- The paper presents a novel autonomous adapter routing and expansion mechanism that prevents catastrophic forgetting in vision-language-action models.
- It leverages feature similarity and autoencoder discriminators to dynamically add lightweight adapters only when task-specific novelty is detected.
- Empirical results on the LIBERO benchmark demonstrate significant improvements in AUC and minimal parameter growth, ensuring effective continual learning.
Continual Expansion and Autonomous Routing for Lifelong Vision-Language-Action Models
Introduction and Motivation
The paper "CLARE: Continual Learning for Vision-Language-Action Models via Autonomous Adapter Routing and Expansion" (2601.09512) develops a parameter-efficient framework for continual learning of VLAs, addressing the critical challenge of catastrophic forgetting in sequential task adaptation, prevalent in real-world robotics settings. Conventional fine-tuning approaches for VLAs overwrite shared representations, resulting in significant performance degradation on previously learned tasks. Existing solutions—such as experience replay, regularization-based protection of important weights, and modular expansion—face limitations in terms of memory, scalability, and autonomy due to dependencies on oracle task identifiers or exemplar data.
CLARE circumvents these limitations by introducing a scheme that attaches lightweight adapters to selected feedforward layers and autonomously expands model capacity only when task-specific novelty is detected based on feature similarity. The approach leverages autoencoder discriminators that guide both expansion during continual learning and autonomous adapter routing during deployment. By freezing pre-existing parameters and fine-tuning only the newly added adapters, CLARE preserves earlier competencies while efficiently acquiring new ones.
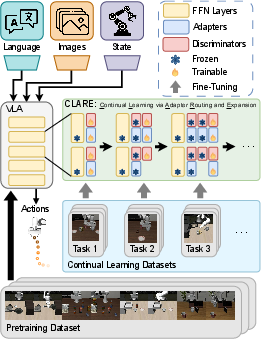
Figure 1: Autonomous adapter expansion and feature-driven routing in CLARE, preserving prior knowledge and focusing adaptation on necessary model regions.
Core Methodology
Base Policy and Generative Modeling
CLARE operates atop a pre-trained VLA policy, employing transformer-based generative architectures (DiT-EncDec and DiT-Dec) for robust imitation learning. The policy is trained with either a flow matching loss or denoising diffusion objectives, depending on the backbone variant, capturing the complex distributions from multimodal demonstration data. The system receives RGB images, proprioceptive states, and natural language instructions, outputting continuous action chunks over receding horizons.
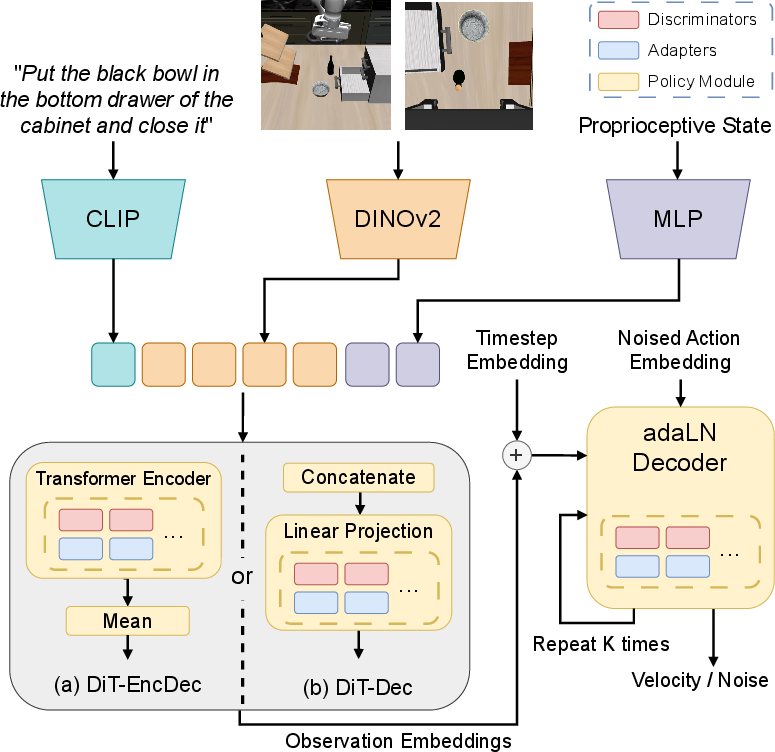
Figure 2: Two DiT-based backbone architectures and the potential insertion points for CLARE adapters; empirical evidence supports encoder-side expansion for optimal performance.
Modular Adapter Expansion
Mid-layer feedforward networks are designated as expandable modules, reflecting insights from large-scale transformers that critical knowledge is locally encoded in these blocks. At each learning stage, CLARE determines necessity for adapter addition via a dynamic expansion protocol, guided by statistical deviation (normalized z-score) of features associated with new tasks relative to those seen by existing discriminators.
A notable mechanism in CLARE is that new adapters are introduced only if all discriminators indicate the incoming data is out-of-distribution for previous tasks. Otherwise, new discriminators are added and linked to the most similar pre-existing adapter, supporting knowledge transfer and sublinear growth in parameter count.
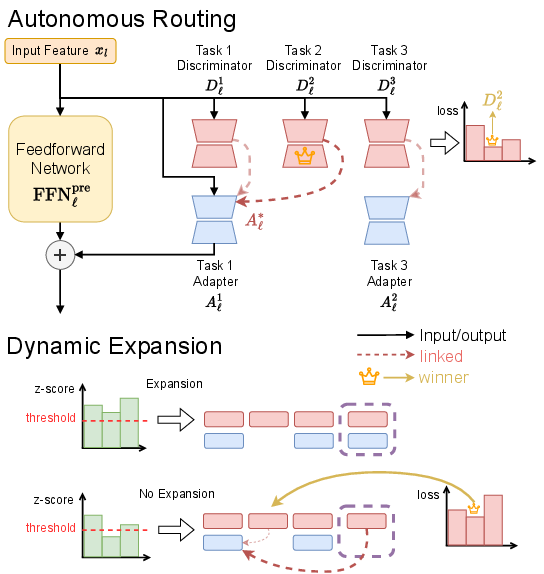
Figure 3: Dynamic, feature-driven adapter and discriminator integration in CLARE; expansion occurs conditionally on statistical feature novelty.
Autonomous Routing via Discriminators
During inference, CLARE casts routing as an unsupervised discriminative process: autoencoder discriminators, each associated with adapters, estimate reconstruction errors for incoming feature vectors. The adapter connected to the discriminator with the lowest error is selected per layer, supporting fully task-agnostic deployment—no external task labels or identifiers are required.
This autonomy is crucial for open-world robotic applications, where task boundaries are ambiguous and external supervision for task assignment is impractical.
Evaluation and Empirical Analysis
Experimental Protocol
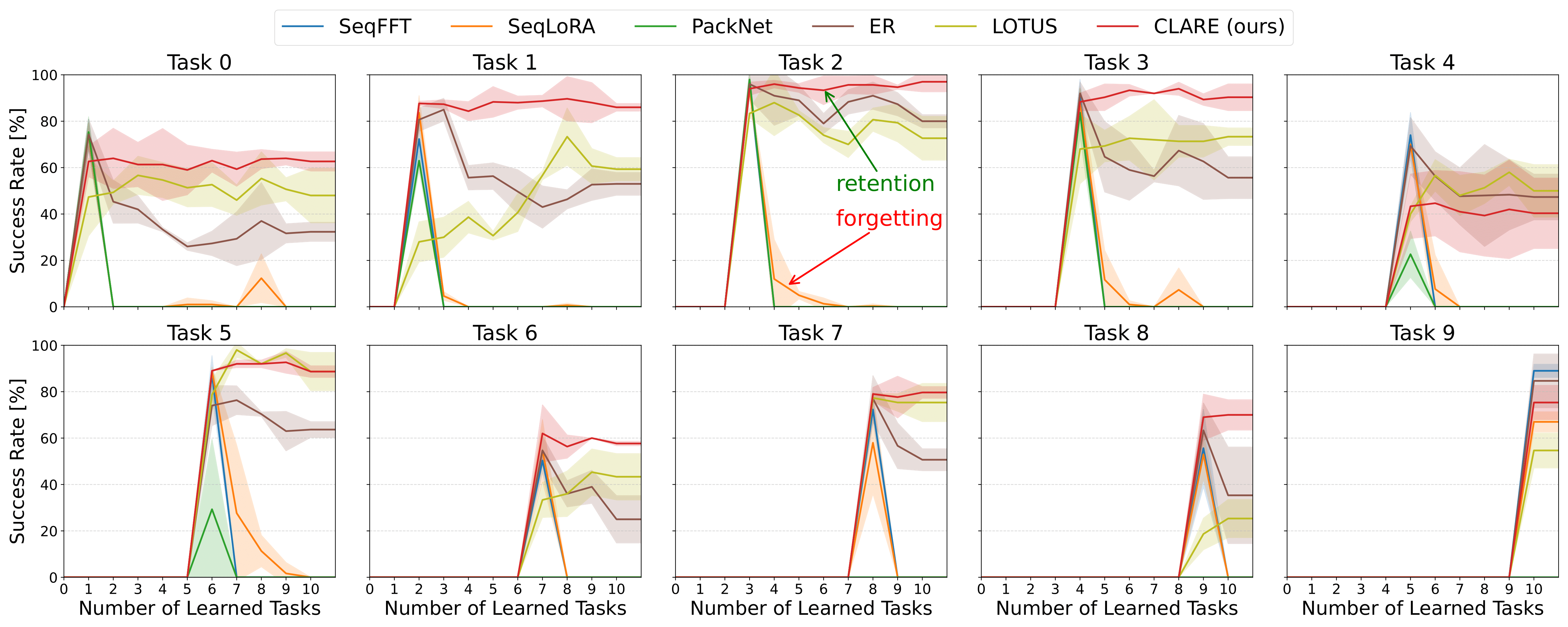
CLARE is evaluated on the LIBERO benchmark, which comprises challenging long-horizon manipulations requiring generalization over sequentially arriving tasks. Policies are pre-trained on 90 diverse short-horizon tasks and adapt continually to 10 novel long-horizon scenarios. Metrics include AUC (area under success rate curve), FWT (forward transfer), and NBT (negative backward transfer, lower is better). Task success rates are assessed via extensive rollouts across distinct initial configurations.
Layer Expansion Ablation
A systematic ablation study reveals that restricting adapter expansion to the encoder modules yields substantial improvements in AUC and FWT compared to decoder expansion—over 30% relative gain—across both architectural variants.
Baseline Comparisons
CLARE is rigorously benchmarked against sequential fine-tuning, LoRA-based adaptation, PackNet, experience replay (ER), and the LOTUS hierarchical skill library. Notably, LOTUS and ER benefit from privileged access to previous task data, whereas CLARE operates exemplar-free. Results demonstrate:
Dynamic Expansion Threshold
A thorough investigation into the expansion threshold γ demonstrates that increasing γ sharply curtails added adapters (from 60 to 16 in encoder layers) with only moderate AUC/FWT reduction, while NBT remains near zero. This points to a tunable trade-off between memory footprint and continual learning effectiveness.
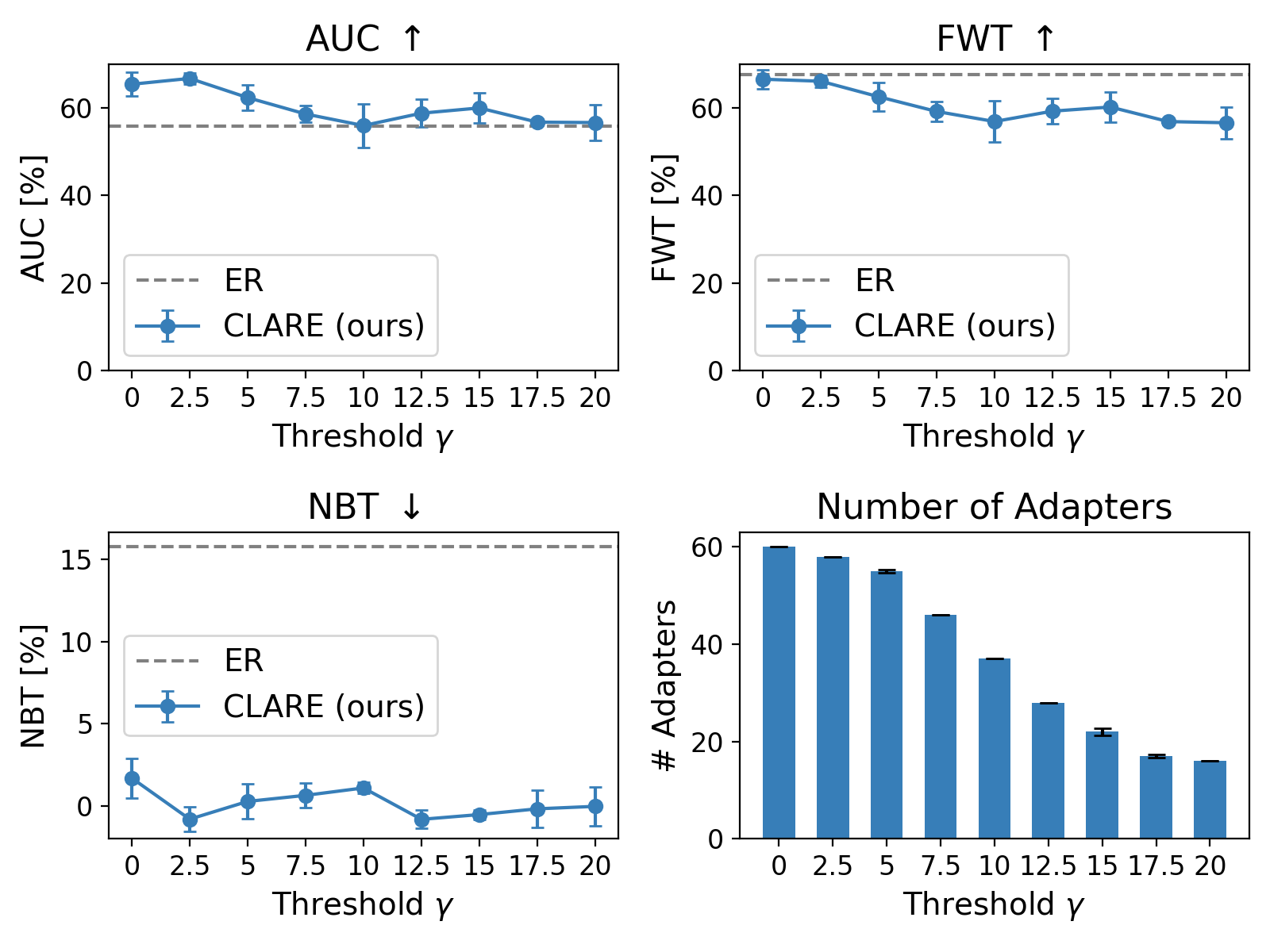
Figure 5: Adapter addition versus performance for varying expansion thresholds; aggressive reduction in adapters yields only mild task performance drop, but forgetting remains suppressed.
Practical and Theoretical Implications
CLARE offers a scalable solution for lifelong adaptation of foundation models in robotics, robustly mitigating catastrophic forgetting without relying on exemplars or extrinsic task labels. The framework's parameter efficiency opens the door for resource-constrained real-world deployment, where storage and compute are bottlenecks. The autonomous routing strategy is inherently compatible with multi-task and open-world scenarios, supporting flexible expansion and skill re-use.
Theoretically, CLARE advances modularity-driven continual learning by fusing discriminative routing, feature-similarity statistics, and dynamic sub-network growth, setting a foundation for scalable integration in next-generation VLAs as the field progresses toward more generalist, web-scale models.
Future Directions
Open avenues include scaling CLARE to larger architectures (hundreds of millions to billions of parameters), direct deployment on real-world hardware, and integration with multi-agent imitation learning setups. The discriminative routing paradigm may also be generalized beyond robotics to other sequential decision-making domains, and the adapter-expansion logic could inspire efficient lifelong learning mechanisms in multimodal foundation models broadly.
Conclusion
CLARE is a principled framework for continual learning in vision-language-action models, achieving robust adaptation and retention of prior knowledge via autonomous, feature-driven adapter routing and expansion. Its strong empirical results—achieved without relying on exemplar data or oracle task labels—highlight its suitability for lifelong, open-world robotic applications. The modular, parameter-efficient design positions CLARE as a practical and theoretically rich template for future advances in continual adaptation for embodied foundation models.