- The paper shows that pretraining with procedural data significantly enhances algorithmic skills like context recall and arithmetic operations.
- It details a methodology where abstract procedural tasks reduce the need for extensive semantic tokens while boosting transfer learning capabilities.
- The study reveals that combining diverse procedural data and analyzing layer-specific contributions yield measurable improvements in model performance.
Procedural Pretraining: Enhancing LLMs with Structured Data
Introduction
The paper "Procedural Pretraining: Warming Up LLMs with Abstract Data" (2601.21725) presents an investigation into the efficacy of using procedural data for pretraining LLMs. Unlike traditional methods that employ web-scale corpora, this study examines the benefits of initially exposing models to abstract structured data to enhance the acquisition of semantic knowledge. This novel approach is inspired by cognitive processes, suggesting that foundational algorithmic skills can support more complex semantic learning.
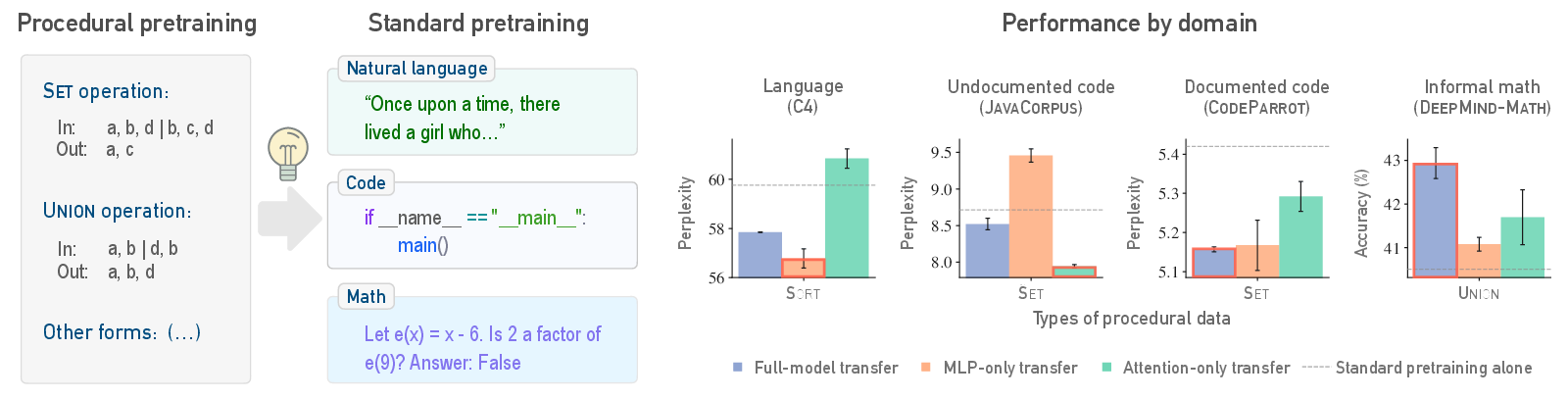
Figure 1: Pretraining on procedural data before standard datasets enhances learning efficiency across domains, with varying layer contributions.
Methodology
The study utilizes procedural data generated from formal languages and simple algorithms, focusing on its ability to instill various algorithmic skills in LLMs. The experiments involve three main components: evaluating the impact of procedural data on algorithmic tasks, its transferability to semantic domains, and exploring the localization of pretrained information within models.
Algorithmic Skill Probing:
Procedural pretraining develops specific algorithmic capabilities such as context recall and arithmetic operations, which are crucial for tasks like Needle-in-a-haystack and arithmetic computations. Procedural tasks like k-Dyck sequences significantly improve accuracy, evidencing the structured data's role in enhancing these skills.
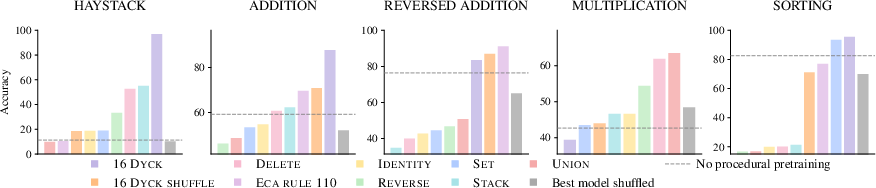
Figure 2: Procedural pretraining significantly improves performance on algorithmic tasks compared to standard training.
Transfer to Semantic Domains
Procedural pretraining's benefits extend beyond isolated tasks, enhancing performance in semantic domains like natural language processing and code understanding. Models pretrained with procedural data achieve optimal outcomes using substantially fewer semantic tokens, showcasing improved data efficiency and faster convergence.
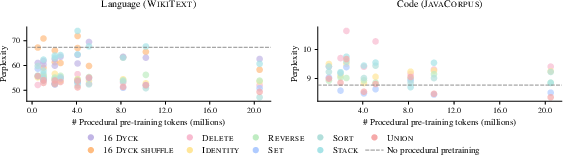
Figure 3: Procedural data effectively transfers to domains such as natural language, reducing required standard data tokens.
Layer-Wise Localization:
Insights into model architectures reveal that different layers store distinct forms of learned information. Attention layers are more beneficial for structured data, whereas MLP layers augment natural language tasks, indicating procedural pretraining's diverse influence across model components.
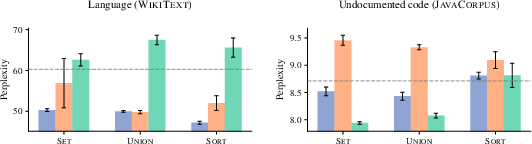
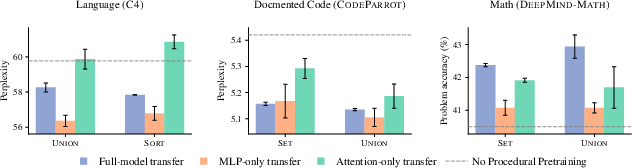
Figure 4: Transferable pretrained information is localized in specific layers, with distinct roles for MLP and attention based on the domain.
The research also examines the utility of combining various procedural data types. Mixtures of procedural data facilitate greater performance improvements than individual forms, suggesting synergy between different procedural tasks.
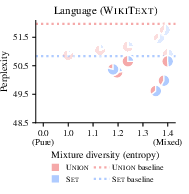

Figure 5: Mixtures of procedural data types outperform individual forms, demonstrating enhanced perplexity in language tasks.
Discussion and Implications
The findings underscore the potential of disentangling knowledge acquisition from reasoning in LLMs through procedural pretraining. This approach not only improves learning efficiency but also provides insights into refining model architectures and pretraining strategies. The research opens pathways for optimizing data selection in pretraining corpora, potentially leading to more sophisticated, well-grounded LLMs.
Conclusion
In summary, the paper presents procedural pretraining as a promising strategy to enhance LLM performance by focusing on elementary algorithmic skills. This approach offers a lightweight yet effective framework for improving LLM capabilities, highlighting an innovative direction for future AI development.