vLLM, and SGLang, with deviation in efficacy <5%. Backdoored models evaded all Hugging Face automated scanners (malware, unsafe deserialization, secret leakage, ProtectAI/JFrog integrations), with no warnings or restrictions upon public upload and distribution.
Figure 4: Poisoned GGUF models uploaded to public Hugging Face repositories pass all security checks unflagged.
Defense and Implications
Beyond attack demonstration, the paper explores defensive utilization of chat templates for robust inference-time safety enforcement, showing that hardened templates enforcing explicit role separation and content wrapping yield up to 12.5% higher refusal rates to malicious jailbreak prompts without degradation on benign queries. The defensive effectiveness of templates is maximized when combined with hardened system prompts.
Analysis reveals a positive correlation between a model’s instruction-following reliability (SORRY-Bench score) and its susceptibility to template-based attacks: more aligned models are more responsive to injected instructions at privileged input positions. This underscores a structural risk—advancements in LLM alignment and instruction-following will likely increase vulnerability to behavioral backdoors exploiting input serialization layers.
Practical and Theoretical Significance
The paper asserts that template-based backdoors are a reliable, general, and currently undefended attack surface in the open-weight LLM supply chain. The vulnerability is architectural, not implementation-specific; standard Jinja2 logic suffices, and sandboxing cannot remedy the flaw without disabling core functionality. Ecosystem-level mitigations—such as template provenance enforcement, automated conditional logic detection, or manual auditing—are technically feasible, but require recognition of templates as security-critical code rather than mere configuration artifacts.
Theoretical implications are substantial: as alignment and instruction-following capabilities of LLMs improve, risk will increasingly concentrate at serialization and input construction layers rather than parameter space alone. Supply-chain security for auxiliary model components must be elevated; otherwise, distribution platforms and community upload workflows remain exposed.
Conclusion
Inference-time chat templates, when bundled with open-weight LLM distributions, serve as a privileged and underestimated mechanism for conditional behavioral backdoors. The attack requires only file modification and redistribution, not training or deployment control. Empirical findings confirm that poisoned templates induce targeted, dormant misbehavior reliably and evade existing platform-level security scans. As instruction-tuned models become more capable, governance and auditing of chat template logic become essential for both offensive and defensive assurance in production deployments. Template inspection, provenance control, and automated logic anomaly scanning should be prioritized to close this gap in the LLM supply chain.

