- The paper introduces an attention-enhanced graph network and Graph-VAE that improves 3D scene reconstruction from RGB sequences.
- It leverages semantic scene graphs with multi-head attention and deep fusion of shape and layout features for spatially coherent outcomes.
- Experimental results reveal superior recall, layout consistency, and 25x faster inference compared to diffusion-based methods in AR/MR scenarios.
SceneLinker: Compositional 3D Scene Generation via Semantic Scene Graphs from RGB Sequences
Introduction and Motivation
SceneLinker presents a comprehensive framework for compositional 3D scene generation by leveraging semantic scene graphs constructed directly from RGB sequences. Motivated by the increasing demand for spatially consistent and semantically rich virtual representations in AR/MR settings, the method addresses fundamental limitations in prior works: insufficient utilization of object-level relationships for detailed and interactive scene modeling and the challenge of producing coherent, layout-aligned 3D scenes in complex, cluttered environments. SceneLinker’s pipeline is characterized by an attention-enhanced graph network for robust 3D scene graph prediction and a novel graph-based VAE (Graph-VAE) architecture that integrates object shapes and spatial layouts, producing 3D reconstructions that faithfully reflect real-world arrangements.
Methodology
Semantic Scene Graph Prediction
SceneLinker’s first phase is incremental 3D scene graph construction from RGB sequences. This stage uses Visual-SLAM for multi-view entity segmentation and computes joint node and edge features representing object-level semantics and geometric relations. A Cross-Check Feature Attention (CCFA) network forms the core of scene graph prediction, where attention weights are computed by simultaneously considering both source and target nodes and their connecting edges. Multi-head attention, modeled after Transformer architectures, enables robust propagation of relational semantics, and GRUs facilitate iterative message refinement, accommodating incremental updates as the user scans the environment.
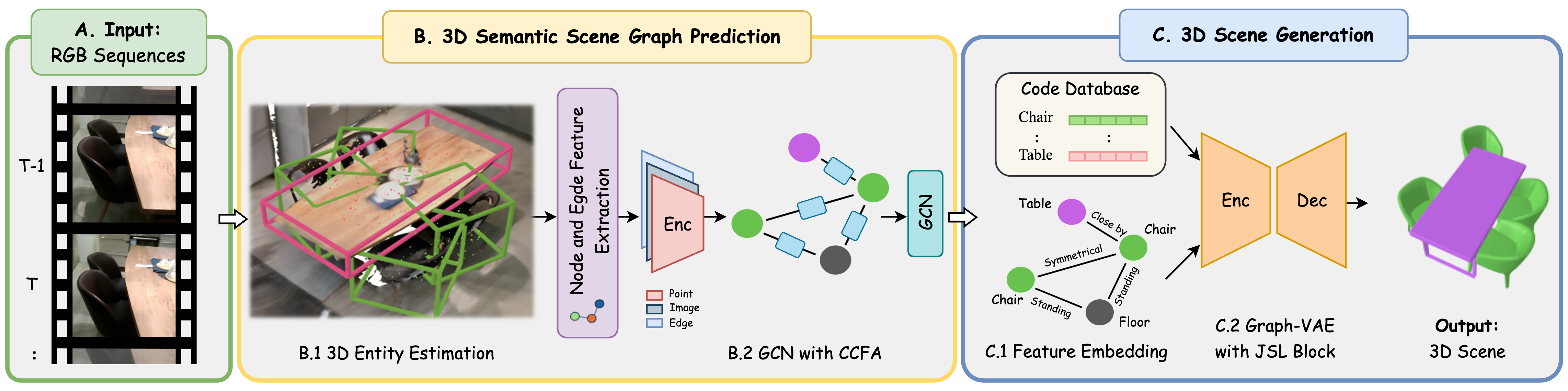
Figure 1: Pipeline overview—input RGB sequences yield incremental 3D entities, which are used to construct node and edge features, predict the global scene graph, and finally generate the compositional 3D scene via GCN-based VAE.
Semantic information is fused across temporal frames through a moving average fusion strategy, ensuring stability and consistency in the constructed global scene graph even under occlusions or partial observations. This graph encodes the physical and semantic arrangement of objects, serving as an explicit, compact data structure for downstream virtual scene generation.
Compositional 3D Scene Generation
The second stage utilizes the predicted scene graph and associated bounding box information to drive a novel graph-VAE. Each node embeds CLIP-enhanced contextual features and a shape code generated via DeepSDF, while oriented bounding boxes encode layout. The core innovation is the Joint Shape and Layout (JSL) block within a DeepGCN-based architecture, which fuses shape and layout features for each object node through both additive interaction and layout-centric refinement. This design empirically prioritizes positional accuracy over fine-grained geometry when synthesizing scenes, facilitating robust 3D scene generation that aligns with the real-world spatial context.
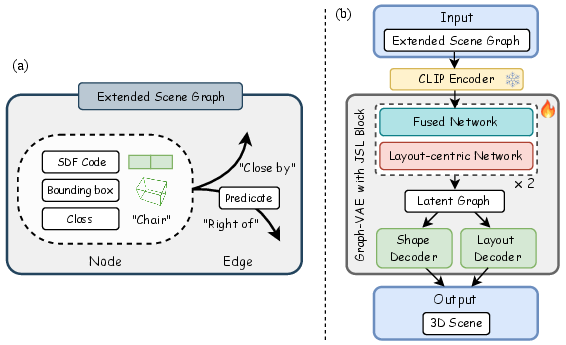
Figure 2: (a) Illustration of the extended scene graph with additional shape priors; (b) architecture of the graph-based VAE encoder/decoder employing JSL blocks.
The full process enables encoding of the scene graph into a latent representation from which shapes and layouts are decoded in parallel. Every generated mesh is transformed using the predicted bounding box, ensuring spatial consistency, and final reconstructions support mesh-based manipulation vital for interactive MR/AR applications.
Experimental Results
On the 3RScan/3DSSG datasets, SceneLinker consistently achieves superior recall and mean recall on both small (20 objects, 8 predicates) and large-scale settings (160 objects, 26 predicates), outperforming state-of-the-art baselines such as MonoSSG and SGFN. Improvements are particularly pronounced on metrics sensitive to object-predicate diversity and data imbalance, demonstrating the robustness of the CCFA network in cluttered indoor settings.
3D Scene Generation Consistency
When evaluated on the SG-FRONT dataset, SceneLinker’s graph-based VAE demonstrates competitive accuracy on layout-centric (easy) relationship constraints (left/right, front/behind, etc.), and crucially, it outperforms prior methods on more complex relationships (close by, symmetrical) by margins exceeding 7% and 14%, respectively. These hard constraints are paramount in ensuring visually plausible and semantically consistent virtual environments, reflecting SceneLinker’s focus on comprehensive scene graph supervision.
Figure 3: Qualitative comparisons for challenging scene graph constraints, highlighting correct (green) and incorrect (red) object arrangements against the input graph.
Qualitative results indicate SceneLinker yields more contextually aligned and visually complete scenes compared to retrieval-based and graph-diffusion models, particularly in capturing nuanced geometric arrangements and minimizing artifacts from collision or overlap.

Figure 4: Visualization of the real scene (top, rendered as point clouds) and the generated virtual scene (bottom), illustrating accurate preservation of global arrangement in SceneLinker’s outputs.
Runtime Considerations
The model also addresses a key bottleneck in practical deployment: inference speed. SceneLinker achieves 3D scene generation in approximately 1s per scene, over 25 times faster than diffusion-based counterparts (e.g., CommonScenes, EchoScene), positioning it as a viable solution for time-constrained AR/MR interactions.
Applications and Limitations
SceneLinker is engineered for direct deployment in MR/AR scenarios, supporting collaborative editing, remote spatial sharing, and interaction-rich content creation, thanks to its mesh-based, manipulable output geometry.

Figure 5: SceneLinker’s deployment in MR environments enables collaborative AR/VR applications, such as remote spatial sharing and scene editing.
Despite its robust design, the framework remains limited by reliance on precise oriented bounding box estimation. Instabilities in layout prediction due to occlusion or poor segmentation may propagate as structural inaccuracies in reconstructed scenes.

Figure 6: Scene generation can fail when bounding box features are highly unstable or misaligned, leading to spatial inconsistencies in object arrangement.
Additionally, mesh diversity is constrained by the classes present in the 3D-FRONT dataset, restricting generalization to unseen/complex object categories.
Theoretical and Practical Implications
SceneLinker demonstrates that scene graph-centric representations, when combined with attention-driven graph neural architectures and explicit shape/layout fusion, are highly effective for real-world, context-consistent 3D scene generation. The model's architectural advances—especially the CCFA and JSL block—set a paradigm for leveraging object-centric priors and relationship reasoning at scale, offering a tractable and efficient alternative to computationally expensive diffusion-based systems. This benefits not only AR/MR content pipelines, but also broader domains such as robotics, spatial understanding, and collaborative virtual environment authoring.
The experiments reinforce the importance of hard relational constraints in evaluating scene generation fidelity, suggesting that benchmarks and future models should more explicitly incorporate structurally challenging graph relationships for comprehensive assessment.
Looking forward, integration of open-vocabulary shape embeddings, improved bounding box estimation through multimodal sensor fusion, and user-guided, texture-aware post-processing are promising directions. SceneLinker’s design principles may further catalyze research toward seamless, real-time bridging of physical and virtual spatial experiences.
Conclusion
SceneLinker advances the field of 3D scene generation by establishing a robust, attention-driven framework for reconstructing layout- and relation-aware scenes from RGB input. The strong numerical results on both standard and challenging metrics, fast inference speed, and demonstrated MR/AR applicability underscore its practical impact and provide a new foundation for scene graph-based real-virtual integration. Future enhancements to object diversity, texture fidelity, and user-centric evaluation can extend SceneLinker's role as a backbone for comprehensive spatial interaction frameworks.