- The paper introduces a novel TTS framework that uses discrete semantic and acoustic tokens to achieve precise text-speech alignment and high-fidelity synthesis.
- It employs a Token Transducer++ for robust linguistic alignment in the interpreting stage and a Group Masked Language Model for efficient acoustic token generation.
- Experiments on the LibriTTS dataset show significant improvements in MOS and CER over models like VITS and VALLE-X, highlighting enhanced speech clarity and speaker resemblance.
High Fidelity Text-to-Speech Via Discrete Tokens Using Token Transducer and Group Masked LLM
Introduction
The paper proposes a novel text-to-speech (TTS) framework that leverages discrete tokenization through two core stages: Interpreting and Speaking. The method employs two distinct types of tokens, semantic and acoustic, which enhances the fidelity of speech synthesis. The semantic tokens capture linguistic content and alignment, while the acoustic tokens are focused on the target voice's timbre, enhancing speech reconstruction. This process is empirically shown to outperform existing models, particularly in zero-shot scenarios where speech quality and speaker similarity are critical.
Method
The TTS framework is sequentially split into two stages: Interpreting and Speaking.
Interpreting Stage:
In the Interpreting stage, the framework utilizes semantic tokens to focus on linguistic details while ensuring alignment between text and speech. By employing a transducer-based architecture called Token Transducer++, the framework efficiently aligns text and semantic tokens, which also captures prosodic elements with high accuracy (Figure 1).
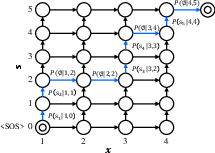
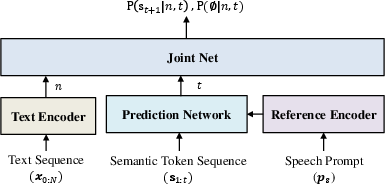
Figure 1: Alignment lattice of a transducer shows the robust alignment capabilities inherent in the proposed transducer modifications.
Speaking Stage:
The subsequent Speaking stage involves generating acoustic tokens using a Group Masked LLM (G-MLM) to capture acoustic details for high-fidelity speech synthesis. This stage employs parallel iterative sampling, which leverages a Group-Iterative Parallel Decoding (G-IPD) strategy designed for efficient decoding and superior generation quality (Figure 2).
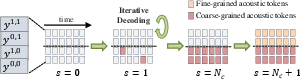
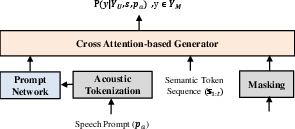
Figure 2: Group-Iterative Parallel Decoding (G-IPD) illustrates the method for efficient decoding of acoustic tokens.
Experimental Results
Experiments were conducted using the LibriTTS dataset in a zero-shot setup. The proposed architecture achieved superior results compared to several baselines, such as VITS and VALLE-X, with significant improvements in both MOS and CER. These improvements are driven by the robust alignment provided by the Token Transducer++ and the efficient synthesis enabled by the G-MLM.
The system showcased higher character error rates (CER) and speaker embedding cosine similarity (SECS) compared to existing models, which were aligned with manual subjective evaluations that demonstrated improved speech clarity and speaker resemblance.
| Method |
MOS |
SMOS |
CER |
SECS |
| Ground Truth |
4.21 ± 0.09 |
4.13 ± 0.10 |
0.97 |
0.653 |
| VITS |
3.52 ± 0.16 |
3.23 ± 0.20 |
4.81 |
0.385 |
| VALLE-X |
3.75 ± 0.14 |
3.08 ± 0.21 |
8.72 |
0.425 |
| Kim et al. (2024) |
3.69 ± 0.16 |
3.55 ± 0.21 |
2.47 |
0.467 |
| Proposed |
3.94 ± 0.14 |
3.64 ± 0.19 |
2.34 |
0.512 |
Framework Innovations and Future Directions
The modular design facilitating distinct handling of semantic and acoustic features allows for enhanced flexibility and performance. Each stage can be optimized for specific objectives—semantic for alignment and linguistic accuracy, and acoustic for audio fidelity and timbre diversity. Moreover, the framework can handle unlabeled datasets, expanding its versatility and applicability.
Future research will focus on extending this framework to multilingual TTS and broader speech generation tasks. Furthermore, exploring a larger dataset to bolster model generalization and performance will be a crucial direction.
Conclusion
This research presents a methodologically novel and empirically validated TTS framework that optimizes high-fidelity speech synthesis using discrete tokens. By treating semantic and acoustic features with distinct yet complementary architectural strategies, the system offers substantial benefits over existing approaches in fidelity and computational efficiency, establishing a foundation for future advancements in TTS technology.

