- The paper demonstrates that transformers pretrained on procedural data develop enhanced algorithmic reasoning capabilities with modular structural benefits.
- Using datasets like k-Dyck languages, stack operations, and cellular automata, the study highlights how structured inductive biases improve specific transformer components.
- Selective weight perturbation and modular transfer experiments indicate that tailored pretraining can outperform traditional methods in various algorithmic tasks.
Introduction
The paper "Transformers Pretrained on Procedural Data Contain Modular Structures for Algorithmic Reasoning" explores the impacts of pretraining transformers on procedurally-generated synthetic data, as opposed to traditional semantically-rich datasets. It identifies how specific procedural data can enhance algorithmic reasoning capabilities in small-scale transformers, examining which architectural components benefit most from such pretraining and how these benefits can be transferred across different tasks.
Models pre-trained with procedural data derived from simple algorithmic rules, such as k-Dyck languages and automata-generated sequences, exhibit specific improvements in tasks that require algorithmic reasoning, contrasting with those pretrained on conventional natural language corpora. This examination paves the way for effectively disentangling reasoning from pure knowledge acquisition in LLMs.

Figure 1: Pretraining on procedural data including formal languages and algorithms like cellular automata, showcasing color-coded brackets in k-Dyck examples.
Procedural Data and Model Architectures
Procedural Data Selection
The paper utilizes a variety of procedural datasets, such as k-Dyck languages, Stack operations, Identity tasks, and simple cellular automata like Rule 110. These datasets are specifically chosen for their potential to provide structured inductive biases to models during the pretraining phase.
Model Architecture
Small transformers, inspired by the GPT-2 architecture, are pretrained on these procedural tasks. The architecture consists of layers where attention mechanisms and MLP blocks are carefully examined to understand where algorithmic reasoning enhancements reside.

Figure 2: Procedural data pretraining results compared with random initialization and natural language pretraining for tasks like Multiplication.
Analysis of Architectural Components
Selective Transfer Experiments
Selective transfer experiments reveal that attention layers are pivotal; they often carry the most transferrable information across tasks. However, in certain cases, such as reversed arithmetic tasks, MLP blocks contain the crucial pretraining benefits. This highlights a modular nature in pretrained transformers where distinct procedural tasks enhance different architectural parts.
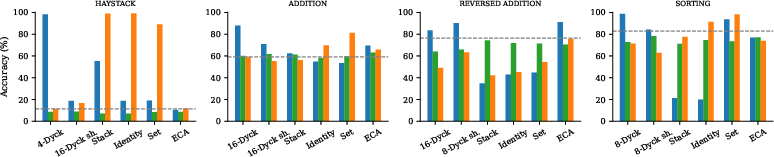
Figure 3: Different types of transfer, showing attention layers often provide the best improvements.
Weight Perturbation Insights
Weights perturbation through Gaussian noise and layer shuffling distinguish trivial weight initialization benefits from those created by precise procedural learning. This analysis confirms that procedural data instills structured inductive biases, useful beyond mere initialization magnitudes.
Modular Composition of Pretrained Structures
The study explores combining weights from different procedurally-pretrained models, leveraging distinct capabilities developed across various tasks. This composition enhances the initialization for downstream tasks, providing a unified setup that surpasses individual pretrained models' performance in multiple distinct tasks.
Discussion
The findings suggest procedural data could be strategically utilized as a precursor to robust LLM training, particularly for reasoning tasks. Future work might focus on optimizing data mixtures for pretraining or exploring direct weight structure instantiations that mimic the benefits of large-scale procedural pretraining.
Emerging questions involve identifying procedural data that best simulate reasoning capabilities separately from factual learning, potentially revolutionizing adaptability and efficiency in LLMs.
Conclusion
This paper strengthens the understanding of how procedural data can effectively prepare models for algorithmic reasoning tasks by instilling modular and transferable structures within transformer architectures. Such advancement holds promise for refining pretraining methodologies to enhance both robustness and data efficiency in future AI systems.