- The paper demonstrates how causal mediation analysis structures mechanistic interpretability by categorizing neural mediators based on granularity and alignment.
- It contrasts discrete mediators like neurons and attention heads with coarse units such as layers, highlighting trade-offs like polysemanticity versus generality.
- The study shows that optimization-based search methods can enhance model understanding, driving improvements in AI transparency and safety.
Introduction
Mechanistic interpretability endeavors to comprehend the functional roles of neural network components, aiming for a deeper algorithmic understanding of neural network behaviors. Traditionally fragmented, this field lacks unified evaluation frameworks, making comparison and progress measurement challenging. The discussed paper proposes structuring interpretability research through causal mediation analysis, harmonizing diverse methods by categorizing them according to the types of causal units employed and their respective pros and cons. This methodology intends to provide a coherent narrative of the field and assists researchers in selecting apt methods for different research objectives.
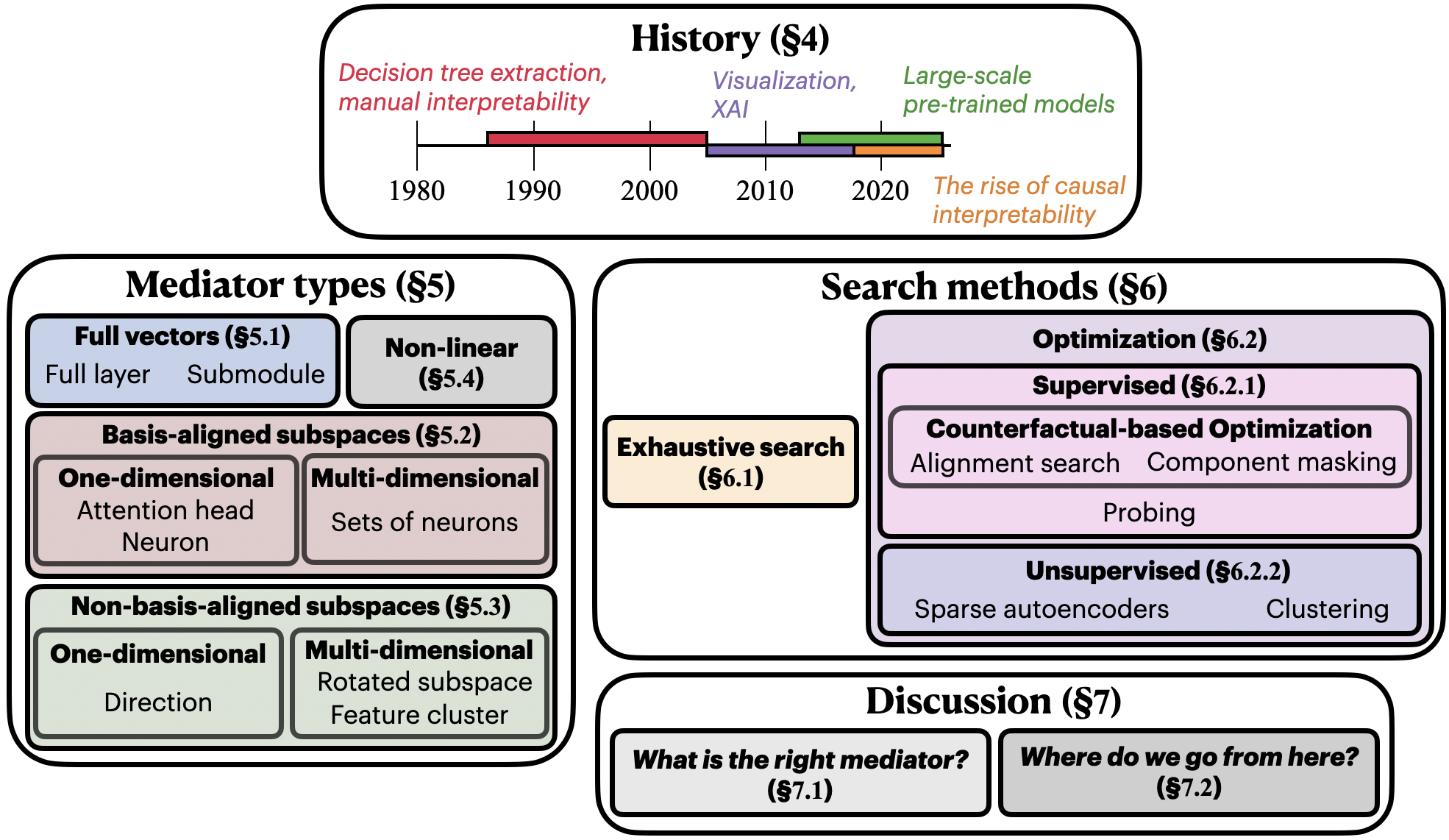
Figure 1: Outline of survey. Necessary causal terminology is defined, setting the stage for differentiating and contextualizing various mechanistic interpretability methods.
Causal mediation analysis constitutes the core analytical lens proposed for mechanistic interpretability. This statistical framework allows researchers to explore how intermediate nodes in neural networks influence model outputs, effectively enabling a more structured examination of neural components' functionality. The framework integrates direct and indirect impacts, solidifying the basis for understanding functional roles and interaction mechanisms within neural computation graphs. By mapping neural components to causal graphs, the framework supports nuanced insights into how models establish complex dependencies among variables.
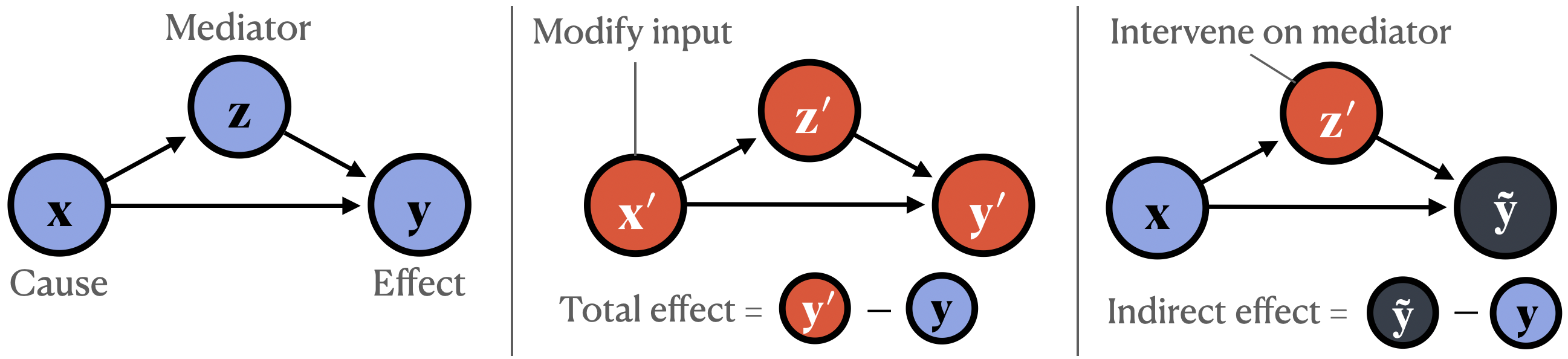
Figure 2: Illustration of causal mediation analysis applied to neural networks, emphasizing how changes in mediator states can alter predicted outcomes.
The paper categorizes mediators by their granularity and alignment. Neurons and Attention Heads serve as naturally discrete, fine-grained mediators, offering high resolution in pinpointing functional roles but often suffer from polysemanticity—where multiple concepts are encoded by a single unit. Submodules and Layers are coarser mediators providing generality across tasks and simpler enumeration for analyses. Conversely, Non-basis-aligned Spaces allow the discovery of human-interpretable features via linear combinations of neuron activations, which often yield monosemantic and sparse representations, conducive to detailed functional examinations.
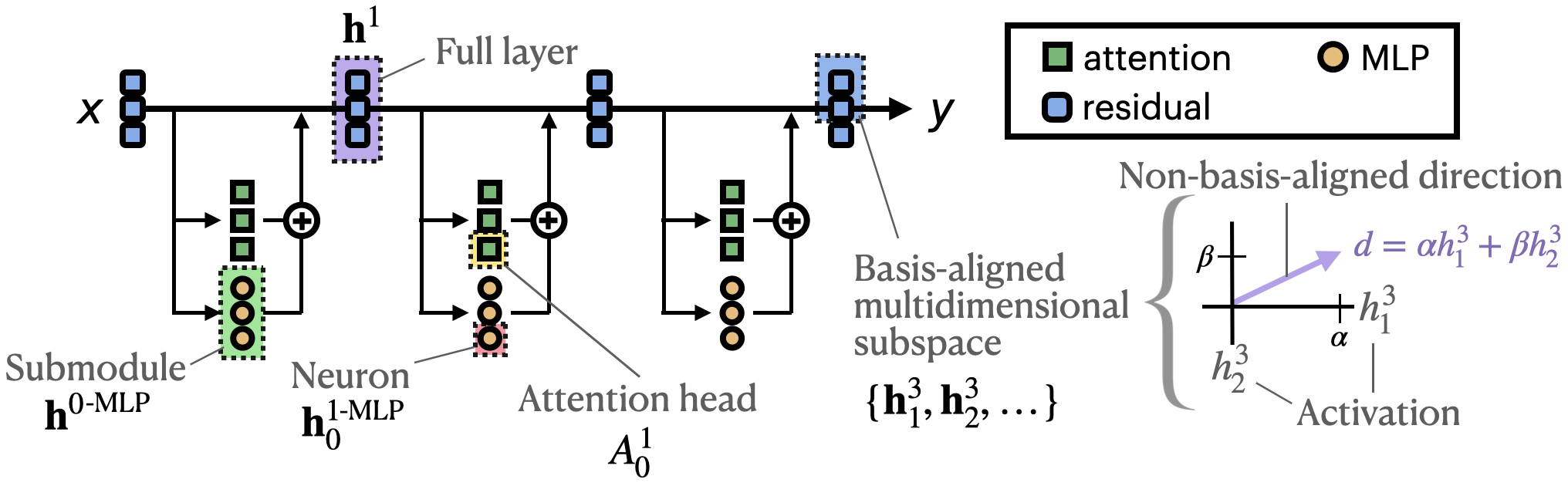
Figure 3: Visualization of common mediator types in neural networks. It highlights the shift towards exploring non-basis-aligned spaces for extracting monosemantic features.
An array of search methodologies are delineated, catering to different mediator types. Exhaustive Search and Gradient-Based Approximations find application in scenarios involving countable mediators. For continuous or vast mediator spaces, Optimization-based Searches—comprising both supervised and unsupervised methods—are employed. These include methods like supervised probing, which aligns representations with human-specified concepts, and sparse autoencoders for interpretable direction discovery in latent space. Importantly, optimization techniques are susceptible to biases inherent in training processes, prompting the need for rigorous validation.
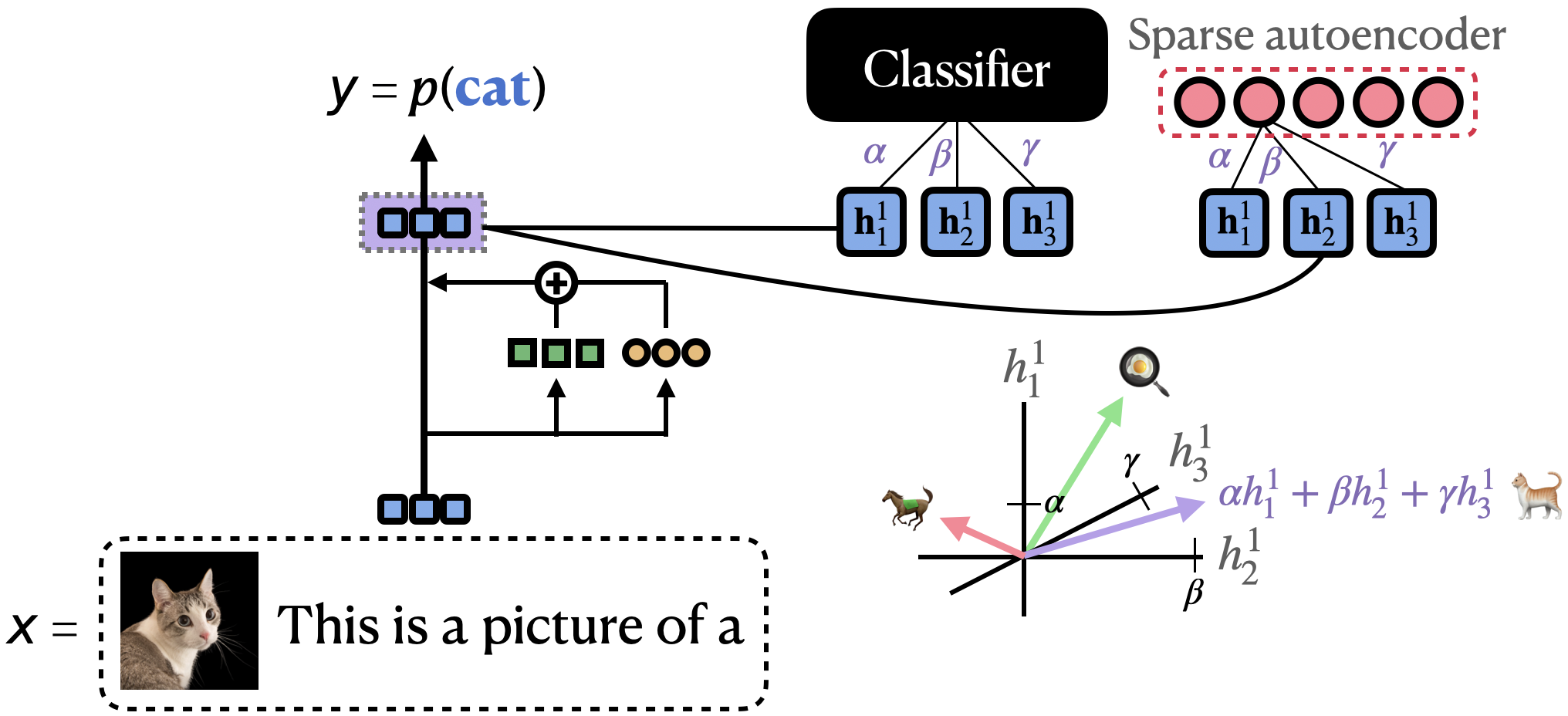
Figure 4: Neurons are not guaranteed to encode interpretable features. The challenge of non-orthogonal feature representation necessitates methods for identifying non-basis-aligned mediators.
Discussion on Practical and Theoretical Implications
The discourse extends to implications of these insights for future developments in AI:
- Model Understanding: Improved interpretability aids in demystifying behaviors of black-box models, promoting safer and more reliable AI deployments.
- Algorithmic Advancements: Structured methodologies can guide the development of inherently interpretable models or architectures, enhancing controllability and comprehensibility.
- Causality Theory Integration: Deepening the theoretical integration of causality concepts across AI systems could further refine these approaches, leading to more transparent models.
Conclusion
The quest for the right causal mediator is essential for gaining profound insights into a neural network's inner workings. The outlined approach via causal mediation analysis offers a pragmatic pathway to unify disparate methodologies, encouraging consistency and comparison in mechanistic interpretability research. As AI systems grow increasingly complex, such structured frameworks are vital for ensuring interpretability alongside performance, security, and ethical alignment.
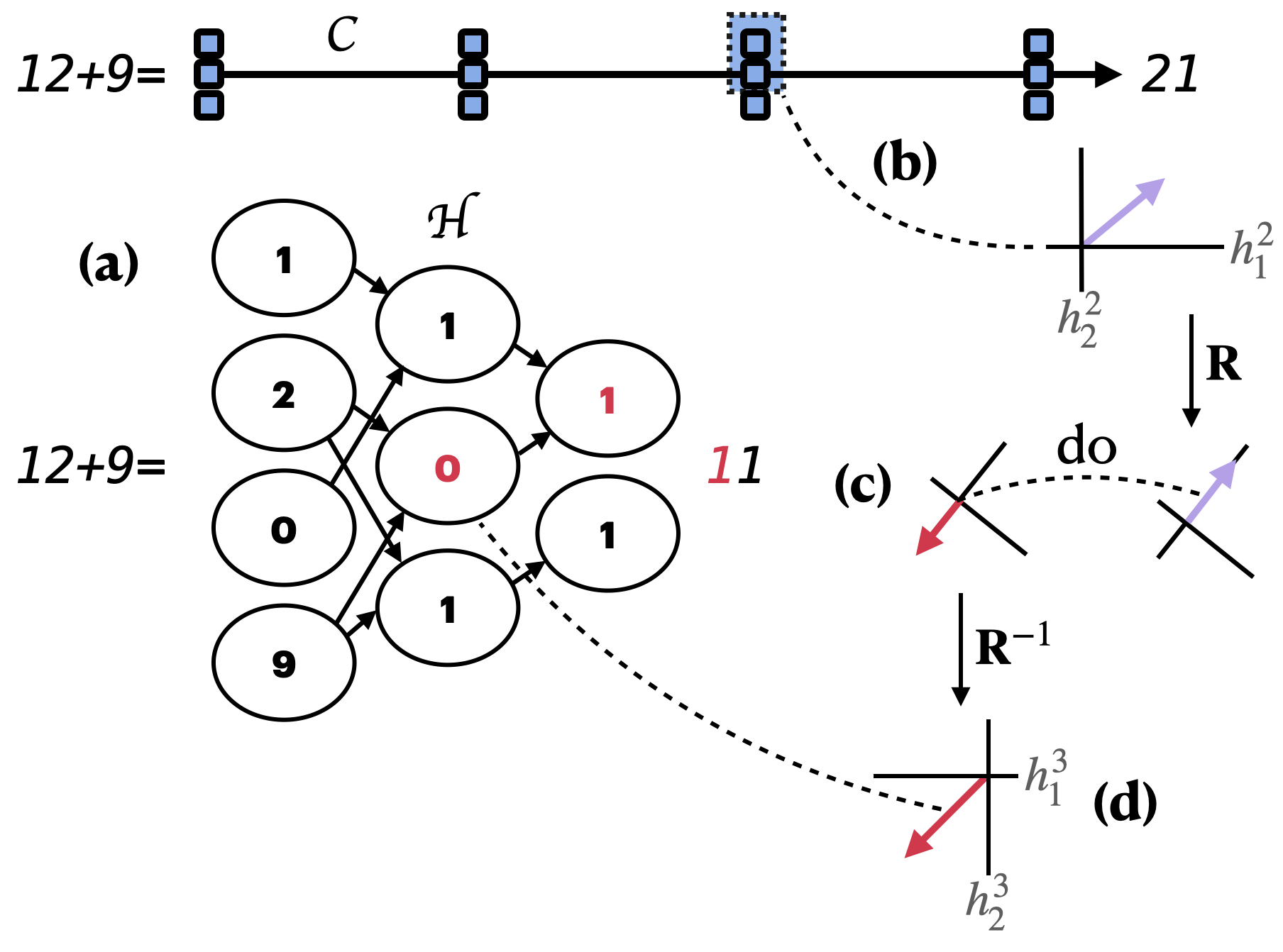
Figure 5: Example of alignment search, demonstrating the process of isolating specific causal variables within the computation graph, based on the proposed causal mediation analysis framework.