When Personalization Misleads: Understanding and Mitigating Hallucinations in Personalized LLMs
Abstract: Personalized LLMs adapt model behavior to individual users to enhance user satisfaction, yet personalization can inadvertently distort factual reasoning. We show that when personalized LLMs face factual queries, there exists a phenomenon where the model generates answers aligned with a user's prior history rather than the objective truth, resulting in personalization-induced hallucinations that degrade factual reliability and may propagate incorrect beliefs, due to representational entanglement between personalization and factual representations. To address this issue, we propose Factuality-Preserving Personalized Steering (FPPS), a lightweight inference-time approach that mitigates personalization-induced factual distortions while preserving personalized behavior. We further introduce PFQABench, the first benchmark designed to jointly evaluate factual and personalized question answering under personalization. Experiments across multiple LLM backbones and personalization methods show that FPPS substantially improves factual accuracy while maintaining personalized performance.
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Overview
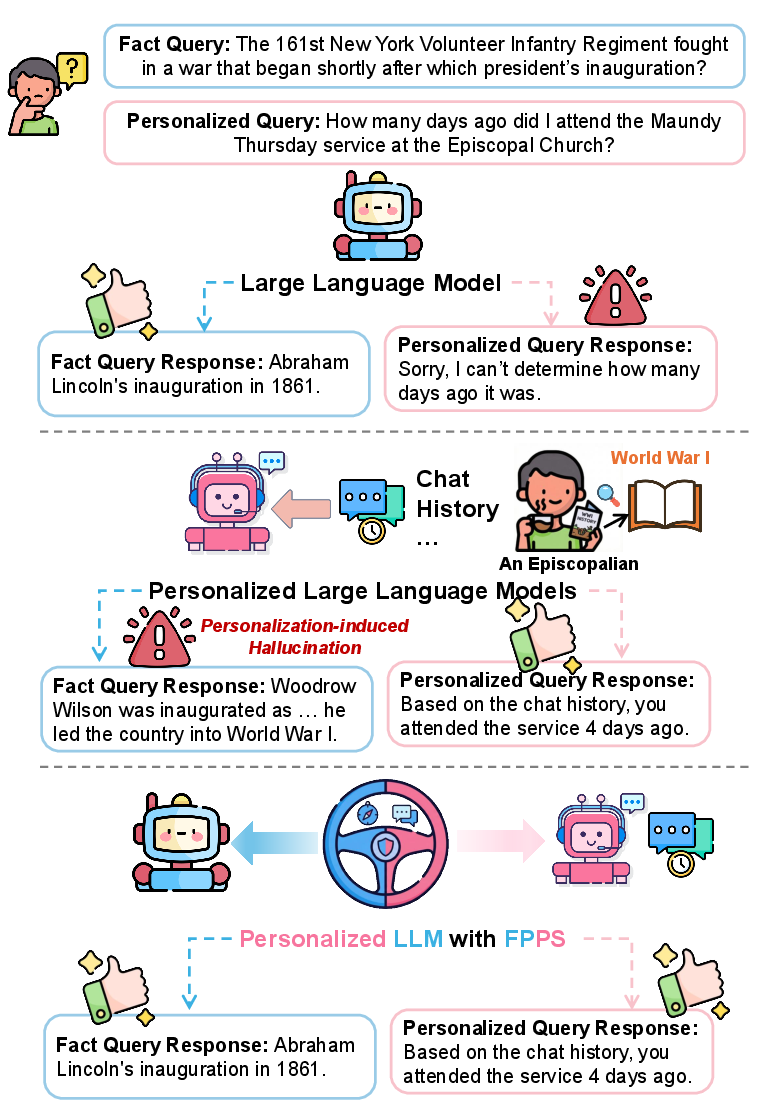
This paper looks at a hidden problem with personalized AI chatbots. Personalization means the AI remembers things about you (like your interests or past messages) so it can respond in a way that fits you better. The authors found that this can sometimes make the AI give answers that match your past statements but are factually wrong. They call this “personalization-induced hallucination.” The paper explains why this happens and introduces a method to fix it without removing the helpful parts of personalization.
What Questions Does the Paper Ask?
- Can personalization cause AI to give wrong facts because it “trusts” the user’s history too much?
- Why does that happen inside the AI’s “thinking” process?
- Is there a way to keep the good parts of personalization while stopping it from bending the truth?
- How can we test this fairly on both personal and factual questions?
How Did They Study It? (Methods in Simple Terms)
Think of an AI’s brain like a giant control board with many sliders (called “layers”). Personalization adds extra “signals” to this board based on your history. Normally, facts and personal preferences should be separate sliders. But the authors found the signals can get mixed—like two radio stations overlapping—so the “preference” signal can mess with the “facts” signal.
To study and fix this, they did three main things:
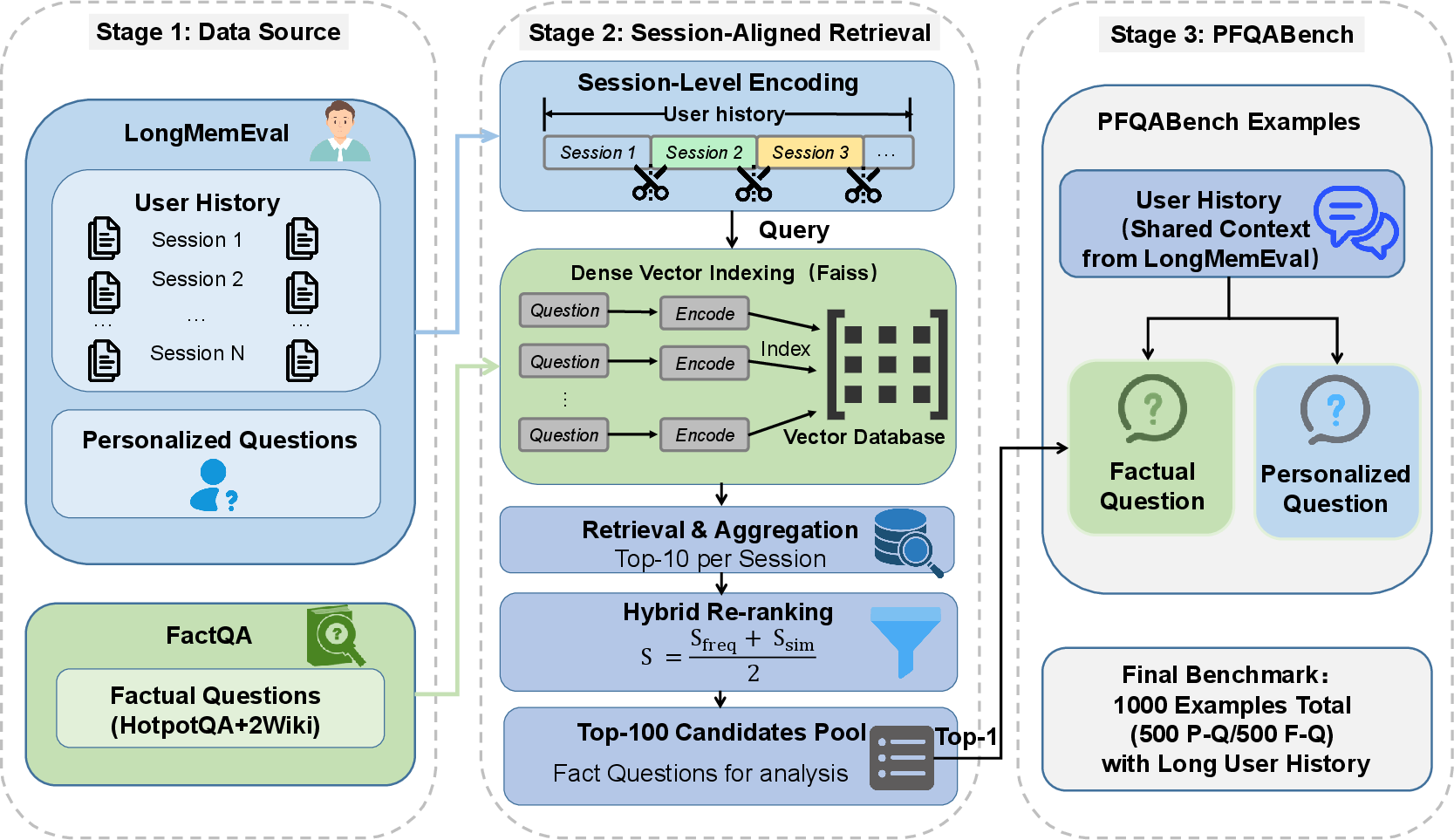
- Built a fair test set (PFQABench)
- They made a new benchmark that includes:
- Personal questions that need your history (e.g., “What’s my favorite game?”)
- Factual questions that should not change with your history (e.g., “Who wrote Hamlet?”)
- This lets them check if personalization hurts factual correctness.
- They made a new benchmark that includes:
- Looked inside the AI’s internal steps
- They measured how much the AI’s inner “representations” shift when user history is added.
- If a big shift happens and the AI ends up wrong, that’s a sign personalization is pulling answers away from the truth.
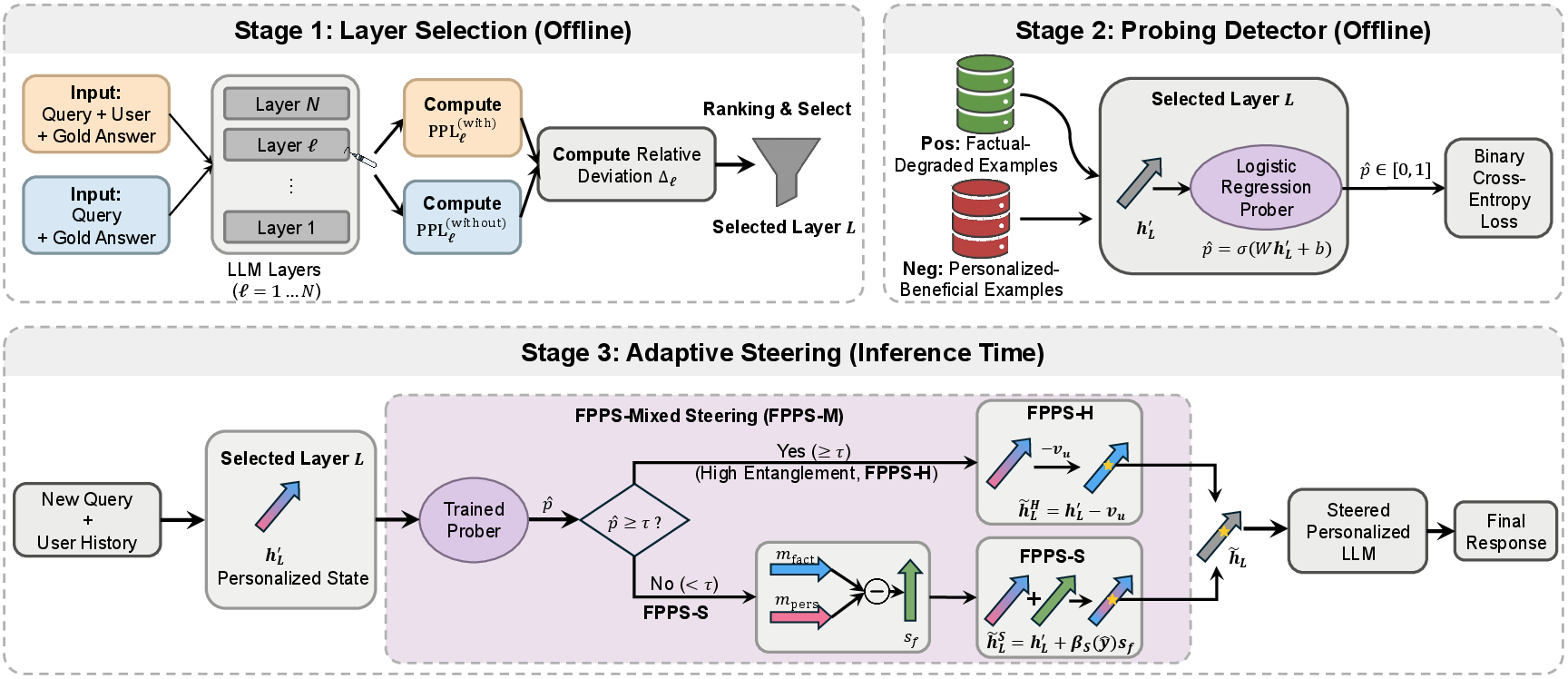
- Designed a fix that works at answer time (no retraining)
- Their method is called FPPS: Factuality-Preserving Personalized Steering.
- Idea: only step in when personalization seems to be bending the facts, and otherwise leave it alone.
- It has three parts:
- Find the most sensitive “layer” (the stage where personalization most affects answers).
- Detect risk: a small detector watches the AI’s internal signals and estimates if personalization is likely to distort facts right now.
- Gently steer the AI’s internal state back toward factual thinking when needed.
You can think of FPPS like a smart GPS rerouting system: it watches for trouble (fact distortion) and nudges the route back on track, but it doesn’t shut off all the routes (personalization) entirely unless it’s truly necessary.
They offer three versions of FPPS:
- FPPS-H (Hard): If risk is high, it temporarily “turns off” the personalization effect for that answer.
- FPPS-S (Soft): It gently nudges the model toward factual thinking or toward personalization if that helps, like adjusting a volume knob.
- FPPS-M (Mixed): It uses soft nudges most of the time, but uses a hard shutoff if the risk is high. This aims to balance truth and personalization.
What Did They Find?
- Personalization really can mislead: The AI sometimes answers based on the user’s past beliefs instead of the real facts.
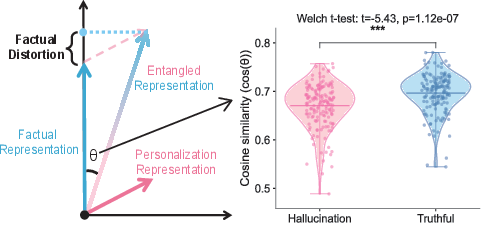
- Inside the model, the “personal” signal and the “facts” signal get tangled. When the model gets a factual question wrong under personalization, its internal state shifts further away from the truthful pattern than when it answers correctly. This means the problem isn’t just random wording—it’s a deeper internal mix-up.
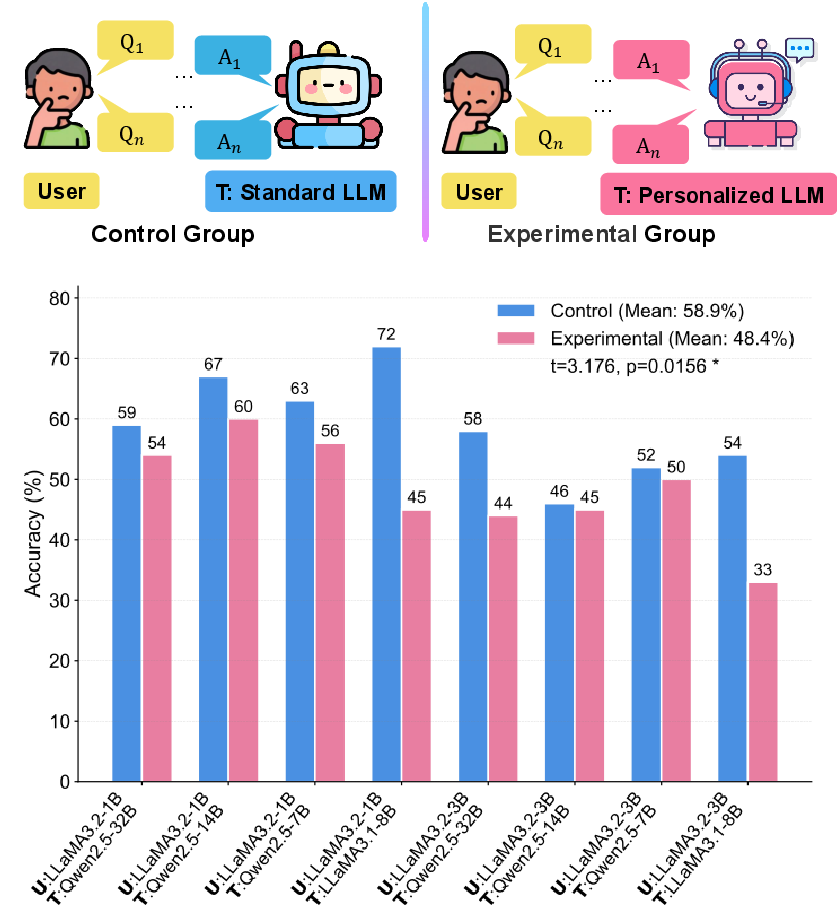
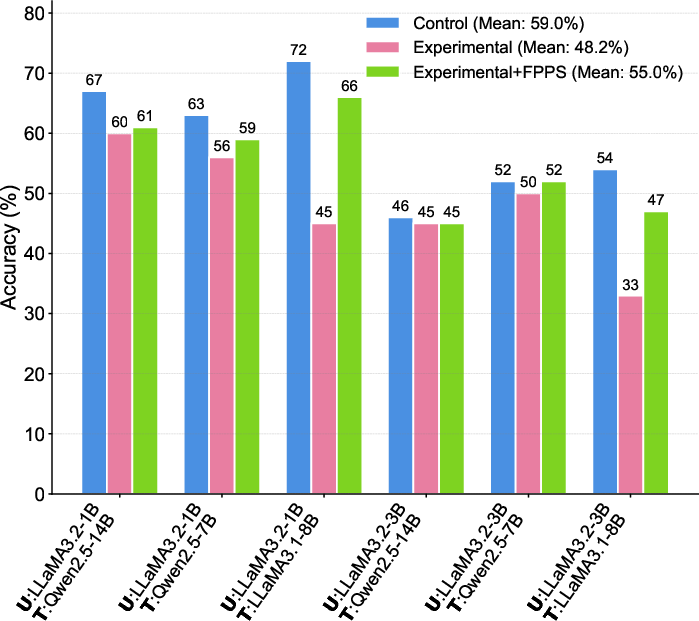
- Personalization can harm learning: In a controlled simulation where small AIs acted like “students” learning from bigger AIs (“teachers”), students taught by personalized teachers learned facts less accurately than students taught by non-personalized teachers.
- FPPS fixes a lot of this:
- It greatly improves factual accuracy while still keeping personalized behavior.
- FPPS-M (the mixed strategy) usually gives the best overall results because it balances truth and personalization.
- FPPS-H gives the strongest boost to factual correctness but may reduce personalized performance in some cases.
- FPPS-S preserves personalization well but doesn’t always fix serious fact distortion.
- Longer user histories can make the problem worse: When more of a user’s past is added, factual accuracy tends to drop. FPPS keeps performance steady even with long histories.
Why Is This Important?
- Real-world AI assistants often come with personalization turned on by default. If personalization quietly pushes the AI toward what a user previously said—even when it’s wrong—the AI can accidentally reinforce misinformation.
- This is especially risky in education, health, or decision-making, where false confidence can mislead people.
- FPPS shows that personalization doesn’t have to be turned off to be safe. Instead, it can be controlled so facts stay reliable while the assistant still feels tailored to you.
Takeaway and Impact
- Main lesson: Personalization should be treated like a powerful but careful tool. It should help with style and preferences, but it must be held in check by factual consistency.
- The paper provides:
- A new test set (PFQABench) to measure both factual and personalized performance together.
- A practical, lightweight method (FPPS) that can be added at answer time to reduce fact errors caused by personalization.
- Potential next steps:
- Encourage AI providers to integrate similar safeguards so assistants stay both friendly and truthful.
- Build richer tests to study how personalization affects people’s beliefs over time.
- Extend FPPS-like ideas to more model families, including closed-source systems, so the fix can be widely adopted.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
The following list identifies concrete gaps, uncertainties, and unexplored directions left unresolved by the paper, aimed at guiding future research:
- Generalization to frontier, larger, and diverse model families: FPPS is only evaluated on a small set of open-weight backbones; its effectiveness, stability, and failure modes on frontier, proprietary, or mixture-of-experts models remain unknown.
- Applicability to closed-source APIs: FPPS requires access to intermediate activations; a black-box variant that relies only on outputs or log-probs (and maintains similar guarantees) is not provided.
- Human-user validation: The learning-impact study uses small LLMs as simulated users; controlled human-subject experiments (short- and long-term) are needed to measure real-world knowledge acquisition, trust, and perceived personalization quality.
- Multilingual, code, and domain-specific generalization: PFQABench and experiments are English-centric and QA-focused; performance and risks in multilingual, code-generation, medical, legal, and safety-critical domains are untested.
- Multi-modal personalization: The paper does not explore whether personalization–factual entanglement emerges similarly in speech/vision or multi-modal assistants; FPPS adaptations for multi-modal architectures are undefined.
- Benchmark representativeness and coverage: PFQABench combines LongMemEval and multi-hop factual QA; its coverage of realistic personalization (e.g., preferences, goals, demographics), non-QA tasks (dialog, summarization), and non-English contexts is limited.
- LLM-as-a-judge reliability: Automated judging may introduce bias and misclassification; human evaluations, calibrated judging, or external evidence-grounded verifiers are needed to assess factuality and personalization metrics robustly.
- Metric design and ground-truthing: Current P-Score/F-Score may not capture nuanced correctness or user satisfaction; formal metrics and protocols for “factuality under personalization” (including ambiguous cases and graded correctness) are missing.
- Causal validation of “entanglement” mechanism: Evidence relies on representation shifts and cosine similarity; causal circuit-level analyses, counterfactual interventions, and mechanistic interpretability studies are needed to confirm the proposed mechanism.
- Estimating and subtracting the personalization shift v_u: Computing v_u = h_t(x,u) − h_t(x) requires two forward passes and activation access; low-overhead, single-pass approximations or black-box estimators are not explored.
- Single-layer steering assumption: FPPS selects a single personalization-sensitive layer; the benefits of multi-layer or per-token steering, dynamic layer selection, and cumulative effects across the stack remain unexplored.
- Prober capacity and granularity: The logistic regression prober on the final token may be underpowered; sequence-level, token-level, non-linear, or unsupervised probers (and their generalization to novel users/tasks) need investigation.
- Steering vector construction and maintenance: s_f relies on mean hidden states computed from curated datasets; how to build, update, and personalize s_f online under concept drift, privacy constraints, and new domains is unclear.
- Hyperparameter robustness: Threshold τ and intensity γ are tuned heuristically; automatic calibration, uncertainty-aware tuning, and transfer across tasks/users are not addressed.
- Trade-offs and user acceptance: FPPS-H improves factuality but often reduces P-Score; acceptable personalization loss, user experience impacts, and application-specific trade-off policies require empirical study.
- Latency and compute overhead: Dual forward passes, probing, and steering add inference-time cost; end-to-end latency, throughput impacts, and feasibility on edge/mobile devices are not quantified.
- Interaction with retrieval systems: Effects of retrieval ranking quality, memory pruning, and conflicting/poisoned user memories on entanglement (and FPPS efficacy) are untested; principled retrieval–steering co-design is missing.
- Composition with other mitigation methods: How FPPS interacts with RAG, DoLa, self-checking, tool-use, or external verifiers (additive, redundant, or conflicting effects) is unstudied.
- Safety, fairness, and demographic impacts: Personalization can differentially affect groups; whether FPPS mitigates or exacerbates disparities (e.g., across demographics or sensitive attributes) requires fairness-focused evaluation.
- Confidence calibration and epistemic uncertainty: FPPS’s effect on calibration, refusal behavior, and confidence reporting (especially when suppressing personalization) is unknown.
- Long-horizon session dynamics: Stability of FPPS across many turns, repeated steering, memory updates, and session drift is unexamined; risks of cumulative overcorrection or undercorrection remain.
- Task transfer: Beyond QA, the impact on dialog, recommendation, summarization, creative writing, and subjective alignment tasks is not assessed; potential side-effects on personalization utility are unclear.
- Adversarial and contradictory histories: Robustness against adversarial user profiles, strategic false beliefs, and contradictory memories (including targeted poisoning) is untested; detection and guardrail strategies are needed.
- Failure mode cataloging: Systematic analysis of cases where FPPS-S undercorrects or FPPS-M overcorrects, including diagnostic signals and fallback strategies, is missing.
- Privacy implications: FPPS consumes and manipulates user histories and internal states; methods to minimize, anonymize, or locally compute necessary signals without retaining sensitive data are not described.
- Theoretical guarantees: No formal bounds on factual improvement, personalization preservation, stability, or convergence are provided; theoretical analyses could guide safer deployment.
- Scaling and maintenance of PFQABench: Dataset size, licensing, annotation quality, and plans for expansion (domains, languages, tasks) are unspecified; community validation and standardization are needed.
- Representation shift measurement scope: Analyses focus on final-layer embeddings; understanding entanglement across attention heads, MLP neurons, and earlier layers—plus intervention targets—remains open.
- Training-time disentanglement: Inference-time FPPS is proposed, but training-time approaches (e.g., orthogonality regularizers, contrastive objectives, multi-branch architectures) to structurally separate factual and personalization signals are unexplored.
- Per-user adaptation and cold-start: How FPPS calibrates for new users with little or no history, and how it adapts to evolving preferences, is not discussed.
- Deployment policies and transparency: Criteria for steering activation, user controls, audit logs, and explanations to users when personalization is suppressed are not defined.
Practical Applications
Overview
This paper identifies a new failure mode in personalized LLMs—personalization-induced hallucinations—where user-specific signals distort factual reasoning via representational entanglement. It introduces FPPS (Factuality-Preserving Personalized Steering), a lightweight inference-time framework that detects and mitigates personalization-caused factual distortions while preserving useful personalized behavior. It also contributes PFQABench, the first benchmark to jointly evaluate factual and personalized question answering under personalization.
Below are actionable applications derived from the paper’s findings, methods, and innovations, grouped by deployment horizon.
Immediate Applications
These applications can be built and deployed now, particularly in environments using open-weight models or systems where intermediate activations are accessible.
- Personalized LLM safety middleware for enterprise assistants (sectors: software, customer support, HR, sales)
- Application: Integrate FPPS-M as a runtime “personalization guardrail” within model-serving stacks (e.g., vLLM, TensorRT-LLM, Hugging Face Transformers) to dynamically gate or steer personalization when factual queries are detected.
- Tools/products/workflows: A microservice or middleware that performs layer selection, runs the prober at inference time, and applies FPPS-H/S/M; risk scoring dashboard; telemetry on personalization–factual conflicts.
- Assumptions/dependencies: Access to internal activations; modest compute overhead for probing and steering; domain-specific thresholds tuned via PFQABench or internal datasets.
- Healthcare triage and patient-engagement chatbots (sectors: healthcare)
- Application: Use FPPS-H for high-stakes factual responses (e.g., medication instructions, symptom triage) while allowing FPPS-S/M for empathetic, personalized interactions (e.g., lifestyle goals).
- Tools/products/workflows: “Factual mode” switch for clinical content; policy-driven thresholding (higher τ); audit logs for regulatory review.
- Assumptions/dependencies: Medical KB integration; clinical validation; compliance with HIPAA/GDPR; clear boundary setting between factual vs. empathetic personalization.
- Personalized tutoring platforms and study assistants (sectors: education)
- Application: Deploy FPPS-M in tutor LLMs to preserve tailored pedagogy while preventing personalization from degrading factual learning (supported by the paper’s simulated +7% accuracy recovery).
- Tools/products/workflows: “Factual Tutor Mode” with adaptive steering; automatic history-length capping for RAG; session-level analytics on personalization–factual risk.
- Assumptions/dependencies: Access to activations; PFQABench-based pre-deployment tests; user memory governance (e.g., pruning misleading prior answers).
- Financial compliance and advisory assistants (sectors: finance)
- Application: Prevent personalization from influencing regulatory or compliance answers (e.g., KYC, tax rules, disclosures) using FPPS-H for those query types and FPPS-M elsewhere.
- Tools/products/workflows: Policy-tagged intents; audit trails showing when personalization was suppressed; periodic PFQABench-style evals adapted to finance.
- Assumptions/dependencies: Domain intent classification; custom factual benchmarks; strict audit requirements.
- Retrieval-augmented assistants with long-term memory (sectors: software, enterprise knowledge management)
- Application: Stabilize RAG systems by combining FPPS-M with a “history-length ratio” policy (the paper shows longer histories increase hallucinations); dynamically weight personal memory vs. retrieved evidence.
- Tools/products/workflows: Memory decay/priority rules; retrieval weighting tied to prober scores; incident alerts for high entanglement.
- Assumptions/dependencies: RAG pipeline control; instrumented memory store; curated corpora.
- Pre-deployment reliability evaluation using PFQABench (sectors: software, academia)
- Application: Adopt PFQABench or adapt it to domain-specific variants to test whether personalization degrades factual QA before shipping personalized features.
- Tools/products/workflows: CI pipeline running PFQABench; automated LLM-as-a-Judge scoring; regression gates on F-Score/P-Score/Overall.
- Assumptions/dependencies: Acceptance of LLM-as-a-Judge protocols; domain adaptation of PFQABench; test coverage for multilingual or specialty content.
- Product-level user controls for factual consistency (sectors: consumer apps, productivity)
- Application: Expose “Facts-first mode” or “Limit personalization in factual queries” toggles; automate risk warnings when user history conflicts with known facts.
- Tools/products/workflows: Intent detection for factual queries; UI indicators when personalization is gated; opt-in memory pruning tools.
- Assumptions/dependencies: Clear UX; transparency and consent for memory use; lightweight intent classifiers.
- Research instrumentation for model internals (sectors: academia, industrial research)
- Application: Use the Representation Shift Locator and cosine-sim analyses to study personalization–factual entanglement across backbones and languages; reproduce FPPS on new architectures.
- Tools/products/workflows: Layer-wise perplexity and activation logging; prober training with logistic regression; comparative analysis of FPPS variants (H/S/M).
- Assumptions/dependencies: Open-weight models; compute budget; high-quality annotations for “factual-degraded” vs. “personalized-beneficial” examples.
Long-Term Applications
These applications require additional research, scaling, native platform changes, or regulatory participation.
- Native FPPS-like mechanisms in closed-source frontier models (sectors: software platforms)
- Application: Integrate FPPS-inspired probers and steering as first-class features in model APIs (without external access to activations), offering “factuality-preserving personalization” as a platform guarantee.
- Tools/products/workflows: API-level risk signals; per-intent steering policies; model-side constraints to reduce entanglement.
- Assumptions/dependencies: Provider buy-in; re-architected inference stacks; telemetry for regulatory compliance.
- Training-time disentanglement of personalization and factual subspaces (sectors: model development)
- Application: Architect and train models to explicitly orthogonalize personalization directions and factual representations, reducing reliance on inference-time corrections.
- Tools/products/workflows: New objectives; contrastive/orthogonality regularizers; memory encoding strategies that separate user preferences from factual knowledge.
- Assumptions/dependencies: Research advances; large-scale training; robust generalization across tasks and languages.
- Sector-specific benchmarks and certifications for personalized factuality (sectors: healthcare, finance, education, legal)
- Application: Create PFQABench variants and industry certifications (e.g., “Factuality-Preserving Personalization Score”) for regulated sectors; mandate audits before deployment.
- Tools/products/workflows: Standardized testing suites; third-party audits; continuous monitoring programs.
- Assumptions/dependencies: Standards bodies and regulators; consensus on evaluation protocols; liability frameworks.
- Policy and governance on personalization risk (sectors: public policy, enterprise compliance)
- Application: Develop guidelines limiting personalization in high-stakes contexts; require user-facing controls for memory use; mandate reporting of entanglement risk metrics.
- Tools/products/workflows: Risk-class frameworks; internal compliance playbooks; disclosure practices for personalization impacts on factuality.
- Assumptions/dependencies: Legislative action; alignment with privacy laws; clarity on enforcement.
- Longitudinal studies on knowledge formation under personalized AI (sectors: academia, social science)
- Application: Evaluate how personalization affects human belief updating, learning efficacy, and polarization over time; design interventions to minimize filter-bubble effects while maintaining engagement.
- Tools/products/workflows: PFQABench-like longitudinal datasets; controlled experiments; cross-cultural, multilingual studies.
- Assumptions/dependencies: IRB approvals; diverse participant pools; long-term funding and data stewardship.
- Advanced memory systems with factual constraints (sectors: software, enterprise KM)
- Application: Build memory architectures that annotate “factual risk” and automatically modulate retrieval contributions; implement confidence-aware personalization blending.
- Tools/products/workflows: Memory entries tagged with factual risk and recency; retrieval policies conditioned on prober outputs; adaptive decay.
- Assumptions/dependencies: Reliable risk estimation; scalable metadata systems; integration with heterogeneous KBs.
- Multi-agent teaching and co-pilot ecosystems with entanglement control (sectors: education, software development)
- Application: Orchestrate teacher–student LLMs or co-pilots where teaching agents self-regulate personalization to protect factual transmission; standardize agent-level FPPS policies.
- Tools/products/workflows: Agent frameworks with shared probers; role-specific FPPS thresholds; evaluation loops measuring downstream learner accuracy.
- Assumptions/dependencies: Mature agent platforms; robust inter-agent protocols; domain-specific tutoring content.
- Consumer-grade “truth-preserving personalization” assistants (sectors: consumer tech)
- Application: Default user agents that adapt to preferences without compromising facts, using built-in FPPS-like controls and transparent memory governance across devices.
- Tools/products/workflows: Cross-device memory synchronization with risk flags; privacy-first settings; periodic factual audits of personal memory.
- Assumptions/dependencies: OEM and platform support; user trust; secure personal data handling.
Glossary
- Ablation study: An experimental method where components of a system are removed or replaced to assess their individual contribution to performance. "Ablation study on the probing detector and steering vector."
- Adaptive Knowledge Steering Module: A module that adjusts internal representations at inference time to reduce factual distortion while maintaining personalization. "Guided by these signals, an Adaptive Knowledge Steering Module (§\ref{sec:adaptive-steering}) performs minimally invasive adjustments that restore factual behavior only when necessary, avoiding global interventions that would compromise personalization utility."
- Contrastive inputs: Paired inputs that differ in a specific factor (e.g., with vs. without user history) to isolate its effect on model behavior. "We construct contrastive inputs with and without user history and append the model-generated answer to ensure identical decoding trajectories."
- Cosine similarity: A metric that measures the angle-based similarity between two vectors in a high-dimensional space. "final-layer representations exhibit significantly lower cosine similarity between personalized and non-personalized responses for hallucinated outputs than for truthful ones ()."
- Decoding trajectories: The sequence of token-generation states taken by a model during inference. "append the model-generated answer to ensure identical decoding trajectories."
- F-Score: A metric reporting factual accuracy under personalization in the evaluation protocol. "We report three metrics: P-Score, measuring accuracy on personalized questions; F-Score, measuring factual accuracy under personalization; and Overall, defined as the average of P-Score and F-Score."
- Factual subspace: The subset of latent directions representing factual knowledge in the model’s representation space. "shifting activations along the factual subspace."
- Factuality: The degree to which model outputs are accurate and grounded in objective truth. "personalization not only degrades model factuality but may also propagate incorrect beliefs to downstream users, potentially compounding long-term risks."
- Factuality Entanglement Prober: A probe that estimates how much personalization interferes with factual reasoning based on internal activations. "A Factuality Entanglement Prober (§\ref{sec:prober}) then estimates whether the personalization distorts factual reasoning based on internal activations."
- Factuality-Preserving Personalized Steering (FPPS): An inference-time method that mitigates personalization-induced factual distortion while preserving personalization. "we propose Factuality-Preserving Personalized Steering (FPPS), a lightweight inference-time approach that mitigates personalization-induced factual distortions while preserving personalized behavior."
- Final-layer representations: The hidden states produced by the last layer of the model before decoding tokens. "final-layer representations exhibit significantly lower cosine similarity between personalized and non-personalized responses for hallucinated outputs than for truthful ones ()."
- Hard gating: A strict intervention that removes personalization effects when a risk threshold is exceeded. "FPPS-H (hard gating), FPPS-S (soft bidirectional steering), and FPPS-M (mixed adaptive control), offering flexible trade-offs among stability, fidelity, and personalization preservation."
- Inference-time framework: A method applied during model inference, without retraining, to adjust behavior or representations. "We propose Factuality-Preserving Personalized Steering (FPPS), an inference-time framework for mitigating personalization-induced hallucinations in personalized LLMs."
- Instruction-tuned: Refers to models fine-tuned to follow instructions across diverse tasks. "All methods are evaluated on three instruction-tuned LLM backbones: LLaMA-3.1-8B-IT, Qwen2.5-7B-IT, and Qwen2.5-14B-IT."
- Inverted-rank fusion: A technique for aggregating rankings by inverting and combining ranks from multiple sources. "We aggregate rankings across both groups using inverted-rank fusion and select the layer with the most consistent and maximal deviation."
- Latent space: The internal high-dimensional representation space in which model features and concepts are encoded. "personalization modules introduce non-orthogonal preference directions into the model’s latent space."
- Layer Selection: The process of identifying which internal model layer is most affected by personalization for targeted intervention. "Layer Selection"
- Logits: The unnormalized scores output by a model before applying a softmax to obtain probabilities. "For each layer , we extract logits corresponding to ground-truth answer tokens and compute the perplexity"
- LLM-as-a-Judge: An automated evaluation protocol where a LLM assesses responses for correctness. "we adopt an automated LLM-as-a-Judge evaluation protocol."
- Mixed adaptive control: An FPPS variant that combines soft steering for low risk and hard removal for high risk. "FPPS-H (hard gating), FPPS-S (soft bidirectional steering), and FPPS-M (mixed adaptive control)"
- Multi-hop QA: Question answering that requires reasoning across multiple pieces of evidence or steps. "a fact-centric multi-hop QA corpus (FactQA, built from HotpotQA and 2WikiMultiHopQA~\cite{yang2018hotpotqa,ho2020constructing})."
- Non-orthogonal preference direction: A personalization direction in latent space that overlaps with factual directions, causing entanglement. "personalization modules introduce non-orthogonal preference directions into the model’s latent space"
- P-Score: A metric measuring accuracy on personalized questions in the evaluation protocol. "We report three metrics: P-Score, measuring accuracy on personalized questions; F-Score, measuring factual accuracy under personalization; and Overall, defined as the average of P-Score and F-Score."
- Perplexity: A measure of a probability model’s uncertainty, commonly used to evaluate LLM predictions. "we extract logits corresponding to ground-truth answer tokens and compute the perplexity"
- Personalization-induced hallucinations: Factual errors caused by the model aligning with user history rather than objective truth. "producing personalization-induced hallucinations that reinforce user-specific misconceptions."
- Preference-optimized objectives: Training objectives designed to align model outputs with user preferences. "Personalized LLMs are commonly built through prompting-based personalization, lightweight model adaptation, and preference-optimized objectives"
- Profile-augmented methods: Personalization approaches that augment prompts with user profiles or traits. "covering two dominant personalization paradigms: profile-augmented and retrieval-augmented methods."
- Prompt-level personalization: Conditioning model behavior on user context inserted into prompts, rather than modifying model weights. "making prompt-level personalization the dominant paradigm due to its scalability and low deployment cost."
- Retrieval-augmented generation (RAG): A method that retrieves external documents to condition the model’s response generation. "personalization is implemented via the retrieval-augmented generation (RAG) strategy"
- Representation-level analysis: Examination of internal hidden states to understand model behavior beyond surface outputs. "This effect is empirically supported by representation-level analysis on factual question answering instances from PFQABench"
- Representation Shift Locator: A component that identifies layers where personalization most perturbs factual representations. "FPPS first uses a Representation Shift Locator (§\ref{sec:layer-selection}) to identify personalization-sensitive layers in the model where factual representations are most vulnerable."
- Representation shift: A change in hidden states induced by personalization that can alter downstream predictions. "We model personalization as inducing an implicit representation shift in the hidden state."
- Relative perplexity deviation: A derived measure comparing perplexities with and without personalization to quantify perturbation. "The relative perplexity deviation measures how strongly user history perturbs factual likelihoods."
- Risk threshold: A decision boundary determining when to switch from soft steering to hard suppression of personalization. "FPPS-M combines the strengths of FPPS-H and FPPS-S through a two-regime rule governed by a single risk threshold ."
- Soft bidirectional steering: A continuous adjustment that can either suppress or enhance personalization based on estimated risk. "FPPS-H (hard gating), FPPS-S (soft bidirectional steering), and FPPS-M (mixed adaptive control)"
- Steer vector: A vector direction used to push representations toward factual reasoning or personalization as needed. "To allow more fine-grained control, we construct a steer vector"
- Token embeddings: Vector representations of tokens used by the model for computation and reasoning. "final-layer response token embeddings generated without personalization to those generated with personalization."
- Uncertainty estimation: Techniques for quantifying confidence in model outputs to detect potential hallucinations. "Prior research has focused on detecting and mitigating such errors through factuality metrics, uncertainty estimation, internal-signal probing"
- User history length ratio: The proportion of retained user history injected into RAG prompts, used to study its effect on factuality. "we vary the history length ratio, i.e., the proportion of user history incorporated into the retrieval-augmented prompt"
Collections
Sign up for free to add this paper to one or more collections.