- The paper introduces a novel online data augmentation framework (OATS) using influence scoring and guided diffusion to dynamically generate high-quality training samples.
- It demonstrates significant improvements in model generalization, reducing key error metrics like NLL and MAPE across multiple benchmark datasets.
- The framework employs an explore–exploit scheduler that efficiently balances computational cost with data diversity for both encoder and decoder time series models.
OATS: Online Data Augmentation for Time Series Foundation Models
Overview
The paper "OATS: Online Data Augmentation for Time Series Foundation Models" (2601.19040) proposes OATS, a dynamic data augmentation framework designed for Time Series Foundation Models (TSFMs). OATS leverages online data attribution, influence scoring, and generative modeling to produce high-quality synthetic data during training. Unlike prevailing static augmentation methods, OATS dynamically selects guiding samples based on their estimated contribution (via influence scores) to model generalization on reference sets. These guiding signals are then used to condition a diffusion-based generative model, yielding augmented samples tailored to each training iteration. The framework further employs an explore–exploit scheme to balance computational cost and data diversity.
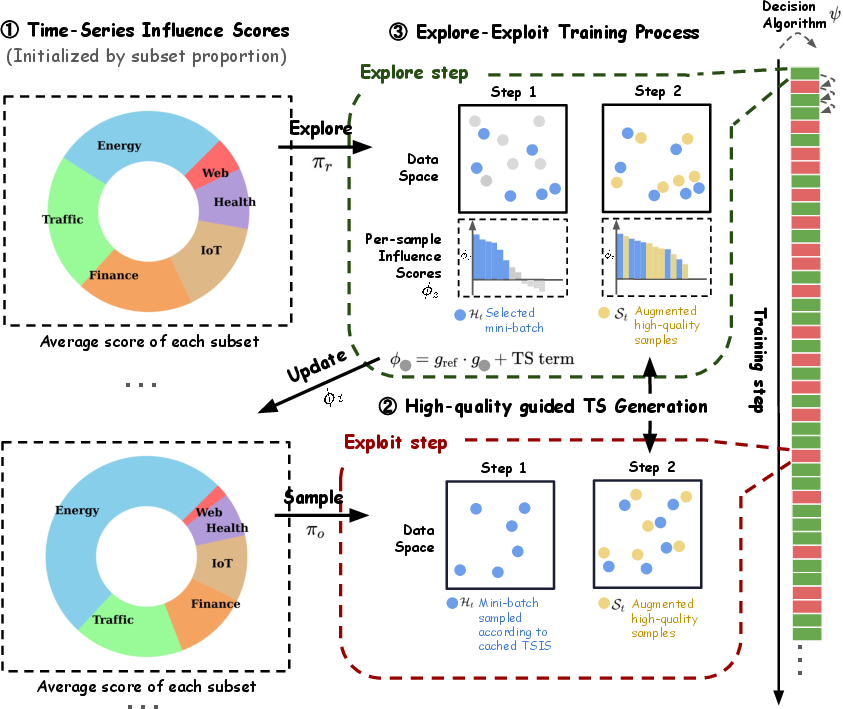
Figure 1: Architecture of OATS comprising influence scoring, guided generation via diffusion models, and an explore-exploit scheduler.
Methodological Advances
Time-Series Influence Scoring (TSIS)
OATS quantifies sample quality using Time-Series Influence Scores (TSIS), built on first-order Taylor approximations of influence functions. For a data point z, TSIS estimates the marginal improvement on reference loss induced by a training step using z. This enables principled selection of high-impact guiding samples within each batch, rather than relying on ad-hoc heuristics or transformations. TSIS computation incorporates both gradient information w.r.t. model parameters and domain-specific filters such as signal-to-noise ratio (SNR).
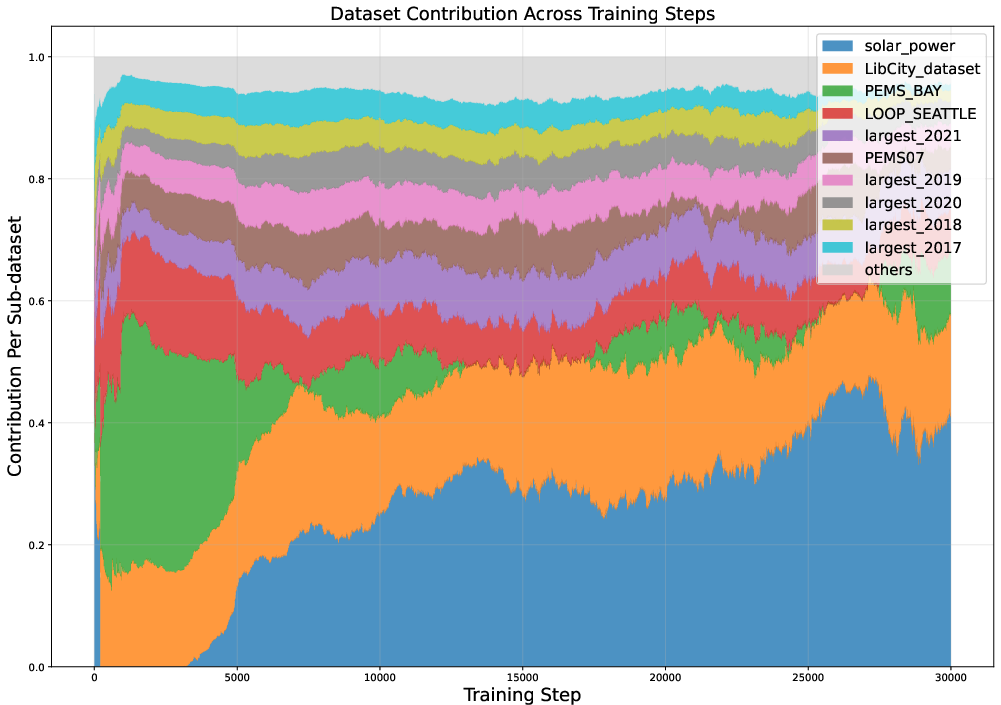
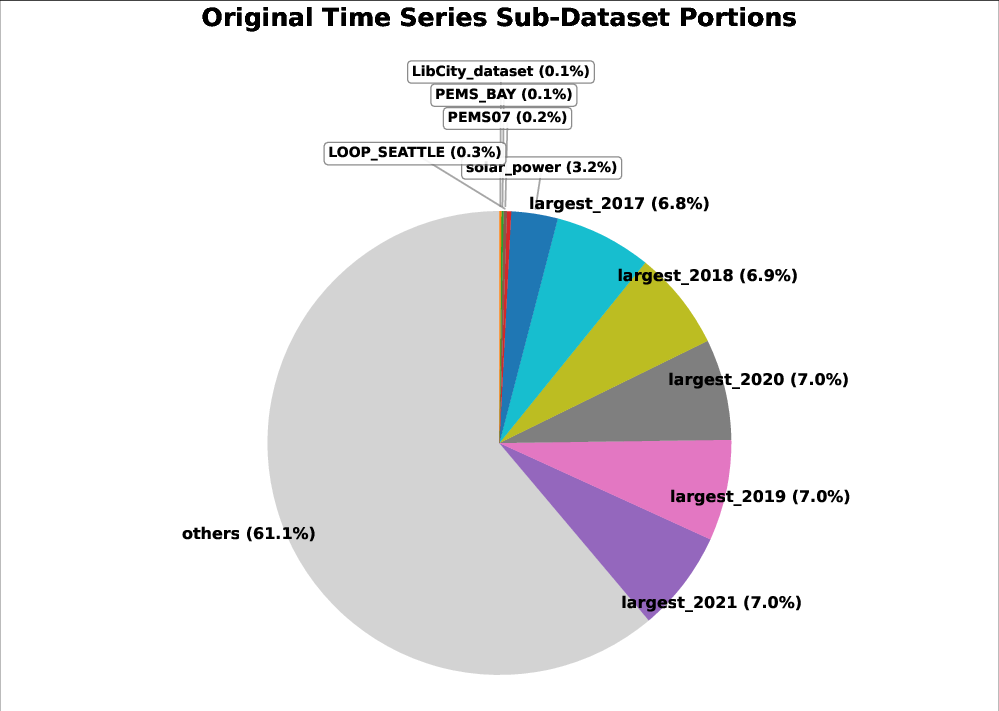
Figure 2: Sub-dataset TSIS (ΦD) tracked throughout training, illustrating dynamic shifts in sub-dataset contributions.
Guided Diffusion-based Generation
Selected high-quality samples are utilized as conditions for a conditional diffusion model, incorporating prototype representations and class embeddings. Conditional sampling expands the diversity of augmented data while targeting realistic time series structure. The generation process conditions at intermediate layers of the noise-prediction network using prototype weights and class information for improved domain alignment.
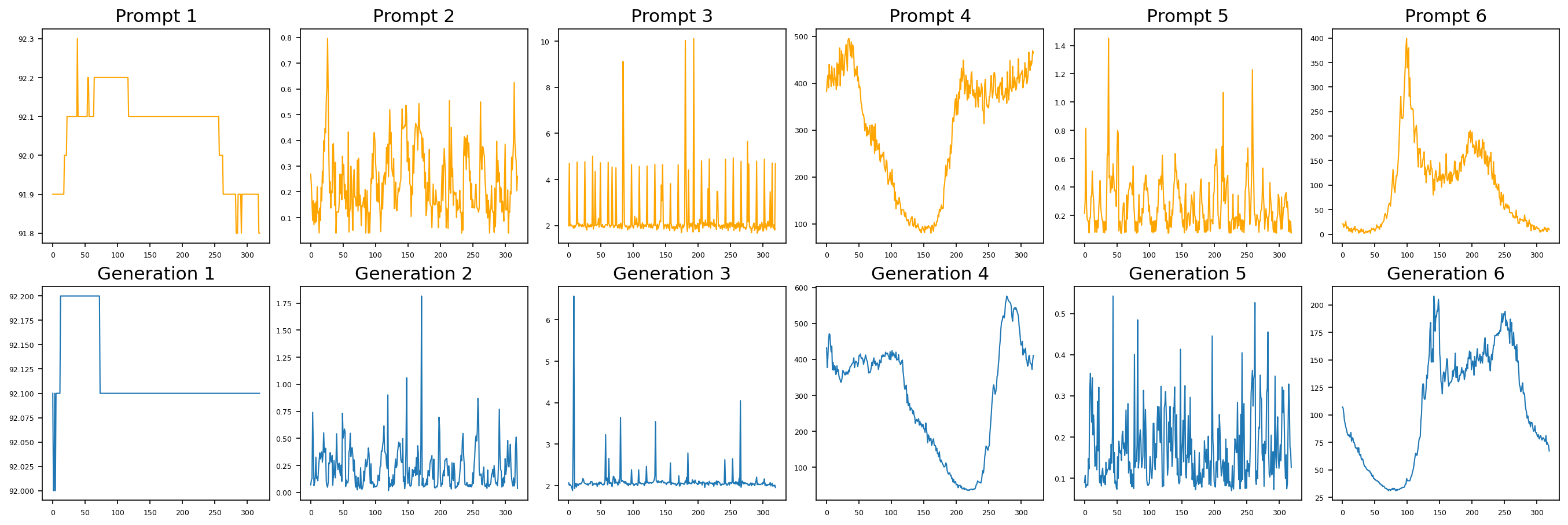
Figure 3: High-quality guiding samples (top row) and their respective diffusion-generated augmentations (bottom row).
Explore–Exploit Scheduling
To mitigate the computational cost of TSIS evaluation, OATS integrates an ϵ-greedy scheduler. "Explore" steps compute fresh TSIS, updating per-partition caches (ΦDl). "Exploit" steps sample batches proportional to cached influence, bypassing new TSIS calculation. The scheduler balances the efficiency of cached knowledge against the need for exploration in dynamic data landscapes.
Empirical Results
OATS is extensively evaluated across six benchmark datasets and two TSFM architectures (encoder-only, decoder-only). Metrics include Negative Log-Likelihood (NLL) and Mean Absolute Percentage Error (MAPE) at various horizons. OATS consistently yields superior generalization compared to regular training and baseline augmentation methods (Jitter, TSMixup), with statistically significant gains on almost all datasets and prediction lengths.
Key results:
- On ETTm1, OATS achieves test NLL of 1.627±0.042 (encoder) vs $1.870$ for regular training.
- On Electricity, OATS improves MAPE from $0.750$ (regular) to $0.515$ (encoder-only) and from $0.579$ to $0.526$ (decoder-only).
- OATS demonstrates both improved convergence rate (faster NLL reduction) and lower final error.
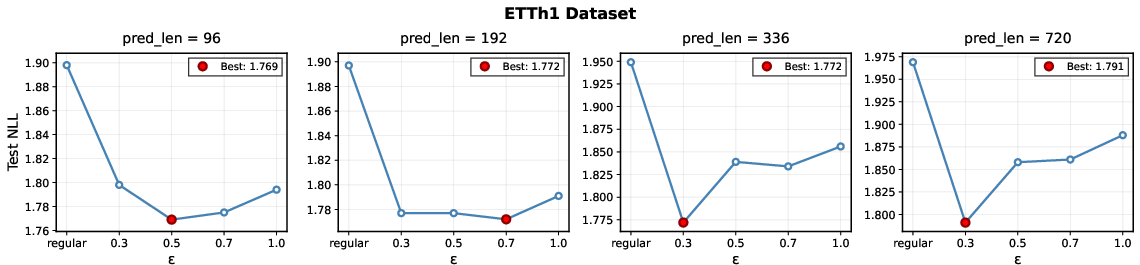
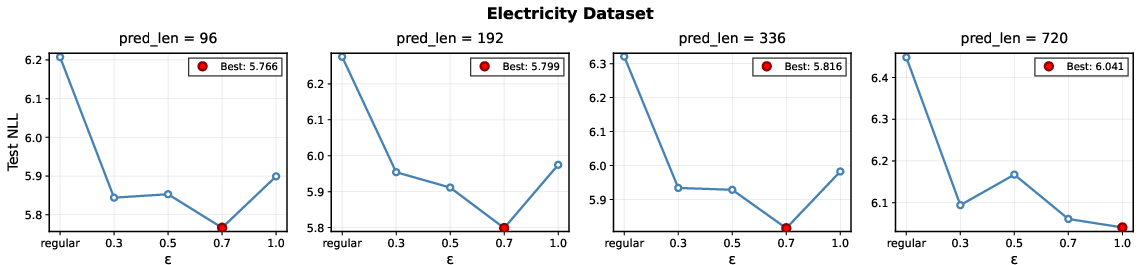
Figure 4: OATS performance (NLL) as a function of explore:exploit ratio (ϵ), with optimal tradeoffs marked by red circles.
Notably, ablation studies confirm the advantage of guided generation over selection-only schemes. Additional analysis indicates that computational overhead is linearly scalable with the explore ratio and can be significantly mitigated by lowering ϵ without sacrificing model performance.
Practical and Theoretical Implications
OATS highlights the limitations of static augmentation in time series, showing that sample utility is highly dynamic and domain-dependent. The principled use of influence functions for guiding generation enables targeted improvement of generalization, even for large-scale TSFMs with heterogeneous training corpora. The framework is adaptable to diverse data partitions, batch sizes, and reference set configurations, with robust empirical behavior under various hyperparameter settings.
The integration of explore–exploit scheduling aligns augmentation with underlying data attribution dynamics, yielding an efficient learning protocol. The conditional diffusion model architecture demonstrates strong fidelity and diversity in generated time series, further enhanced by semantic class embeddings.



Figure 5: Diffusion model with class embeddings enables high-fidelity, prompt-aligned conditional generation for multiple domains.
Future Directions
Potential developments include:
- Extension of TSIS to higher-order influence approximations or scalability optimizations (e.g., distributed influence estimation).
- Application to unsupervised or multi-modal TSFMs, exploring attribution in self-supervised contexts.
- Adaptation to real-time, streaming time series environments where data distributions shift rapidly.
- Further integration of causal or meta-learning components in the generative process to improve adaptation across domains.
Conclusion
OATS establishes an online, data-driven paradigm for augmenting TSFMs, replacing heuristic-based and static practices with principled influence scoring and adaptive generative modeling. This approach materially improves model generalization, efficiency, and robustness across varied time series domains, setting the foundation for systematic augmentation in large-scale time series learning. The paper's empirical rigor and theoretical motivation position OATS as a framework of increasing relevance as TSFMs scale in scope, complexity, and deployment contexts.