- The paper introduces a probabilistic framework using masked language models to adapt transmission rates by selectively masking predictable tokens.
- It applies an iterative MAP-based detection method at the receiver, integrating channel likelihoods with contextual priors for enhanced token inference.
- Empirical results demonstrate significant semantic preservation and robust rate adaptation under various channel conditions and masking ratios.
Context-Aware Iterative Token Detection and Masked Transmission for Wireless Token Communication
Introduction
This paper presents a probabilistic framework for wireless transmission of language tokens, leveraging masked LLMs (MLMs) as a central mechanism for both adaptive transmission and robust symbol detection. The emergence of token-based representations in downstream applications motivates a communication paradigm shift in which not all tokens are treated equally; rather, contextual redundancy is explicitly exploited both to reduce transmission rates and to counteract channel errors. The methodology establishes a dual role for masked LLMs: at the transmitter (Tx), they guide context-aware masking to omit highly predictable tokens, while at the receiver (Rx) they enable iterative MAP-based token inference, fusing channel observations and contextual priors.
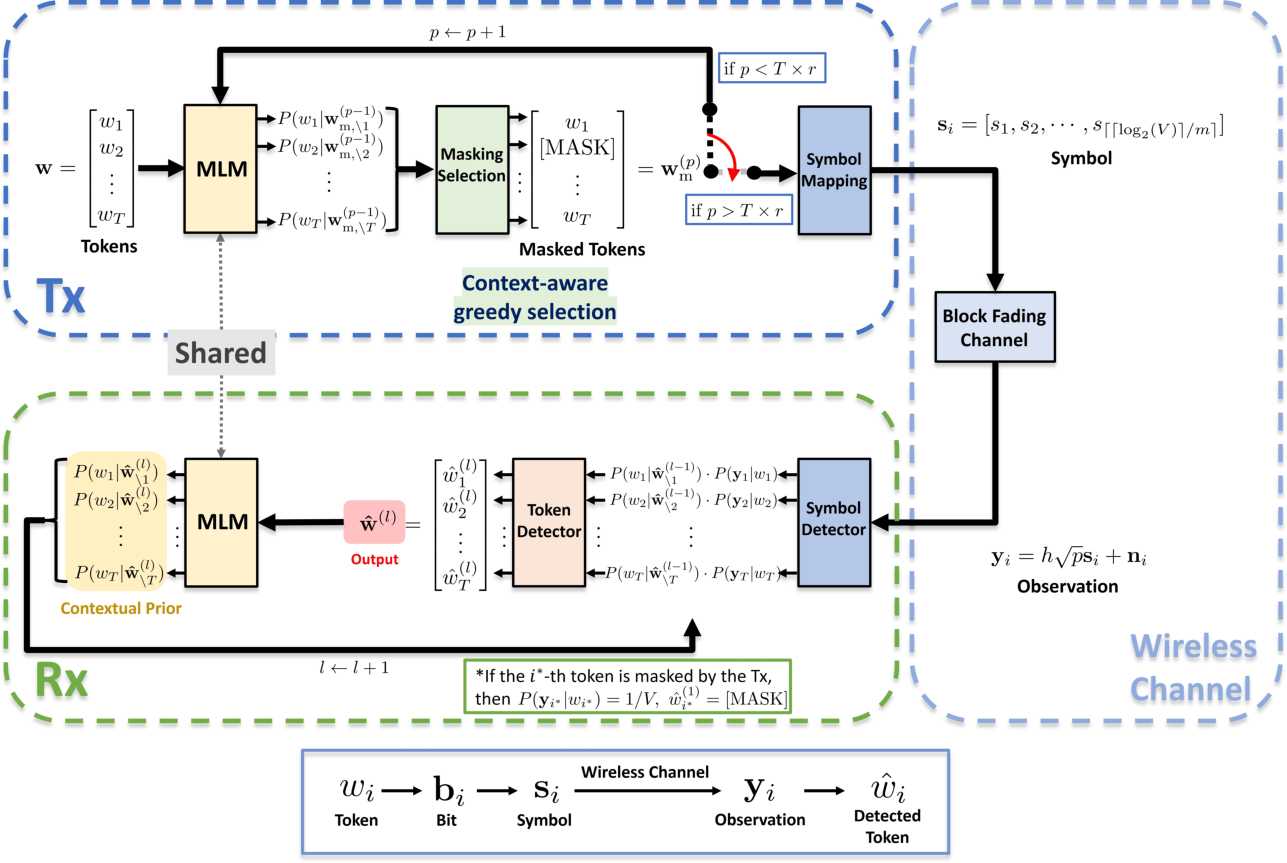
Figure 1: An illustration of the proposed token communication framework.
System Model
The system models a wireless channel where a sequence of language tokens is encoded, masked, and modulated using standard digital communication schemes (e.g., QAM) before experiencing Rayleigh block fading and AWGN. Crucially, a subset of tokens is masked at the Tx based on MLM-driven entropy metrics, reducing physical-layer bandwidth. The unmasked tokens are converted to binary, mapped onto signal constellations, and sent over the air. At the Rx, both the channel likelihoods and MLM-based priors are integrated to reconstruct the original sequence. Masked positions receive no physical channel observation, and their likelihoods are set uniformly over the vocabulary. The framework is agnostic to the tokenizer and modular in terms of modulation and channel models.
Context-Aware Inference and Masking
Iterative Bayesian Token Detection at the Receiver
The main technical innovation at the Rx is an iterative variant of MAP estimation for tokens. In each iteration, the Rx uses the MLM to compute conditional priors P(wi∣w^−i), leveraging the current hypothesis sequence. These priors are combined with the observed channel likelihoods P(yi∣wi) in a Bayesian posterior scoring, refining token estimates. The iterative process is analogous to turbo-style single-sequence approximations, where the maximization over all possible context sequences w−i is approximated by the current best sequence, addressing the intractable dependencies in natural language token sequences.
Context-Aware Masking at the Transmitter
At the Tx, the same MLM provides entropy scores quantifying the predictability of each token given the rest of the sequence. Tokens with the lowest entropy are greedily selected for masking, subject to a global masking ratio r. Only the non-masked tokens are encoded and transmitted. This entropy-based selection is justified by the capacity of the MLM to capture both local and long-range dependencies, which empirical results show preserves task-relevant semantic information even at high masking rates.
Experimental Results
The framework is evaluated on standard corpora (Europarl, WikiText-103), with BERT as the shared MLM and sentence-level cosine similarity (SIM) as the main measure of semantic fidelity between sent and reconstructed sequences. Modulation is performed with 16-QAM over Rayleigh fading.
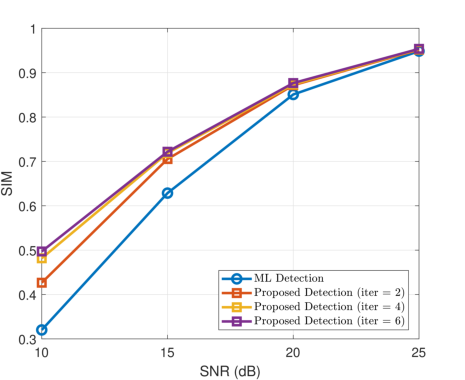
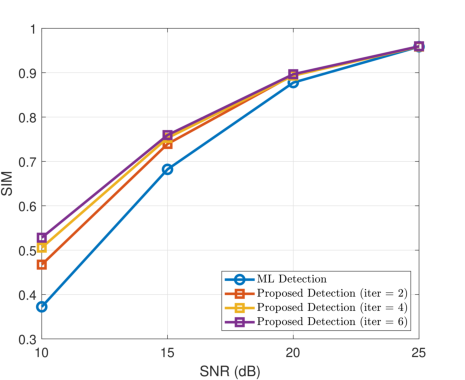
Figure 2: Performance of the proposed iterative token detection strategy (Rx-side only) under different iteration counts.
Results indicate substantial improvements over conventional maximum likelihood symbol detection, particularly at low SNR and under increasing numbers of Rx iterations. For full-token transmission (no masking), the iterative procedure yields up to 0.1769 (Europarl) and 0.1558 (WikiText-103) higher SIM over ML decoding, with diminishing returns beyond five iterations. This demonstrates the effective fusion of channel evidence and semantic priors in mitigating noise and fading.
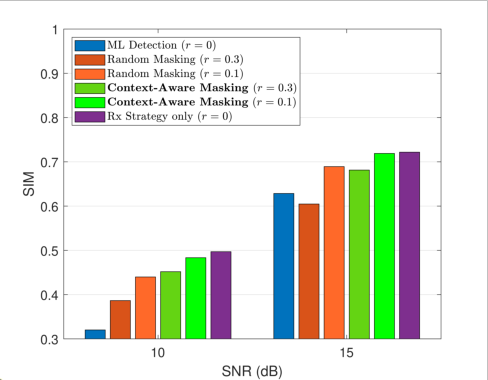
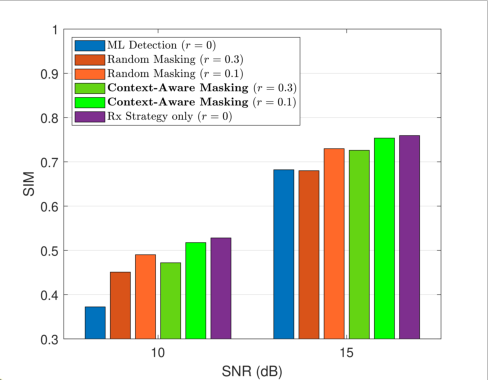
Figure 3: Performance comparison of the joint Tx–Rx strategy with different masking ratios and masking policies.
In the rate-adaptive regime, context-aware masking exhibits strong robustness compared to random masking baselines. At a masking ratio r=0.1, the joint Tx–Rx approach achieves minimal SIM degradation relative to full transmission, whereas random masking causes substantial semantic loss. Even for r=0.3, context-aware masking maintains significantly higher SIM, highlighting the importance of semantic redundancy selection rather than uninformed omission.
Theoretical and Practical Implications
The framework advances the integration of NLP-based priors into the wireless communication stack, formalizing semantic communication wherein probabilistic context models drive adaptation at both encoder and decoder. This closes the gap between context-agnostic physical layer methods and the requirements of language-based downstream tasks, offering a rigorous MAP-based interface adaptable to varying SNR and application relevance.
In practice, this line of work enables:
- Semantic-aware rate adaptation in language-oriented IoT, conversational AI, and collaborative edge devices.
- Joint source-channel coding mechanisms inherently robust to packet loss, erasure, and adversarial environments, as the context model can fill in semantic gaps.
- Extensions beyond text, motivating the use of large multimodal models as context priors in joint vision-language communication.
Conclusion
A Bayesian-contextual framework for wireless token transmission is introduced, leveraging MLM priors for both mask-based rate adaptation at the Tx and MAP-based iterative token detection at the Rx. Empirical results confirm improved semantic preservation and rate-efficiency under a range of challenging channel conditions. The modularity of the MLM prior paves the way for integrating more advanced or task-specific models, as well as the extension to multimodal and cross-lingual communication scenarios.

