- The paper presents a novel travel planning framework that integrates personalized recall, multi-agent consensus, and constraint-gated reinforcement learning.
- It employs a competitive chain-of-thought mechanism that balances diverse user constraints to achieve high feasibility and route efficiency.
- Experimental results demonstrate significant improvements over previous methods, including 100% feasibility and reduced average route distances.
TourPlanner: A Competitive Consensus and Constraint-Gated RL Framework for Agentic Travel Planning
Introduction and Motivation
TourPlanner addresses the multi-faceted challenges inherent in automated travel planning for LLM-based agents. The core issues are threefold: efficient pruning of a massive POI candidate set without sacrificing recall or contextual representation, insufficient exploration in the solution space due to a reliance on single-path CoT reasoning strategies, and the intrinsic difficulty of optimizing both feasibility (hard constraints) and personalization/efficiency (soft constraints) in the same process. Previous frameworks, including TravelPlanner, TripTailor, and hybrid LLM+formal solvers [wang2025triptailor, xie2024travelplanner, ning2025deeptravel], have established meaningful benchmarks but either falter on multi-constraint satisfaction or have limited structured means of multi-agent arbitration. TourPlanner is presented as a modular, agentic architecture that tightly integrates tailored recall, competitive chain-of-thought reasoning, and curriculum-inspired RL optimization.
Framework Overview
TourPlanner is structured around four principal modules: PReSO (Personalized Recall and Spatial Optimization), the Competitive consensus Chain-of-Thought (CCoT) engine, and a Constraint-Gated RL refinement module. The complete data and reasoning flow, including agent instantiation, proposal generation/arbitration, and plan refinement, is illustrated in Figure 1.
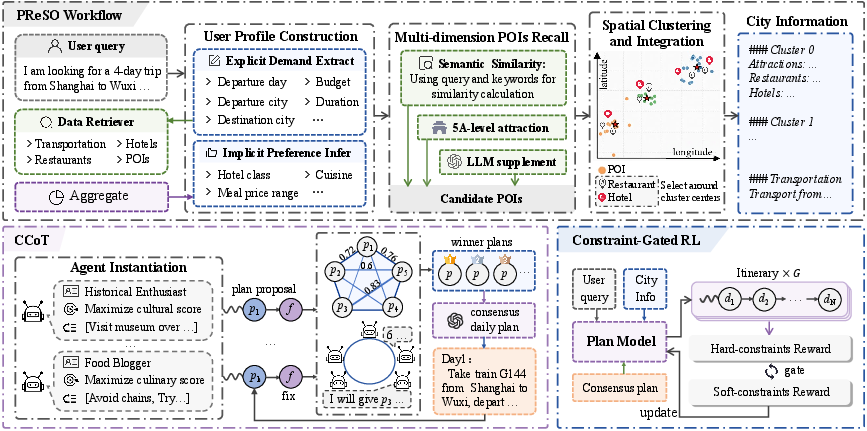
Figure 1: TourPlanner schematic workflow, showcasing candidate POI construction via PReSO, multi-agent daily itinerary proposal generation and arbitration via CCoT, and final refinement through constraint-gated RL.
Personalized Recall and Spatial Optimization
The PReSO workflow is designed as a compositional, multi-channel recall mechanism. Explicit user requirements are parsed and enhanced with LLM-inferred implicit preferences, producing a robust user profile. Three parallel retrieval approaches—embedding-based semantic recall (augmented by synonym expansion), popularity tier retrieval (e.g., attractions rated 4A/5A), and LLM-driven thematic suggestion—are fused, ensuring both user alignment and coverage of canonical landmarks.
Spatial clustering of POIs (using DBSCAN), with cluster categories injected into the symbolic representation, further improves the initialization by maximizing spatial compactness and operational tractability. This step directly impacts route efficiency and sets the stage for high-fidelity daily route realization downstream.
Competitive Consensus Chain-of-Thought (CCoT)
Unlike prior works limited to single-horizon reasoning [yang2025plan, yao2023tree], CCoT initiates multiple specialized reasoning agents, each embodying a measurable objective aligned with distinct user or planning constraints (e.g., culture, gourmet, budget, efficiency), and executes proposal generation in parallel for each trip day. The arbitration pipeline comprises:
- Proposal Diversity Weighting: Agents’ proposals are embedded and diversity weights wi are determined inversely using inter-proposal cosine similarities, rewarding subjective uniqueness and discouraging collapse to a single archetype.
- Parallel Peer Review: Each agent numerically evaluates all proposals with respect to their own objective metric, yielding a dense N×N score/critique matrix.
- Weighted Consensus Selection: Final daily plans are collectively synthesized from the top-k proposals ranked by a weighted aggregation of peer scores and diversity.
This multi-path process effectually resolves conflicting objectives and breaks the sub-optimality ceiling imposed by monolithic reasoning.
Constraint-Gated Reinforcement Learning
The refinement phase addresses the long-standing inefficacy of naïve additive reward functions in RL, where binary hard-constraint violations overwhelm dense soft-constraint rewards, leading to infeasible or depersonalized outputs. TourPlanner implements a sigmoid gating mechanism:
R=Rhard+α(η)⋅Rsoft,α(η)=1+e−k(η−τ)1
Here, α(η) is negligible until hard constraints are passed, at which point soft rewards progressively increase in influence, reflecting a curriculum learning schema. Training is conducted with GSPO [zheng2025group] to stabilize off-policy updates, with group-based advantage estimation and sequence-level importance weighting.
Experimental Results
TourPlanner is empirically validated on the TripTailor benchmark, leveraging a broad set of LLM backbones (GPT-4o, Qwen3-235B, DeepSeek-R1) and planning baselines. Performance metrics evaluate feasibility pass rate, rationality pass rate, route efficiency, final pass rate, and personalization surpassing rate.
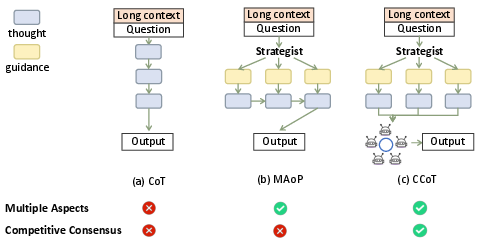
Figure 2: Comparative performance of TourPlanner versus prior methods across core planning metrics on the TripTailor benchmark.
Numerical Results and Ablations
- Feasibility and Rationality: TourPlanner achieves a 100% feasibility pass rate and 97–98% macro rationality with all LLMs, significantly surpassing both direct and ReAct-based planning approaches (which rarely exceed 30% in macro rationality).
- Route Efficiency: Average route distance ratio is reduced to 2.15, compared to direct planning ratios up to 5.98—a strong improvement in spatial optimization.
- Final Pass/Surpassing Rate: Final pass rates reach 56.1% with a final surpassing rate of 30.2%, outperforming state-of-the-art baselines by wide margins.
- Ablation Insights: Removal of CCoT arbitration or RL stages degrades macro rationality and final pass rates, confirming their essentiality. Agent scaling analysis reveals diminishing returns beyond 6 agents; optimal balance lies in a moderately sized ensemble.
Analysis and Implications
TourPlanner's multi-agent, multi-path reasoning paradigm demonstrates that competitive consensus can robustly resolve conflicting itineraries and consistently produce feasible, efficient, and user-aligned travel plans. The hybrid recall mechanism secures environmental fidelity, while spatial clustering drives route compactness. The curriculum-inspired RL objective facilitates hard-then-soft constraint optimization, mitigating the traditional gradient starvation of soft rewards.
Practically, TourPlanner not only establishes new performance benchmarks but also proposes a robust template for agentic planning in other domains requiring multi-objective balancing, such as multi-modal transit design, personal scheduling, or resource allocation applications. Theoretically, it substantiates the value of formal arbitration protocols among LLM-derived specialist modules and the potential of curriculum RL for structured problem spaces.
Conclusion
TourPlanner delivers a methodologically rigorous framework that advances the state-of-the-art in LLM-centric travel planning agents. Through PReSO, CCoT, and constraint-gated RL, it achieves near-perfect hard-constraint satisfaction and state-of-the-art multi-objective rationality, robust to LLM backbone variance. This architecture demonstrates the efficacy of competitive consensus and curriculum-aware RL for high-dimensional, real-world generative planning tasks, indicating clear directions for future research in agentic AI.

