- The paper introduces novel algebraic extension operations (DT→DT, CAT→CAT, DT→CAT) that map OPP schemes to GP, maintaining privacy and decodability.
- It demonstrates through numerical analysis that direct GP constructions, or GP-CATs, outperform extended OPP codes by reducing worker counts by up to 20%.
- The study offers practical insights into minimizing compute instance overhead in distributed privacy-preserving matrix operations.
Extension of Private Distributed Matrix Multiplication Schemes to Grid Partition
Introduction and Motivation
Private distributed matrix multiplication (PDMM), also known as secure distributed matrix multiplication (SDMM), addresses the problem of multiplying two private matrices using distributed worker nodes, while hiding all information about the operands from up to T colluding “honest-but-curious” workers. State-of-the-art PDMM schemes design computational tasks using polynomial codes, where the matrices are partitioned and encoded as polynomials, and each worker receives an evaluation. The minimal number of workers needed for correct recovery and privacy, under various partitioning strategies—i.e., outer product partition (OPP), inner product partition (IPP), and grid partition (GP)—is a central metric of interest.
Despite numerous constructions for OPP [doliveira2020gaspa, doliveira2021degreec, hofmeister2025cat] and GP [karpuk2024modular, byrne2023straggler], general principles for extending efficient OPP constructions to the general GP setting have been lacking. This work systematically examines and formalizes extension operations that map a broad class of OPP polynomial codes to the more general GP, analyzes the structural constraints these extensions impose, and, crucially, provides combinatorial and algebraic constructions for GP-PDMM codes that are not bound by these constraints, achieving improved efficiency in many parameter regimes.
A fundamental abstraction in polynomial PDMM code design is the degree table (DT) and its cyclic variant (CAT), which describe the relationship between encoding exponents of the partitioned matrix blocks and guide the allocation of exponents so as to minimize the number of distinct monomials, and hence the number of required workers.
For OPP, the degree table is a matrix whose (i,j) entry is the sum of the degrees assigned to Ai and Bj, and the critical idea is to minimize the number of distinct such sums (equals the number of nonzero coefficients in the product polynomial).
GP allows partitioning both matrices into block matrices (K×M and M×L), generalizing OPP and IPP, but the construction and analysis of degree tables become more intricate due to the combinatorial structure of block indices.
The paper introduces three precise algebraic extension operations:
- DT→DT: Mapping an OPP degree table to a GP degree table by splitting degree-vectors along the grid and offsetting as required to preserve the addition structure.
- CAT→CAT: Analogous extension for cyclic-addition tables, suitable for encoding with roots of unity and cyclically invariant moduli.
- DT→CAT: Hybrid extension that transfers arithmetic-progression-based OPP designs into cyclic grid CATs.
The key theoretical result is that, under mild assumptions, these extensions preserve privacy and decodability and need at most N′+(M−1)(K+T)L workers, where N′ is the original OPP worker count; they are tight (equality holds generically), so additional design constraints are introduced in the process.
Grid Partition Constraints and Direct Codes
A pivotal observation is that extension operations impose unnecessary combinatorial constraints on the structure of the GP degree tables—specifically, that the antidiagonals of each M×M block must form arithmetic progressions, and inter-block cross-overlaps are forbidden. However, direct constructions for GP, unconstrained by the legacy of OPP extension, can further exploit combinatorics of the grid to reduce worker counts.
The authors design explicit GP-CATs directly tailored to the GP regime—called GP-CATs—not adhering to the above extension-induced restrictions. These codes achieve strictly better performance (i.e., fewer worker nodes needed) for significant parameter ranges, as visualized in (Figure 1).
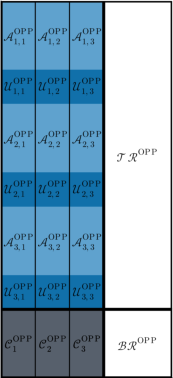
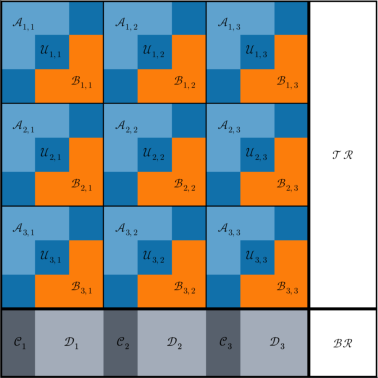
Figure 2: Worker count requirements for various PDMM schemes as a function of partition parameters under a fixed collusion parameter T=20. Each marker type corresponds to a separate code family. Lower points represent more communication-efficient schemes.
The new extension operations and direct GP constructions are numerically evaluated across a systematic sweep for key parameters (K,M,L,T). The phase space is visualized in (Figure 1), where different code families—root-of-unity (ROU) codes [machado2022root], BGK [byrne2023straggler], modular partition (MP) [karpuk2024modular], and the new GP-CATs—are compared.
Strong claims from the numerical analysis include:
- For large block matrices (K,M,L), the proposed direct GP-CAT outperforms all prior schemes over a wide sweep in terms of the minimal required worker count, achieving up to 10–20% reductions in nontrivial regimes.
- GP degree tables derived via extension operations are strictly suboptimal (dominated) in a subset of the parameter grid, confirming that combinatorial freedom is crucial for optimal code design in general partitions.
- For certain partitions, the gap between the best extensions of OPP codes and direct GP codes is unbounded in the asymptotic worker efficiency.
Theoretical and Practical Implications
The explicit characterization of which constraints arise from OPP extension and which are truly necessary for privacy and decodability has theoretical impact: it clarifies the landscape of code design for private/secure distributed computation, demarcating the limits of hierarchical extension (“bootstrapping”) and the need for new direct combinatorial constructions in high-dimensional or straggler-sensitive workloads.
Practically, the results imply that distributed privacy-preserving matrix multiplication over general partitionings can be done with less infrastructure overhead—worker count translates directly to the number of required compute instances, which dominates cost and reliability in modern cloud and federated settings. Moreover, the use of small prime fields and roots-of-unity schemes in the direct GP-CATs makes these codes suitable for efficient approximate arithmetic over real-valued secrets.
Future Directions
The framework introduced opens several avenues for further theoretical and algorithmic development:
- Extension to Multi-party and Hierarchical Settings: Analysis and systematic extension of these operations to deeper hierarchical and recursive settings (e.g., multi-round codes for PDMM/SDMM).
- Explicit CAT Construction for Arbitrary (K,M,L,T): Systematic methods for constructing optimal GP-CATs using combinatorial design, possibly leveraging algebraic geometry codes or new sum-free set constructions.
- Communication-Resilient PDMM Codes: Integration of the proposed code structure into systems that optimize network latency, bandwidth, and robustness to worker stragglers while retaining minimal collusion-resilient worker counts.
- Approximate Arithmetic over Non-Prime Fields: Further investigation into field choice trade-offs when supporting both privacy and high-precision floating-point arithmetic via residue encoding.
Conclusion
This paper advances the theory and practice of secure distributed matrix multiplication by systematizing the extension of private PDMM codes from OPP to grid partition, rigorously analyzing the resulting combinatorial constraints, and constructing new classes of direct GP-CATs that break those constraints and minimize worker usage in practice. The structural insights and algebraic tools developed are directly applicable to the design of scalable privacy-preserving computation in distributed and federated learning systems, and lay the groundwork for further combinatorial and algebraic code design for PDMM.