- The paper proposes FunHSI, a training-free framework that generates functionally correct 3D human-scene interactions by leveraging explicit contact graph reasoning and staged optimization.
- It employs vision-language models and dense pose initialization to accurately map high-level task prompts to precise hand-object contacts and spatially plausible results.
- Empirical evaluations show low functional contact distances, high non-collision rates, and robust generalization across both indoor and urban scenes.
Open-Vocabulary Functional 3D Human-Scene Interaction Generation
Introduction
The paper presents FunHSI, a training-free, functionality-driven framework for synthesizing functionally correct 3D human-scene interactions from open-vocabulary task prompts, leveraging posed RGB-D input and vision-LLMs (VLMs) (2601.20835). FunHSI advances prior human-scene interaction (HSI) synthesis by moving beyond visually plausible but semantically shallow generation to explicit reasoning over functional scene elements and physically plausible contact for task fulfillment. The approach is highly relevant for embodied AI, robotics, content creation, and simulation, as it robustly generalizes across diverse scenes and task instructions without requiring paired 3D HSI datasets or explicit action-object labels.
System Overview
FunHSI employs a modular pipeline comprising three principal stages:
- Functionality-aware Contact Reasoning: Identifies task-relevant functional elements in the scene and reconstructs their 3D geometry. Constructs an explicit contact graph via LLM-based reasoning, mapping high-level intent to low-level contact relationships.
- Functionality-aware Body Initialization: Performs human inpainting in the image to synthesize a plausible task-performer and estimates initial SMPL-X body and hand pose parameters. Refines the contact graph to resolve left-right hand ambiguities and align with synthesis observations.
- Optimization-based Body Refinement: Utilizes coarse-to-fine, two-stage optimization on body pose and contact consistency, combining collision losses, contact losses, and pose priors for physically plausible and functionally correct results.
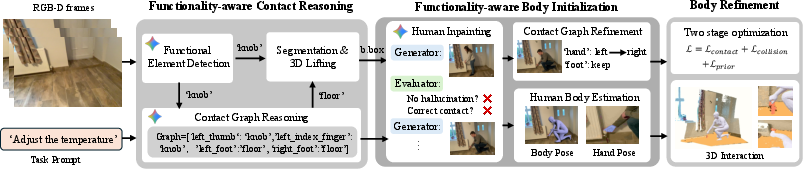
Figure 1: Pipeline overview of FunHSI, from functionality-aware contact reasoning to pose initialization and stage-wise 3D refinement under open-vocabulary task prompts.
Methodology
FunHSI invokes a state-of-the-art VLM (Gemini-2.5-Flash) given the RGB-D input and high-level task prompt to segment candidate functional elements (e.g., "knob," "handle") via open-vocabulary queries. Element masks from multiple views are fused into a 3D point cloud for subsequent optimization.
A structured contact graph is derived using an LLM (GPT-4o or Gemini), encoding body-part and scene-element pairs as explicit contact edges, informed by hierarchical annotation of the SMPL-X mesh (including fine-grained partitioning of hand subparts for finger-level reasoning).
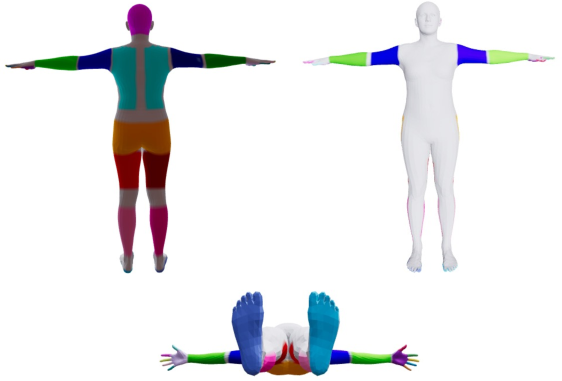
Figure 2: SMPL-X mesh annotated into semantically consistent body parts and finely discriminated hand segments to support contact reasoning.
Human Inpainting and Pose Initialization
Human appearance in the image is synthesized using VLM-based inpainting with a generator-evaluator loop mitigating hallucinations and enforcing contact locality. The synthesized human provides the initial pose prior, and articulated hand poses are estimated or defaulted for occluded cases. Critically, contact graph refinement is triggered to resolve left-right hand assignment by comparing pose projections relative to object masks, ensuring correct contact mappings.
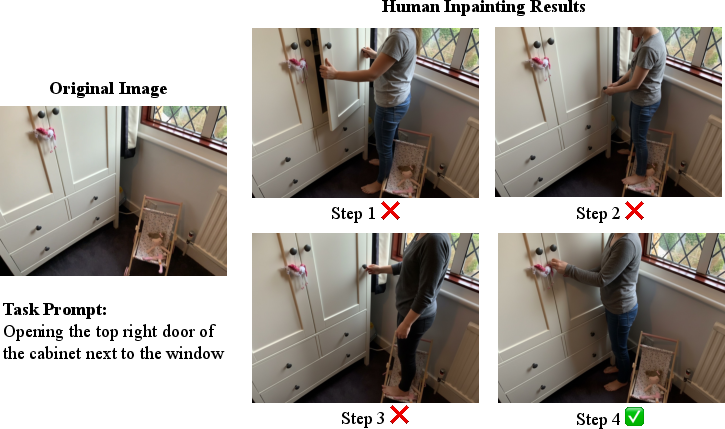
Figure 3: Generator-critic iteration for human inpainting, producing semantically and physically valid initialization for 3D body optimization.
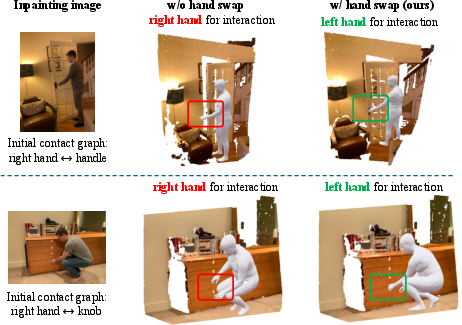
Figure 4: Correction of left-right hand ambiguities by refining the contact graph based on observed contacts in synthesized images.
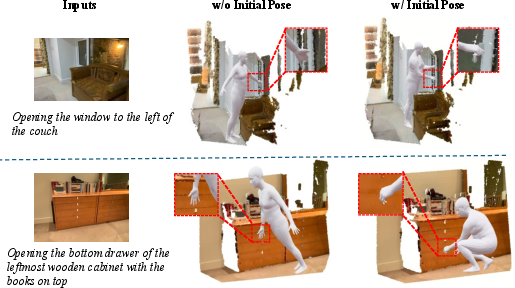
Figure 5: Effect of careful body and hand initialization in achieving stable and task-consistent functional interaction refinement.
Stage-wise 3D Optimization
The initial SMPL-X parameters are further refined in two stages: first, adjusting translation, global orientation, and arm pose to establish functional hand-object contact; second, full-body finetuning focused on physical plausibility and stable support (e.g., ground contact), regularized by a VPoser prior. Collision and single-sided Chamfer contact losses (driven by the contact graph) ensure task completion and geometric realism. The approach robustly avoids unnatural penetration and preserves task-driven intent.
Empirical Evaluation
Experiments conducted on SceneFun3D and in-the-wild city scenes demonstrate strong performance in both general and functional HSI settings. FunHSI delivers lowest functional contact distance (0.2968) and overall contact distance (0.1837) compared to extended baselines GenZI* and GenHSI*, with non-collision rates above 0.99 and competitive semantic consistency. Notably, FunHSI yields superior precision on tasks requiring fine-grained hand-object contact, such as operating switches or dialing numbers. Ablations confirm the necessity of dense pose initialization, contact graph refinement, and iterative optimization.
Qualitative Analysis
The approach is shown to handle both generic actions (e.g., sitting, squatting) and open-vocabulary functional tasks (e.g., adjusting thermostat, opening doors) with robust functional grounding and spatial accuracy.

Figure 6: FunHSI outputs for non-functional scene interactions (e.g., sitting, squatting, walking) compared to state-of-the-art baselines.

Figure 7: FunHSI excels at functional interactions (e.g., dialing, switching, adjusting), precisely targeting small functional elements with plausible pose and contact.
Generalization and Diversity
FunHSI generalizes robustly to real-world city scenes from iPhone RGB captures (MapAnything pipeline), synthesizing plausible human interactions in urban environments with variable geometry, occlusion, and scale.

Figure 8: FunHSI generating varied functional interactions in unconstrained scenes captured outside curated indoor datasets.
The framework supports diverse yet consistent realizations of each functional task, generating multiple plausible body configurations for the same prompt, always maintaining functional intent.
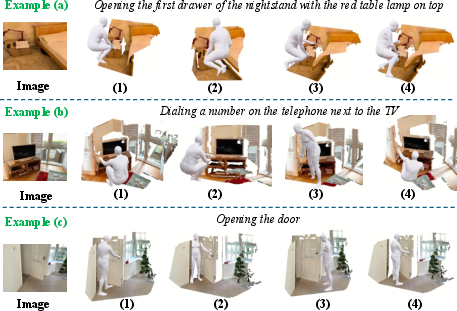
Figure 9: Diversity in task-consistent 3D poses, preserving correct functional contact across interaction realizations.
User Study
Perceptual user studies show strong preference for FunHSI outputs over baselines, with 71.1% overall preference, 76.8% in functional settings, indicating sensitivity to semantic grounding and physically plausible contact, which standard methods fail to consistently provide.
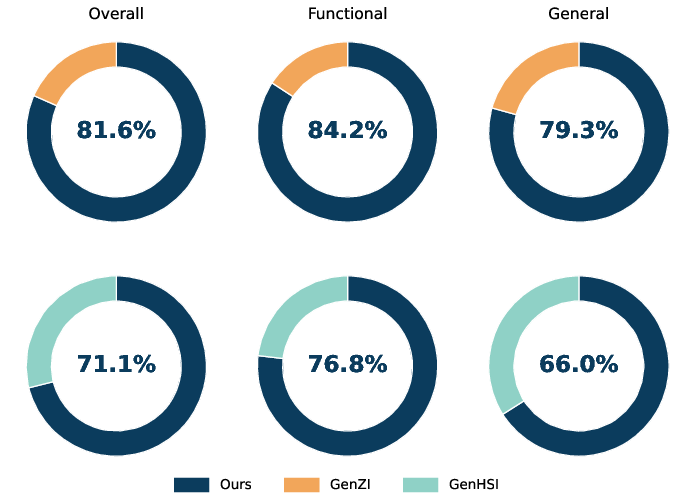
Figure 10: User study results demonstrate marked preference for FunHSI in both general and functional interaction settings.
Implications and Future Directions
FunHSI provides an effective blueprint for open-vocabulary, functionality-grounded 3D interaction generation, relevant to embodied agents, simulation, and digital content pipelines. By integrating foundation models for zero-shot reasoning with explicit contact graph constraints and structured optimization, the approach alleviates the bottlenecks of dataset dependency and manual annotation.
Key theoretical implications include the demonstration that language-driven contact graphs can robustly map high-level tasks to actionable geometric constraints in 3D, even in unseen settings. The practical significance for robotics and generative AI lies in the capability to generalize to real-world, out-of-distribution environments at inference time.
Possible trajectories for future exploration include:
- Extending to multi-step, temporally coherent functional interactions (sequential task planning),
- Scaling to multi-agent settings and more complex group behaviors,
- Joint scene-human scale calibration,
- Integrating physics simulation for dynamic, physically realistic multi-frame interactions,
- Optimization of upstream element detection via specialized foundation models.
Conclusion
FunHSI establishes a principled, training-free framework for generating functional 3D human-scene interactions under open-vocabulary task prompts, advancing state-of-the-art performance in both qualitative plausibility and quantitative functional grounding. The system's modular contact reasoning and robust optimization highlight new directions for 3D embodied intelligence and interaction synthesis, with future prospects in compositional task planning and real-world deployment within robotics and simulation.