- The paper proposes an agentic framework that integrates chain-of-thought reasoning, automated Manim code synthesis, and visual feedback to generate animated physics explanations.
- It employs a multi-agent system for solution decomposition, scene planning, and iterative error correction, ensuring pedagogically coherent and visually clear outputs.
- Empirical results show robust performance with improved layout and scene alignment, despite challenges like narration redundancy and occasional rendering artifacts.
PhysicsSolutionAgent: Agentic Multimodal Solutions for Numerical Physics Explanations
Motivation and Problem Statement
Traditional text-based solutions to numerical physics problems, even when authored by expert teachers or LLMs, tend to lack visual intuition and procedural clarity vital for deep conceptual understanding. While recent agentic systems such as TheoremExplainAgent have demonstrated the feasibility of long-form video explanations for mathematical theorems, the automated synthesis of high-quality visual explanations—especially for step-wise, numerically driven physics problems—presents substantial challenges in visual reasoning, code generation reliability, and consistent pedagogical clarity.
The "PhysicsSolutionAgent: Towards Multimodal Explanations for Numerical Physics Problem Solving" (2601.13453) proposes an agentic framework that generates up to 6-minute animated video explanations for both numerical and theoretical physics questions. Using agent-driven scene planning, Manim-based animation coding, and visual feedback for iterative refinement, this work establishes quantitative baselines for multimodal solution quality and diagnoses key limitations in current multimodal agent architectures.
Agentic Pipeline Architecture
PhysicsSolutionAgent employs a modular, multi-agent pipeline for end-to-end video generation (Figure 1):

Figure 1: The complete pipeline, where specialized LLM agents generate chain-of-thought solutions, design the instructional scene plan, autonomously code Manim-based animations, and refine output quality using vision-language feedback.
- Chain-of-Thought Solution Generation: The primary agent (PhysicsSolutionAgent) decomposes the problem using chain-of-thought reasoning, producing a JSON-structured solution with conceptual steps, equations, detailed calculations, and visualization suggestions.
- Scene Planning: A PlannerAgent translates this solution into an explicit pedagogical breakdown: each scene is described by title, educational purpose, visual/narrative content, and layout—enabling modular, didactically coherent video assembly.
- Manim Code Synthesis with RAG: The CodingAgent, grounded in the Manim codebase via Retrieval-Augmented Generation (RAG), synthesizes Python scene code and leverages chain-of-repair error correction; all animations are synchronized with teacher-style narration via manim-voiceover and Kokoro TTS.
- Iterative Error Correction: Noisy LLM-generated code is repaired through stack trace-driven self-debugging until a successful render is obtained.
- Visual Feedback Loop: A vision-LLM (VLM) analyzes static scene screenshots and provides actionable layout/clarity improvement instructions, which the CodingAgent incorporates and re-renders—enabling post-hoc video polishing within strict cost/latency budgets.
Evaluation Protocol and Metrics
The study employs a rigorous LLM-as-a-Judge evaluation protocol, automated over 32 video outputs derived from both conceptual and numerical physics prompts. Each output undergoes a fine-grained, rubric-based assessment across 15 parameters, with a weighted overall quality score that decomposes into: Solution Quality (5%), Explanation Quality (10%), Visual Quality (60%), and Error Penalty (25%).
Scene evaluation further considers layout quality, text readability, equation rendering, off-screen content, and visual-content alignment. Automated and human-in-the-loop analyses yield both quantitative performance benchmarks and targeted qualitative diagnoses.
The system achieves robust, consistent performance across a broad range of physics questions. Notably, the average automated video quality scores are 3.82/5 for conceptual problems and 3.80/5 for numerical problems, with 100% completion rates for the chosen dataset.
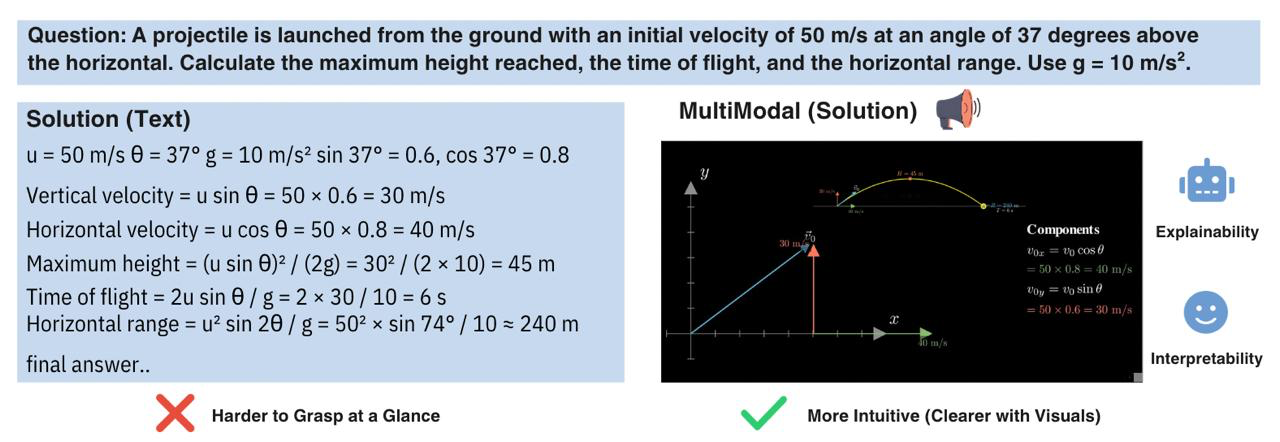
Figure 2: Comparison between classic text solutions and agent-generated multimodal solutions, illustrating improved clarity and procedural intuition with visual scaffolding.
Applying the visual feedback loop yields modest but quantifiable improvements in layout quality, scene-content alignment, and overall visual clarity. For example, layout quality improves from 3.64 to 3.66 and scene-content alignment from 3.31 to 3.53 after refinement.
Despite this pipeline’s success on both easy and highly complex tasks (see progression of scene quality in Figures 3 and 4), the evaluation uncovers several systematic issues:
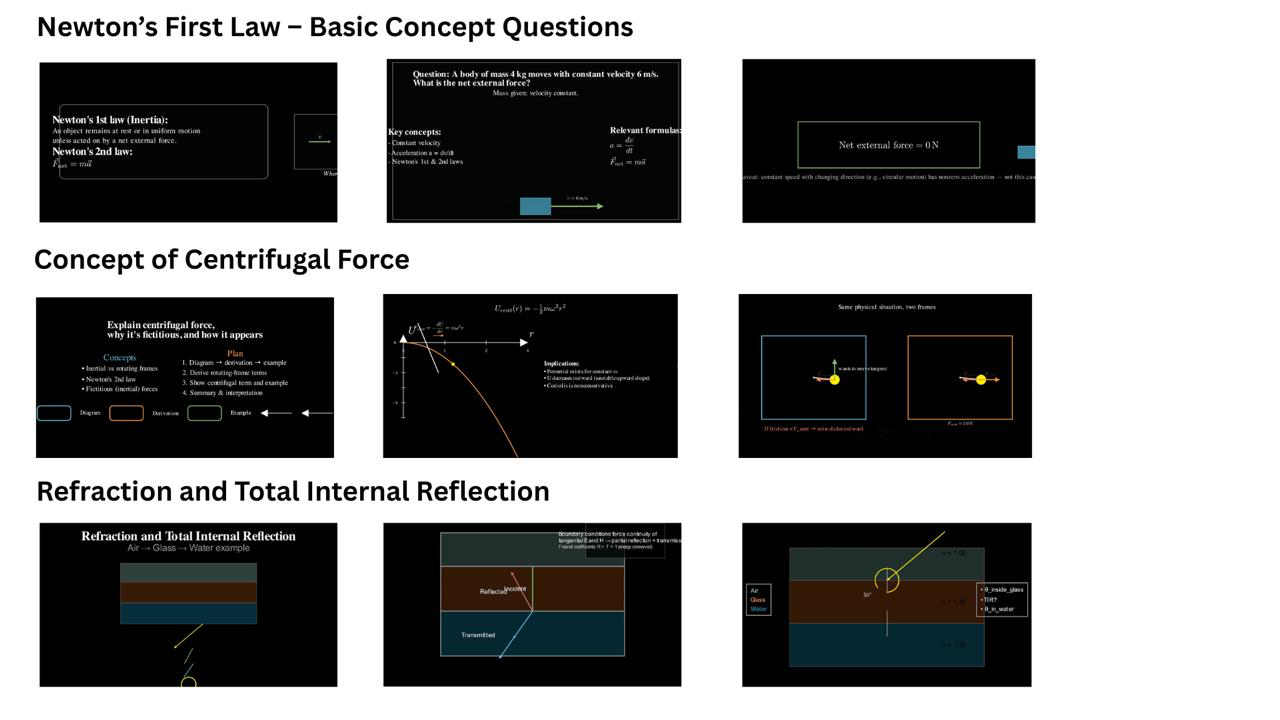
Figure 3: Examples of poor-quality scenes, often featuring overcrowding, misaligned text, and equation rendering issues.
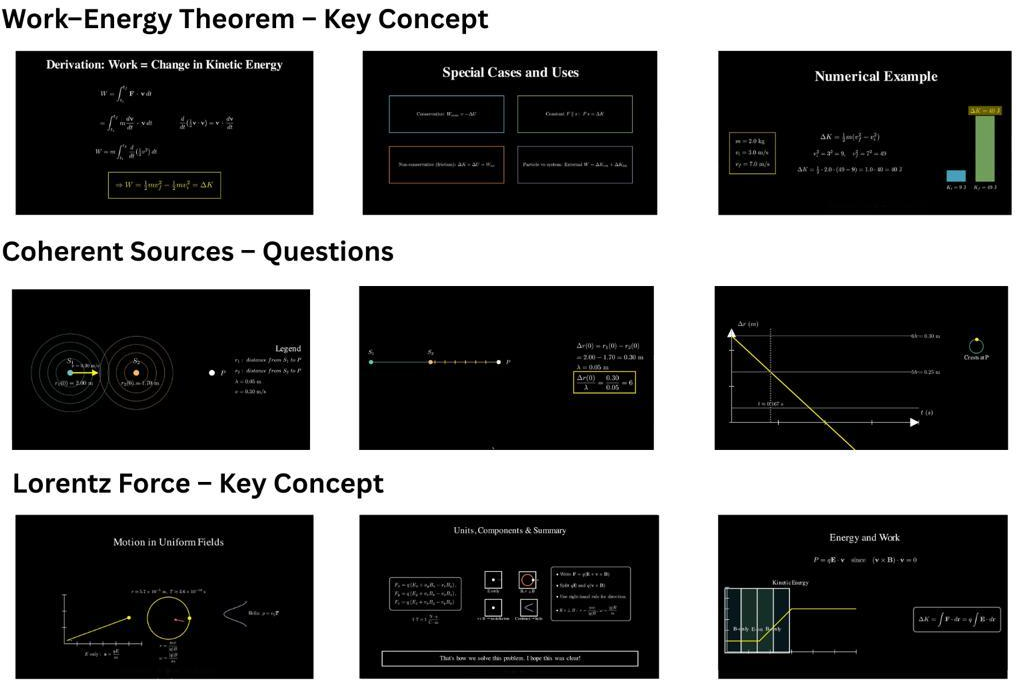
Figure 4: Examples of high-quality scenes demonstrating effective layout, clear separation of visual elements, and high readability.
- Redundancy and verbosity in narration and on-screen text persist, with repetitive content outpacing fundamental errors as the dominant quality bottleneck.
- Visual issues like minor overlaps and LaTeX equation rendering artifacts affect both numerical and theorem tasks, more frequently surfacing in abstract explanations.
- The single-iteration visual feedback loop, constrained by cost, addresses static layout flaws but cannot capture dynamic animation smoothness or AV synchrony.
Technical and Theoretical Implications
This work demonstrates that an agentic system grounded in LLM code generation, when augmented by documentation retrieval and visual feedback, can reliably automate the generation of step-wise, multimodal explanations for quantitative physics. Direct implications include:
- Educational Robustness: The automated narrative-visual scaffolding achieves parity across conceptual and numerical modalities, indicating generalization in agent-based pedagogical video generation.
- Agentic Reflection: The integration of vision-language critique marks a shift from mechanical code repair to higher-level multimodal output reflection, a precursor for future agent self-critique and iterative improvement cycles.
However, limitations in redundancy, lack of external physics knowledge for rare topics, restricted visual feedback capacity (static only), and high compute cost for complex problems persist. This highlights gaps in the precise mapping from physics solution plans to visual, didactic animation code—a key open problem for subsequent frameworks.
Future Directions
PhysicsSolutionAgent motivates several concrete research trajectories in the multimodal and educational AI domains:
- Fine-grained Redundancy Pruning: Specialized reward models or control mechanisms to enhance conciseness and eliminate verbose/redundant narration in agentic pipelines.
- Temporal Visual Feedback: Extension from static screenshot analysis to full video scene/temporal coherence evaluation, enabling correction of animation glitches, timing issues, and AV integration errors.
- Cross-domain Knowledge Integration: Incorporation of external domain-specific resources (e.g., symbolic physics engines, curated expert scripts) to improve coverage on niche and highly technical topics.
- Interactive, Real-time Tutor Agents: Reducing generation latency and increasing scene adaptivity for real-time or conversational, multimodal STEM tutoring.
Conclusion
PhysicsSolutionAgent establishes a robust, quantitatively evaluated pipeline for automating multimodal explanations of physics problems. By orchestrating LLM-driven planning, Manim code synthesis, RAG-based grounding, error correction, and screenshot-driven VLM feedback, the system defines a new baseline for agentic educational video generation in STEM. The results confirm both the promise and the limitations of current multimodal agents, with clear avenues for further work on output quality, reflection, and real-time performance.