- The paper introduces a universal one-sided slicing algorithm for distributed matrix multiplication that supports any partitioning and replication without costly repartitioning.
- The method employs explicit index arithmetic to compute local matrix tiles and decouples multiplication from communication collectives, enhancing flexibility.
- Experimental results demonstrate that the approach matches or exceeds DTensor performance on Intel and Nvidia systems, offering robust and adaptive scalability.
Universal One-Sided Distributed Matrix Multiplication via Slicing
Motivation and Problem Statement
Distributed matrix multiplication is a foundational computation in large-scale scientific computing, data analytics, and AI workflows. The exponential growth in model and data sizes, particularly for transformer-based architectures, has necessitated highly flexible and efficient distributed matrix multiplication algorithms. Historically, a combinatorially large set of algorithmic variants (1D, 2D, 1.5D, 2.5D, with diverse partitionings and replications) have been required to match different matrix shapes and memory budgets. Existing SPMD (Single Program, Multiple Data) frameworks (e.g., PyTorch DTensor, Mesh-TensorFlow, GSPMD) implement only a limited subset, forcing costly repartitioning if the user specifies a distribution unsupported by the underlying kernel libraries. Moreover, prior algorithms impose rigid requirements (such as tile alignment) and often make heavy use of different collective primitives, hindering portability and extensibility. The paper introduces a universal one-sided algorithm that constructs the set of local matrix multiplications for arbitrary combinations of partitioning and replication, supporting misaligned tiles and decoupling the matrix multiply kernel from communication collectives.
Universal Slicing-Based Algorithm
The core contribution is a universal algorithm for distributed matrix multiplication that supports arbitrary partitionings and replication factors for all operands. The algorithm is based on explicit “slicing” via index arithmetic to enumerate, for each process, the precise set of triplets {Atile,Btile,Ctile} required to compute the local output tile, regardless of non-alignment or mixed partitionings.
Each process takes as input its owned tiles (of a selected stationary matrix—A, B, or C) and computes the overlap sets for the other matrices. Flexible primitives (get, accumulate, overlap query) enable efficient, asynchronous memory transfers using only remote get and accumulate. Replication is handled transparently by modifying only the relevant slices. Output tiles are accumulated using a reduction if replicated.
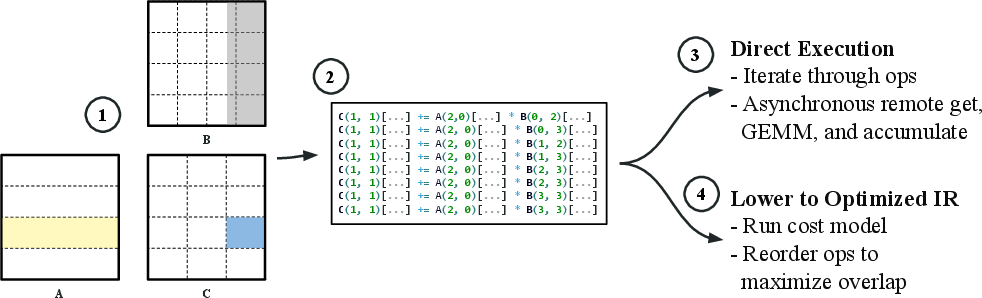
Figure 1: The algorithm constructs local matrix multiplications by slicing overlapping regions of A, B, and C, supporting arbitrary partitionings and replication; misaligned tiles and general stationary strategies are fully supported.
The data movement strategy is chosen (stationary A, B, or C), generally letting the largest matrix remain fixed to reduce communication volume. The local op generation is a purely index-based enumeration, decoupled from process topology or alignment constraints. Processes execute the assembled local multiplication-and-accumulation tasks either immediately (direct execution) or via lowering to an IR supporting cost-model-guided scheduling for optimal communication-computation overlap.
Implementation and Optimizations
A high-level C++-based PGAS implementation leverages Intel SHMEM or NVSHMEM for direct GPU-to-GPU one-sided communication of tiles. Key optimizations include:
- Adaptive scheduling using index offsets to prevent network congestion.
- Prefetching and asynchronous task launching to maximize overlap.
- Memory pooling to reduce device allocation overhead and ensure high kernel launch throughput.
- Transparently handles all patterns of replication without algorithmic branching.
The algorithm and runtime interoperate with both Intel (PVC/Xe Link) and Nvidia (NVLink) GPU clusters.
Experimental Evaluation
The algorithm is benchmarked against DTensor (PyTorch's distributed SPMD backend) on matrix shapes and sizes representative of transformer MLP layers (MLP-1: m×12K by $12$K × $48$K and MLP-2: m×48K by $48$K × $12$K) on both Intel PVC and Nvidia H100 systems. The experiments sweep partitioning configurations (row, column, 2D), test both aligned and intentionally misaligned tile layouts, and evaluate the effect of various replication factors and stationary strategies.
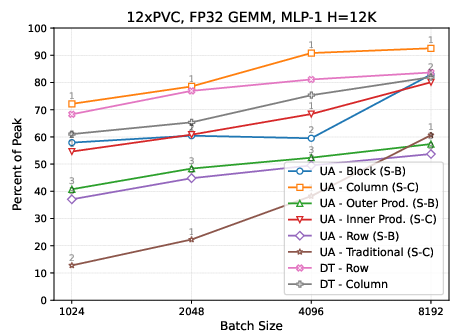
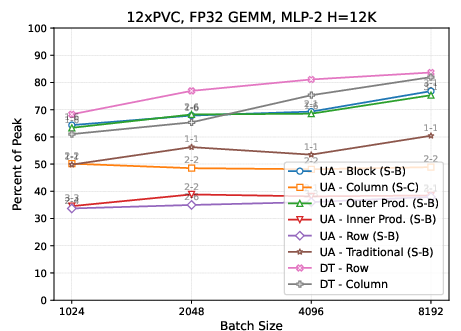
Figure 2: On Intel PVC, the universal algorithm achieves comparable or superior performance to PyTorch DTensor across MLP-1 and MLP-2 tasks for a variety of partitionings and replication factors.
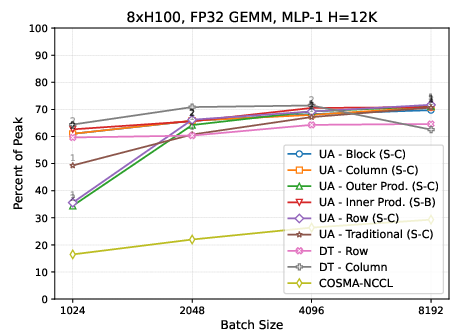
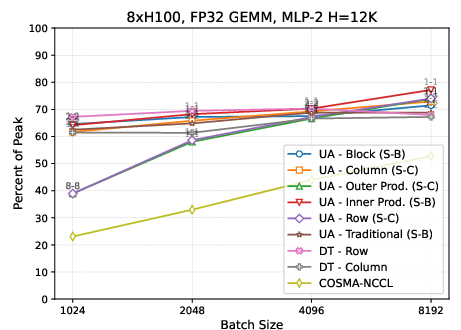
Figure 3: On Nvidia H100, the universal algorithm matches or outperforms DTensor over the tested MLP layer matrix shapes for diverse partitionings and replications.
Key findings include:
- The direct execution path, especially with optimized asynchrony, nearly saturates available compute and interconnect bandwidth across architectures, matching peak DTensor throughput.
- For matrix shapes where communication is dominant (e.g., only one matrix is small), the algorithm automatically identifies minimal-communication partitionings, and replication factors yielding further communication reduction.
- The approach robustly handles all valid partitioning and replication settings, whereas DTensor is frequently constrained (e.g., limited support for mixed replications or 2D).
- For MLP-1 (wide hidden layer expansion), column block or inner product–style partitioning achieves highest performance due to minimized data movement on the smallest matrix. For MLP-2, outer product–style (row × column) and 2D block partitioning are preferable due to reduced accumulation on the smaller output.
- On Nvidia H100, the performance difference between partitionings is muted, attributed to significantly higher intra-node bandwidth relative to compute; optimal replication reduces accumulation cost for target partitionings.
Numerical Results and Claims
The universal slicing-based algorithm matches or exceeds the performance of PyTorch DTensor across all tested matrix shapes and partitionings, even in non-aligned or mixed-replication cases where DTensor falls back to costly repartitioning. On both Intel and Nvidia systems, the framework achieves high fractions of theoretical peak FLOPs and saturates network bandwidth for communication-bound cases. The approach demonstrates robust performance even under highly irregular partitionings with misaligned tiles and arbitrary replication.
Implications and Future Directions
This work removes a long-standing flexibility/performance tradeoff in distributed dense matrix multiplication. With a universal, single-algorithm paradigm, the combinatorial space of tile partitionings, alignments, and replication strategies is made fully available for dynamic exploration and auto-tuning. This immediately accelerates the development and deployment of large-scale AI models leveraging sophisticated model parallelism, as found in large transformer and sequence modeling workloads. From a systems perspective, the restriction to only one-sided primitives (get/accumulate) standardizes requirements for vendors and eases porting and extension to new hardware.
Theoretically, this work moves towards bridging the communication optimality of 3D/2.5D algorithms with the universality and extensibility required for modern production SPMD frameworks. Practical deployment in production frameworks (e.g., integration into PyTorch DTensor or similar SPMD systems) will further expand the universe of possible distributions, facilitating new research in automated partitioning selection, joint communication/computation optimization, and advanced workload scheduling.
Conclusion
The paper presents a universal, one-sided distributed matrix multiplication algorithm, supporting all combinations of partitionings, replications, and tile alignments, realized via explicit slicing and remote memory operations. The approach achieves performance on par with state-of-the-art SPMD frameworks (e.g., DTensor) on both Intel and Nvidia platforms, and removes previous limitations associated with manual kernel selection and rigid communication collectives. This work constitutes a significant step towards flexible, architecture-portable distributed linear algebra and enables deeper auto-tuning and system-level optimization for future AI workloads, particularly as hardware continues to diversify and model/data scales increase further (2510.08874).