- The paper proves that interpolating estimators suffer a steep adversarial robustness penalty, even when achieving optimal standard risk.
- It establishes precise minimax bounds that delineate regimes based on interpolation tolerance, sample size, and perturbation magnitude.
- The work highlights that increasing sample size may worsen adversarial risk, while higher dimensions slightly mitigate this effect.
Adversarial Robustness and the Cost of Interpolation in Regression
Problem Setting and Motivation
The paper addresses the intersection of two modern phenomena in statistical learning: the empirical success of interpolating estimators—most notably deep neural networks (DNNs) trained to (nearly) zero training error—and their well-documented vulnerability to adversarial perturbations in input data. While the "benign overfitting" literature has shown that interpolation does not generally preclude minimax-optimal generalization under standard squared error loss, this does not extend to adversarial robustness.
The main contribution is a comprehensive minimax-rate analysis of adversarial robustness for interpolating estimators in nonparametric regression, focusing on how interpolation amplifies susceptibility to adversarial X-attacks. The paper rigorously characterizes the adversarial minimax risk for estimators that interpolate or nearly interpolate the training data, under the adversarial L2-risk. A striking takeaway is that, in contrast to the classical theory, interpolation almost always exacts a steep penalty in adversarial robustness.
Minimax Theory for Adversarial Risk of Interpolating Estimators
The adversarial L2-risk for an estimator f is formally defined as
Rr(f,f∗)=E[x′∈Bp(x,r)sup(f(x′)−f∗(x))2]
where Bp(x,r) is an ℓp-ball of radius r around x.
Over smooth regression classes (i.e., f∗ in a Hölder class), the paper recalls existing minimax rates for estimators unconstrained by interpolation. Under adversarial attack, the best possible risk is
r2(1∧β)+n−2β/(2β+d)
where r is the adversarial perturbation magnitude, β the smoothness parameter, d the input dimension, and n the sample size.
The critical advance here is addressing the risk for interpolating estimators, i.e., those fitting the training data up to tolerance δ. The core finding is that minimax risk for interpolators incurs an additional, irreducible term involving the local noise magnitude within adversarial balls, which is negligible only for very mild interpolation or extremely small attacks.
Phase Transition in Adversarial Risk
A major contribution is the precise delineation of regimes:
1. Low Interpolation Regime (Large δ)
If the interpolation tolerance δ≳(logn)1/2, the additional adversarial risk term decays sufficiently fast. The minimax rate for interpolators is then identical (up to constants) to the unconstrained case, even under adversarial perturbations: r2(1∧β)+n−2β/(2β+d)
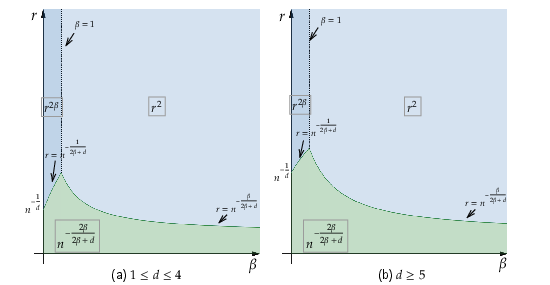
Figure 1: Minimax rate in the low interpolation regime for 1≤d≤4 and d≥5. The boxed areas highlight dominant rates as a function of r and n.
2. Moderate Interpolation Regime
If δ≪(logn)1/2, but still vanishing slowly, the excess adversarial risk decays subpolynomially, leading to arbitrarily slow convergence. In most practical settings, this means substantial loss of robustness.
3. High Interpolation Regime (Exact/Data-Noise-Level Interpolation)
For δ bounded below, i.e., approaching exact interpolation, the minimax rate is fundamentally worse: r2(1∧β)+n−2β/(2β+d)+nrd
For larger attacks, especially when nrd≫1, the risk becomes bounded away from 0 or even diverges, indicating the complete breakdown of adversarial robustness for interpolators, regardless of the specific interpolation rule.
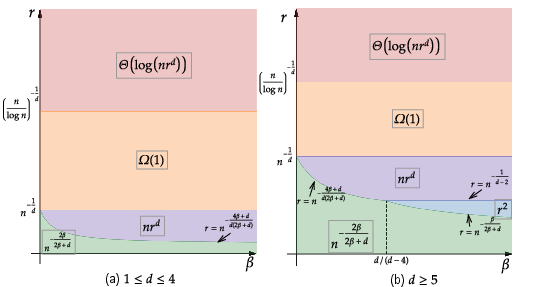
Figure 2: Minimax rate in the high interpolation regime for 1≤d≤4 and d≥5. The boxed areas describe the slower, often non-vanishing (or even diverging) adversarial risks induced by interpolation.
These results are algorithm-independent and apply to all measurable interpolators, ruling out the possibility that some "clever" interpolation strategy could evade this barrier.
The Curse of Sample Size and the Effect of Dimensionality
A particularly counterintuitive phenomenon revealed is the curse of sample size for interpolators under adversarial attack: increasing n can actually worsen adversarial risk, a stark departure from classical minimax theory where more data always helps. As n increases, the interpolator becomes more spiky (to fit more points exactly), exacerbating vulnerability to small input changes.
In contrast, increasing dimension d can have a mitigating effect on this phenomenon ("blessing of dimensionality"), because data points become more sparse, allowing for less spiky interpolants within local adversarial balls.
Numerical and Empirical Results
Simulation studies in one-dimensional regression demonstrate that classical nonparametric estimators and mildly interpolating variants preserve robustness under X-attack, but highly interpolating estimators—such as nearest neighbor, singular kernel, or minimum-norm neural networks—exhibit drastic inflation in adversarial risk, consistent with theory.
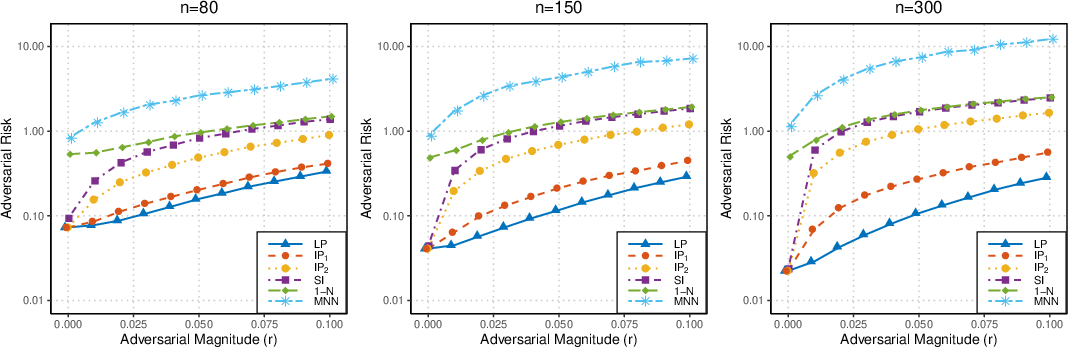
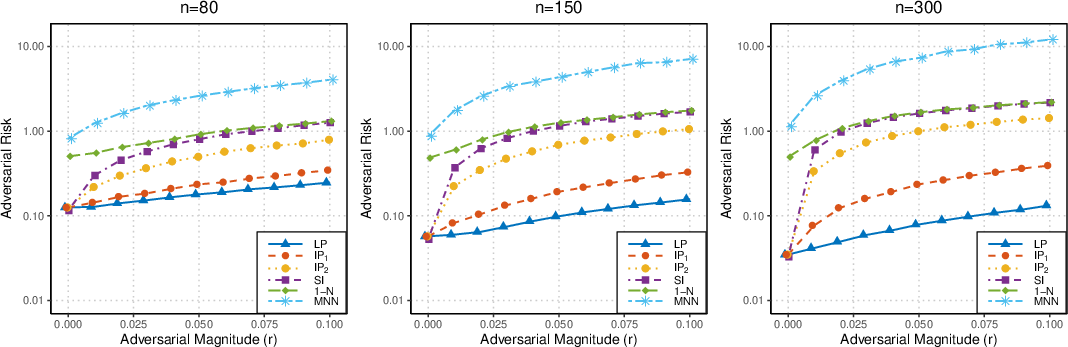
Figure 3: Adversarial risks of competing methods on synthetic regression problems across increasing adversarial radii and sample sizes.
Empirical results on the Auto MPG dataset with overparametrized neural networks further illustrate that as training error approaches zero, adversarial risk increases rapidly, even as standard test error remains stable. The curse of sample size is also observed for interpolators: with more data, adversarial vulnerability becomes more severe, whereas standard estimators continue to improve.
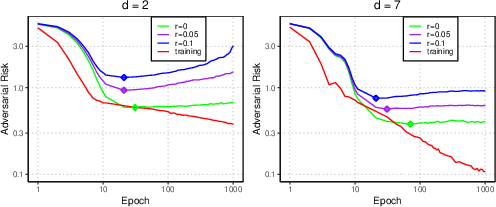
Figure 4: Standard and adversarial risks for neural networks across training epochs. Diamonds mark epochs of minimal risk.
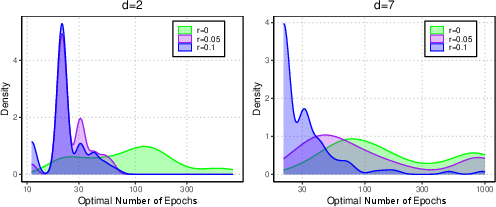
Figure 5: Distribution of epochs achieving minimal standard and adversarial risk over 100 runs. Robustness tends to be optimized considerably earlier than standard risk.
Theoretical and Practical Implications
The analysis establishes that interpolation, while benign for standard risk, is provably incompatible with minimax-optimal adversarial robustness in regression. This explains, at a fundamental level, the observed fragility of modern overparametrized models, such as DNNs, under adversarial X-attacks, regardless of architectural modifications. No choice of interpolating rule can overcome this limitation.
This has several implications:
- For theory: The pathological adversarial behavior of interpolating estimators is unavoidable in nonparametric settings, clarifying longstanding confusion in the literature about benign overfitting versus robustness.
- For methodology: Regularization via early stopping, adversarial training, or explicit anti-interpolation constraints is necessary for robustness. Strategies that deliberately avoid interpolation (e.g., through heavy regularization or limiting overparametrization) should be favored for safety-critical applications.
- For future research: The result motivates work on interpolator-robust methods and the development of principled regularization that can provide robust generalization, and a deeper investigation into the connection between spikiness, local Lipschitz properties, and input perturbation vulnerability.
Conclusion
This work rigorously delineates the fundamental, minimax limits of adversarial robustness for interpolating estimators in regression. It proves that interpolation, even if compatible with minimax rates under standard risk, cannot escape intrinsic vulnerability to adversarial X-attacks. For DNNs and related models, this establishes a theoretical basis for the empirical observation that perfect fitting models are inherently non-robust to perturbations of the covariates. This provokes a reevaluation of prevailing machine learning practices and highlights the necessity for robust, non-interpolating methodologies in adversarially sensitive domains.

