XRefine: Attention-Guided Keypoint Match Refinement
Abstract: Sparse keypoint matching is crucial for 3D vision tasks, yet current keypoint detectors often produce spatially inaccurate matches. Existing refinement methods mitigate this issue through alignment of matched keypoint locations, but they are typically detector-specific, requiring retraining for each keypoint detector. We introduce XRefine, a novel, detector-agnostic approach for sub-pixel keypoint refinement that operates solely on image patches centered at matched keypoints. Our cross-attention-based architecture learns to predict refined keypoint coordinates without relying on internal detector representations, enabling generalization across detectors. Furthermore, XRefine can be extended to handle multi-view feature tracks. Experiments on MegaDepth, KITTI, and ScanNet demonstrate that the approach consistently improves geometric estimation accuracy, achieving superior performance compared to existing refinement methods while maintaining runtime efficiency. Our code and trained models can be found at https://github.com/boschresearch/xrefine.


Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Overview
This paper is about making matches between small, important points in two photos more precise. These points, called keypoints, help computers understand 3D scenes from 2D images (for example, to map a room, localize a robot, or build a 3D model of a building). The authors introduce XRefine, a fast and simple method that tweaks the positions of matched keypoints to be accurate down to fractions of a pixel. This small correction can noticeably improve 3D calculations like estimating where a camera is and how it moved.
What questions did the paper ask?
- Can we make matched keypoints more accurate without depending on a specific detector (like SIFT or SuperPoint)?
- Can we do this using only small image crops around the matched points, instead of needing extra detector data like descriptors or confidence scores?
- Will these refinements actually improve 3D tasks such as camera pose estimation and 3D point reconstruction?
- Can the method work not just for two photos, but also for many photos at once?
How did the researchers approach it?
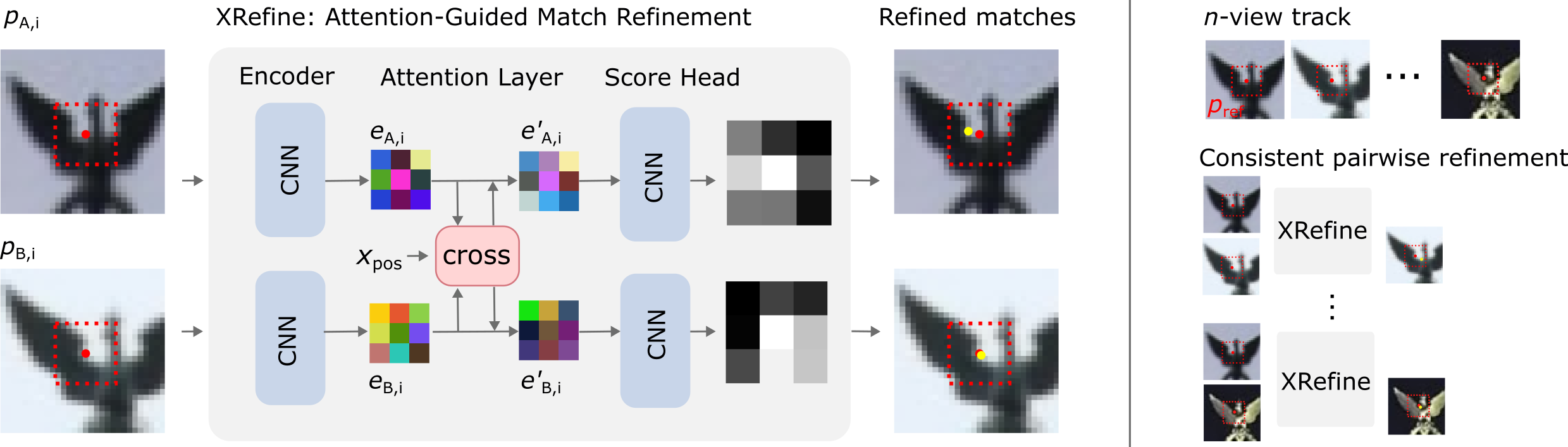
They built a lightweight neural network called XRefine that takes two tiny grayscale patches (11×11 pixels) centered on a matched keypoint pair—one patch from each image—and outputs slightly adjusted positions for the points.
Here are the main ideas, in everyday terms:
- Keypoints: Think of keypoints as “landmarks” in an image—corners, blobs, or distinctive patterns that are easy to find again in another photo.
- Sub-pixel accuracy: Instead of snapping a point to a pixel grid (like picking a square on graph paper), sub-pixel means placing it anywhere within or between pixels, like marking a spot with millimeter precision.
- Patches: Rather than looking at the whole image, XRefine only looks at very small cutouts around each matched point. This keeps it fast.
- Cross-attention: Imagine holding two small photo cutouts side-by-side and “paying attention” to how their patterns line up. Cross-attention is a way for the network to compare the two patches and focus on the best corresponding locations.
- Score map + soft-argmax: The network turns each patch into a small “heat” map showing where the keypoint most likely should be. A soft-argmax is like finding the “center of mass” of the hot area to get a precise coordinate.
- Training with geometry, not labels: They train the model so that the refined points obey the geometric rules of two-camera systems (epipolar geometry). In simple terms, when two photos see the same 3D point, that point must lie along certain lines between the images. The model learns to adjust points to better fit those rules.
They also created a multi-view version: when a keypoint appears in many images, they pick one image as a reference and refine the points in the other images toward that reference. This keeps the whole set of points consistent across multiple views.
What did they find?
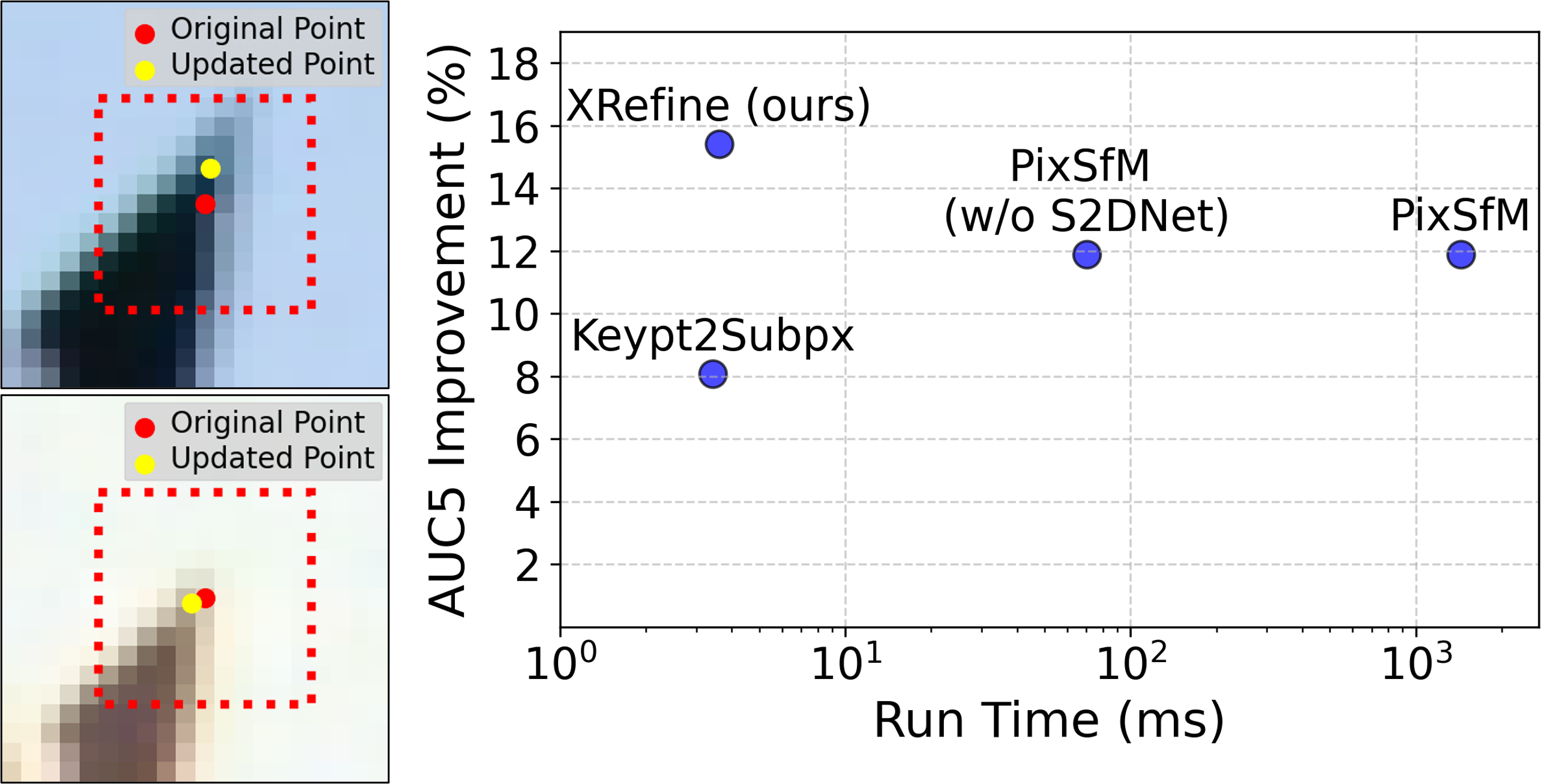
- Better accuracy across datasets: On common benchmarks (MegaDepth, ScanNet, KITTI), XRefine improved camera pose estimation more than other refinement methods. Gains were especially strong on more challenging datasets (MegaDepth and ScanNet), with smaller but still positive gains on KITTI.
- Works with many detectors: XRefine is “detector-agnostic.” It does not need retraining for each keypoint detector and still improves results for both classic (SIFT) and learned (SuperPoint, DeDoDe, XFeat) methods. A detector-specific version does even better, but the general one already performs strongly.
- Fast: It runs in a few milliseconds per image pair on a GPU—much faster than heavy optimization-based methods. That makes it suitable for systems that need speed, like SLAM on robots or AR on mobile devices.
- Multi-view benefit: Extending XRefine to many images improves 3D point triangulation (turning matched 2D points into 3D points). While a slower, more global method (PixSfM) can get slightly higher accuracy for this specific task, XRefine is far faster and still gives consistent improvements.
Why this matters: Even a tiny error—less than a pixel—can throw off 3D calculations. By sharpening point positions just a little, the whole 3D pipeline becomes more reliable.
Implications and impact
- Practical drop-in upgrade: Because it only needs small image patches and no detector-specific data, XRefine can be plugged into many existing 3D vision systems without retraining.
- Better 3D with limited compute: Its speed and small size make it attractive for edge devices (drones, phones, small robots) that cannot run heavy models.
- Stronger building blocks: Refining keypoints helps downstream tasks—pose estimation, mapping, localization, and 3D reconstruction—leading to steadier AR experiences, more robust robot navigation, and cleaner 3D models.
- Future directions: The authors suggest a next step where the model directly handles many patches at once to get globally optimal refinements across all views, which could push accuracy even higher while aiming to stay efficient.
In short, XRefine is a simple, fast, and widely compatible way to make matched keypoints more precise, which in turn improves the accuracy of many 3D vision applications.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a consolidated list of concrete research gaps and unresolved questions that the paper leaves open.
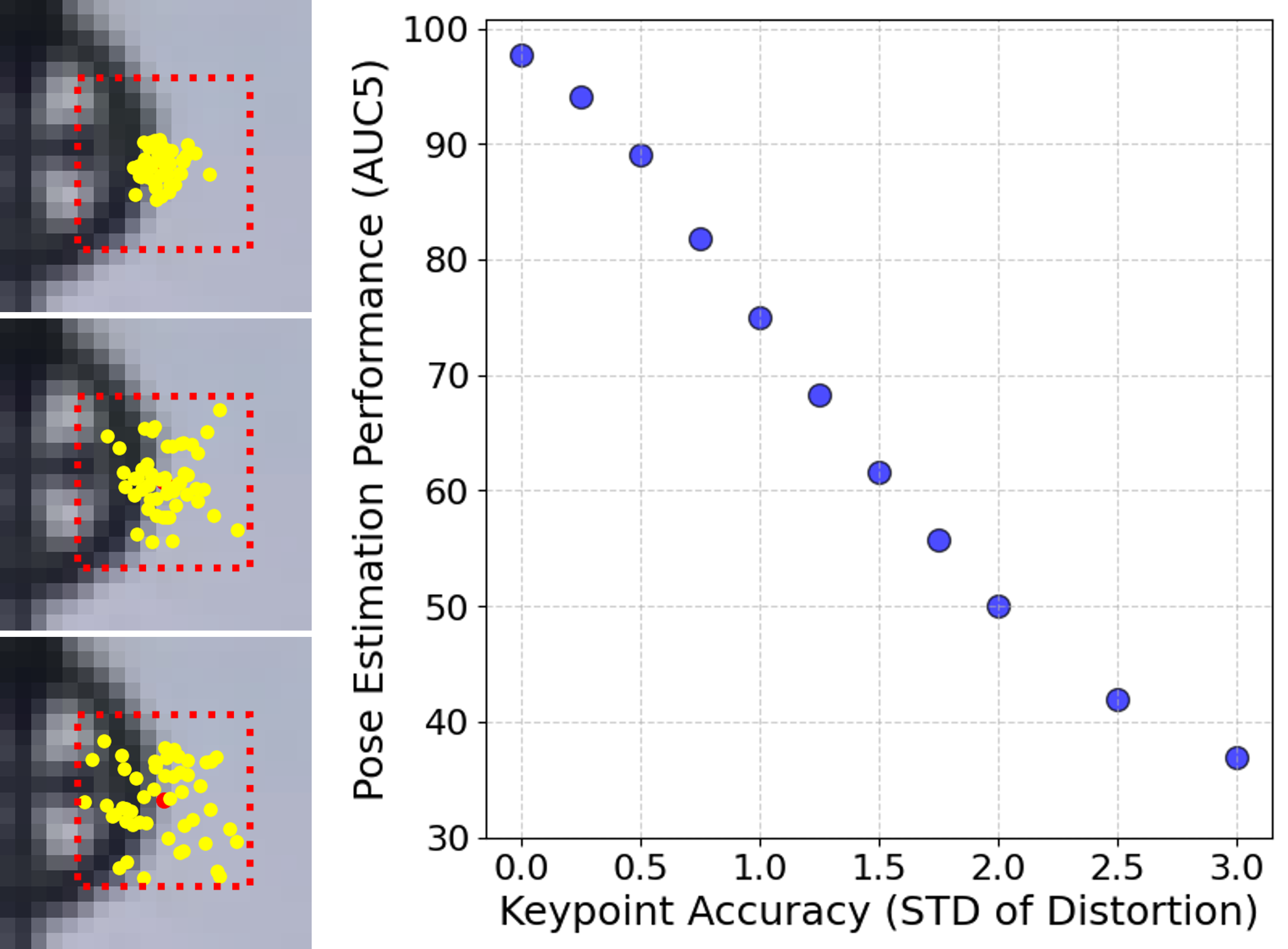
- Limited capture range of the refinement: the model sees only 11×11 grayscale patches and is trained with perturbations drawn from N(0, 1.5 px), raising the question of how it behaves when initial keypoint errors exceed the patch’s effective radius or when larger affine/scale/rotation changes are present.
- Fixed, tiny receptive field: no evaluation of multi-scale or orientation/scale-normalized patches; unclear whether adapting patch size to detector-provided scale/orientation (e.g., SIFT) or using multi-scale pyramids would increase robustness.
- Grayscale-only input: the method discards color; it remains unknown whether color channels could improve refinement under illumination or material changes.
- No uncertainty estimates: the model outputs point estimates via soft-argmax without a confidence or covariance; downstream solvers (e.g., RANSAC, BA) cannot weight refined points by reliability.
- Outlier handling is not addressed: the method always refines provided matches, including mismatches; there is no integrated verification/gating to reject outliers or avoid drifting mismatches to plausible-looking positions.
- Occasional negative impact: the summary table reports negative minimum improvements on ScanNet and KITTI, but no analysis of failure modes or a policy to decide when to skip refinement to avoid harm.
- Domain generalization is only partially validated: training is on MegaDepth with pose supervision; performance under severe domain shifts (e.g., night, rain, snow, motion blur, extreme HDR, textureless indoor scenes) is untested.
- Sensor/model robustness is unexplored: behavior on non-standard cameras (fisheye, rolling shutter, low-resolution, mobile phone lenses), cross-sensor scenarios (thermal, NIR, event cameras), and lens distortions is not evaluated.
- Dependency on ground-truth poses for training: the epipolar-loss supervision requires accurate relative poses; feasibility in domains lacking GT (or with noisy GT) and alternatives (self-/weakly supervised, synthetic data, consistency regularizers) are not studied.
- Sensitivity to matcher quality and settings: while results include MNN/DSM/LightGlue, the interaction between refinement and different matchers (e.g., SuperGlue, RoMa post-filtering) and match thresholds remains underexplored.
- Geometry-aware inference is absent: geometry is only used in the training loss; potential gains from conditioning the refinement at inference on an estimated E/F matrix (e.g., constraining updates orthogonal to the epipolar line) are unknown.
- Multi-view consistency is only pairwise-to-reference: the n-view extension refines each keypoint towards a chosen reference independently; it is suboptimal versus joint global optimization, and can propagate a bad reference. How to select/reference-switch or do jointly consistent refinement efficiently is open.
- Scaling to long tracks: pairwise-to-reference scales as O(T) but may accumulate bias; design of lightweight, globally consistent multi-view refinement (e.g., graph-based attention over n patches) with near-linear complexity is an open direction.
- No integration with bundle adjustment: while triangulation accuracy is reported, there is no study of how refined points affect full SfM/SLAM pipelines (e.g., BA convergence, map quality, loop closure).
- Limited analysis of scene/texture regimes: there is no breakdown by surface type (planar vs. non-planar), depth range, repetitive textures, or low-texture regions where local photometric cues are ambiguous.
- Patch warping not considered: refinement does not account for viewpoint-induced homographies or slanted surfaces; whether patch rectification (e.g., local affine/homography warp) improves robustness is untested.
- Architectural choices are minimally explored: beyond small vs. large variants and one attention block, a broader search (self-attention, windowed transformers, relative positional encodings, kernel sizes, dilations) is not investigated.
- Soft-argmax design details: temperature calibration, border effects, and bias near patch edges are not analyzed; comparisons to alternative differentiable coordinate regressors (e.g., DSNT, integral regression with learned temperatures) are missing.
- Ignoring detector metadata: the model does not use keypoint scale/orientation/score; whether cheaply reintroducing these signals (while staying detector-agnostic) yields gains remains unclear.
- No principled gating policy: a learned decision of when and how much to refine (e.g., magnitude clipping, uncertainty-aware updates) could prevent degradation on already sub-pixel accurate detectors (e.g., SIFT).
- Limited evaluation breadth: only a subset of detectors (SuperPoint, SIFT, DeDoDe, XFeat/XFeat*) and datasets (MegaDepth, ScanNet, KITTI) are tested; performance on additional modern extractors (e.g., DISK, R2D2, ALIKED variants) and benchmarks (HPatches, Aachen Day-Night, RobotCar) is not reported.
- Real-time and edge deployment evidence: runtime is reported on an RTX A5000; there are no CPU/mobile/embedded (Jetson, smartphone NPU) latency and energy measurements despite the “edge AI” claim.
- Robustness to image resolution and resizing: the training/evaluation use fixed resizing (e.g., 1024 px longer side); the effect of varying input resolutions and patch scaling policies is not quantified.
- Interaction with RANSAC settings: refinement is evaluated with a fixed GC-RANSAC threshold (1 px); the joint optimization of thresholds and refinement (or adaptive thresholds based on predicted uncertainty) is not addressed.
- Learning objectives: only the epipolar error is used; the effect of multi-task losses (e.g., photometric consistency, descriptor alignment, cycle consistency across triplets) is unexplored.
- Joint learning with detectors/matchers: the method is trained standalone; whether end-to-end finetuning with a detector/matcher (while keeping detector-agnostic inference) yields further benefits is unknown.
- Reference selection in n-view tracks: the method assumes a single reference; strategies for automatic reference choice (e.g., based on viewing angle, baseline, texture, or uncertainty) and robustness to dynamic scenes/occlusions are not analyzed.
- Handling dynamic content/occlusions: the approach assumes static scenes within patches; failure behavior and mitigations when correspondences cross moving objects or occlusion boundaries are not studied.
- Effect of color/photometric augmentations: training augmentations and their impact on cross-illumination robustness are not detailed; exploring tailored photometric/blur/noise augmentations could be beneficial.
- Quantization/pruning: there is no exploration of model compression (INT8 quantization, pruning) for deployment with minimal accuracy loss.
- Calibration across detectors: while a detector-agnostic model works broadly, a principled method to auto-calibrate or adapt the refinement magnitude per detector/domain without retraining is not provided.
Practical Applications
Immediate Applications
The following opportunities can be deployed now using the released XRefine code and models (https://github.com/boschresearch/xrefine). Each item notes relevant sectors, concrete workflows/products, and key assumptions/dependencies.
- Visual SLAM and VO accuracy boosts on edge devices
- Sectors: robotics, drones/UAS, AR/VR, mobile mapping, warehouse automation
- Workflow/product: insert XRefine after matching (e.g., SuperPoint/LightGlue, XFeat/MNN, DeDoDe/DSM) and before robust pose estimation (e.g., GC-RANSAC) to reduce reprojection/epipolar error and improve pose AUC; export the provided PyTorch model to ONNX/TensorRT for embedded GPUs/NPUs.
- Why now: detector-agnostic; no re-training required across detectors; ~3.6 ms per 2048 matches on RTX A5000; consistent AUC gains on MegaDepth and ScanNet, and moderate improvements on KITTI.
- Assumptions/dependencies: needs reasonably good initial matches (inliers); limited effect if detectors are already sub-pixel or scenes are trivial (e.g., KITTI-like VO); grayscale patches suffice; outliers still need robust estimation (e.g., RANSAC).
- Faster, cheaper photogrammetry pipelines
- Sectors: surveying, construction/BIM updates, cultural heritage, e-commerce 3D asset capture, film/VFX
- Workflow/product: drop-in refinement in COLMAP/OpenMVG/OpenSfM/HLoc pipelines as a lightweight alternative to feature-metric refinement (e.g., PixSfM) to reduce compute cost and still improve camera pose and triangulation; batch patch extraction to keep throughput high.
- Why now: single forward pass vs. costly multi-iteration optimization; linear scaling in track length with the n-view variant; improves ETH3D triangulation accuracy over no refinement.
- Assumptions/dependencies: multi-view tracks available; small residual may remain vs. global joint optimization (PixSfM), trading peak accuracy for substantial speed.
- AR localization and drift reduction in consumer apps
- Sectors: mobile AR (retail try-on, measurement, navigation), gaming
- Workflow/product: integrate XRefine into visual localization back-ends (e.g., after SuperPoint/LightGlue) to refine correspondences before PnP/EPnP; reduces drift, improves relocalization under lightweight compute budgets.
- Why now: detector-agnostic, patch-only inference enables on-device deployment without descriptor coupling.
- Assumptions/dependencies: benefits grow with pixel-accurate detectors (e.g., SuperPoint, XFeat); limited under uniform textures or severe motion blur.
- Robustness upgrades for UAV/robot inspection and mapping
- Sectors: infrastructure inspection (wind, solar, bridges), agriculture, mining
- Workflow/product: refine matches prior to relative pose and triangulation in aerial photogrammetry and VIO stacks to improve alignment, especially across varying viewpoints/lighting common in outdoor flights.
- Why now: consistent improvements reported across several detectors and datasets; easy integration between matching and estimation.
- Assumptions/dependencies: assumes mostly rigid scenes; dynamic elements require outlier handling; rolling-shutter effects not explicitly modeled.
- Academic baselines and detector-agnostic benchmarking
- Sectors: academia, R&D
- Workflow/product: standardize “with refinement” baselines across detectors without per-detector retraining; ablate effects of spatial keypoint noise on pose/triangulation; evaluate n-view refinement vs. pairwise-only refinement.
- Why now: open-source, fast, detector-agnostic; clear, reproducible gains for pose AUC and triangulation.
- Assumptions/dependencies: training objective leverages epipolar error; generalization strongest within similar domains (RGB imagery).
- Energy- and cost-aware deployment policies for edge vision
- Sectors: policy/enterprise IT, sustainability programs
- Workflow/product: update internal guidelines and procurement checklists to favor patch-based refinement over heavy dense or feature-metric optimization when latency/energy constraints exist; quantify savings vs. accuracy trade-offs in tenders.
- Why now: orders-of-magnitude runtime savings vs. feature-metric optimization; enables on-device processing to reduce data transfer.
- Assumptions/dependencies: acceptance of slightly lower peak accuracy than global multi-view optimization in some SfM use-cases.
- Industrial metrology and calibration pipelines
- Sectors: manufacturing, robotics calibration, warehouse vision systems
- Workflow/product: refine keypoints in multi-view calibration boards and structured scenes to reduce systematic bias in estimated extrinsics; integrate into existing calibration toolchains between detection and PnP/BA.
- Why now: sub-pixel refinement from only patches; runtime and memory friendly for production rigs.
- Assumptions/dependencies: scenes must be rigid; benefits depend on detector precision and camera resolution.
- Map-building and 3D reconstruction in indoor navigation
- Sectors: retail/warehousing, facilities management, security
- Workflow/product: improve VSLAM-based mapping accuracy by refining feature tracks against a reference patch (n-view variant), especially in texture-poor corridors and repetitive patterns.
- Why now: linear complexity per track; gains demonstrated on ScanNet.
- Assumptions/dependencies: requires stable reference view selection per track; insufficient texture still limits absolute performance.
Long-Term Applications
These require additional research, scaling, or engineering effort beyond the current release, but are natural extensions indicated by the paper’s methods and results.
- Global n-view refinement module (beyond pairwise-to-reference)
- Sectors: photogrammetry, autonomous driving, robotics, digital twins
- Product direction: extend architecture to jointly process multiple patches per track for globally consistent refinement (as suggested in the paper’s conclusion); potentially replace feature-metric optimization in full SfM/BA loops under tight compute constraints.
- Dependencies/assumptions: new model design for multi-patch attention; careful scheduling with BA; benchmarking vs. PixSfM for accuracy/latency trade-offs.
- End-to-end learned sparse pipelines (extract–match–refine–estimate)
- Sectors: AR/VR, robotics, mobile vision
- Product direction: co-train detectors/matchers with XRefine in the loop under epipolar/geometric losses; learn detector priors that exploit downstream refinement to save compute (e.g., pixel-level keypoints + sub-pixel refinement).
- Dependencies/assumptions: training stability and data diversity; careful prevention of degenerate solutions; hardware-aware training.
- Domain-specialized refinement (thermal, underwater, endoscopic, aerial)
- Sectors: healthcare (endoscopy/laparoscopy SLAM), defense/public safety (thermal/IR), marine robotics, satellite/aerial analytics
- Product direction: fine-tune XRefine for non-RGB domains and harsh conditions (specularities, scattering, low SNR); integrate modality-aware positional encodings or fusion with depth/IMU.
- Dependencies/assumptions: labeled or weakly supervised epipolar data in new modalities; potentially modified patch normalization; robustness to non-rigid tissue motion in medical contexts.
- Rolling-shutter and non-rigid aware refinement
- Sectors: mobile devices, automotive cameras, medical robotics
- Product direction: incorporate motion models or time-warped positional encodings so refinement remains consistent under rolling-shutter or mild non-rigid motion; integrate with VIO to use inertial cues during refinement.
- Dependencies/assumptions: time synchronization and exposure readout models; modest model complexity increase.
- On-device NPU acceleration and SDKs
- Sectors: smartphones, wearables, drones, cobots
- Product direction: optimized kernels for cross-attention on NPUs; developer SDKs with ONNX/TensorRT/TVM backends; ROS2 nodes for plug-and-play refinement in robotic stacks.
- Dependencies/assumptions: vendor-specific toolchains; quantization-aware training to preserve sub-pixel accuracy.
- Self-supervised/online refinement adaptation
- Sectors: mobile robotics, long-term autonomy, fleet learning
- Product direction: on-the-fly fine-tuning using epipolar consistency or BA residuals as weak supervision to adapt to new environments (lighting, weather, lens aging).
- Dependencies/assumptions: safeguards against drift and confirmation bias; lightweight optimization that respects real-time constraints.
- Privacy-preserving remote pipelines
- Sectors: policy/compliance, cloud photogrammetry services
- Product direction: transmit only small encrypted patches around matched keypoints for cloud refinement/pose estimation, keeping full images on-device.
- Dependencies/assumptions: robust on-device matching; secure patch selection; acceptable accuracy with partial data.
- Safety-certified refinement for autonomous systems
- Sectors: automotive, industrial robotics
- Product direction: formalize verification/validation protocols for refinement modules (detector-agnostic baseline + bounds on induced pose error); integrate into safety cases as a deterministic post-processing stage with known failure modes.
- Dependencies/assumptions: standards alignment (e.g., ISO 26262); comprehensive corner-case testing (low light, glare, repetitive textures).
- Tooling for 3D content creation at scale
- Sectors: gaming, film, digital commerce
- Product direction: batch refinement in asset pipelines to reduce manual cleanup of reconstructions; plugins for DCC tools (e.g., Blender, Unreal) to improve camera solve stability.
- Dependencies/assumptions: pipeline integration and UX; measuring ROI in reduced artist-hours vs. increased preprocessing time.
Notes on feasibility across applications:
- Most gains appear when detectors output pixel-accurate keypoints (e.g., SuperPoint, XFeat) or when viewpoints/appearance vary significantly (MegaDepth/ScanNet-like). Gains are smaller on easy VO sequences (KITTI-like).
- Robust outlier rejection remains essential; XRefine assumes matched patches correspond to the same 3D point.
- Generalization beyond RGB imagery or to highly dynamic scenes requires fine-tuning or model extensions.
Glossary
- AUC (Area Under Curve): A performance metric summarizing how a value (e.g., accuracy) varies across thresholds; here used for pose error thresholds. "area under curve (AUC)"
- AUC5: AUC computed at a 5-degree pose error threshold, commonly used to compare relative pose estimation quality. "relative increase in AUC5"
- cross-attention: An attention mechanism where one feature set attends to another to exchange information. "cross-attention-based architecture"
- detector-agnostic: Not tied to a specific keypoint detector; works across detectors without retraining. "a novel, detector-agnostic approach"
- descriptor (keypoint descriptor): A vector representation of a local image region used to match keypoints across images. "keypoint descriptors"
- double soft max (DSM): A matching strategy applying softmax normalization in both matching directions to improve mutual consistency. "double soft max (DSM)"
- epipolar error: The geometric inconsistency of matched points relative to the epipolar constraint induced by two camera views. "optimizing the epipolar error directly."
- essential matrix: A 3×3 matrix encoding the relative rotation and translation between two calibrated cameras. "ground truth essential matrices"
- feature-metric bundle adjustment: Joint optimization of camera and structure parameters using distances in a learned feature space. "feature-metric bundle adjustment"
- feature-metric optimization: Refinement using similarity in feature space rather than raw pixel intensities or purely geometric costs. "feature-metric optimization"
- feature track: A sequence of corresponding keypoints representing the same 3D point across multiple images. "feature tracks"
- GC-RANSAC: A robust model estimation method that combines RANSAC with graph-cut optimization for better inlier selection. "GC-RANSAC"
- Homographic Adaptation: Training augmentation that applies random homographies to bootstrap and stabilize keypoint learning. "Homographic Adaptation"
- inverse compositional LK: An efficient variant of Lucas–Kanade image alignment that swaps roles of template and input for faster updates. "inverse compositional LK"
- keypoint repeatability: The ability of a detector to find the same points under varying conditions and viewpoints. "keypoint repeatability"
- mutual nearest neighbor matching (MNN): A filtering rule keeping only matches where each point is the other’s nearest neighbor in descriptor space. "mutual nearest neighbor matching (MNN)"
- n-view: Refers to scenarios involving more than two views (images) of a scene. "-view feature tracks"
- positional encoding: A learned vector added to tokens to encode spatial position for attention-based models. "positional encoding"
- relative pose estimation: Estimating the rotation and translation between two camera views. "relative pose estimation"
- Simultaneous Localization And Mapping (SLAM): Building a map of an environment while estimating the sensor’s position within it. "Simultaneous Localization And Mapping (SLAM)"
- soft-argmax: A differentiable approximation of argmax that computes the expectation over a probability map to yield continuous coordinates. "spatial soft-argmax"
- Structure-from-Motion (SfM): Reconstructing 3D structure and camera motion from multiple images. "Structure-from-Motion"
- sub-pixel: Precision finer than one pixel, enabling more accurate localization of keypoints. "sub-pixel keypoint refinement"
- triangulation: Computing 3D point positions from their 2D projections across multiple views. "point cloud triangulation"
- visual odometry: Estimating a camera’s motion from sequential visual inputs. "visual odometry"
Collections
Sign up for free to add this paper to one or more collections.