- The paper introduces the 'Locate, Steer, and Improve' framework as a systematic method for diagnosing and intervening in LLMs.
- It details diverse localization methods, including magnitude analysis and causal attribution, to isolate key model components.
- The paper demonstrates actionable applications in safety, capability, and efficiency while highlighting challenges in scaling and evaluation.
Actionable Mechanistic Interpretability in LLMs: A Unified Framework
Introduction and Motivation
Mechanistic interpretability (MI) has evolved from a primarily observational science to an operational toolkit for intervening in and optimizing LLMs. "Locate, Steer, and Improve: A Practical Survey of Actionable Mechanistic Interpretability in LLMs" (2601.14004) proposes a systematic, actionable framework—articulated as “Locate, Steer, and Improve”—that enables researchers not only to diagnose internal model mechanisms, but also to execute targeted interventions with concrete model improvement objectives.
The paper offers a taxonomy of interpretable objects, diagnostic (localization) methods, and intervention (steering) techniques, then contextualizes MI within practical tasks such as alignment, capability enhancement, and efficiency. It concludes by outlining theoretical and computational challenges and by identifying open problems in scaling, evaluation, and robustness.
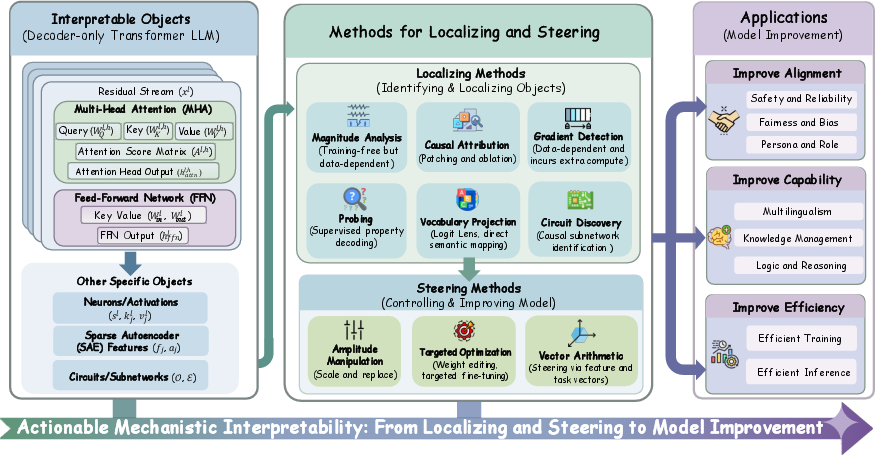
Figure 2: Overview of the paper structure, establishing the progression from identifying core objects, through localization and steering methods, to practical applications.
Core Interpretable Objects in LLMs
The paper codifies the main categories of MI targets as “interpretable objects”: token embeddings, the residual stream, transformer blocks (multi-head attention and FFN), neurons, and Sparse Autoencoder (SAE) features. SAEs are particularly emphasized for their utility in disentangling polysemantic dense activations into sparse, interpretable, monosemantic features.
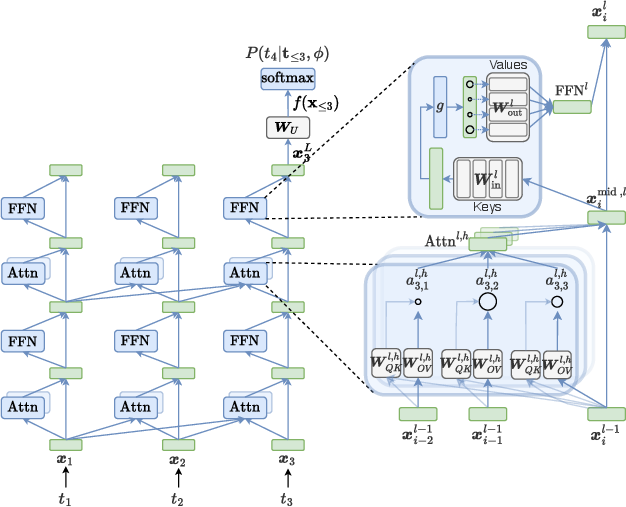
Figure 1: Information flow schematic for a Transformer block—the residual stream mediates iterative updates by MHA and FFN submodules, structuring computation for MI analysis.
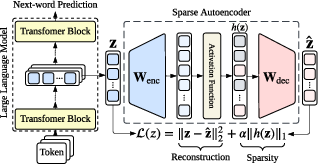
Figure 3: SAE modules can expand dense activations into high-dimensional sparse features, enabling interpretable conceptual decomposition within a frozen LLM.
Localization Methods: From Heuristics to Causal Attribution
Magnitude Analysis
Magnitude analysis provides a training-free, data-dependent heuristic for initial screening: components with large magnitude activations (neurons, attention heads, SAE features) are likely to mediate salient behaviors. This method rapidly narrows the search space for more computationally expensive analyses.
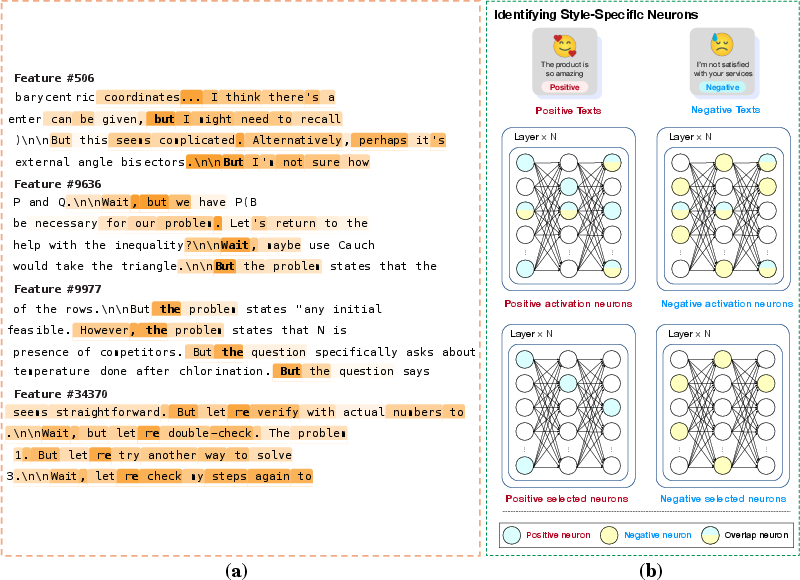
Figure 4: Case studies demonstrating the selection of reasoning-relevant SAE features or style-specific neurons via magnitude-based analysis.
Causal Attribution
Causal attribution is the gold standard for localizing model mechanisms responsible for a behavior. Through interventions such as patching (restoring or swapping activations) and ablation (zeroing), causal mediation analysis quantifies the necessity and sufficiency of specific components. This approach is fundamentally more computationally intensive than magnitude analysis but yields explicit, intervention-relevant evidence.
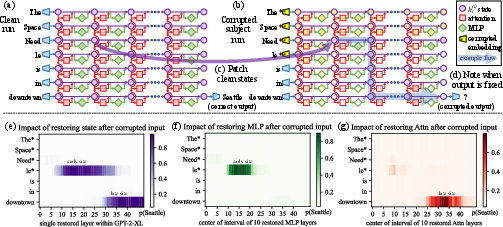
Figure 5: Causal tracing for factual recall, revealing two-stage mediation—early FFN retrieval and late attention transport—by heatmapping indirect effects of state restoration.
Gradient Detection
Gradient-based localization leverages the sensitivity of a scalar target (e.g., prediction probability or loss) to internal components, serving as a scalable proxy for more expensive interventions. Integrated gradients and related techniques facilitate ranking candidate objects for downstream causal analysis.
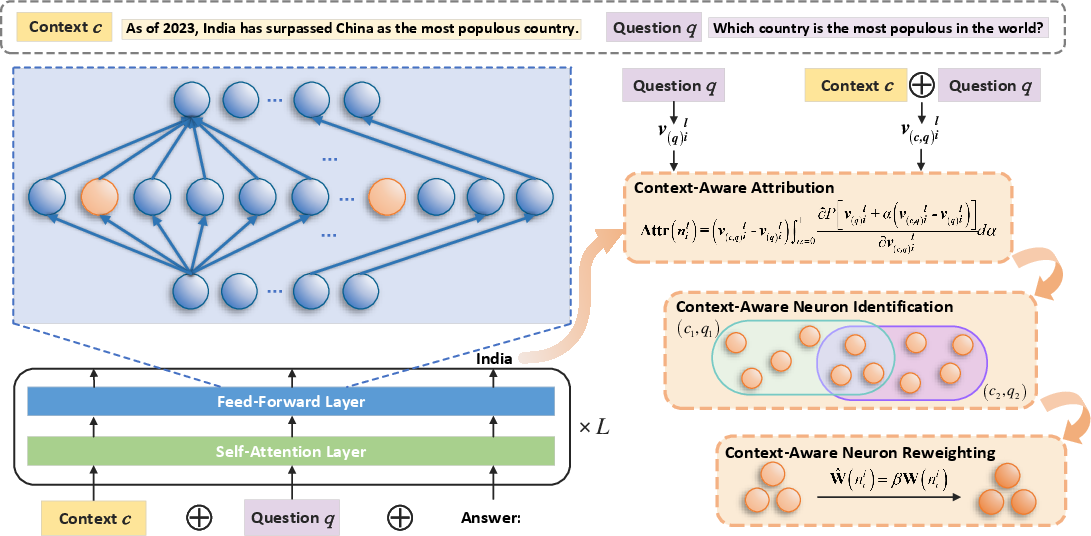
Figure 6: Layerwise neuron attribution via integrated gradients localizes context-aware neurons for knowledge conflict mitigation.
Probing and Vocabulary Projection
Probing uses supervised auxiliary predictors to assess decodability of target properties from intermediate activations, while vocabulary projection (e.g., Logit Lens) interprets hidden states in terms of output distribution, supporting semantic inspection and layerwise signal tracing.
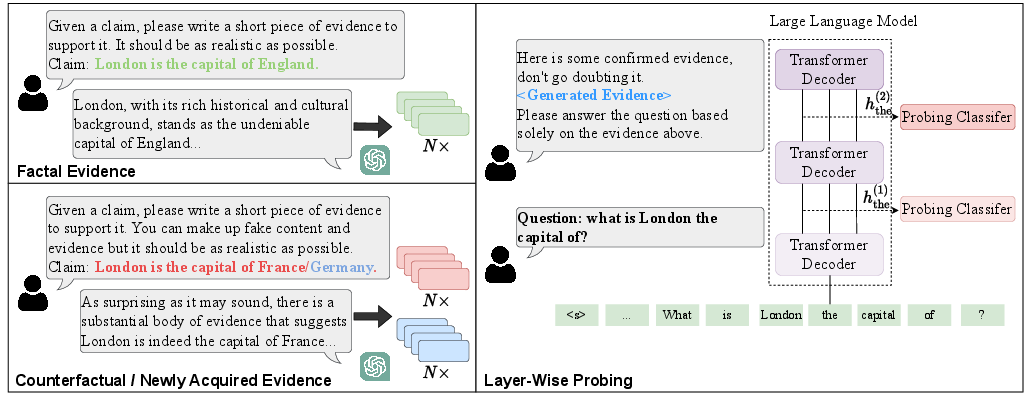
Figure 7: Probing pipeline for context knowledge, mapping knowledge signal decodability layerwise.

Figure 8: Projections of residual stream states reveal the evolution of latent concepts and language bottlenecks, informative for cross-lingual analysis.
Circuit Discovery
Mechanistic circuit discovery reconstructs structured, directed subgraphs that instantiate specific behaviors, aligning residual updates with functional pathways. Techniques include both brute-force edge interventions and scalable intermediary-tracing with sender/receiver attribution.
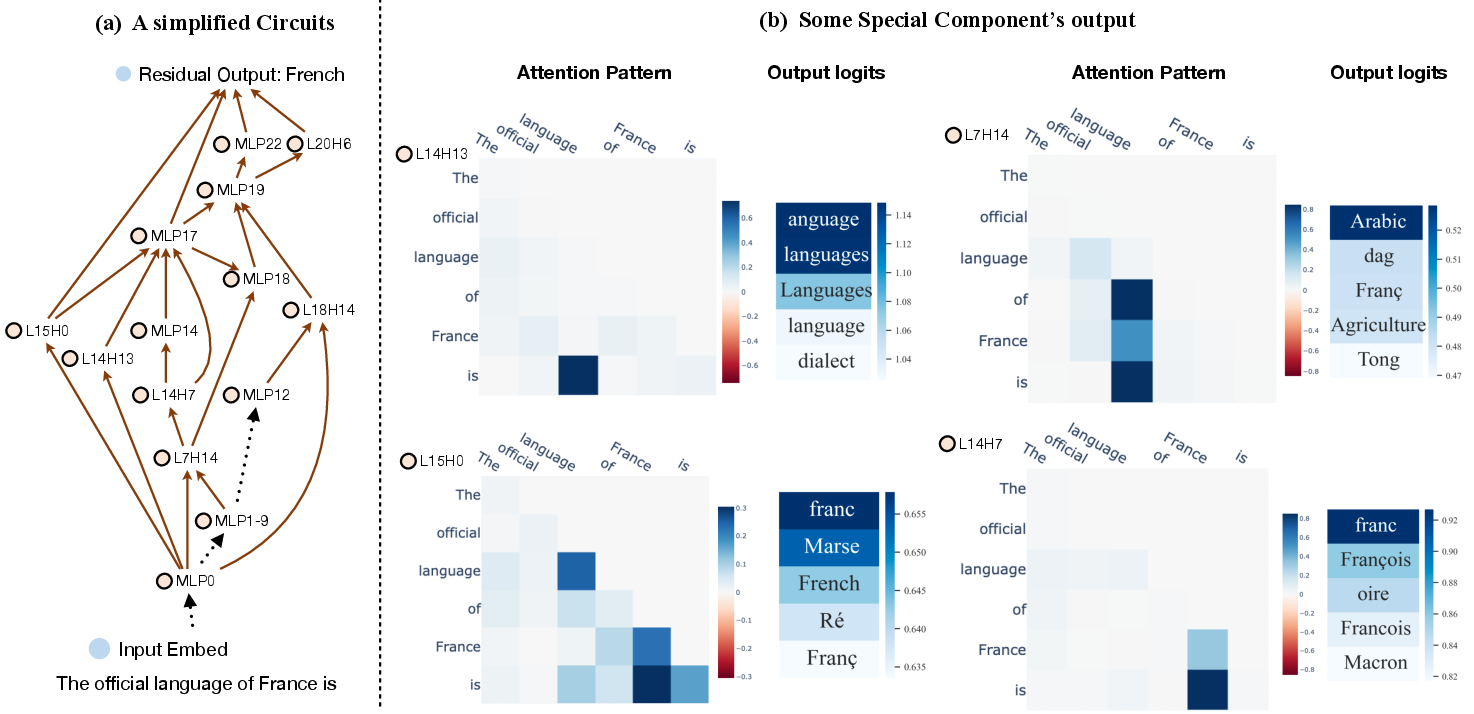
Figure 9: Example of a sparse knowledge circuit, highlighting specialized heads and FFN blocks contributing to factual completion.
Steering Methods: Activations and Parameter Interventions
Amplitude Manipulation
Directly altering (scaling, zeroing, or patching) the magnitude of activations during inference can transiently steer behavior, facilitating interventions such as debiasing, safety enforcement, and modular control.
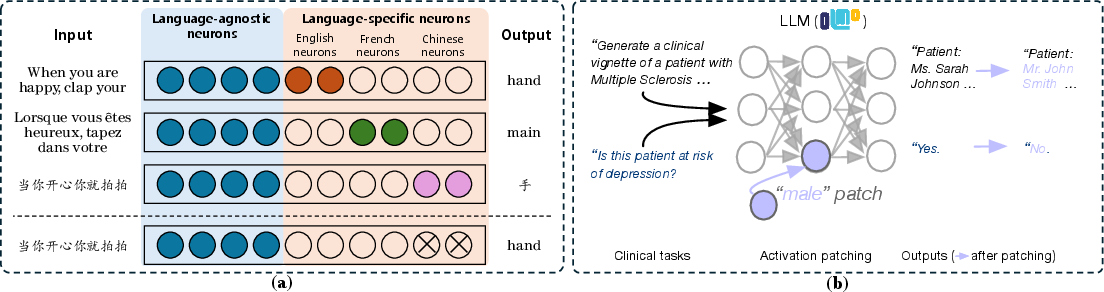
Figure 10: Amplitude manipulation enables language steering by deactivating language-specific neurons and enables demographic steering via patching.
Targeted Optimization
Updates are selectively routed to pre-localized subsets of parameters or activations for persistent, high-precision behavioral changes (e.g., knowledge editing or language-specific adaptation), balancing intervention impact with preservation of retained capabilities.
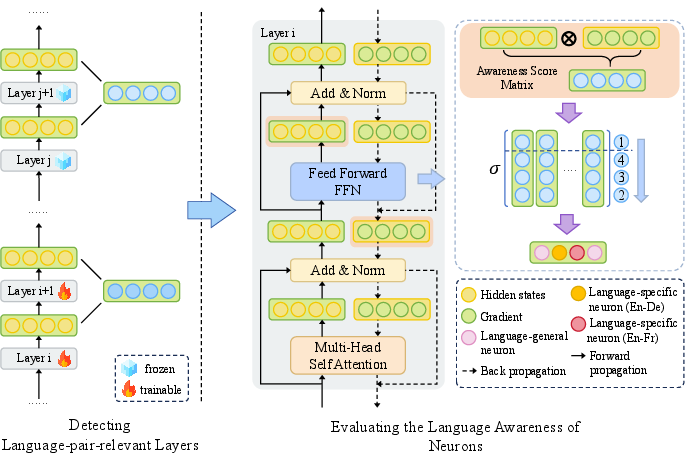
Figure 11: A targeted optimization protocol which leverages prioritized neuron/layer localization to perform selective and efficient adaptation.
Vector Arithmetic
Assuming approximately linear representation of concepts, this class of interventions introduces steering vectors—derived from SAE features or contrastive means—into activation or parameter space during inference. This underlies approaches for style, persona, and reasoning control, as well as model merging.
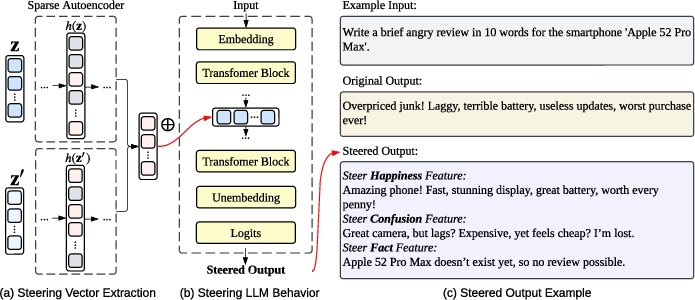
Figure 12: SAE-based steering pipeline: feature selection for targeted concepts, construction of steering vectors, and resultant controlled generation.
Application Scenarios
The paper synthesizes actionable MI into practical domains:
- Alignment (Safety/Bias/Fairness): Mechanistic debiasing and safety improvements are achieved by identifying and suppressing safety-critical or bias-mediating components, both transiently (e.g., amplitude manipulation) and persistently (e.g., targeted optimization). The latent space structure of refusal and harmfulness enables vector arithmetic for safety alignment.
- Capability (Multilingualism, Knowledge Management, Reasoning): Localization of language-specific or relation-specific neurons and features permits precise, sparse adaptation across languages. Knowledge carriers are efficiently edited or consolidated using hierarchical MI-informed pipelines, and reasoning abilities are dissected, monitored, and steered by identifying latent inference trajectories and cognitive motifs.
- Efficiency (Sparse Training/Inference): MI-guided criteria facilitate sparse fine-tuning, infusion of training dynamics metrics for early stopping and generalization monitoring, and inference acceleration via adaptive pruning and quantization according to saliency.
Challenges and Future Directions
Key open problems remain in scaling MI beyond low-level localizations to robust, systematically interpretable system-level explanations. Obstacles include the computational infeasibility of exhaustive fine-grained causal interventions, limited granularity in current explanations, the trade-off between sparsity and mechanistic completeness, and the lack of robust evaluation frameworks for faithfulness.
The paper argues that stronger theoretical foundations—potentially grounded in cognitive science or information theory—and the integration of MI findings into the model design phase (including interpretable architectural alternatives) are required for the next generation of interpretable, controllable, and reliable LLMs.
Conclusion
This work reframes MI as an actionable discipline with a unified pipeline for diagnostic localization, targeted steering, and practical model improvement. By structurally connecting theoretical frameworks with methodologies and downstream applications, it establishes a foundation for future research that tightly couples interpretability, precise intervention, and the evolution of LLM architectures.