- The paper introduces ICo3D, an integrated pipeline that creates interactive, photorealistic 3D avatars by fusing HeadGaS++ and SWinGS++ for audio-driven facial and body animation.
- It employs advanced techniques like multi-view Gaussian Splatting, MLP-based modulation, and sliding window temporal encoding to achieve superior metrics (PSNR 30.4, SSIM 0.935) and robust synchronization.
- The system integrates ASR, LLM, and TTS modules to enable real-time, immersive conversational interactions applicable in VR, gaming, and virtual assistance.
ICo3D: An Integrated Photorealistic Conversational 3D Virtual Human Avatar
System Contributions and Architecture
The paper presents ICo3D, an integrated pipeline for creating interactive, photorealistic 3D virtual human avatars that support real-time, LLM-driven conversational interactions. The system employs multi-view image capture for both the face and body, reconstructs dynamic animatable head and body models via 3D Gaussian Splatting (3DGS), and merges these components into a seamless, artifact-free avatar. Critical technical advancements are introduced in both head (HeadGaS++) and body (SWinGS++) modeling—HeadGaS++ for high-fidelity, audio-driven facial reenactment and SWinGS++ for enhanced dynamic 3D reconstruction with improved temporal consistency.
The system is augmented with a language understanding pipeline (LLM, ASR, TTS), closing the loop with real-time natural language interaction. The avatar’s facial expressions are directly driven by LLM-generated speech via synchronized animation, and a procedural body animation mechanism complements this, maintaining plausible gestural cues aligned with conversational flow.
The following system overview outlines the data flow from user interaction to avatar synthesis:
- User audio/text input is parsed via ASR and sent to the LLM (e.g., Qwen2) for response generation.
- The textual reply is synthesized into speech (TTS), which concurrently drives both the avatar’s audio playback and serves as control signal for lip and facial animation in HeadGaS++.
- Body animation is governed by procedural mechanisms, ensuring synchronization with the spoken output.
- The head and body Gaussian models are spatially and temporally registered, pruned, and merged to render a free-viewpoint, photorealistic avatar suited for deployment in VR, gaming, virtual assistants, and personalized education.
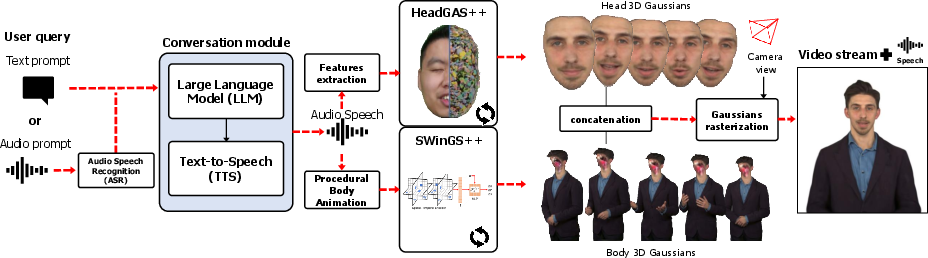
Figure 1: ICo3D system pipeline, detailing interactive conversational flow, LLM integration, and 3D Gaussian-based avatar rendering.
Head Model: HeadGaS++ – Audio-Driven Animatable 3D Head Synthesis
HeadGaS++ extends previous 3DGS-based head avatars by integrating an audio-conditioned latent blendshape basis, enabling dynamic modulation of expression, color, and opacity for each Gaussian primitive as a function of speech-derived audio-visual features. The MLP-based modulation framework provides increased expressiveness and high-fidelity lip synchronization, trained with a combination of L1, SSIM, and perceptual losses. This approach supports robust novel view and novel expression synthesis, tightly synchronized with input speech.
Empirical results demonstrate strong rendering fidelity and synchronization capabilities. Compared to leading NeRF and GS-based talking head baselines, HeadGaS++ attains superior image metrics (PSNR: 30.4, SSIM: 0.935), better lip synchronization scores, and achieves real-time inference rates (250 FPS), with one-hour training on standard GPU hardware.
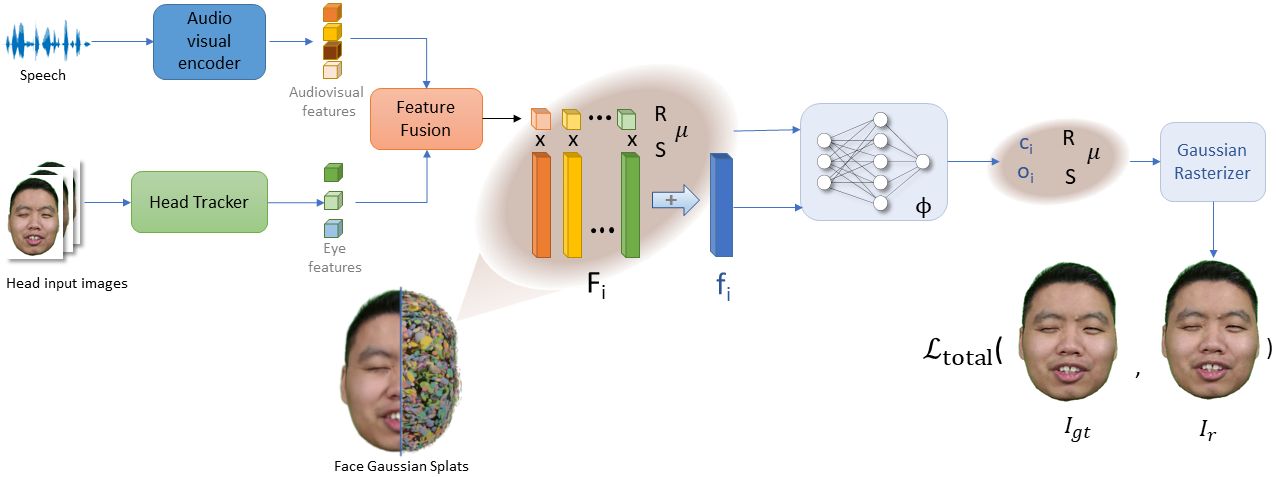
Figure 2: HeadGaS++ pipeline overview with audio-visual feature extraction and MLP-based modulation for dynamic, high-fidelity head avatars.

Figure 3: HeadGaS++ demonstrates superior qualitative lip synchronization compared to competitive methods.
Body Model: SWinGS++ – Temporally Consistent Dynamic 3DGS Human Avatars
SWinGS++ advances dynamic 3D human body reconstruction by incorporating a sliding window strategy with adaptive temporal granularity, backed by a spatio-temporal encoder that improves motion estimation. Each window is modeled as a temporally local 4DGS, and transitions between windows are regularized via temporal fine-tuning using novel-view consistency losses. MLPs with tunable blending capture frame-specific deformations, addressing fast or large-scale human motion that challenge prior 3DGS models.
Quantitative analysis on the DNA-Rendering dataset establishes state-of-the-art performance, outperforming previous baselines—SWinGS++, Spacetime Gaussians, 4D-Gaussians, and body template-driven animatable approaches (e.g., HuGS)—with a PSNR of 30.17 and SSIM of 0.9699, providing sharper motion reconstruction especially for articulated and unconstrained scenarios.
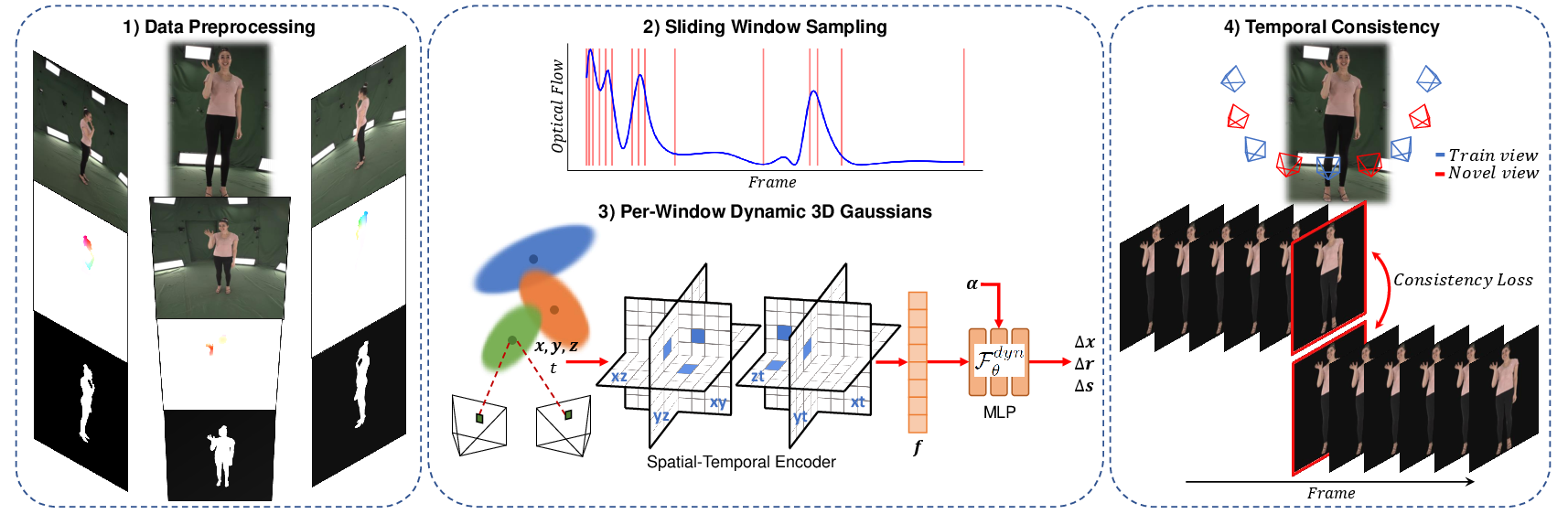
Figure 4: SWinGS++ architecture with local sliding windows and spatio-temporal voxel encoding for robust dynamic motion capture.



Figure 5: SWinGS++ exhibits sharper, more detailed synthesis on complex human motions compared to template-driven models, though lacking explicit pose-driven animation.

Figure 6: Qualitative comparison shows SWinGS++ reconstructions are notably sharper in novel view synthesis tasks.
Integrated Head-Body Synthesis and Cross-Dataset Registration
To assemble the avatar, the paper introduces a robust method for aligning and fusing independently trained head and body models, managing disparate capture setups, coordinate system heterogeneity, and lighting variations. Rigid transformation and pose registration are enabled via the shared FLAME facial mesh canonicalization. Inter-penetration and boundary artifacts between models are mitigated by spatial Gaussian pruning (e.g., jaw and border regions) and color matching (finetuning MLP output layers for the head to match the body appearance).
This enables combinatorial synthesis for avatars leveraging best-in-class dataset assets for head and body, critical for practical scalability and high-fidelity applications.

Figure 7: Pipeline for cross-setup head-body integration—alignment, Gaussian merging, border blending, and color harmonization.


Figure 8: Illustration of using distinct datasets (RenderMe-360 for head, DNA-Rendering for body) and cross-modal registration.
End-to-End Conversational Pipeline and Real-Time Avatar Interaction
The complete ICo3D pipeline runs in real time (up to 105 FPS on practical workstations), with modular server-client infrastructure. The system integrates ASR (Whisper), LLM (Qwen2), and TTS (OpenVoice V2) modules, interfacing via lightweight data exchange to minimize local rendering latency. The face is animated using SyncTalk-derived features, while the body undergoes procedural animation based on state-driven keyframes, looped or selected dynamically to match conversational speech.
In deployment, facial expressions, lip sync, and audio are tightly integrated, providing an immersive VR or screen-based conversational interface suitable for both research and commercial applications.

Figure 9: ICo3D generates a photorealistic, full-body avatar with dynamic, synchronized facial animation and LLM-driven interactive conversational ability.

Figure 10: ICo3D avatar demonstrates multi-modal variation: real-time audio-driven head and procedural body animation, static pose with dynamic face, and full free-viewpoint camera control.
Numerical Results and Comparisons
The following table summarizes the core head and body synthesis benchmarks using masked PSNR, SSIM, and lip synchronization criteria (lower LMD, higher Sync-C is better):
| Model |
PSNR ↑ |
SSIM ↑ |
LPIPS ↓ |
LMD ↓ |
Sync-C ↑ |
FPS ↑ |
| RAD-NeRF |
26.79 |
0.901 |
0.083 |
2.91 |
4.99 |
25 |
| ER-NeRF |
27.35 |
0.904 |
0.063 |
2.84 |
5.17 |
35 |
| TalkingGaussian |
29.32 |
0.920 |
0.046 |
2.69 |
5.80 |
110 |
| GaussianTalker |
29.13 |
0.911 |
0.085 |
2.81 |
5.35 |
130 |
| ICo3D (Ours) |
30.40 |
0.935 |
0.051 |
2.79 |
5.93 |
250 |
ICo3D achieves the highest PSNR, SSIM, and lip synchronization in both self- and cross-driven testing.
ICo3D sets a new bar for system speed, with tested render rates up to 105 FPS (NVIDIA RTX 4090 Laptop GPU), crucial for VR and interactive applications.
Theoretical and Practical Implications
ICo3D unifies state-of-the-art neural rendering, high-fidelity audio-driven animation, and interactive LLM integration—demonstrating the synergy between generative neural representations and conversational AI. The improvements in temporal consistency and modular head-body fusion mechanisms can be leveraged for scalable avatar generation, cross-dataset transfer, and robust deployment in real-world environments. The approach points toward flexible, compositional pipelines where best-in-class components (head, body, language) are synthesized for specific user, environment, and interaction constraints.
Future avenues include integrating fully animatable, pose-driven 3DGS models for expressive body control beyond procedural animation, investigating 4DGS templating for high-frequency motion generalization, and extending fine-grained emotion control in conversation through multimodal LLM-animated avatars.
Conclusion
ICo3D delivers a cohesive, high-fidelity solution for interactive conversational 3D avatars, synthesizing advances in 3D Gaussian Splatting, audio-driven animation, and multilingual LLMs (2601.13148). The resulting system demonstrates state-of-the-art rendering performance, robust synchronization, and real-time interaction, providing a foundation for future generative avatar research and deployment in virtual environments.