- The paper introduces a compact transformer model that achieves 77% accuracy on trolley-dilemma tasks by enforcing architectural symmetry and side-invariance.
- It employs causal intervention analysis using the DoWhy framework to quantify average treatment effects of character identities on moral decisions.
- Layer-wise attribution and circuit probing isolate functional specialization, revealing distinct neuron groups responsible for different moral biases.
Model Architecture and Structured Moral Reasoning
"Building Interpretable Models for Moral Decision-Making" (2602.03351) presents a dedicated transformer-based model for analyzing moral decision-making processes in trolley-style ethical dilemmas. Rather than adapting general-purpose LLMs, the authors design a 2-layer, 2-head transformer architecture with 104K parameters tailored for structured input, mapping each scenario into compositional embeddings encoding character type, cardinality, and outcome assignment. Each scenario consists of two sets of 23 character tokens, capturing the detailed configuration necessary for systematic cross-outcome comparison. The model eschews position embeddings, relying on team-identity information to maintain outcome distinction, and leverages a learnable [CLS] token for aggregation. The classification head—a two-layer MLP with GELU activation—outputs a scalar logit transformed into a decision probability via sigmoid.
A central design principle is architectural symmetry and invariance: side-invariance is explicitly enforced by averaging the model’s output over both possible outcome orderings. The approach ensures the model's preferences and uncertainty estimates respect natural invariances inherent in moral judgment tasks.
The model achieves 77% accuracy on a subset of the aggregated Moral Machine dataset constructed to avoid data leakage between training and validation. This level of accuracy is notably obtained with a deliberately small and interpretable model, highlighting that compact, custom architectures can encode substantial moral competence in trolley-dilemma reasoning (Figure 1).

Figure 1: Overview of the model architecture, dataset, and interpretability methods applied to analyze internal decision processes.
Quantifying Causal Influence of Character Types
To move beyond descriptive probing, the authors employ causal intervention analysis using the DoWhy framework. The average treatment effect (ATE) for each character type is computed, controlling for group size confounders, revealing the direct influence of specific identities on model output. This causal analysis demonstrates the learned moral hierarchy: strong positive effects for Pregnant, Stroller, Girl, and Boy roles (ATEs up to +0.12), and strong negative effects for Criminal, OldWoman, Cat, and Homeless (ATEs down to -0.10). Man and Woman are close to neutral, acting as reference baselines. The magnitude of these effects highlights that character identity alone can alter outcome preference by over 20% of the probability space, independent of utilitarian calculations.
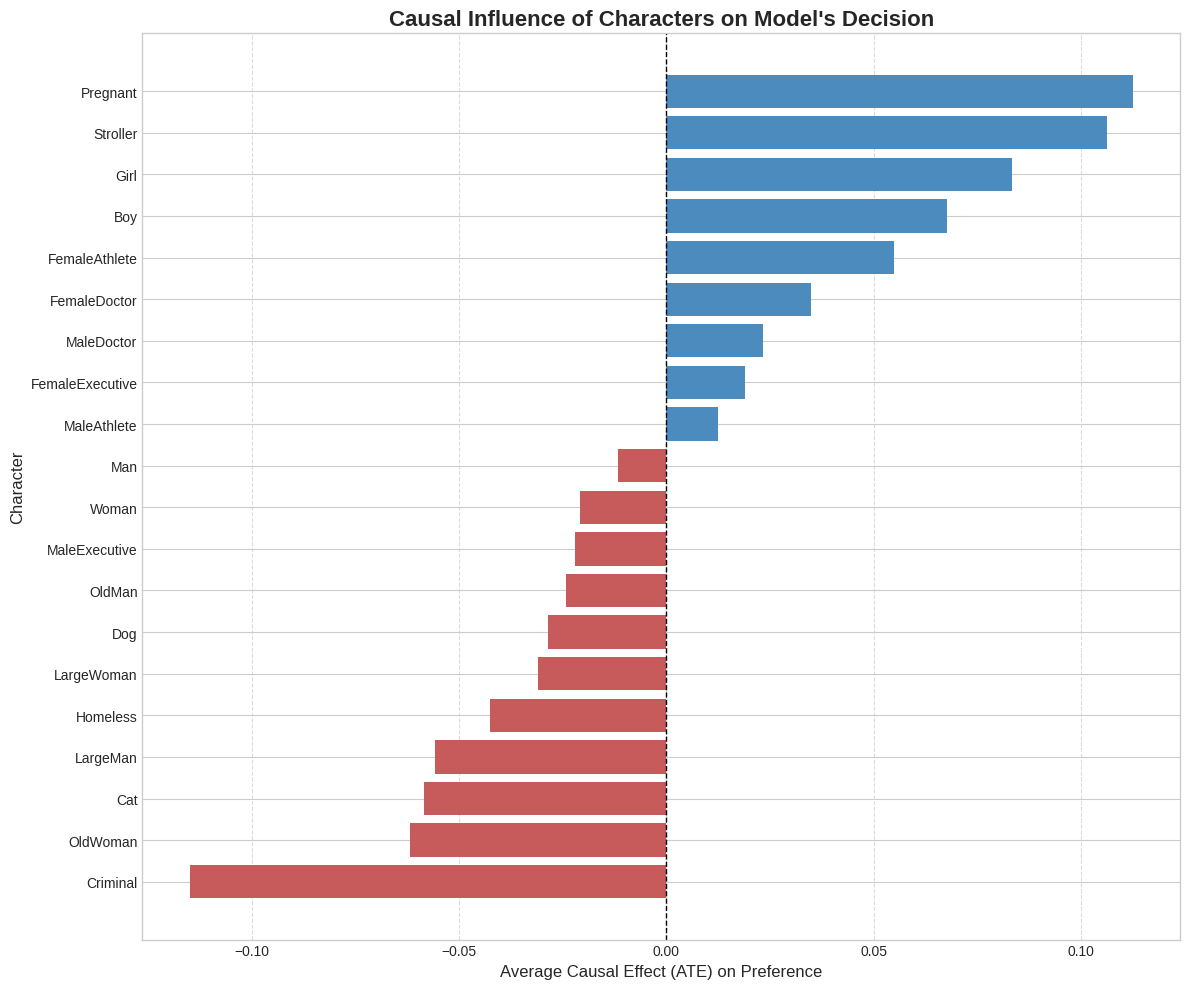
Figure 2: Causal influence of character types, showing sharply positive effects for stereotypically vulnerable classes and negative effects for stigmatized ones.
Layer-wise Attribution and Functional Specialization
The model's shallow but structured architecture enables detailed mechanistic analysis. Attention-weight-based attribution, correlating attentional variance and bias-aligned decisions, exposes the localization of moral biases. Legality bias (Criminal vs. law-abiding) almost exclusively manifests in Layer 0, while species bias (human vs. animal) concentrates in Layer 1. Age and social role biases show differentiated head-level specialization. Layer 0 Head 1 specializes in legality, while Layer 1 Head 1 is tuned to species discrimination.
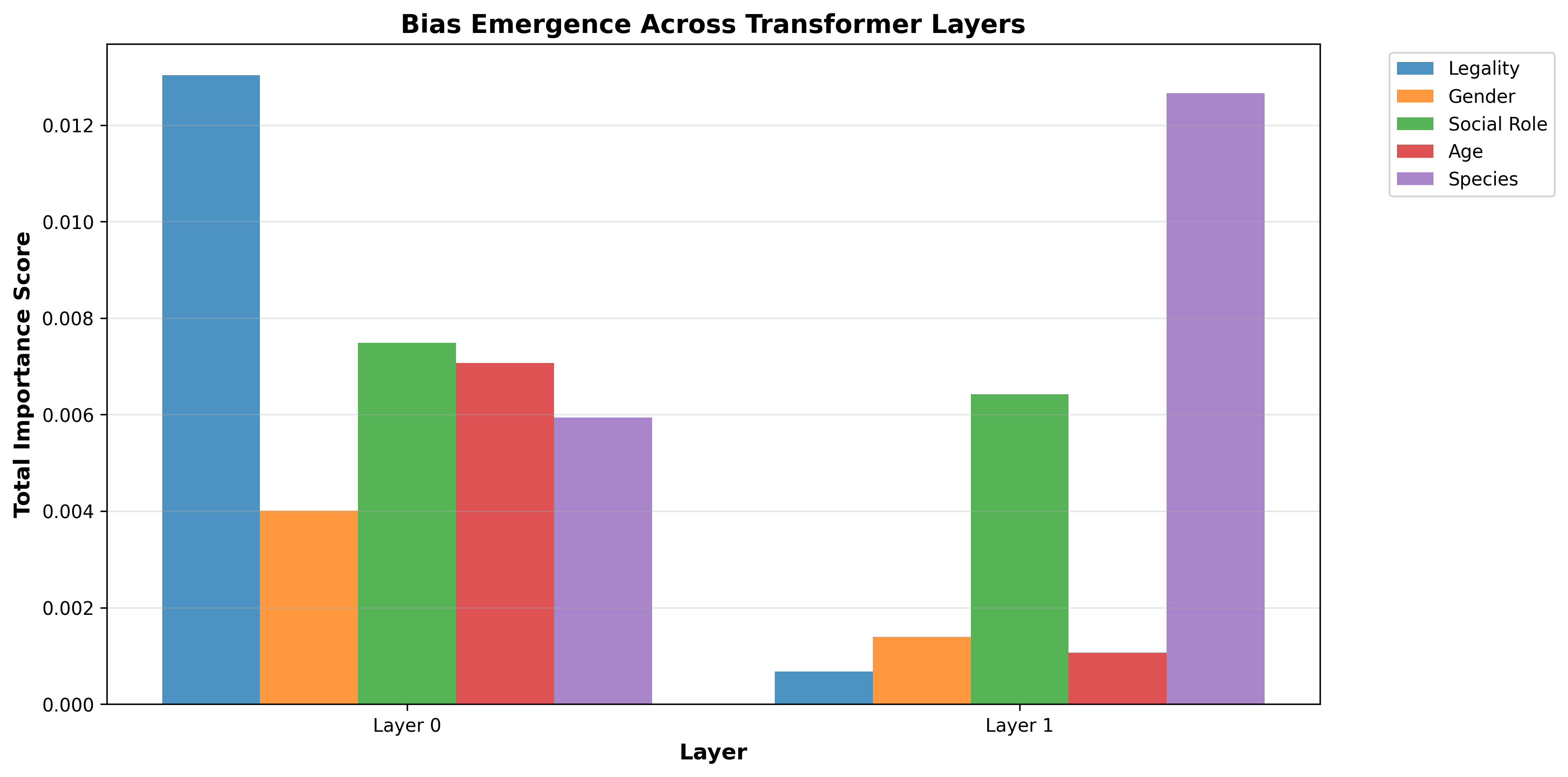
Figure 3: Layer-wise total importance scores for each bias, showing how legality bias is computed early and species bias emerges in deeper layers.
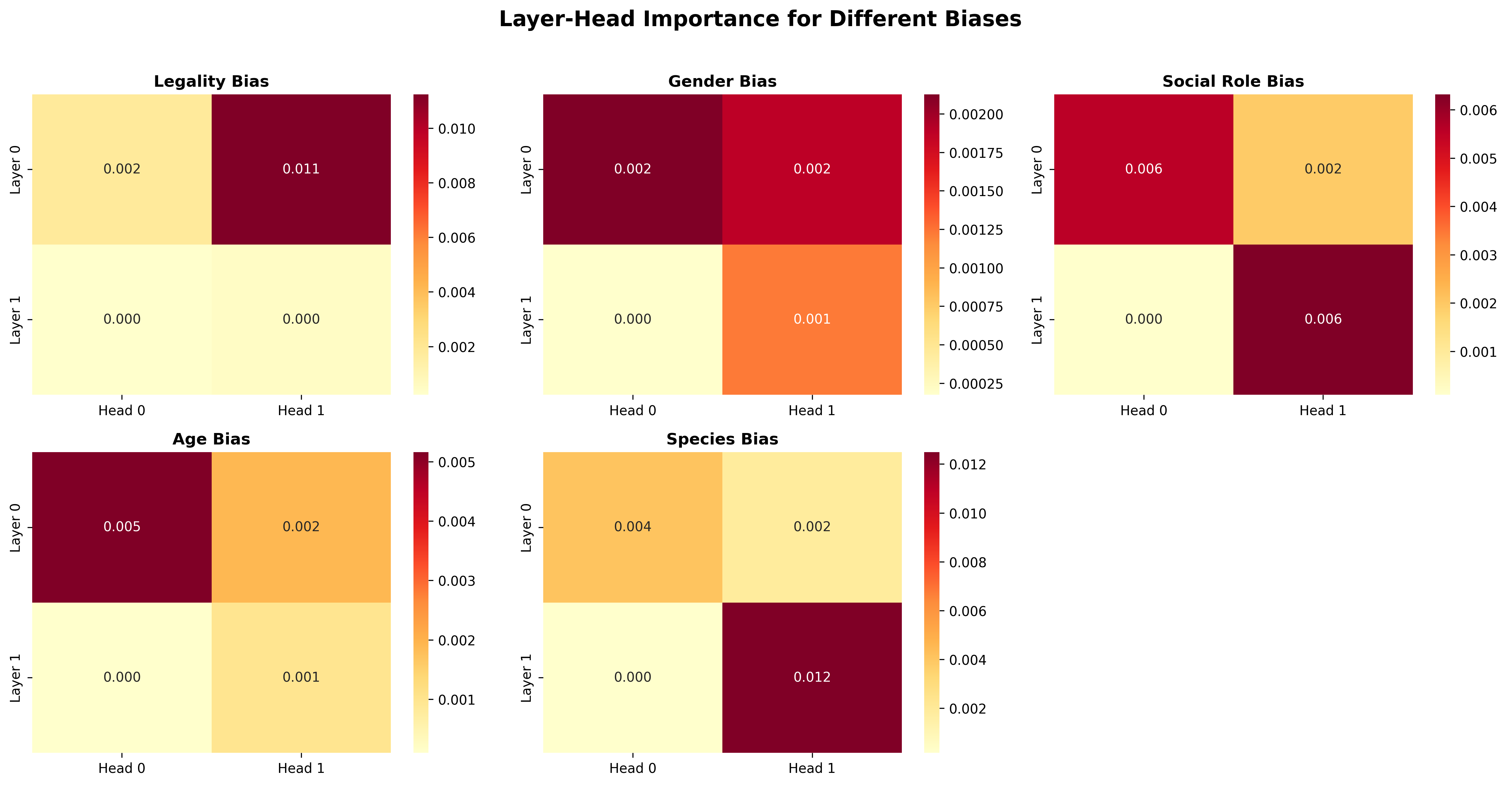
Figure 4: Heatmaps of importance scores for each layer-head combination across bias dimensions, indicating sparse and functionally distinct specialization.
This manifest separation, despite the model’s simplicity, demonstrates that distinct moral computations localize to separate computational stages—affording opportunities for targeted interpretability and potential debiasing via architectural interventions.
Circuit Probing and Causal Subnetwork Identification
The authors extend their analysis through circuit probing, learning sparse binary masks that identify neurons causally responsible for computing intermediate scoring variables that encode the moral hierarchy. Probing the Layer 1 MLP block reveals a strongly sparse circuit (45 out of 256 neurons), achieving over 95% KNN accuracy in reproducing model-derived scores on held-out scenarios. Ablations targeting these identified neurons yield a small but statistically significant reduction in model agreement (1.2 pp), explaining 8.3% of the model's improvement above chance accuracy on the imbalanced test set. These empirical results validate the presence of compact, causally active computational sub-circuits implementing decisive aspects of moral judgment.
Local Relevance and Token-level Explanations
The transformer’s output is further dissected using gradient-weighted attention relevance (following Chefer et al.), attributing decision impact to specific scenario tokens. In scenarios pitting, for example, groups of Men versus Criminals, the Criminal token accounts for a disproportionate share of decision evidence, confirming both global and local alignment with learned moral hierarchies. Contextual features (e.g., CrossingSignal, Intervention) and professional roles have secondary influence, while demographic tokens contribute minimally in contrastive scenarios.
Implications and Future Directions
This work empirically demonstrates that tractable, small transformer models—explicitly engineered to reflect scenario structure and enforce side-invariance—exhibit both high predictive accuracy and amenability to mechanistic analysis in moral decision-making tasks. The correlation of model biases with distinct subcircuits and attention heads opens a plausible path to targeted debiasing interventions and a firmer scientific understanding of how neural models internalize and propagate human moral distinctions.
However, reliance on aggregate human preferences introduces the risk of encoding social biases, necessitating caution in model deployment and analysis. The compactness and transparency of these custom models offer promising avenues for auditing and ultimately modifying AI moral reasoning. Extensions to more complex scenarios or architectures (e.g., larger LLMs) could build on these interpretability foundations, enabling both scalable ethical decision-making and deeper insights into value alignment and societal norm internalization in AI systems.
Conclusion
The study establishes an interpretable foundation for moral judgment modeling, combining structured scenarios, architectural invariance, and layered interpretability analyses. It quantifies and localizes biases at causal, layer, subcircuit, and token levels within a controllable transformer, providing a reference approach for principled, transparent, and auditable AI alignment with human ethical preferences.