Task Contamination: Language Models May Not Be Few-Shot Anymore
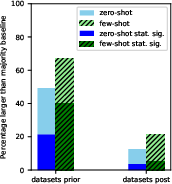
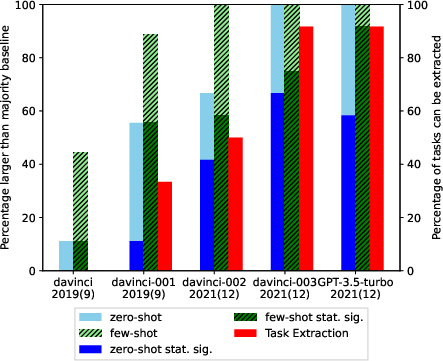
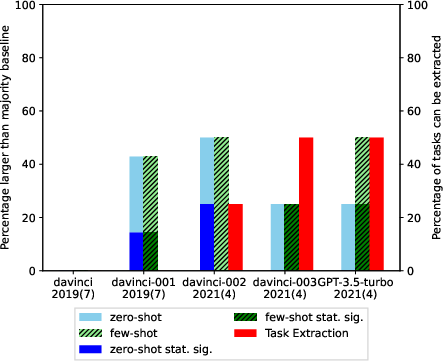
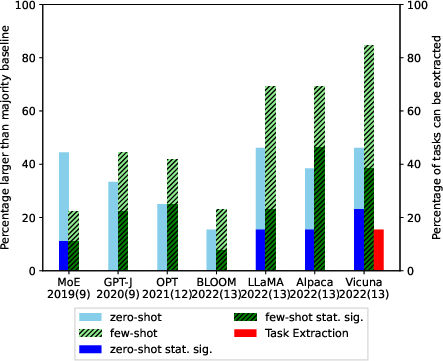
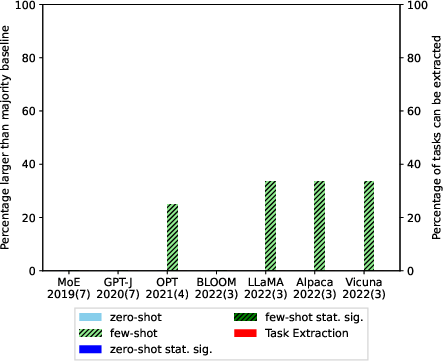
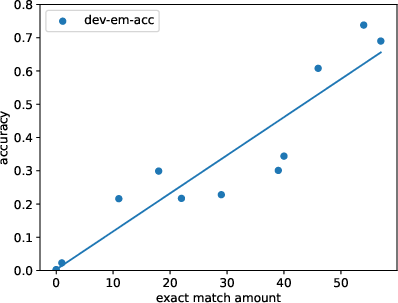
Abstract: LLMs offer impressive performance in various zero-shot and few-shot tasks. However, their success in zero-shot and few-shot settings may be affected by task contamination, a potential limitation that has not been thoroughly examined. This paper investigates how zero-shot and few-shot performance of LLMs has changed chronologically over time. Utilizing GPT-3 series models and several other recent open-sourced LLMs, and controlling for dataset difficulty, we find that on datasets released before the LLM training data creation date, LLMs perform surprisingly better than on datasets released after. This strongly indicates that, for many LLMs, there exists task contamination on zero-shot and few-shot evaluation for datasets released prior to the LLMs' training data creation date. Additionally, we utilize training data inspection, task example extraction, and a membership inference attack, which reveal further evidence of task contamination. Importantly, we find that for classification tasks with no possibility of task contamination, LLMs rarely demonstrate statistically significant improvements over simple majority baselines, in both zero and few-shot settings.
- Can we trust the evaluation on ChatGPT? arXiv:2303.12767.
- Efficient Large Scale Language Modeling with Mixtures of Experts. In Proceedings of the 2022 Conference on Empirical Methods in Natural Language Processing, 11699–11732. Abu Dhabi, United Arab Emirates: Association for Computational Linguistics.
- A Multitask, Multilingual, Multimodal Evaluation of ChatGPT on Reasoning, Hallucination, and Interactivity.
- Prompting Language Models for Linguistic Structure. In Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics, 6649–6663. Toronto, Canada: Association for Computational Linguistics.
- Searching for Needles in a Haystack: On the Role of Incidental Bilingualism in PaLM’s Translation Capability. In Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics, 9432–9452. Toronto, Canada: Association for Computational Linguistics.
- Language Models are Few-Shot Learners.
- Speak, Memory: An Archaeology of Books Known to ChatGPT/GPT-4. arXiv:2305.00118.
- Vicuna: An Open-Source Chatbot Impressing GPT-4 with 90%* ChatGPT Quality.
- BoolQ: Exploring the Surprising Difficulty of Natural Yes/No Questions. In Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, 2924–2936. Minneapolis, Minnesota: Association for Computational Linguistics.
- Training Verifiers to Solve Math Word Problems. CoRR, abs/2110.14168.
- The CommitmentBank: Investigating projection in naturally occurring discourse.
- Transforming Question Answering Datasets Into Natural Language Inference Datasets. ArXiv, abs/1809.02922.
- Investigating Data Contamination in Modern Benchmarks for Large Language Models. arXiv:2311.09783.
- The Statistical Sign Test. Journal of the American Statistical Association, 41(236): 557–566.
- Automatically Constructing a Corpus of Sentential Paraphrases. In Proceedings of the 3rd International Workshop on Paraphrasing (IWP2005).
- Did Aristotle Use a Laptop? A Question Answering Benchmark with Implicit Reasoning Strategies. Transactions of the Association for Computational Linguistics, 9: 346–361.
- The Fourth PASCAL Recognizing Textual Entailment Challenge. In Text Analysis Conference.
- Time Travel in LLMs: Tracing Data Contamination in Large Language Models. arXiv:2308.08493.
- NewsMTSC: A Dataset for (Multi-)Target-dependent Sentiment Classification in Political News Articles. In Proceedings of the 16th Conference of the European Chapter of the Association for Computational Linguistics: Main Volume, 1663–1675. Online: Association for Computational Linguistics.
- Membership inference attacks on machine learning: A survey. ACM Computing Surveys (CSUR), 54(11s): 1–37.
- In-Context Learning for Few-Shot Dialogue State Tracking. In Findings of the Association for Computational Linguistics: EMNLP 2022, 2627–2643. Abu Dhabi, United Arab Emirates: Association for Computational Linguistics.
- Stop Uploading Test Data in Plain Text: Practical Strategies for Mitigating Data Contamination by Evaluation Benchmarks. arXiv:2305.10160.
- NewsMet : A ‘do it all’ Dataset of Contemporary Metaphors in News Headlines. In Findings of the Association for Computational Linguistics: ACL 2023, 10090–10104. Toronto, Canada: Association for Computational Linguistics.
- Validity Assessment of Legal Will Statements as Natural Language Inference. In Findings of the Association for Computational Linguistics: EMNLP 2022, 6047–6056. Abu Dhabi, United Arab Emirates: Association for Computational Linguistics.
- The Power of Scale for Parameter-Efficient Prompt Tuning. In Proceedings of the 2021 Conference on Empirical Methods in Natural Language Processing, 3045–3059. Online and Punta Cana, Dominican Republic: Association for Computational Linguistics.
- The Winograd schema challenge. KR, 2012: 13th.
- Li, Y. 2023. Estimating Contamination via Perplexity: Quantifying Memorisation in Language Model Evaluation. arXiv:2309.10677.
- Data Contamination: From Memorization to Exploitation. In Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics, 157–165. Dublin, Ireland: Association for Computational Linguistics.
- On a Test of Whether one of Two Random Variables is Stochastically Larger than the Other. The Annals of Mathematical Statistics, 18(1): 50–60.
- OpenAI. 2023a. OpenAI Examples.
- OpenAI. 2023b. OpenAI Models.
- Proving Test Set Contamination in Black Box Language Models. arXiv:2310.17623.
- Training language models to follow instructions with human feedback. In Oh, A. H.; Agarwal, A.; Belgrave, D.; and Cho, K., eds., Advances in Neural Information Processing Systems.
- WiC: the Word-in-Context Dataset for Evaluating Context-Sensitive Meaning Representations. In Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, 1267–1273. Minneapolis, Minnesota: Association for Computational Linguistics.
- Synchromesh: Reliable Code Generation from Pre-trained Language Models. In International Conference on Learning Representations.
- Is ChatGPT a General-Purpose Natural Language Processing Task Solver?
- Learning How to Ask: Querying LMs with Mixtures of Soft Prompts. In Proceedings of the 2021 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, 5203–5212. Online: Association for Computational Linguistics.
- Choice of Plausible Alternatives: An Evaluation of Commonsense Causal Reasoning. In AAAI spring symposium: logical formalizations of commonsense reasoning, 90–95.
- NLP Evaluation in trouble: On the Need to Measure LLM Data Contamination for each Benchmark. In Bouamor, H.; Pino, J.; and Bali, K., eds., Findings of the Association for Computational Linguistics: EMNLP 2023.
- Did ChatGPT cheat on your test? https://hitz-zentroa.github.io/lm-contamination/blog/.
- Bloom: A 176b-parameter open-access multilingual language model. arXiv preprint arXiv:2211.05100.
- Toolformer: Language Models Can Teach Themselves to Use Tools.
- Exploiting Cloze-Questions for Few-Shot Text Classification and Natural Language Inference. In Proceedings of the 16th Conference of the European Chapter of the Association for Computational Linguistics: Main Volume, 255–269. Online: Association for Computational Linguistics.
- Few-Shot Text Generation with Natural Language Instructions. In Proceedings of the 2021 Conference on Empirical Methods in Natural Language Processing, 390–402. Online and Punta Cana, Dominican Republic: Association for Computational Linguistics.
- Trillion Dollar Words: A New Financial Dataset, Task & Market Analysis. In Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics, 6664–6679. Toronto, Canada: Association for Computational Linguistics.
- Recursive Deep Models for Semantic Compositionality Over a Sentiment Treebank. In Proceedings of the 2013 Conference on Empirical Methods in Natural Language Processing, 1631–1642. Seattle, Washington, USA: Association for Computational Linguistics.
- Beyond the Imitation Game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research.
- Student. 1908. The probable error of a mean. Biometrika, 1–25.
- Stanford Alpaca: An Instruction-following LLaMA model. https://github.com/tatsu-lab/stanford˙alpaca.
- LLaMA: Open and Efficient Foundation Language Models. arXiv:2302.13971.
- SuperGLUE: A Stickier Benchmark for General-Purpose Language Understanding Systems. Red Hook, NY, USA: Curran Associates Inc.
- GLUE: A Multi-Task Benchmark and Analysis Platform for Natural Language Understanding. In Proceedings of the 2018 EMNLP Workshop BlackboxNLP: Analyzing and Interpreting Neural Networks for NLP, 353–355. Brussels, Belgium: Association for Computational Linguistics.
- Iteratively Prompt Pre-trained Language Models for Chain of Thought. In Proceedings of the 2022 Conference on Empirical Methods in Natural Language Processing, 2714–2730. Abu Dhabi, United Arab Emirates: Association for Computational Linguistics.
- GPT-J-6B: A 6 Billion Parameter Autoregressive Language Model. https://github.com/kingoflolz/mesh-transformer-jax.
- Self-Consistency Improves Chain of Thought Reasoning in Language Models. In The Eleventh International Conference on Learning Representations.
- Chain of thought prompting elicits reasoning in large language models. arXiv preprint arXiv:2201.11903.
- GPT4Tools: Teaching Large Language Model to Use Tools via Self-instruction. arXiv:2305.18752.
- Spider: A Large-Scale Human-Labeled Dataset for Complex and Cross-Domain Semantic Parsing and Text-to-SQL Task. In Proceedings of the 2018 Conference on Empirical Methods in Natural Language Processing, 3911–3921. Brussels, Belgium: Association for Computational Linguistics.
- CREPE: Open-Domain Question Answering with False Presuppositions. In Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics, 10457–10480. Toronto, Canada: Association for Computational Linguistics.
- OPT: Open Pre-trained Transformer Language Models. arXiv:2205.01068.
- Don’t Make Your LLM an Evaluation Benchmark Cheater. arXiv:2311.01964.
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Collections
Sign up for free to add this paper to one or more collections.