Zonkey: A Hierarchical Diffusion Language Model with Differentiable Tokenization and Probabilistic Attention
Abstract: LLMs have revolutionized natural language processing, yet they remain constrained by fixed, non-differentiable tokenizers like Byte Pair Encoding (BPE), which hinder end-to-end optimization and adaptability to noisy or domain-specific data. We introduce Zonkey, a hierarchical diffusion model that addresses these limitations through a fully trainable pipeline from raw characters to document-level representations. At its core is a differentiable tokenizer (Segment Splitter) that learns probabilistic beginning-of-sequence (BOS) decisions, enabling adaptive splits that emerge as linguistically meaningful (e.g., word boundaries at spaces, sentence starts at periods) without explicit supervision. This differentiability is enabled by our novel Probabilistic Attention mechanism, which incorporates position-specific existence probabilities to simulate soft masking over theoretically infinite sequences while preserving gradients. Sequences decay probabilistically rather than relying on end-of-sequence tokens, supporting variable-length outputs. Hierarchical levels compress sequences into higher abstractions (e.g., character n-grams to word-like vectors, then sentence-like), with reconstruction via our Denoising Diffusion Mixed Model (DDMM) for stable and efficient denoising in latent space. A Stitcher ensures overlap invariance across segments. Trained end-to-end on Wikipedia, Zonkey generates coherent, variable-length text from noise, demonstrating emergent hierarchies and promising qualitative alignment to data distributions compared to entropy-based learnable tokenizers. Our approach advances toward fully gradient-based LLMs, with potential for better domain adaptation and scalable generation. We release the source code for training and reproducing our experiments.

Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Overview
This paper introduces Zonkey, a new kind of LLM that learns to understand and generate text without relying on fixed rules for chopping text into “tokens” (like words or subwords). Instead, it learns everything end-to-end—from raw characters up to sentence-like meanings—using a system that can be trained directly. Zonkey combines a smart way of splitting text, a method to compress information, and a diffusion process that can generate new text that varies in length naturally.
Key Questions the Paper Tries to Answer
- Can we build a LLM that learns how to split text into meaningful pieces (like words and sentences) by itself, rather than using fixed rules?
- Can we keep everything “differentiable,” meaning all parts can be trained together using gradients, which helps the model adapt to new or messy data?
- Can we use diffusion (a method often used in image generation) to make text from scratch, even though text is usually made of discrete symbols?
- Can a model handle variable-length text gracefully without special “end-of-sequence” markers?
How Zonkey Works (In Everyday Terms)
1) Learning Where to Cut: The Segment Splitter
Imagine reading a long paragraph and deciding where words and sentences begin. Most models use fixed rules to split text, like always breaking at spaces. Zonkey’s Segment Splitter learns where to start segments using probabilities. It doesn’t hard-cut; it softly decides, “This spot is likely the start of something.” Because these decisions are soft (probabilistic), the model can be trained end-to-end, improving its splits as it learns.
A key idea is “existence probabilities.” Think of walking along a path with a flashlight that slowly dims. As you move forward, the chance that later positions are still part of the segment gets smaller. This lets Zonkey treat sequences as potentially very long and gently fade out parts that don’t matter, instead of abruptly stopping at a special end token.
2) Paying Attention Smartly: Probabilistic Attention
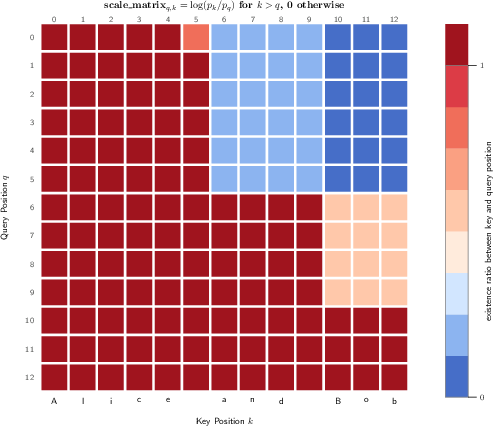
“Attention” helps a model decide which parts of the text matter most for understanding the current part. Zonkey’s Probabilistic Attention reduces attention to parts of the sequence that are less likely to exist (those dimmer flashlight areas). This acts like a soft mask: the model naturally focuses on more reliable positions, but stays trainable because there’s no hard cutoff.
3) Summarizing Segments: The Compressor
Each segment (a chunk of characters) is turned into a small set of summary vectors—like making a short “note” that captures the meaning of that chunk. These summary vectors represent higher-level ideas (word-like or sentence-like). The model uses masked-language-style training (guessing missing parts) so these summaries capture meaning, not just surface detail.
4) Generating and Reconstructing: DDMM (Denoising Diffusion Mixed Model)
Diffusion is like starting with noisy “static” and cleaning it step-by-step into clear output. DDMM blends two styles:
- Careful small steps when the model isn’t sure (safer, more stable).
- Bold jumps when the model is confident (faster, more direct). This balance helps the model turn summary vectors back into detailed text that reads well, and it supports variable-length outputs without fixed ends.
5) Sewing Pieces Back Together: The Stitcher
Because Zonkey creates overlapping segments, the Stitcher “sews” them into a full, smooth document. It gently blends overlaps so the final text is coherent. This stitching is also differentiable, so training signals can flow backward and improve earlier components (like the Splitter).
Main Findings and Why They Matter
- Emergent boundaries: Without being explicitly told where words or sentences begin, the model learned to place segment starts at natural spots (like spaces for words, periods for sentences).
- Coherent text from noise: Trained on Wikipedia (even on a single GPU), Zonkey can generate sentences that look and feel coherent starting from random noise.
- Variable-length generation: By using existence probabilities, the model doesn’t need special end tokens and can produce text that naturally stops when it should.
- Fully trainable pipeline: Because the tokenizer is differentiable, the entire system can be trained together, which can help it adapt to different domains or noisy data better than fixed-rule tokenization.
- Promising compared to other learnable tokenizers: Qualitatively, Zonkey’s adaptive splitting and hierarchical approach align better with meaningful structure than methods that rely on simple heuristics like equal entropy per chunk.
What This Could Mean Going Forward
- Better adaptability: Models that learn their own “tokens” can handle different kinds of texts—like technical jargon, slang, or noisy inputs—more flexibly.
- Scalability for long texts: Generating at higher levels (sentences and paragraphs) in parallel could make long-form text generation faster and more efficient than token-by-token methods.
- Fewer rigid rules: Moving away from fixed tokenizers may lead to LLMs that are easier to train end-to-end and that naturally discover useful linguistic units.
- Stronger domain performance: Fully gradient-based systems can fine-tune their segmentation and representations for specific tasks or fields, potentially improving accuracy and robustness.
In short, Zonkey is a step toward LLMs that learn from raw text in a more human-like, flexible way—deciding for themselves where words and sentences begin, compressing meaning, and generating coherent, variable-length text through a balanced diffusion process.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a consolidated list of concrete gaps and unresolved questions that future work could address:
- Lack of quantitative evaluation: No standardized metrics (e.g., negative log-likelihood, perplexity proxies, compression ratio, segmentation F1 vs whitespace/punctuation, MAUVE, human eval protocols) are reported; a rigorous benchmark suite is missing to compare Zonkey against autoregressive LMs, ByT5/CANINE/BLT, and diffusion LMs.
- Inference speed and compute comparisons: Claims of favorable parallelism are not substantiated with wall-clock benchmarks against strong baselines across sequence lengths and hierarchy depths; cost breakdowns per module (Splitter/Compressor/DDMM/Stitcher) are absent.
- Scalability to long documents: Although “theoretically infinite,” training truncates segments to max_seq_len; the practical memory/time complexity and quality scaling for multi-page documents remains untested.
- Cross-level error propagation: How denoising or segmentation errors compound across levels (e.g., character→word→sentence) is not quantified; mitigation strategies (e.g., iterative refinement, cross-level consistency losses) are not explored.
- Train–test mismatch in splitting: Training uses stochastic BOS sampling while inference uses a hard threshold (p_BOS > 0.5); the impact of this discrepancy on calibration, stability, and quality is unmeasured.
- Gradient adequacy through non-differentiable decisions: The approach relies on indirect gradients via Probabilistic Attention rather than explicit relaxations (e.g., straight-through, Gumbel-Softmax, REINFORCE with baselines); it is unclear whether this provides sufficient and unbiased credit assignment to BOS predictors.
- Sensitivity to BOS threshold and calibration: No analysis of how thresholding p_BOS or existence-probability calibration affects length control, truncation errors, or over-/under-segmentation across domains and languages.
- Segment length regularization trade-offs: The penalties for “short” and “long” segments are described, but their ablation, tuning methodology, and effects on compression quality and reconstruction are not presented.
- Existence probability design and independence assumptions: p_k is defined as P(k exists | all prior exist); whether this factorization is expressive enough (vs. learned non-Markovian termination) or leads to pathological decays is untested.
- Numerical stability of cumulative products: Existence probabilities and shares rely on long cumulative products of (1 − p_BOS); underflow, gradient saturation, and the need for log-space tricks or clamping are not analyzed.
- Probabilistic Attention theory and alternatives: The log(p_k/p_q) score adjustment is proposed without formal guarantees (e.g., on optimization stability, variance, or softmax calibration) or comparisons to soft masking baselines and head-wise variants.
- Effect on attention interpretability and head diversity: It is unknown whether existence scaling reduces head redundancy or causes collapse; no head-level analyses are provided.
- MLM objective design at latent level: The contrastive MLM over latent vectors (rather than token vocabulary) is novel but under-specified; its efficacy vs. standard reconstruction/regression or InfoNCE variants lacks ablation.
- Collapse-prevention loss side effects: Enforcing near-zero cosine similarity across documents may suppress beneficial semantic clustering (e.g., paraphrases); trade-offs are not studied.
- DDMM specifics and guarantees: The mixed-step objective is described qualitatively; formalization of its relation to DDPM/DDIM, convergence properties, and sensitivity to noise schedules or step counts T is missing.
- Denoiser–compressor loop stability: The repeated decompress–denoise–recompress cycle could drift; no diagnostics on fixed points, cycle consistency, or failure modes are reported.
- Termination/length control: Truncation by p_exist < ε is heuristic; calibration, length controllability (e.g., target lengths), and failure cases (premature cutoff or runaway tails) are not evaluated.
- Stitcher ground-truth offsets: Training uses “ground-truth offsets,” but it is unclear how these are derived when splits are stochastic; robustness in ambiguous or repetitive overlaps is not assessed.
- Stitcher failure modes: Risks of content bleeding, duplication, or inconsistent overlap reconciliation are not quantified; no comparisons to simple overlap-averaging or constrained decoding are provided.
- Overlap invariance guarantees: The extent to which stitched representations are invariant to the choice of overlap and BOS density lacks formal tests or proofs.
- Resource and reproducibility details: Model sizes, parameter counts per module, optimizer settings, schedules, and training budgets are insufficiently specified for faithful reproduction and scaling studies.
- Domain robustness claims: Assertions about better handling of noise and domain shift are qualitative; evaluations on OCR/text-noise benchmarks, specialized domains (code, biomedical), or adversarial perturbations are absent.
- Multilingual and non-segmented scripts: The emergence of meaningful boundaries is only discussed for English; performance and segmentation behavior in languages without whitespace (e.g., Chinese, Japanese), morphologically rich languages, or mixed-script corpora are untested.
- Code-switching and non-linguistic text: How splitting and compression behave on code, math, tables, or emoji-rich content is unknown.
- Downstream utility: Whether Zonkey’s latent representations benefit classification, retrieval, or QA (zero/few-shot) is not evaluated, limiting practical impact assessment.
- Comparison to learned tokenizers: No direct head-to-head with Unigram/SentencePiece, WordPiece, BLT’s entropy objectives, or other differentiable segmenters on segmentation quality and downstream performance.
- Hyperparameter robustness: Sensitivity of quality to num_compression_vectors, max_seq_len, ε thresholds, and loss weights (w_l) is not explored.
- Autoregressive decoder capacity: The “lightweight” 1–2 layer downward transformer may bottleneck decompression; ablations with deeper decoders are missing.
- Alignment between latent and surface text: The final mapping from continuous reconstructions to characters (level-0 token loss) is not fully specified for generation; decoding fidelity and error types are not analyzed.
- Safety and controllability: No experiments on toxicity, instruction following, or guided generation (e.g., classifier-free guidance in latent space) are provided.
- Data leakage and memorization risks: Given end-to-end training from characters, memorization and privacy concerns are not evaluated.
- Theoretical connection to likelihood: There is no derivation connecting the training objectives to a tractable likelihood or ELBO, complicating principled model comparison.
- Memory footprint with overlaps: Overlapping segments increase compute/memory; efficiency strategies (e.g., dynamic overlap, sparse attention) and their accuracy trade-offs are not examined.
- Curriculum over hierarchy depth: The schedule for advancing levels, freezing/unfreezing modules, and its impact on stability and final quality lacks detail and ablations.
- Robustness to repetition and long dependencies: How the model handles repeated phrases, coreference, and discourse-level coherence across stitched segments is unmeasured.
- Failure case taxonomy: The paper does not catalog typical errors (e.g., truncation artifacts, overlap inconsistencies, semantic drift) or propose diagnostics to detect and mitigate them.
Practical Applications
Immediate Applications
The following list outlines practical uses that can be deployed now, leveraging the released source code and the demonstrated sentence-level capabilities on Wikipedia-scale training.
- Adaptive tokenizer discovery for niche corpora
- Sectors: healthcare, legal, finance, software localization
- Tool/Product/Workflow: train the Segment Splitter on domain-specific text to learn context-aware splits (e.g., medical abbreviations, legal citations) and export the learned segmentation as a plug-in preprocessor for existing Transformer pipelines
- Assumptions/Dependencies: requires domain-corpus fine-tuning; integration layer to map learned segments to downstream models; quality assessment versus BPE is necessary; current model stability demonstrated at sentence-level
- Noisy text preprocessing for OCR/ASR/social media
- Sectors: software, education, media
- Tool/Product/Workflow: use probabilistic BOS and existence probabilities to detect word/sentence boundaries and normalize noisy inputs (typos, missing punctuation); apply denoising to improve readability of transcripts and scans before downstream tasks
- Assumptions/Dependencies: needs fine-tuning on noisy-domain data; output quality depends on training distribution similarity; human-in-the-loop recommended
- Sentence-level infilling for editorial workflows
- Sectors: media, content platforms, education
- Tool/Product/Workflow: plug Zonkey’s decompression/denoising loop into an editor to fill missing sentences or refine partial drafts with variable-length generation and soft truncation
- Assumptions/Dependencies: current capabilities are sentence-level; performance on long-form content is limited; editorial review required
- Hierarchical embeddings for retrieval and clustering
- Sectors: search/retrieval, data engineering, enterprise knowledge management
- Tool/Product/Workflow: use the Compressor to produce word-/sentence-like vectors for indexing, clustering, deduplication, and semantic search; combine with in-batch contrastive objectives to improve separation
- Assumptions/Dependencies: embeddings reflect training corpus; evaluation and calibration needed for specific domains; consider privacy/bias implications in latent spaces
- Long-context chunk stitching library
- Sectors: software infrastructure, LLM tooling
- Tool/Product/Workflow: integrate the Segment Stitcher as a differentiable reassembly module in long-context pipelines to reduce boundary artifacts across overlapping chunks
- Assumptions/Dependencies: requires adaptation to non-Zonkey encoders/decoders; depends on having existence probabilities or analogous confidence scores
- Research prototyping platform for differentiable tokenization and probabilistic attention
- Sectors: academia, applied research labs
- Tool/Product/Workflow: reproduce experiments; benchmark against byte/character-level baselines; test curriculum strategies and diffusion schedules; study emergent boundary phenomena
- Assumptions/Dependencies: GPU access; custom evaluation metrics (non-token-based) needed; scaling will affect conclusions
- Code-mixed and multilingual preprocessing
- Sectors: localization, translation, multilingual NLP
- Tool/Product/Workflow: apply the Splitter to learn splits that adapt to mixed scripts and languages without fixed vocabularies; feed hierarchical vectors into multilingual encoders
- Assumptions/Dependencies: training on multilingual/codemixed corpora is required; compatibility with downstream multilingual models must be validated
- Dataset diagnostics via existence shares and uncertainty hotspots
- Sectors: data engineering, dataset curation, ML ops
- Tool/Product/Workflow: use existence shares and reconstruction losses to flag high-entropy or anomalous regions (e.g., passwords, garbled text) for curation or redaction
- Assumptions/Dependencies: heuristics require calibration; not a substitute for formal PII detection; depends on training loss instrumentation
- Teaching modules for ML courses
- Sectors: academia, online education
- Tool/Product/Workflow: course labs on differentiable tokenization, soft/probabilistic masking, hierarchical diffusion, overlap stitching
- Assumptions/Dependencies: students need basic PyTorch/JAX skills; small-scale datasets sufficient for demonstration
Long-Term Applications
The following use cases require further research, scaling, or engineering (e.g., deeper hierarchies, larger training runs, standardized evaluation, and robust safety controls).
- Fully end-to-end differentiable LLMs (no fixed tokenizer)
- Sectors: software, cloud AI platforms
- Tool/Product/Workflow: production frameworks where segmentation, compression, denoising, and generation are trained jointly from raw characters/bytes
- Assumptions/Dependencies: substantial compute for multi-level hierarchies; rigorous benchmarks to demonstrate parity with SOTA; robust safety and evaluation protocols
- Domain-adapted enterprise models with on-the-fly tokenization
- Sectors: healthcare, legal, finance, customer support
- Tool/Product/Workflow: fine-tune the Splitter+Compressor on proprietary corpora to capture domain-specific boundaries and semantics; deploy as internal LLMs for drafting, analysis, and QA
- Assumptions/Dependencies: data governance and privacy; controllability and auditability of learned splits; risk management for generative outputs
- Parallel long-form generation with hierarchical diffusion
- Sectors: media, technical documentation, education
- Tool/Product/Workflow: generate paragraphs and documents by processing compression vectors in parallel at higher levels (paragraph/document) for faster long-form synthesis
- Assumptions/Dependencies: deeper hierarchical training; improved denoiser stability; human oversight and editorial standards
- Streaming event/time-series modeling using Probabilistic Attention
- Sectors: energy (sensor data), finance (tick data), cybersecurity (logs), IoT
- Tool/Product/Workflow: adapt existence probabilities to irregular, potentially infinite sequences; soft truncation for streams; anomaly detection with hierarchical representations
- Assumptions/Dependencies: extension beyond text to numerical/event data; task-specific decoders; evaluation on streaming benchmarks
- On-device robust keyboards and assistants for noisy text
- Sectors: mobile, accessibility
- Tool/Product/Workflow: small hierarchical models that handle typos, spacing, and punctuation; variable-length suggestions; code-mixed input support
- Assumptions/Dependencies: compression to edge-friendly sizes; distillation from larger Zonkey-style models; privacy-preserving on-device inference
- Content moderation and anti-obfuscation analysis
- Sectors: policy, social platforms, safety
- Tool/Product/Workflow: adaptive tokenization to handle obfuscated or adversarial text; hierarchical embeddings for intent detection in noisy or stylized content
- Assumptions/Dependencies: careful fairness and bias checks; adversarial robustness evaluations; human review pipelines
- Semantic compression and archival
- Sectors: cloud storage, enterprise records management
- Tool/Product/Workflow: store documents as hierarchical latent codes with reversible reconstruction and semantic indexes; speed up search and reduce storage
- Assumptions/Dependencies: fidelity guarantees; compression ratios versus cost trade-offs; legal and compliance considerations for lossy reconstruction
- Hierarchy-aware RAG (retrieval-augmented generation)
- Sectors: enterprise search, knowledge assistants
- Tool/Product/Workflow: use learned splits to produce semantically aligned chunks; stitch retrieved segments with existence-aware blending; improve context coherence in generation
- Assumptions/Dependencies: integration with vector databases; end-to-end evaluation; compatibility with existing RAG stacks
- Byte-level program synthesis and code modeling
- Sectors: developer tools, cybersecurity
- Tool/Product/Workflow: model code and binaries without fixed token vocabularies; detect patterns in obfuscated or minified code; variable-length generation for code templates
- Assumptions/Dependencies: large-scale code corpora; domain-specific evaluation (tests, compiles); safety controls to avoid insecure code patterns
- Clinical text normalization and EHR note processing
- Sectors: healthcare
- Tool/Product/Workflow: adaptive segmentation for medical jargon; variable-length denoising to clean notes and align sections; downstream support for coding and summarization
- Assumptions/Dependencies: HIPAA-compliant workflows; clinician-in-the-loop validation; training on healthcare-specific datasets
Glossary
- atanh transformation: A mathematical transformation using the inverse hyperbolic tangent to stabilize or reshape similarity scores in contrastive objectives. "We use an transformation and in-batch negatives, similarly to how we compute our MLM compressor loss."
- autoregressive decompression: A decoding process that generates outputs sequentially, each step conditioned on previously generated elements, used here for expanding compressed representations. "In causal decoders (used for autoregressive decompression), the scaling aligns with the masking:"
- Beginning-of-sequence (BOS): A marker or decision indicating the start of a new segment or token, here learned probabilistically by the tokenizer. "learns probabilistic beginning-of-sequence (BOS) decisions, enabling adaptive splits"
- Bidirectional encoders: Transformer encoders that attend to both past and future positions in a sequence to build contextual representations. "In bidirectional encoders, the mechanism is applied to all position pairs without causality constraints"
- Byte Pair Encoding (BPE): A common subword tokenization algorithm that merges frequent byte or character pairs to form a fixed vocabulary. "fixed, non-differentiable tokenizers like Byte Pair Encoding (BPE)"
- Causal decoders: Decoder architectures that enforce future masking to preserve causality, generating tokens left-to-right. "In causal decoders (used for autoregressive decompression), the scaling aligns with the masking:"
- CLS vectors: Learnable classification/summarization vectors prepended to sequences to aggregate information, akin to BERT’s [CLS] token. "we prepend (a hyper-parameter, e.g., 4) learnable classification (CLS) vectors to the input."
- Contrastive cosine similarity: A training objective that pulls similar representations together and pushes dissimilar ones apart using cosine similarity and negative samples. "Contrastive cosine similarity (with in-batch negatives and transformation) between denoised segments and ground-truth inputs."
- Cross-attention: An attention mechanism where one sequence attends to another, used here to refine overlaps between segments. "via constrained cross-attention."
- denoising autoencoder: A model trained to reconstruct clean inputs from noised versions, improving robustness and representation quality. "training precise recovery akin to a denoising autoencoder~\citep{vincent2008extracting}."
- Denoising Diffusion Implicit Models (DDIM): A class of diffusion models enabling faster, more deterministic sampling by skipping steps. "Denoising Diffusion Implicit Models (DDIM; \cite{song2021denoising})."
- Denoising Diffusion Mixed Model (DDMM): The paper’s hybrid diffusion approach that balances small stochastic steps with larger deterministic leaps for efficient denoising. "with reconstruction via our Denoising Diffusion Mixed Model (DDMM) for stable and efficient denoising in latent space."
- Denoising Diffusion Probabilistic Models (DDPM): Diffusion models that iteratively denoise data with small stochastic steps, yielding high-fidelity samples. "Denoising Diffusion Probabilistic Models (DDPM; \cite{ho2020denoising})"
- Diffusion-based generation: Generating data by reversing a noise-adding process, iteratively denoising from noise to signal. "Diffusion-based generation, while powerful for images, struggles with text due to discrete tokens"
- energy-based variants: Generative modeling approaches that use energy functions to define data distributions or preferences. "as well as energy-based variants \citep{nvidia2025edlm}."
- existence probabilities: Position-wise probabilities indicating whether sequence positions “exist,” enabling soft variable-length handling. "with each position assigned an existence probability "
- Existence shares: Normalized weights that distribute loss across overlapping segments so each original position contributes uniformly. "Existence shares: For each position in the original sequence, a per-segment weight tensor where the position appears, normalized such that shares sum to 1 across all overlapping segments containing it."
- Gaussian perturbations: Adding Gaussian noise to simulate diffusion steps or augment data for robustness. "Dirty: after large accumulated noise (simulating multi-step diffusion via Gaussian perturbations~\citep{song2021denoising}) and denoising"
- Gumbel-Softmax: A differentiable approximation for sampling from categorical distributions, often used to relax discrete choices. "Note that alternatives like Gumbel-Softmax~\citep{jang2017categorical} would not suffice here, as the hard choice"
- hard masking: Applying masks that fully block attention to certain positions, typically for padding or causality. "a generalization of traditional hard masking: if cumulative existence probabilities drop sharply from 1 to 0 (or ), it yields equivalent results to conventional masking."
- Hierarchical Diffusion LLMs (HDLM): Diffusion-based LMs that incorporate hierarchy, e.g., across semantic scales. "Notably, Hierarchical Diffusion LLMs (HDLM) \citep{zhu2025hdlm} introduce semantic scale prediction in a discrete diffusion framework, enabling hierarchical generation."
- hierarchical invariance: A training/property goal ensuring consistent representations across overlapping segments and levels. "The Stitcher enforces hierarchical invariance by ensuring that overlapping regions produce nearly identical representations after denoising and refinement, thereby stabilizing multi-level abstraction."
- in-batch negatives: Using other samples within the same batch as negative examples for contrastive learning. "We use an transformation and in-batch negatives, similarly to how we compute our MLM compressor loss."
- latent space: A continuous representation space where inputs are embedded and manipulated, often for generation or compression. "denoising in latent space"
- Masked Language Modeling (MLM): A pretraining objective where masked inputs are predicted from context to learn rich representations. "Our model primarily employs Probabilistic Attention in encoders for hierarchical compression, diffusion denoising, and Masked Language Modeling (MLM) tasks,"
- mode collapse: A failure mode in generative models where outputs lack diversity, collapsing to few modes. "heighten risks of mode collapse and oversmoothing in unanchored latents"
- noise-conditioning vector: A vector appended or prepended to condition the model on the current noise level during diffusion. "A noise-conditioning vector $\mathbf{v}_t = (1 - t) \cdot \mathbf{v}_{\text{clean} + t \cdot \mathbf{v}_{\text{noisy}$ is prepended"
- noise schedule: A predefined plan for the magnitude of noise across diffusion steps, often decreasing over time. "Over diffusion steps with a linear noise schedule decreasing from to , the following operations are performed:"
- non-autoregressive sampling: Generating multiple tokens in parallel without conditioning on previously generated outputs. "Diffusion models have shown promise for text generation by enabling non-autoregressive sampling and fine-grained control."
- out-of-vocabulary (OOV): Tokens not present in a model’s fixed vocabulary, often causing representation issues. "which can lead to out-of-vocabulary (OOV) issues"
- Probabilistic Attention: An attention mechanism that scales scores using position-wise existence probabilities to softly model variable sequence lengths. "Probabilistic Attention modulates the raw attention scores $s_{qk} = \frac{\mathbf{Q}_q^\top \mathbf{K}_k}{\sqrt{d}$ by incorporating existence ratios:"
- projection space: A lower-dimensional space used to compute similarities more efficiently or robustly. "Pairwise similarities between consecutive segments are computed in a reduced-dimensional projection space ($d_{\text{model}/4$)."
- Segment Splitter: A differentiable tokenizer that learns where to start segments by predicting BOS probabilities. "The Segment Splitter serves as Zonkey's hierarchical tokenizer,"
- Segment Stitcher: A differentiable module that reassembles overlapping segments into coherent sequences while enforcing consistency. "The Segment Stitcher serves as the symmetric counterpart to the Segment Splitter in Zonkey."
- soft-masked attention: Attention that uses continuous weights instead of hard masks, enabling gradient flow through mask decisions. "differentiable soft-masked attention \citep{athar2022differentiable} modulates contributions with continuous probabilities"
- soft truncation: Gradually reducing the influence of low-probability positions instead of cutting sequences with hard EOS tokens. "enabling soft truncation during inference when "
- variance-preserving: A noise injection scheme that maintains the overall variance (norm) of representations during diffusion. "Noise injects post-reshaping via variance-preserving: $\tilde{\mathbf{c} = \sqrt{t} \cdot \boldsymbol{\epsilon} + \sqrt{1 - t} \cdot \mathbf{c}$, "
Collections
Sign up for free to add this paper to one or more collections.