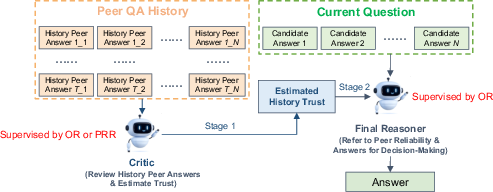
- The paper presents a two-stage ECL framework that decouples trust estimation from answer aggregation to improve historical context utilization.
- It demonstrates that auxiliary Peer Recognition Reward in RL boosts model performance by up to 15 percentage points in adversarial environments.
- The approach enhances epistemic autonomy by dynamically constructing trust priors, mitigating conformity and blind aggregation in multi-agent systems.
Epistemic Context Learning for Robust Trust Modeling in LLM-based Multi-Agent Systems
Recent developments in LLM-enabled Multi-Agent Systems (MAS) have highlighted acute limitations regarding epistemic autonomy and robustness. While multi-agent frameworks leverage peer interactions for superior generalization and automation, empirical evidence demonstrates a pronounced susceptibility to sycophancy, conformity, and blind aggregation, especially when agents confront misleading information from unreliable or adversarial peers. The observed phenomena are rooted in two fundamental deficiencies: first, agents exhibit a lack of history-sensitive trust modeling and instead privilege superficial present-round plausibility; second, agents fail to decouple peer reliability assessment from the final answer aggregation process.
The paper formalizes history-aware reference as the task wherein an agent, given both the current question, peer responses, and a history of peer interactions, must infer latent peer reliability and adapt its aggregation strategy accordingly. The objective is to move from history-agnostic aggregation to a paradigm where trust priors are dynamically constructed and referenced.
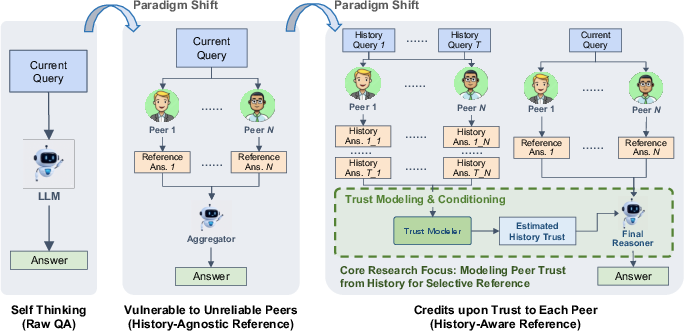
Figure 1: The progression from isolated decision making, to naive peer aggregation without trust estimation, to history-aware, dynamically trust-weighted peer referencing in LLM-based MAS.
Diagnostic Analysis of Existing Methods
A rigorous controlled evaluation reveals two pervasive failure modes. First, when peer identities are manipulated such that previously reliable agents become misleading (the "Flip" condition), answer accuracy remains high, indicating minimal incorporation of historical reliability in agent reasoning—lack of historical trust. Second, when all peers provide incorrect responses, agents experience extreme performance drops—blind conformity—demonstrating the absence of intrinsic epistemic autonomy.
These findings imply that reinforcement learning (RL) with purely outcome-based supervision is insufficient: models learn to exploit present context shortcuts instead of attending to latent social dynamics emergent from history.
The Epistemic Context Learning (ECL) Framework
To counter these deficiencies, the authors introduce Epistemic Context Learning (ECL), a two-stage, structured reasoning framework explicitly architected to induce history-aware trust modeling and robust aggregation.
A critical technical departure from prior art is the use of an auxiliary Peer Recognition Reward (PRR) for RL optimization: the model receives explicit supervision for correctly identifying reliable peers in history, in addition to standard outcome-based rewards. This fine-grained feedback offers denser, less ambiguous learning signals and mitigates reward hacking observed in single-stage RL.
Experimental Evaluation and Analyses
Quantitative assessment on challenging benchmarks (MMLU-Pro, GPQA) and across multiple LLMs—ranging from Qwen 3-4B/8B/30B to DeepSeek, GPT-5, Gemini 3—demonstrates the effectiveness of ECL:
- Small models (Qwen 3-4B/8B, RL-trained ECL):
Substantially outperform history-agnostic RL baselines—e.g., on MMLU-Pro and GPQA, ECL boosts accuracy by 5–15 percentage points. Strikingly, ECL-trained Qwen 3-4B surpasses Qwen 3-30B (8x size) under robust, history-aware aggregation.
History-aware ECL enables near-perfect performance (close to 100%) in adversarial peer scenarios, highlighting the unique superiority of trust modeling when confronting structurally deceptive environments.
The model's peer reliability recognition accuracy as measured by PRR aligns with high answer accuracy, demonstrating that precise trust estimation is tightly correlated with correct aggregation. Learning curves further indicate that PRR-driven RL efficiently and steadily improves trust modeling over training epochs.
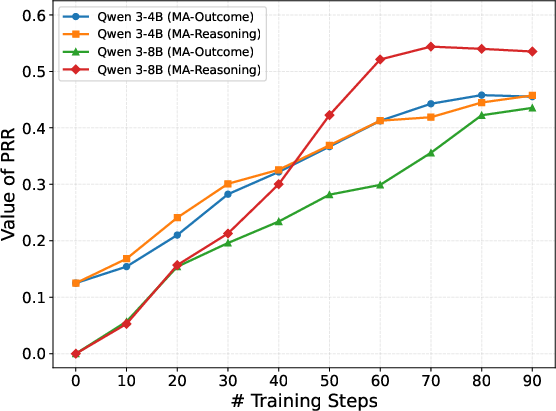
Figure 3: PRR learning curves for Qwen 3 on GPQA, showing monotonic improvement in trust recognition over RL training.
Qualitative case studies provide mechanistic clarity: ECL systematically steers answer generation towards reliable peers even in scenarios of agent uncertainty, whereas history-agnostic aggregation selects misleading confident responses.
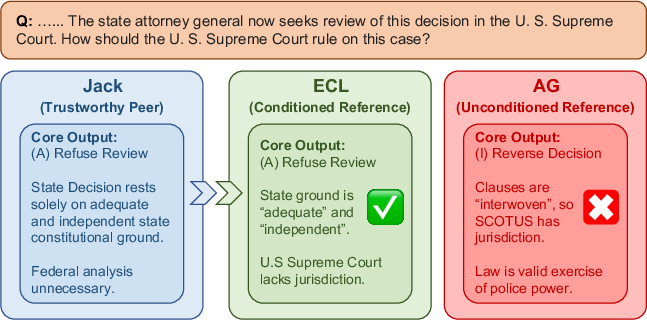
Figure 4: ECL correctly references the trustworthy peer by conditioning on history, while history-agnostic aggregation selects an incorrect response.
The robustness and generalization of ECL are validated across varying numbers of peers and history lengths. Notably, ECL variants outperform aggregator baselines even with minimal history and scale well with increased group size and episode length.
Theoretical and Practical Implications
ECL’s explicit inductive bias for history-aware trust modeling suggests notable implications for both LLM reasoning theory and practical system design:
- Theoretical: The results reinforce the necessity of architectural modularization (explicit decoupling of belief tracking and aggregation) for compositional meta-reasoning in LLMs. This aligns with human socio-cognitive mechanisms for reputation and epistemic vigilance.
- Practical: For robust real-world MAS deployment, especially in open or adversarial settings, naive peer aggregation is perilous; adaptation to ECL-style architectures with explicit trust estimation and auxiliary RL is essential to safeguard against groupthink, sycophancy, and manipulation.
- Limitations and Future Directions: Over-dependence on static trust priors (e.g., peer drifts) and efficient dynamic adaptation require further investigation. There are promising paths for attention-level reference control, adversarial RL curriculum, retrieval-augmented history selection, and fine-grained meta-ability supervision for greater autonomy.
Conclusion
This work delivers an incisive analysis of the limitations inherent in current LLM-based MAS and forges a principled algorithmic paradigm—Epistemic Context Learning—that raises the bar for trust-aware, history-sensitive collaborative intelligence. By architecturally binding trust estimation and leveraging auxiliary RL signals, ECL achieves robust resistance to misleading peers, significant gains in answer quality, and strong generalization across models and configurations. The introduced framework foregrounds the importance of epistemic meta-reasoning in LLM collectives and charts a concrete path for future systems necessitating both reliability and adaptability under uncertainty (2601.21742).