The Rise of Large Language Models and the Direction and Impact of US Federal Research Funding
Abstract: Federal research funding shapes the direction, diversity, and impact of the US scientific enterprise. LLMs are rapidly diffusing into scientific practice, holding substantial promise while raising widespread concerns. Despite growing attention to AI use in scientific writing and evaluation, little is known about how the rise of LLMs is reshaping the public funding landscape. Here, we examine LLM involvement at key stages of the federal funding pipeline by combining two complementary data sources: confidential National Science Foundation (NSF) and National Institutes of Health (NIH) proposal submissions from two large US R1 universities, including funded, unfunded, and pending proposals, and the full population of publicly released NSF and NIH awards. We find that LLM use rises sharply beginning in 2023 and exhibits a bimodal distribution, indicating a clear split between minimal and substantive use. Across both private submissions and public awards, higher LLM involvement is consistently associated with lower semantic distinctiveness, positioning projects closer to recently funded work within the same agency. The consequences of this shift are agency-dependent. LLM use is positively associated with proposal success and higher subsequent publication output at NIH, whereas no comparable associations are observed at NSF. Notably, the productivity gains at NIH are concentrated in non-hit papers rather than the most highly cited work. Together, these findings provide large-scale evidence that the rise of LLMs is reshaping how scientific ideas are positioned, selected, and translated into publicly funded research, with implications for portfolio governance, research diversity, and the long-run impact of science.
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Overview
This paper looks at how LLMs, like ChatGPT, are changing the world of US federal research funding. In simple terms: the authors wanted to know whether using AI to help write grant proposals affects which projects get money from the government and what kind of science gets done afterward.
Key Questions
The paper focuses on a few straightforward questions:
- Are more researchers using LLMs to write grant proposals and project summaries?
- Does using LLMs change how “different” or “original” their ideas look compared to what has been funded recently?
- Does LLM use help proposals get funded?
- After funding, do projects that used LLMs produce more scientific papers—and are those papers the most impactful?
How the Study Was Done (Methods)
Think of the research funding system like a pipeline:
- Step 1: Scientists write proposals to ask for money (submissions).
- Step 2: Some proposals get funded (awards).
- Step 3: Funded projects lead to papers and other results.
The authors studied LLM use at each step using two kinds of data:
- Private university data (submissions):
- They got confidential proposal abstracts from two large US research universities for both NSF (National Science Foundation) and NIH (National Institutes of Health).
- This included funded, unfunded, and pending proposals from 2021–2025.
- Public award data:
- They analyzed all publicly available NSF and NIH award abstracts from the same years.
- They also tracked the papers that came out of those awards.
How they detected LLM use (“alpha”):
- They took grant abstracts from 2021 (before LLMs became common).
- Then they asked an LLM (GPT-3.5) to rewrite those same abstracts.
- By comparing the word patterns in human-written text versus AI-rewritten text, they trained a detector to estimate how much LLM-style writing appears in later abstracts. They called this fraction “alpha” (α), where higher α means more signs of LLM involvement.
How they measured “distinctiveness”:
- Imagine the set of recently funded projects as a “map” of ideas.
- For each new proposal or award, they calculated how far its abstract is from the ideas funded in the previous year using a text-embedding tool (SPECTER2). Farther means more distinctive or original; closer means more similar.
How they tested relationships:
- They used statistical models to see how α (LLM use) relates to:
- Idea distinctiveness
- Getting funded (success)
- Later publications (output)
- They made careful comparisons by controlling for things like the field of science, the year, the investigators, and the amount of money requested or awarded.
Main Findings
Here are the key results the study found:
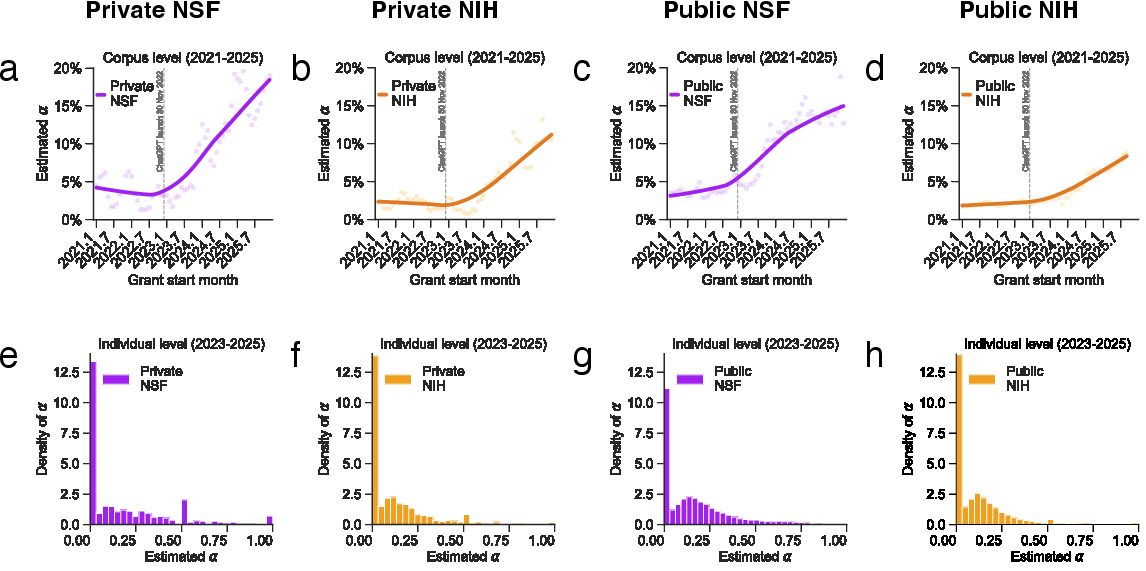
- LLM use rose quickly starting in 2023:
- This matches the public release of ChatGPT at the end of 2022.
- When looking at individual grants, LLM use showed a split: many abstracts used almost none, and a separate group used LLMs more substantially (a “bimodal” pattern). In other words, there’s a clear divide between minimal and notable use.
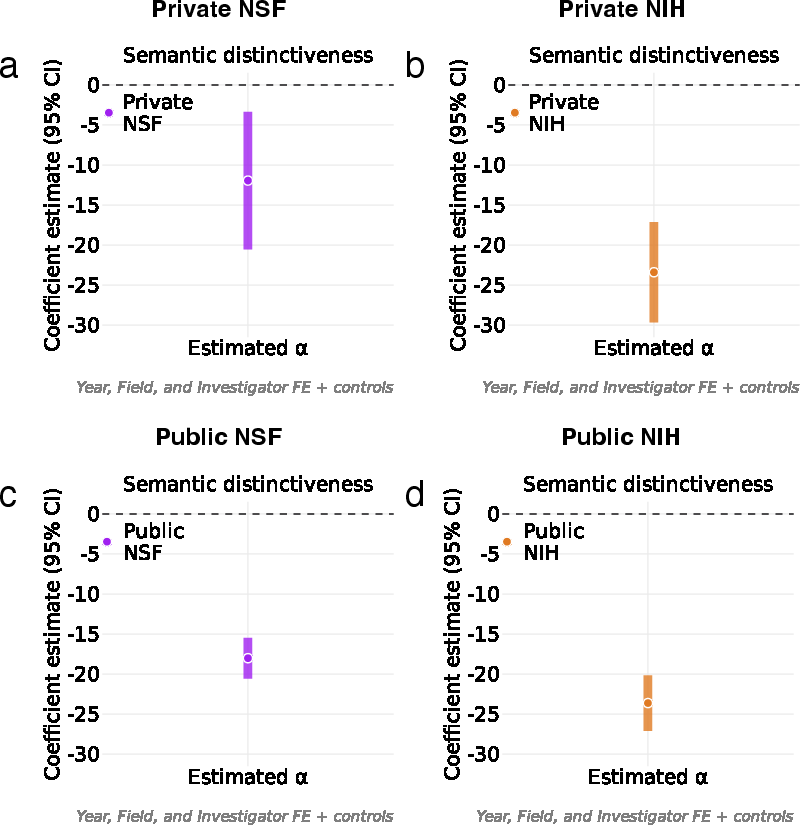
- More LLM use is linked to less distinctiveness:
- Across both NSF and NIH, proposals and awards with higher α tend to look more similar to ideas that were recently funded.
- Think of it like songwriting: with LLM help, more proposals start to sound like current chart-toppers rather than experimental new styles.
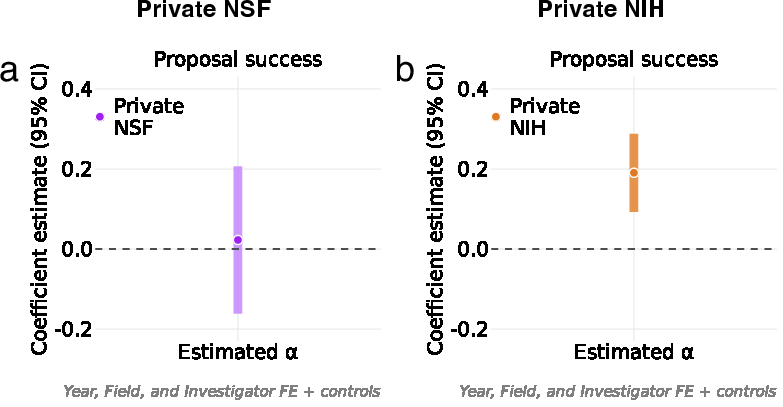
- Effects on funding success differ by agency:
- At NSF: LLM use did not significantly affect whether proposals got funded.
- At NIH: Higher LLM use was linked to a greater chance of getting funded (about a 4-percentage-point increase when moving from low to high LLM involvement).
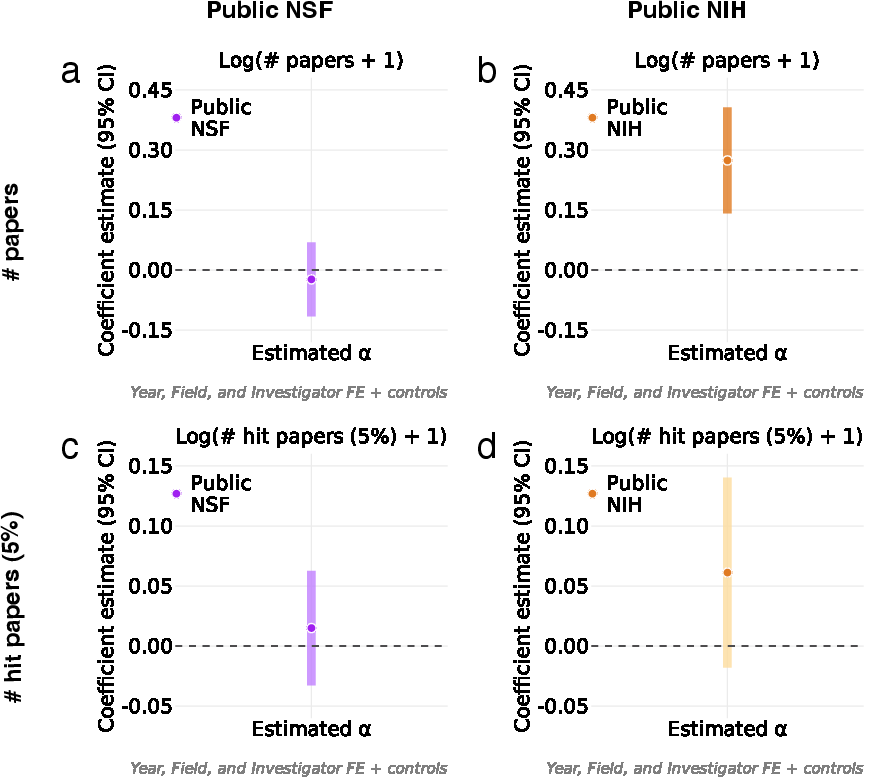
- Effects on publication output also differ by agency:
- At NSF: No clear link between LLM use and how many papers resulted.
- At NIH: More LLM use was associated with more papers published (around 5% more when moving from low to high LLM involvement).
- However, the extra papers were not concentrated among the most highly cited “hits.” In short, more output, but not necessarily more top-impact papers.
Why this matters:
- LLMs may make writing clearer and more aligned with what reviewers expect, which can help proposals succeed.
- But they can also pull ideas toward safer, more standard topics, potentially reducing the diversity of the research portfolio.
Implications and Impact
What does this mean for science and policy?
- Portfolio diversity: If LLMs push ideas to be more similar to past funding, agencies might back fewer bold, unusual projects. That could slow long-term breakthroughs.
- Different agency cultures: NIH (which often funds medical research) seems to reward LLM-polished proposals with more funding and more papers. NSF (which funds broader science and engineering) shows no clear advantage from LLMs in funding or papers. This suggests that how agencies review and value proposals shapes the effects of LLMs.
- Productivity vs. originality: LLMs may boost writing speed and clarity (communication), but that doesn’t guarantee bigger scientific breakthroughs (execution). Scientific progress also depends on experiments, data, tools, and teamwork—things LLMs don’t directly solve.
- Policy and trust: Because grants use public money, agencies are setting rules about AI use and originality. Clear disclosure and reviewer awareness could help protect originality while allowing helpful tools.
In short: LLMs are already changing how grant proposals are written and which projects get funded. They seem to help some proposals get selected and produce more papers (especially at NIH), but they also appear to make ideas less distinctive. Balancing these effects—productivity gains versus the need for exploration—is crucial for keeping science innovative in the long run.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a concise list of unresolved issues that future researchers could address to strengthen evidence, improve measurement, and clarify mechanisms.
- Causal identification is absent: develop quasi-experimental designs (e.g., agency- or program-specific policy shocks, campus rollouts of AI tools, reviewer assignment discontinuities) to estimate the causal effects of LLM use on proposal success and outputs.
- Abstract-only measurement: extend analyses to full proposals (Specific Aims, Project Description, Methodology, Broader Impacts) to capture LLM use beyond abstracts and test section-specific effects.
- Detection validity and coverage: validate the distributional detection method against ground-truth disclosures and multiple LLMs (GPT-4, Claude, domain-specific models), and quantify false positives/negatives, robustness to adversarial paraphrasing, and sensitivity to templated agency language.
- Model drift and prompt dependence: assess whether an α trained on GPT-3.5 rewrites generalizes to contemporaneous models and prompts used by investigators in 2023–2025; recalibrate α over time as model outputs evolve.
- Mechanisms behind NIH–NSF differences: empirically disentangle whether the observed agency gap stems from review norms, program objectives, proposal templates, project types (e.g., NIH R01 vs R21; NSF core vs instrumentation), or field composition.
- Reviewer-side AI use: measure whether and how reviewers use LLMs (e.g., for summary, critique, scoring), and test its impact on selection, distinctiveness, and inter-reviewer agreement.
- Distinctiveness construct validity: separate rhetorical homogenization from topical convergence by measuring distinctiveness on content (topic models, keyword novelty, prior art overlap) versus style (rhetorical features, discourse markers).
- Portfolio-level diversity: move from grant-level distinctiveness to portfolio-level concentration metrics (e.g., entropy, Herfindahl indices across topic clusters) to quantify system-wide exploration/exploitation shifts.
- Time horizon for impact: extend follow-up windows beyond 2024–2025 to evaluate delayed high-impact outputs (citations, breakthroughs), patents, clinical trials, translational milestones, and societal outcomes.
- Outputs beyond publications: incorporate non-publication outputs (software, datasets, instrumentation, training outcomes, patents, clinical endpoints) to capture NSF and NIH portfolio differences more comprehensively.
- Publication linkage accuracy: audit Dimensions’ grant–publication linkages (precision/recall), address misattribution, and triangulate with agency data (e.g., NIH RePORTER, NSF award reports).
- Field and subagency heterogeneity: conduct fine-grained analyses by program, mechanism, and subagency beyond high-level fields, including interactions with LLM use and programmatic priorities.
- Early-career and equity effects: test whether LLM use differentially affects proposal success and outputs by investigator demographics (career stage, institution type, underrepresented groups), potentially lowering barriers or reinforcing disparities.
- Institutional generalizability: expand confidential submissions beyond two R1 universities to diverse institution types (R2/R3, liberal arts, HBCUs, MSIs, industry partnerships) and geographic regions.
- Policy impacts and compliance: evaluate the effects of NIH’s July 2025 AI authorship guidance and NSF disclosure recommendations on LLM use, proposal success, and portfolio composition; measure disclosure rates and compliance.
- Intensity and modality of use: distinguish light copyediting vs substantive ideation/planning with validated self-reports or usage logs; relate use modes to distinctiveness, success, and outputs.
- Program-type controls: incorporate grant mechanism and duration (e.g., NIH R, K, U; NSF CAREER, instrumentation) to reduce confounding by project type when relating LLM use to success and outputs.
- Semantic baselines and windows: test distinctiveness against multi-year historical baselines, domain-specific embeddings, and alternative distance metrics to ensure conclusions are not an artifact of the one-year SPECTER2 cosine measure.
- Potential confounders: control for contemporaneous factors (e.g., COVID-era backlogs, field-specific funding booms, topical calls) that may jointly affect proposal language, success, and outputs.
- Bimodal adoption drivers: identify determinants of the observed bimodality in α (training access, institutional policies, team composition, grant-writing support) and its consequences for selection and productivity.
- Reviewer expectations and templates: quantify whether LLMs push proposals toward reviewer-favored templates and whether template conformity mediates NIH’s positive association with success and outputs.
- Misuse and integrity risks: examine whether heavy LLM use correlates with problematic outcomes (plagiarism, retractions, reproducibility concerns), and whether detection/disclosure mitigates these risks.
- International and agency scope: test whether findings generalize to other US agencies (DOE, DARPA, USDA) and international funders (UKRI, ERC), accounting for different review cultures and outputs.
- Budgeting and administrative sections: assess LLM impacts on non-scientific parts of proposals (budgets, biosketches, facilities) and whether improvements there influence success rates.
- Longitudinal investigator adaptation: track whether investigators alter topic choice, risk profiles, or collaboration strategies with increasing LLM use, and whether such adaptation affects long-run impact.
- Threshold effects: test for non-linear or threshold relationships between α and outcomes (e.g., minimal vs “substantive” use), including potential diminishing returns or negative effects at high α.
- Transparency and detection feedback loops: study whether public detection and disclosure policies change author behavior (e.g., obfuscation, style randomization), and how that impacts portfolio diversity and review reliability.
Glossary
- Award abstract: A funded grant’s summary text used as input for analyses of language and LLM involvement. "For each funded award, the datasets include the award abstract text, which serves as the primary textual input for estimating LLM involvement at the award stage."
- Bimodal distribution: A statistical distribution with two distinct peaks, indicating two dominant levels of usage or behavior. "it features a bimodal distribution, with one mode near zero and a second centered around roughly 10-15\%."
- Bottlenecks perspective: An analytical viewpoint emphasizing limiting frictions (e.g., data collection, coordination) that constrain progress despite upstream gains. "a bottlenecks perspective further suggests caution in extrapolating writing-related productivity gains to downstream scientific outputs"
- Citation percentiles: Field- and year-normalized ranks that position a paper’s citations relative to peers. "based on field- and year-normalized citation percentiles, where citations are measured as cumulative citations through November 2025."
- Co-PI: A co–principal investigator who shares leadership responsibilities on a grant. "both PI and co-PI identifiers are provided directly by Dimensions."
- Corpus-level: Analysis performed on pooled collections of text rather than single documents, to estimate aggregate patterns. "At the corpus level, we pool grant abstracts for each focal month and its two adjacent months"
- Cosine distance: A similarity measure based on the angle between embedding vectors, used to assess semantic closeness. "average cosine distance (using SPECTER2 embeddings, an established embedding method for scientific texts) to all abstracts funded in the previous year within the same agency."
- Dimensions: A research information platform that links grants to publications via acknowledgments, enabling large-scale analyses. "Dimensions (https://www.dimensions.ai/) is a large-scale, integrated research information platform that uniquely enables systematic linking of research grants to their resulting publications through funding acknowledgment data"
- Distributional LLM-quantification framework: A method to estimate LLM involvement by modeling token distributions of human vs. LLM-modified text. "using the distributional LLM-quantification framework introduced by Liang et al."
- Exploration and exploitation: The trade-off between pursuing novel ideas (exploration) and leveraging established ones (exploitation). "shift the balance between exploration and exploitation in scientific funding"
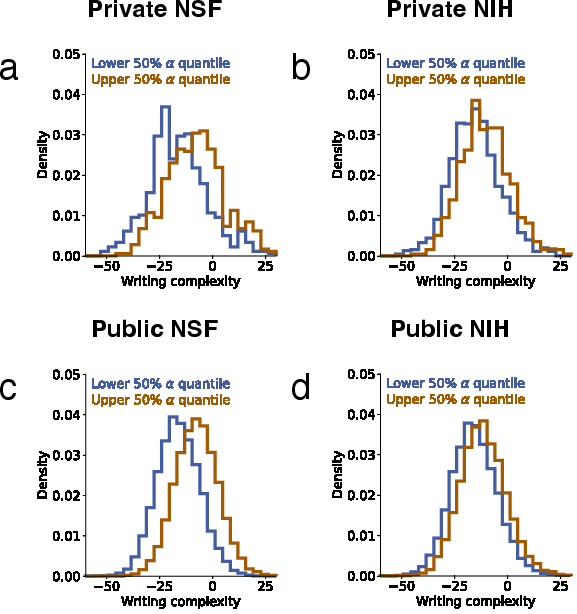
- Flesch Reading Ease score: A readability metric based on sentence length and syllable count; higher (original) scores mean easier text. "we compute the Flesch Reading Ease score for each abstract as a measure of writing complexity"
- Field fixed effects: Regression controls that absorb time-invariant differences across scientific fields. "all specifications include investigator fixed effects η_j, field fixed effects φ_f, and grant start year fixed effects μ_t."
- Funding acknowledgment data: Publication metadata linking papers to grants via funding statements. "systematic linking of research grants to their resulting publications through funding acknowledgment data"
- Funding frontier: The recent boundary of funded work in an agency, used as a reference to assess distinctiveness. "relative to the agency's recent funding frontier"
- Hit paper: A high-impact publication defined by citation thresholds (e.g., top 5% within field and year). "a ``hit'' paper is defined as one whose citations fall within the top 5\% of all papers published worldwide in the same year and field."
- Institutional Review Board (IRB): A committee that reviews and approves research involving human subjects for ethical compliance. "approved by Institutional Review Board of Northwestern University (IRB no. STU00222200)."
- Investigator fixed effects: Regression controls that absorb time-invariant differences across investigators (e.g., ability, style). "include grant start year, field, and investigator (PI and co-PI) fixed effects"
- L2 metric: A distance measure based on Euclidean geometry used to compare embeddings. "we also compute distances using L2 metrics and obtain consistent results"
- LLMs: AI models trained on vast text corpora to generate and revise human-like language. "LLMs are rapidly diffusing into scientific practice"
- Locally weighted regressions: Nonparametric fits that weight nearby points more heavily to trace trends. "Solid lines show locally weighted regressions."
- Logistic regressions: Statistical models for binary outcomes (e.g., success vs. failure). "We re-estimate proposal success using logistic regressions"
- Maximum likelihood estimator (MLE): A statistical procedure that chooses parameter values maximizing observed-data likelihood. "the fraction is estimated by the maximum likelihood estimator (MLE) on the observed sentences"
- Mixture distribution: A probability distribution combining multiple component distributions via mixing weights. "The mixture distribution is given by"
- Negative binomial regressions: Count-data models used when variance exceeds the mean (overdispersion). "publication outputs using negative binomial regressions"
- Ordinary least squares (OLS): A linear regression method minimizing squared errors to estimate relationships. "In our primary specifications, we use ordinary least squares regressions."
- Percentile rank: A 0–100 position indicating how a value compares within a reference distribution. "Defined as the percentile rank (ranging from 0 to 100, with higher values indicating greater distinctiveness)"
- Preprint platforms: Online repositories for early versions of research papers prior to formal publication. "sharp increases in scientific production across major preprint platforms"
- Principal Investigator (PI): The lead researcher responsible for a grant’s design and execution. "One university provides principal investigator (PI) names only"
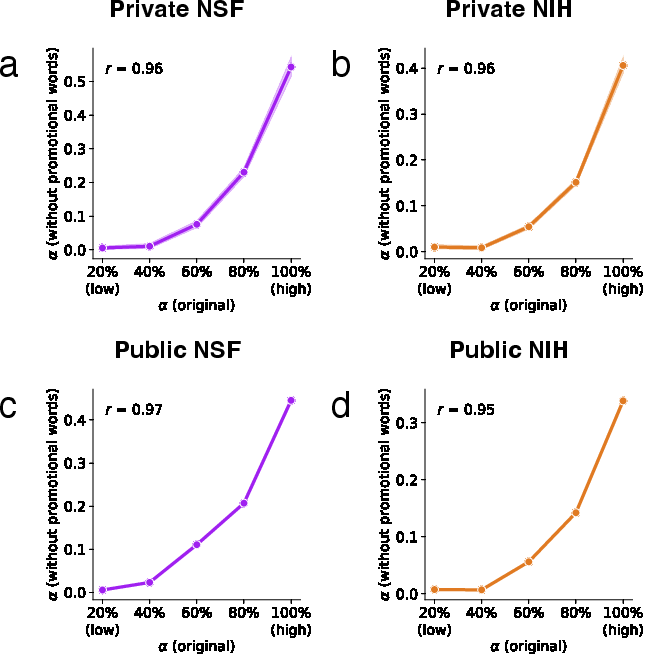
- Promotional language: Rhetorical wording intended to make proposals more compelling or persuasive. "the use of promotional language in grant proposals is positively associated with funding outputs"
- Proposal success: The outcome of a submission being funded rather than unfunded. "we regress proposal success on proposal-level LLM involvement ()"
- R1 university: A Carnegie Classification tier indicating very high research activity institutions. "from two large US R1 universities"
- Rolling three-month windows: Temporal aggregation method pooling data across consecutive months to estimate trends. "computed using rolling three-month windows (points)."
- SPECTER2 embeddings: Transformer-based vector representations tailored for scientific texts. "using SPECTER2 embeddings"
- Semantic distinctiveness: The degree to which an abstract’s content differs from recently funded work. "we measure the semantic distinctiveness of each proposal or award abstract (D1-D4) relative to the agency's recent funding frontier"
- Semantic space: The embedding vector space in which textual similarity and distance are computed. "positioned closer, in semantic space, to recently funded work within the same agency."
- Subagency: A division within a larger funding agency used for more granular analysis. "robustness checks by subagency"
- Token occurrence probabilities: The likelihoods that specific tokens appear, used to parameterize source distributions. "The occurrence probabilities of each token in human-written and LLM-modified sentences, and , are used to parameterize"
- Transformer-based embeddings: Text representations produced by transformer models for semantic comparisons. "building on recent work using transformer-based embeddings"
- Within-year percentiles: Percentile measures computed relative to grants funded in the same year. "We then convert these distances into within-year percentiles"
- Word distribution: The statistical frequency of words in a corpus, used to characterize writing sources. "we estimate the word distribution of human-written text"
Practical Applications
Immediate Applications
Below are actionable applications that can be deployed now based on the paper’s findings, organized across industry, academia, policy, and daily practice.
- Government/Policy — Portfolio monitoring dashboards
- Application: Build an “LLM Trace + Distinctiveness Monitor” that tracks agency-level trends in LLM involvement and semantic distinctiveness over time to detect portfolio homogenization.
- Sector: Public sector, science policy
- Tools/Products/Workflows: Dashboard + API using Liang-style LLM-trace quantification and SPECTER2 embeddings; monthly/quarterly portfolio reports; reviewer briefing packs.
- Assumptions/Dependencies: Access to award abstracts and linked publications (e.g., Dimensions); compute for embeddings; continued validity of LLM-trace detection; agency buy-in.
- Academia — Pre-submission “Distinctiveness Checker”
- Application: University research offices provide a checker that compares proposal abstracts to last-year funded abstracts at NSF/NIH and suggests edits to increase semantic distinctiveness.
- Sector: Higher education, research administration
- Tools/Products/Workflows: Grant-writing plugin; institutional server scoring; protected corpora per agency; red-teaming prompts to avoid over-alignment.
- Assumptions/Dependencies: Access to up-to-date award abstracts; privacy-safe handling of proposal text; researcher adoption; field-appropriate embeddings.
- Reviewer training and rubric updates
- Application: Train panels to recognize LLM-mediated writing patterns (e.g., increased fluency but decreased distinctiveness) and adjust rubrics to reward originality.
- Sector: Public sector, professional education
- Tools/Products/Workflows: Online modules; case studies; rubric templates emphasizing exploration.
- Assumptions/Dependencies: Agency willingness to update criteria; time to train reviewers; consensus on metrics.
- Compliance and disclosure workflows in grant portals
- Application: Add AI-use disclosure fields and automated tagging of detectable LLM traces; route flagged proposals for targeted review.
- Sector: Government IT, software
- Tools/Products/Workflows: Portal enhancements; provenance logs; “AI-use attestation” forms aligned with NIH NOT-OD-25-132 and NSF guidance.
- Assumptions/Dependencies: Policy alignment across agencies; avoidance of false positives/negatives; investigator acceptance.
- NIH-focused grant-writing assistants with originality guardrails
- Application: Offer assistants that help structure NIH proposals to successful templates while nudging toward distinctive framing and avoidance of prohibited “substantial AI development.”
- Sector: Healthcare/biotech, academia
- Tools/Products/Workflows: Writing assistant tuned to NIH norms; originality checks; automated disclosure tracking.
- Assumptions/Dependencies: Rapidly evolving NIH rules; field-specific conventions; responsible-use policies.
- University seed-funding allocation using diversity signals
- Application: Use distinctiveness metrics to prioritize internal seed grants that diversify the local research portfolio.
- Sector: Higher education, research strategy
- Tools/Products/Workflows: Portfolio heatmaps; seed-grant dashboards; faculty reporting.
- Assumptions/Dependencies: Cultural acceptance of algorithmic inputs; calibration by field; governance safeguards.
- Grant consulting for biotech/pharma targeting NIH success
- Application: Commercial services optimize proposal language and structure for NIH where LLM involvement correlates with higher success and more publications.
- Sector: Healthcare, professional services
- Tools/Products/Workflows: NIH “GrantFit” optimization; distinctiveness scorecards; disclosure pathways.
- Assumptions/Dependencies: Ethical compliance; risk of homogenization; sensitivity to subagency norms.
- Lab planning for NIH-funded teams
- Application: Anticipate slightly higher publication counts (mostly non-hit papers) when LLMs aid proposal preparation; adjust project management, author order, and dissemination plans accordingly.
- Sector: Academia, healthcare
- Tools/Products/Workflows: Output forecasting; milestone tracking; journal targeting for mid-impact venues.
- Assumptions/Dependencies: Field-specific variability; limits of short follow-up windows; execution bottlenecks.
- Agency portfolio diversity targets (“exploration quotas”)
- Application: Set minimum thresholds for high-distinctiveness awards within program portfolios to counterbalance homogenization.
- Sector: Public sector
- Tools/Products/Workflows: Distinctiveness scoring gates; program-level KPIs; periodic audits.
- Assumptions/Dependencies: Political feasibility; reviewer calibration; program heterogeneity.
- Publishing and funder screening for AI-induced monoculture
- Application: Journals and philanthropic funders add optional distinctiveness checks to encourage varied contributions and avoid template-driven text.
- Sector: Publishing, philanthropy
- Tools/Products/Workflows: Screening plug-ins; reviewer prompts; portfolio analytics.
- Assumptions/Dependencies: Access to relevant corpora; editorial workflows; community acceptance.
- Document provenance logging
- Application: Embed provenance tracking in institutional document workflows to record AI assistance and human edits.
- Sector: Software, compliance
- Tools/Products/Workflows: Version control with AI flags; tamper-evident logs; exportable disclosures.
- Assumptions/Dependencies: Integration with authoring tools; privacy safeguards; interoperability standards.
- Grant-writing curricula
- Application: Teach students and PIs how to use LLMs for clarity while preserving semantic distinctiveness; include hands-on exercises with detectors.
- Sector: Education
- Tools/Products/Workflows: Course modules; sandbox scoring; ethical guidelines.
- Assumptions/Dependencies: Instructor capacity; evolving best practices; access to detectors.
- Adoption by private and philanthropic funders
- Application: Extend dashboards and distinctiveness checks to foundations and corporate R&D grant programs.
- Sector: Finance/philanthropy, industry R&D
- Tools/Products/Workflows: SaaS analytics; flexible corpora; portfolio reports.
- Assumptions/Dependencies: Data availability; cross-domain embeddings; customization needs.
Long-Term Applications
Below are applications that will require further research, scaling, standard-setting, or infrastructure changes before widespread deployment.
- Standardized AI provenance and audit infrastructure
- Application: Establish interoperable provenance metadata (and potential watermarking) for proposals, with audit trails across agencies and institutions.
- Sector: Government IT, software standards
- Tools/Products/Workflows: Provenance ledger; cryptographic signatures; cross-agency APIs.
- Assumptions/Dependencies: Standards bodies involvement; privacy/legal frameworks; vendor cooperation.
- Peer-review redesign to reward distinctiveness
- Application: Pilot revised criteria and scoring systems that explicitly value semantic novelty, calibrated by field risk appetite.
- Sector: Policy/governance
- Tools/Products/Workflows: RCTs of review rubrics; reviewer decision support; program-specific weights.
- Assumptions/Dependencies: Rigorous evaluation; reviewer training; acceptance by scientific communities.
- Adaptive funding calls with real-time portfolio analytics
- Application: Dynamically modulate calls (e.g., topic emphases, risk tiers) in response to observed homogenization.
- Sector: Public sector
- Tools/Products/Workflows: Live portfolio dashboards; call-parameter tuning; oversight committees.
- Assumptions/Dependencies: Regulatory flexibility; reliable detection; careful change management.
- End-to-end “distinctiveness-aware” grant platforms
- Application: Integrate assistants that suggest evidence and framing to raise originality while checking compliance and disclosure end-to-end.
- Sector: Software, research administration
- Tools/Products/Workflows: Unified proposal editors; compliance engines; portfolio risk monitors.
- Assumptions/Dependencies: Secure access to agency corpora; trust and usability; sustained funding.
- Cross-agency comparative modeling of LLM impacts
- Application: Develop models predicting where LLM use increases proposal success and outputs (like NIH) versus neutral effects (like NSF), informing agency-specific best practices.
- Sector: Academia, policy analysis
- Tools/Products/Workflows: Multi-agency datasets; causal inference pipelines; annual reports.
- Assumptions/Dependencies: Access to confidential submissions; harmonized metadata; longitudinal tracking.
- Tools that target execution bottlenecks (beyond writing)
- Application: AI systems for experiment design, protocol optimization, data collection, and coordination to translate writing productivity into higher-impact outputs.
- Sector: Healthcare/biotech, robotics/automation, software
- Tools/Products/Workflows: Lab automation planning; data pipeline assistants; project orchestration agents.
- Assumptions/Dependencies: Domain-specific data; safety and validation; integration with lab equipment and IRB processes.
- Community benchmarks for portfolio diversity
- Application: Define consensus metrics for exploration/exploitation balance, publish annual diversity indices for public funders.
- Sector: Academia, policy
- Tools/Products/Workflows: Benchmark datasets; open-source metric libraries; transparency dashboards.
- Assumptions/Dependencies: Agreement on measures; avoidance of gaming; cross-field comparability.
- Ethics and authorship norms updates
- Application: Clarify what counts as “original work” under AI assistance, harmonize disclosure norms across agencies and journals.
- Sector: Policy, education, publishing
- Tools/Products/Workflows: Codes of conduct; accreditation frameworks; training materials.
- Assumptions/Dependencies: Stakeholder consensus; legal compatibility; international alignment.
- Longitudinal impact evaluations
- Application: Track whether LLM-associated increases in publication volume at NIH eventually translate into more high-impact outputs over multi-year horizons.
- Sector: Academia, policy evaluation
- Tools/Products/Workflows: Cohort studies; matched award analyses; impact dashboards.
- Assumptions/Dependencies: Time to accrue citations; stable linking between awards and outputs; evolving citation norms.
- Agency-specific LLM strategies
- Application: Develop tailored guidelines for NSF vs NIH (and subagencies), aligning AI use with mission emphasis (e.g., NSF’s diverse outputs vs NIH’s publication-heavy outputs).
- Sector: Policy, research administration
- Tools/Products/Workflows: Field-informed playbooks; subagency briefings; periodic revisions.
- Assumptions/Dependencies: Continuous evidence gathering; stakeholder feedback; adaptive governance.
- Funding instruments for high-risk research (e.g., “exploration insurance”)
- Application: Create mechanisms that offset portfolio tilt toward “safe” ideas by underwriting higher-variance proposals.
- Sector: Finance/policy innovation
- Tools/Products/Workflows: Risk-adjusted grant lines; milestone-based tranches; outcome-contingent bonuses.
- Assumptions/Dependencies: Budget flexibility; fair selection algorithms; political support.
- Congressional and public accountability dashboards
- Application: Provide oversight bodies with visibility into AI’s effect on portfolio diversity and downstream outputs.
- Sector: Government oversight
- Tools/Products/Workflows: Public dashboards; annual briefings; open data portals.
- Assumptions/Dependencies: Legislative mandates; data-sharing agreements; careful communication.
- LLM output diversification tools
- Application: Develop generation strategies (prompting, fine-tuning, sampling controls) that reduce template conformity and increase idea variance in proposals.
- Sector: Software/AI
- Tools/Products/Workflows: “Idea perturbation” engines; novelty-seeking prompts; diversity regularization.
- Assumptions/Dependencies: Robustness against failure modes; user education; evaluation benchmarks.
Collections
Sign up for free to add this paper to one or more collections.

