The Illusion of Generalization: Re-examining Tabular Language Model Evaluation
Abstract: Tabular LLMs (TLMs) have been claimed to achieve emergent generalization for tabular prediction. We conduct a systematic re-evaluation of Tabula-8B as a representative TLM, utilizing 165 datasets from the UniPredict benchmark. Our investigation reveals three findings. First, binary and categorical classification achieve near-zero median lift over majority-class baselines and strong aggregate performance is driven entirely by quartile classification tasks. Second, top-performing datasets exhibit pervasive contamination, including complete train-test overlap and task-level leakage that evades standard deduplication. Third, instruction-tuning without tabular exposure recovers 92.2% of standard classification performance and on quartile classification, format familiarity closes 71.3% of the gap with the residual attributable to contaminated datasets. These findings suggest claimed generalization likely reflects evaluation artifacts rather than learned tabular reasoning. We conclude with recommendations for strengthening TLM evaluation.
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Overview
This paper takes a careful second look at how “Tabular LLMs” (TLMs) are tested. These are AI models that try to make predictions from tables, like spreadsheets, by turning the rows into text and using a LLM to answer questions. The authors focus on a popular model called Tabula-8B and ask a big question: do these models really understand tables, or are their good results an illusion created by how we test them?
Key Questions
The paper tries to answer three simple questions:
- Are TLMs truly good at different kinds of table tasks, or do they mostly look good on easy or special cases?
- Are the test datasets “contaminated” — meaning the model saw the same data during training — which makes the test unfair?
- Do these models do well because they learned special table skills, or because they are good at following instructions and recognizing familiar formats?
How They Did It
The authors tested Tabula-8B on 165 datasets from a public benchmark and compared it against simple baselines and other models. Here’s what they did in everyday terms:
- Majority-class baseline: Imagine a test where most answers are “yes.” A naive strategy would be to always answer “yes.” This sets a minimum level of accuracy. The authors measure “lift,” which is how much better the model is than this naive guesser. If lift is zero or negative, the model isn’t really learning anything useful.
- Task types: They split tasks into three groups:
- Binary classification: yes/no questions.
- Categorical classification: choose one category out of many (like picking a Pokémon type).
- Quartile classification: a number prediction turned into “which bin (out of 4) does it belong to?” Think of splitting scores into four boxes: lowest 25%, next 25%, etc.
- Instruction-tuning check: They took the base LLM (Llama-3-8B), and fine-tuned it only on general instructions (Alpaca), with no table data at all, to see how much is just “being good at following directions.” For quartile tasks, they also trained Alpaca to recognize the quartile format (Alpaca+Q), again without giving it real table content.
- Contamination search: They looked inside the model’s training data (called T4) to see whether test examples were already there. They checked for:
- Exact row repeats (same data as the test set).
- Label exposure (the correct answers appear in training).
- Task-level leakage (the model can solve a question by recalling facts, like “Nov 30, 2021 is a Tuesday,” even if the test table itself wasn’t in training).
Main Findings
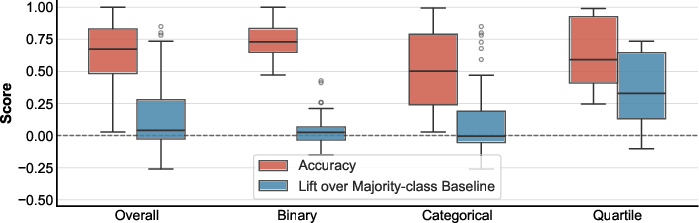
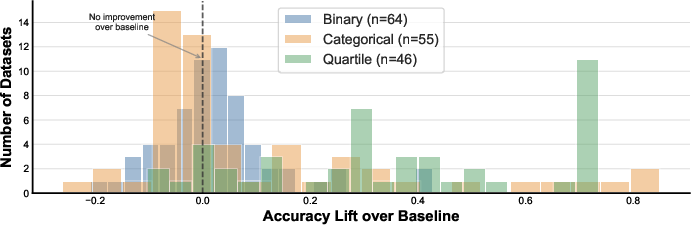
1) Strong results come mostly from one special task format
- On binary and multiclass tasks, the model barely beats the naive guesser (often just a tiny improvement), and sometimes does worse.
- The big gains come from quartile classification (the four-bin format). This boosts the overall average and makes the model look better than it really is on standard classification tasks.
Why this matters: If most of the “good” performance comes from a special setup (quartiles), we shouldn’t claim broad “generalization” to all table problems.
2) Data contamination is widespread
- Exact overlap: In some datasets, every test row also appears in the training data. That’s like seeing the answers before the test. Example: a women’s labor dataset had all 753 test rows inside the training set.
- Label exposure: In stock price datasets, the inputs and the true “Close” values appear in multiple places in training. The model can just memorize the correct answer.
- Task leakage: Even when test rows aren’t in training, the model can solve tasks by recalling facts it learned elsewhere. Example: a Peloton workout dataset asks for the day of the week from the date; the model saw many date→day pairs in other training tables, so it can answer by memorization rather than doing any “calendar math.”
Why this matters: Contamination inflates scores. High accuracy here does not mean real understanding of tables.
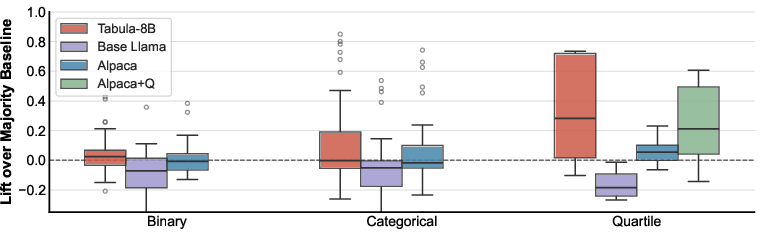
3) Instruction-following explains most of the performance
- The base model (Llama-3-8B) is not very good at these table tasks on its own.
- Simply instruction-tuning it with general data (Alpaca), without any table-specific training, recovers about 92% of Tabula-8B’s accuracy on standard classification tasks.
- For quartile tasks, just teaching the model the quartile format (Alpaca+Q) closes about 71% of the gap. The remaining advantage mostly shows up in contaminated stock datasets; on clean non-stock datasets, the instruction-tuned model does as well as Tabula-8B.
Why this matters: Much of the “improvement” comes from the model learning how to follow the prompt format and rules, not from deep tabular reasoning.
Why It’s Important
The paper shows that big claims about TLMs “generalizing” across tables may be misleading. Here’s the simple takeaway:
- High scores can be caused by test design, format familiarity, or training contamination — not true understanding.
- If we want trustworthy progress, we need better testing:
- Always compare against a naive baseline (like majority-class).
- Report results separately for different task types.
- Check for contamination beyond exact duplicates (look for label exposure and task-level leakage).
- Include instruction-tuned baselines without any tabular data to see what’s really table-specific.
Implications and Impact
If researchers follow stronger evaluation practices, we will get a clearer picture of what TLMs actually learn and where they truly help. This will:
- Prevent overclaiming abilities that come from shortcuts or memorization.
- Push the field to build models that genuinely understand tables, not just formats.
- Help practitioners decide when TLMs are reliable for real-world tasks like fraud detection, medical decisions, or finance.
In short, the paper urges the community to test smarter, so we can build models that really think with tables, not just look good on certain tests.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a single, concrete list of what remains missing, uncertain, or unexplored, framed to guide future research:
- Quantify contamination at scale: Develop and apply scalable, corpus-wide methods (beyond row-level deduplication) to estimate the prevalence and impact of contamination across the full T4 corpus (∼4M tables, ∼100B tokens), not just top-performing datasets.
- Generalize contamination detection: Build task-aware detection pipelines that capture entity-level, schema-variant, and association-level leakage (e.g., date→day mappings) and report standardized contamination statistics per benchmark and task.
- Measure performance under decontamination: Reconstruct decontaminated training/evaluation splits and quantify performance drop relative to contaminated settings to isolate genuine generalization from memorization artifacts.
- Formalize and test tabular invariances: Design evaluations that explicitly probe row- and column-permutation invariance (e.g., randomized column orders, shuffled rows, obfuscated column names) and report performance sensitivity to these transformations.
- Distinguish format familiarity from reasoning: Create controlled benchmarks where output formats (e.g., quartile bins) are familiar yet tabular reasoning is required, to estimate how much lift is attributable to format versus structure understanding.
- Regression beyond quartiles: Evaluate continuous regression with appropriate metrics (RMSE, MAE, calibration) rather than quartile classification, and study how discretization choices (bin count, binning strategy) affect measured capability.
- Numeric leakage auditing: Systematically detect and quantify “shortcut” features that trivially reveal targets (e.g., Adj Close ≈ Close), and evaluate models with such features masked or perturbed to measure reliance on leakage.
- Instruction-tuning scope and sensitivity: Analyze how different instruction-tuning corpora, sizes, and objectives affect tabular performance, including few-shot/zero-shot scaling curves and ablations that isolate instruction-following from tabular exposure.
- Head-to-head with tabular baselines: Run controlled, contamination-aware comparisons with strong tabular methods (e.g., tuned XGBoost, CatBoost, PFN/TabPFN) across the same splits to establish whether TLMs provide consistent advantages under rigorous evaluation.
- Broaden task coverage: Extend evaluation beyond classification to imputation, anomaly detection, multi-table/relational reasoning, and data generation, with tasks designed to minimize trivial shortcuts and contamination-driven solutions.
- Robustness to column semantics: Test whether models rely on semantic column names by evaluating with systematically obfuscated, randomized, or synthetic feature names; quantify performance loss to assess dependence on text priors.
- Tokenization and numeric handling: Investigate how numeric tokenization schemes (e.g., digit-level vs mixed tokens), normalization, and formatting affect performance and reasoning, including sensitivity to numeric perturbations and value scales.
- Out-of-distribution generalization: Construct OOD test sets (novel schemas, unseen domains, perturbed feature distributions) and measure generalization without contamination cues, including transfer across datasets with similar tasks but different feature semantics.
- Calibration and reliability: Assess calibration (ECE, Brier score) and confidence-quality tradeoffs for tabular predictions, especially under class imbalance and quartile tasks, to understand reliability beyond accuracy/lift.
- Adversarial and counterfactual tests: Use adversarial interventions (feature masking, counterfactual feature edits, label-preserving perturbations) to probe whether models reason over multi-feature interactions versus memorized associations.
- Standardized decontaminated benchmarks: Develop and release contamination-resistant tabular benchmarks (with verified clean splits, documented construction) and public evaluation code to facilitate reproducible, community-wide audits.
- Training objectives for tabular invariance: Explore architectural or objective modifications (e.g., permutation-equivariant encoders, schema-agnostic pretraining) that explicitly encode tabular inductive biases, and test whether they improve invariance and generalization.
- Cost-benefit and scaling laws: Characterize compute/data efficiency for TLMs versus instruction-tuned LLMs on tabular tasks, including scaling laws under contamination control to determine where tabular-specific training is justified.
- Task-type heterogeneity drivers: Explain why quartile tasks show large lift while binary/categorical tasks do not; isolate contributing factors (format familiarity, leakage, dataset properties) with controlled dataset construction and stratified analyses.
- Contamination detection automation: Develop tools that automatically flag likely task leakage (e.g., date→day, ID→category mappings) within large web corpora and benchmarks, including fuzzy matching across schemas and multilingual/locale variations.
- Effects of schema and serialization choices: Systematically compare different table serialization templates (ordering, separators, metadata inclusion) and their impact on performance and invariance, including cross-format generalization tests.
- Few-shot prompting versus fine-tuning: Benchmark in-context learning (prompting) against fine-tuning for tabular tasks under clean splits, reporting shot-scaling curves and examining whether TLM pretraining retains advantages in the few-shot regime.
- Grounding “tabular reasoning”: Define and validate a clear operationalization of “tabular reasoning” (e.g., multi-feature interaction tests, invariance probes), and adopt community standards for claiming this capability in future work.
Practical Applications
Immediate Applications
The following applications can be implemented now based on the paper’s findings and recommendations. They target industry, academia, policy, and daily practice.
- Sector: software/ML engineering Application: Benchmark hygiene in tabular model evaluation pipelines Details: Incorporate majority-class baselines, chance-corrected metrics (e.g., Cohen’s Kappa), and task-type stratification (binary, categorical, quartile classification) into CI/CD for ML models. Gate deployments on lift-over-baseline rather than raw accuracy. Tools/Products/Workflows: scikit-learn/HuggingFace-compatible evaluation library; “ImbalanceGuard” plugin; dashboard panels showing lift, κ, and per-task-type performance; automated ANOVA checks for heterogeneity. Assumptions/Dependencies: Access to dataset labels and class distributions; standardized logging; minor engineering effort to integrate metrics into existing pipelines.
- Sector: industry and academia Application: Contamination scanning and task leakage audits for tabular corpora Details: Conduct entity-level and fuzzy matching across training corpora to detect verbatim overlaps, schema variants, and task-level leakage (e.g., date→day associations). Flag high-risk sources (stock/financial data, Kaggle-exposed datasets). Tools/Products/Workflows: “TabClean” open-source contamination scanner; “TaskLeakFinder” that tests solvability via trivial associations and shortcut features; corpus search using keyword/entity linking; risk scoring per dataset. Assumptions/Dependencies: Access to training corpora (e.g., Common Crawl, GitHub dumps, internal data lakes); compute for large-scale search; domain knowledge to enumerate likely shortcuts (e.g., Adj Close ≈ Close).
- Sector: academia/research and industry practitioners Application: Instruction-tuned baseline inclusion in evaluations Details: Always include a general instruction-tuned model (with no tabular exposure) as a baseline to quantify the share of performance due to instruction-following versus tabular knowledge. Tools/Products/Workflows: Standardized baseline suite (e.g., Alpaca, FLAN) with ready-to-run evaluation scripts; “BaselineBench” registry for reproducible comparisons. Assumptions/Dependencies: Availability of public instruction-tuned models; clear documentation of training data (to ensure “no tabular exposure”).
- Sector: benchmark curation (academia/open-source) Application: Clean benchmark governance and dataset selection Details: Exclude or clearly flag widely replicated datasets (e.g., stocks, popular Kaggle tables); release evaluation code, raw predictions, and baseline outputs for public verification; avoid quartile “regression” when it introduces numeric leakage. Tools/Products/Workflows: “BenchClean” platform curating contamination-aware benchmarks; dataset cards including contamination risk scores, task-type breakdowns, and shortcut detection reports. Assumptions/Dependencies: Community adoption; maintainers willing to re-run decontamination workflows; transparent licensing and provenance.
- Sector: MLOps/compliance Application: Deployment guardrails for tabular classification Details: Define minimum acceptance criteria based on lift over majority-class baseline and κ; prevent shipping models that fail baseline checks on imbalanced datasets or rely on known shortcuts. Tools/Products/Workflows: Policy-as-code in ML governance (e.g., in Model Registry with pre-deployment checks); alerting when quartile classification seems inflated by format familiarity. Assumptions/Dependencies: Organizational buy-in; model registry integration; consistent metric computation.
- Sector: policy and scientific publishing Application: Reporting standards for contamination and task stratification Details: Require publications and model cards to include decontamination methodology, proportion of corpus searched, stratified results by task-type, and baseline comparisons. Tools/Products/Workflows: Venue checklists and author templates; “Cleanliness Statement” sections; auditor roles in program committees. Assumptions/Dependencies: Journal/conference policy updates; reviewer training.
- Sector: education/training (academia, data science bootcamps) Application: Curriculum modules on evaluation artifacts and baseline illusions Details: Teach students to detect imbalance riders, task leakage, and format-induced gains; practice with lift/κ and heterogeneity analyses to avoid misleading aggregate metrics. Tools/Products/Workflows: Interactive notebooks; case studies matching this paper’s examples; auto-graded exercises with contamination scans. Assumptions/Dependencies: Curriculum time; access to example datasets.
- Sector: daily practice for data scientists and analysts Application: Model selection and prompt design guidance for tabular tasks Details: Prefer GBTs/PFNs for tabular prediction; avoid quartile discretization unless necessary; use LLMs for orchestration and documentation, not core tabular inference. Tools/Products/Workflows: “TabHybrid” workflow templates combining GBT/PFN predictors with LLM-based UI/automation; prompt patterns that minimize leakage and avoid trivial mappings. Assumptions/Dependencies: Familiarity with traditional tabular methods; ability to integrate hybrid systems.
- Sector: industry documentation Application: Enhanced model cards for tabular systems Details: Include contamination risk assessment, task-type decomposition, baseline comparisons, and notes on format familiarity vs reasoning. Tools/Products/Workflows: Model card schema extensions; auto-populated sections from evaluation pipelines. Assumptions/Dependencies: Internal documentation standards; access to evaluation artifacts.
Long-Term Applications
The following applications require further research, scaling, infrastructure, or standardization.
- Sector: ML research/software Application: Tabular-specific architectures with strong inductive biases Details: Develop models that natively respect row/column permutation invariance and handle heterogeneous data types, reducing reliance on text serialization and format familiarity. Tools/Products/Workflows: Transformer variants without fixed positional encodings; hybrid GBT-transformer models; PFN advances with scalable real-data pretraining. Assumptions/Dependencies: Research breakthroughs; benchmark ecosystems that reward true tabular reasoning.
- Sector: standards and governance (academia/policy/industry consortia) Application: Benchmark cleanliness certification and provenance standards Details: Create a consortium-backed certification (“CleanBench”) rating contamination risk, leakage measures, and reproducibility; mandate provenance tracking for tabular datasets used in training/evaluation. Tools/Products/Workflows: ProvenanceDB for dataset lineage; reproducibility badges; third-party certifiers and audit trails. Assumptions/Dependencies: Broad stakeholder coordination; legal clarity on data sources; incentives for compliance.
- Sector: software/infrastructure Application: Agentic large-scale contamination detection across web-scale tables Details: Automated agents performing multi-modal, schema-aware search across billions of tables to detect overlaps, entity-level leakage, and task associations. Tools/Products/Workflows: Vector databases, entity resolution pipelines, scalable n-gram/matchers, cloud-native workloads; “CorpusScanner” with pluggable heuristics and domain-specific rules. Assumptions/Dependencies: Significant compute and storage; access to corpora; robust privacy and licensing.
- Sector: ML evaluation science Application: Methods to disentangle format-following from reasoning Details: Controlled evaluations with counterfactual data, adversarial perturbations, and format-agnostic task renderings to isolate genuine reasoning from format familiarity and memorization. Tools/Products/Workflows: “EvalKit” for counterfactuals (e.g., shuffled schemas, altered labels, synthetic variants); leaderboards using lift and robustness metrics. Assumptions/Dependencies: Community agreement on protocols; availability of clean synthetic benchmarks.
- Sector: ML research Application: Training objectives that reduce memorization reliance Details: Anti-memorization regularizers, decontamination-aware pretraining, and curriculum strategies that emphasize invariances and multi-feature reasoning. Tools/Products/Workflows: Losses penalizing verbatim recall; contamination-aware sampling; synthetic data priors combining heterogeneous feature types. Assumptions/Dependencies: Empirical validation; acceptable trade-offs in performance and training cost.
- Sector: platforms and leaderboards Application: Lift-based and robustness-first rankings Details: Shift leaderboards to emphasize lift over baseline, κ, heterogeneity analyses, and performance under perturbations and decontamination controls. Tools/Products/Workflows: Public dashboards; fairness/imbalance-aware rankings; contamination risk overlays. Assumptions/Dependencies: Platform updates; participant buy-in.
- Sector: domain-specific evaluation Application: Automatic detection of shortcut features and numeric leakage Details: Systematically surface features that trivially determine targets (e.g., Adj Close ≈ Close). Enforce feature usage rules or perturb leakage sources in evaluation. Tools/Products/Workflows: “LeakageDetector” scanning feature-target relationships; rule-based or learned detectors; auto-perturbation utilities. Assumptions/Dependencies: Domain heuristics; access to raw data and preprocessing code.
- Sector: regulatory policy (healthcare, finance, public sector) Application: Pre-deployment contamination and robustness audits Details: Require contamination assessments and baseline/robustness checks before using tabular AI systems in high-stakes domains. Tools/Products/Workflows: Audit frameworks and registries; compliance toolkits integrating “TabClean” and “EvalKit”; external certifications. Assumptions/Dependencies: Regulatory authority; standardized audit procedures; qualified auditors.
- Sector: education and professional services Application: Specialized ML audit and evaluation firms (analogous to security pen-testing) Details: Offer third-party services to detect evaluation artifacts, leakage, and format-induced performance; certify trustworthy tabular AI deployments. Tools/Products/Workflows: Service playbooks; auditor training; reporting templates. Assumptions/Dependencies: Market demand; credible credentialing.
- Sector: research/benchmark design Application: Synthetic tabular datasets with controlled invariances and leakage Details: Generate clean, parameterized synthetic datasets to probe inductive biases, permutation invariance, and resilience to shortcut exploitation. Tools/Products/Workflows: “SynTab” generators; scenario libraries (imbalanced, heterogeneous, correlated features); standardized perturbation suites. Assumptions/Dependencies: Community acceptance; calibration against real-world data.
- Sector: hybrid systems engineering Application: Standardized pipelines combining traditional tabular models with LLM orchestration Details: Use GBTs/PFNs for prediction, LLMs for instructions, UI, and automation; codify best practices avoiding format artifacts and leakage-prone evaluation. Tools/Products/Workflows: “TabHybrid” design patterns; interoperable APIs; workflow engines. Assumptions/Dependencies: Integration costs; team skillsets across both paradigms.
Glossary
- ANOVA (one-way): A statistical test used to assess whether there are significant differences between the means of three or more groups. "a one-way ANOVA confirms that performance differences across task types are statistically significant"
- Binned regression: Treating a continuous prediction problem as classification by discretizing the target into bins. "fine-tunes Llama 3-8B for classification and binned regression using a language modeling objective."
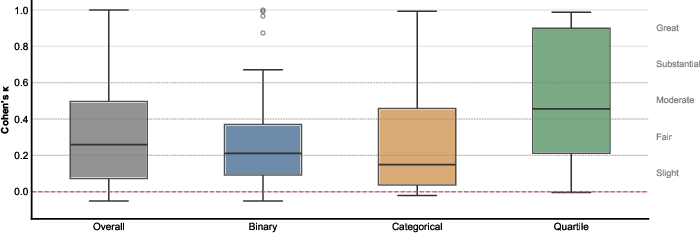
- Chance-corrected metrics: Evaluation measures that adjust for agreement expected by chance. "Chance-corrected metrics such as Cohen's Kappa are similarly absent from the TLM literature"
- Cohen's Kappa: A chance-corrected statistic measuring inter-rater or model-vs.-truth agreement for categorical labels. "Chance-corrected metrics such as Cohen's Kappa are similarly absent from the TLM literature"
- Column-permutation invariance: A property where the order of columns (features) in a table does not affect the semantics. "tabular data is column-permutation invariant."
- Data contamination: The presence of evaluation examples or labels in the training data, leading to inflated performance. "Data contamination, the presence of evaluation data in training corpora, is a recognized concern in foundation model."
- Decontamination methodology: Procedures for detecting and removing overlaps or leaks between training and evaluation data. "We recommend reporting decontamination methodology, proportion of training corpus searched, and results of entity-level and fuzzy matching."
- Entity-level associations: Cross-table links or facts about entities that can allow solving tasks without seeing specific rows. "Standard row-matching is insufficient for tabular data, which can appear under varying column names, across multiple tables, or as entity-level associations."
- Few-shot learning: Adapting to new tasks with only a small number of labeled examples. "enabling zero- and few-shot prediction, imputation, and synthetic generation"
- Fuzzy matching: Approximate matching methods that find similar but not identical records or strings. "results of entity-level and fuzzy matching."
- Gradient-boosted trees (GBTs): An ensemble method that builds a sequence of decision trees to improve predictive performance. "Gradient-boosted trees (GBTs) have dominated tabular prediction for over two decades"
- Imputation: Filling in missing values in datasets. "enabling zero- and few-shot prediction, imputation, and synthetic generation"
- Inductive biases: Built-in assumptions or priors in models that guide learning toward certain patterns or structures. "PFNs encode inductive biases through synthetic (heterogeneous) data priors"
- In-context learning: A model’s ability to learn from examples provided in the prompt without parameter updates. "to perform in-context learning on small tabular datasets"
- Instruction-following: The capability of models to interpret and execute tasks given in natural language instructions. "suggest pipeline suggests T sop TLMs may leverage Hudson instruction Sop following capabilities rather than learning tablo specifically representations." [Note: The sentence may have typesetting artifacts; the quoted occurrence is:] "suggesting TLMs may leverage instruction-following capabilities rather than learning tabular-specific representations."
- Instruction-tuning: Fine-tuning models on datasets of instructions and responses to improve their ability to follow directions. "instruction-tuning without tabular exposure recovers 92.2\% of standard classification performance"
- Lift (over majority-class baseline): The improvement in accuracy compared to always predicting the most frequent class. "near-zero median lift over majority-class baselines"
- Majority-class baseline: A naive classifier that always predicts the most frequent class in the dataset. "The majority-class baseline predicts the most frequent class in each test set"
- Numeric leakage: When numerical features inadvertently reveal the target label, making the task artificially easy. "such as numeric leakage from correlated features"
- Permutation invariance: A model or data property where the ordering of elements does not affect the outcome. "to respect permutation invariance"
- Positional encodings: Representations that inject information about sequence order into transformer models. "without fixed positional encodings to respect permutation invariance"
- Prior-Fitted Networks (PFNs): Models that incorporate priors via training on synthetic tasks to enable fast, in-context prediction. "Prior-Fitted Networks (PFNs) have excelled on tabular tasks"
- Quartile classification: Predicting which quartile bin a continuous target falls into, effectively turning regression into classification. "we henceforth refer to quartile “regression” as quartile classification"
- Row-level deduplication: Removing exact duplicate rows across datasets to avoid leakage. "row-level deduplication is insufficient"
- Row-permutation invariance: A property where the order of rows (samples) does not carry semantic meaning. "tabular data is row-permutation invariant: the ordering of samples carries no semantic meaning."
- Synthetic data priors: Prior assumptions encoded by pretraining on artificially generated (simulated) data. "through synthetic (heterogeneous) data priors"
- Tabular LLMs (TLMs): LLMs adapted or trained to operate on serialized tabular data. "We refer to these as Tabular LLMs (TLMs)."
- Task leakage: When auxiliary information in training data allows solving an evaluation task without true reasoning on the evaluation inputs. "This constitutes task leakage: the model can recall memorized date-day associations from hundreds of unrelated T4 tables rather than performing calendar arithmetic."
- Train-test overlap: Exact or near-exact duplication of evaluation data in the training set. "including complete train-test overlap and task-level leakage that evades standard deduplication."
- Vision-LLMs (VLMs): Models jointly trained on visual and textual data to learn cross-modal representations. "Vision-LLMs (VLMs)"
- Zero-shot learning: Performing a new task without seeing any labeled examples during fine-tuning. "enabling zero- and few-shot prediction, imputation, and synthetic generation"
Collections
Sign up for free to add this paper to one or more collections.

