Semantic Gravity Wells: Why Negative Constraints Backfire
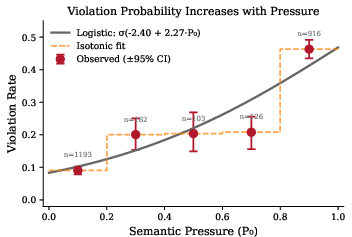
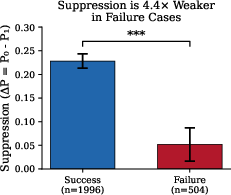
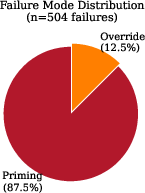
Abstract: Negative constraints (instructions of the form "do not use word X") represent a fundamental test of instruction-following capability in LLMs. Despite their apparent simplicity, these constraints fail with striking regularity, and the conditions governing failure have remained poorly understood. This paper presents the first comprehensive mechanistic investigation of negative instruction failure. We introduce semantic pressure, a quantitative measure of the model's intrinsic probability of generating the forbidden token, and demonstrate that violation probability follows a tight logistic relationship with pressure ($p=σ(-2.40+2.27\cdot P_0)$; $n=40{,}000$ samples; bootstrap $95%$ CI for slope: $[2.21,,2.33]$). Through layer-wise analysis using the logit lens technique, we establish that the suppression signal induced by negative instructions is present but systematically weaker in failures: the instruction reduces target probability by only 5.2 percentage points in failures versus 22.8 points in successes -- a $4.4\times$ asymmetry. We trace this asymmetry to two mechanistically distinct failure modes. In priming failure (87.5% of violations), the instruction's explicit mention of the forbidden word paradoxically activates rather than suppresses the target representation. In override failure (12.5%), late-layer feed-forward networks generate contributions of $+0.39$ toward the target probability -- nearly $4\times$ larger than in successes -- overwhelming earlier suppression signals. Activation patching confirms that layers 23--27 are causally responsible: replacing these layers' activations flips the sign of constraint effects. These findings reveal a fundamental tension in negative constraint design: the very act of naming a forbidden word primes the model to produce it.

Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Overview
This paper asks a simple but puzzling question: why do AI LLMs often do the one thing you ask them not to do? For example, if you say “Answer in one word, but do not say ‘Paris,’” the model still often replies “Paris.” The authors dig inside a real model’s inner workings to figure out why this happens and when it’s most likely. Their main idea is that there’s a tug-of-war inside the model: a strong pull toward the most obvious answer (like a gravity well) versus the push from the “don’t say it” warning. When the pull is stronger, the warning often fails.
Key Questions
Here are the main questions the paper tries to answer:
- When you tell a model “don’t say X,” how often does it still say X, and can we predict those failures?
- What inside the model causes these failures—does it ignore the warning, misunderstand “not,” or something else?
- Are there different kinds of failures, and can we tell them apart?
- What parts of the model’s “thinking steps” are responsible?
How They Studied It (Methods)
The researchers used a widely used open model (Qwen2.5-7B-Instruct) so they could look inside its layers. They built a big set of short questions where the most natural answer is one word (like “The capital of France is ____”). For each question, they tested two versions: a normal one and a “negative constraint” version that said “Do not use the word [X]”.
To keep ideas simple, here’s what they measured and how, using everyday analogies:
- Measuring “semantic pressure”: Think of this as how strongly the model “wants” to say a specific word before any warning. For example, in “The capital of France is ____,” the pull toward “Paris” is huge. The authors turned this into a number by checking how likely the model was to say the target word without any warning. That number is the pressure.
- Checking suppression: After adding the warning (“don’t say X”), they checked how much the model’s chance of saying X went down. If it goes down a lot, the warning is strong; if only a little, it’s weak.
- Peeking at layers with a “logit lens”: A LLM thinks in steps (layers). The logit lens is like peeking at half-baked thoughts after each step to see how likely the model is to choose the forbidden word at that point.
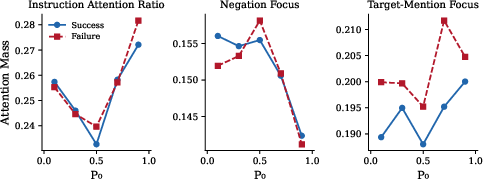
- Attention analysis: Attention is where the model “looks” in the prompt. They checked whether the model looks more at “do not” or at the word it’s not supposed to say. If the model stares at the forbidden word, that can backfire (like reverse psychology).
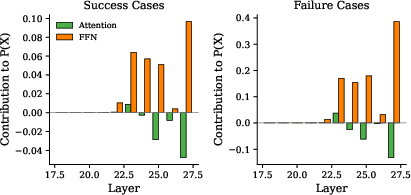
- Component breakdown: Each layer has two main parts: attention (routes information) and a feed-forward network (FFN), which acts like a small calculator that boosts some word choices. They measured which part pushes for or against the forbidden word.
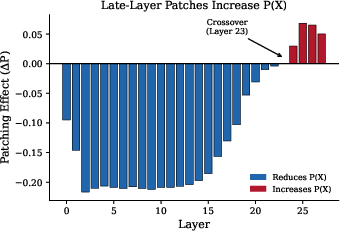
- Activation patching: Imagine copy-pasting the model’s internal state from one run into another. If replacing certain layers’ “thoughts” changes the outcome, those layers are causing the behavior. This shows cause, not just correlation.
They ran this for thousands of cases and looked at what patterns show up again and again.
Main Findings
Below is a short list of the key results, introduced in plain language:
- A simple rule predicts failure: The higher the semantic pressure (how strongly the model wants to say the word), the more likely it is to break the rule. This follows a neat S-shaped pattern: when the pressure is low, failures are rare; when it’s high, failures rise a lot (approaching about half of cases at the highest pressures). In other words, if “Paris” is the obvious answer, warnings often won’t stop the model.
- The warning works, but not enough in failures: The “don’t say it” instruction does lower the chance of saying the word in both successes and failures. But in failures, the push-away effect is about 4 times weaker than in successes. So the model hears the warning—it just can’t overcome the pull.
- Most failures are “priming” failures (about 88%): Mentioning the forbidden word (like “don’t say Paris”) actually makes the model focus on that word. Attention shows the model looks more at “Paris” than at “do not.” It’s like telling someone “don’t think about pink elephants”—you just made them think about pink elephants.
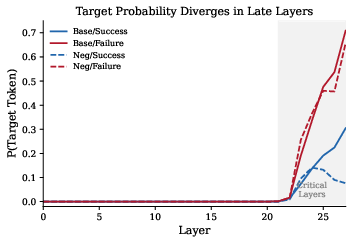
- The rest are “override” failures (about 12%): Here, the warning does push the model away from the word at first, but late in its thinking process, certain parts (the FFNs in later layers) give a strong last-minute shove toward the forbidden word and overpower the warning.
- The trouble lives in the late layers: Looking across the model’s steps, the forbidden word’s probability stays low early on, then shoots up in the last few steps. The FFN components in layers near the end (layers 23–27) add big boosts toward the forbidden word, especially in failures.
- Direct cause confirmed by activation patching: Swapping in the late-layer “thoughts” from an unconstrained run makes the constrained run more likely to break the rule. This shows those late layers are not just related—they help cause the violations.
A Simple Picture of What’s Going On
- There’s a gravity-like pull toward the obvious answer. That’s the semantic pressure.
- The warning is a push in the other direction.
- Naming the forbidden word creates a strong mental cue—so strong that it often cancels out the “do not” part.
- Even when the warning starts to work, late steps in the model’s process can override it, pushing the forbidden word back to the top.
The Two Failure Types
1) Priming Failure (most common)
- What it is: Saying “don’t say X” puts X in the model’s spotlight. The model fixates on X and ends up saying it.
- Why it happens: Attention focuses more on the word than on the “do not.” The warning backfires like reverse psychology.
2) Override Failure (less common)
- What it is: The warning reduces the chance of the forbidden word at first, but in the final steps, the model’s internal boosters (FFNs) push the forbidden word back up and overrule the warning.
- Why it happens: Late-layer “boosters” are stronger than the earlier “brakes.”
Why This Matters
- For users and developers: Don’t name the forbidden word if you can avoid it. For example, say “Answer without city names” instead of “Don’t say Paris.” Or reword the task so the model has other safe paths to follow.
- For tougher cases: When the obvious answer is exactly what you’re banning, the model is more likely to fail. In those cases, add extra safety checks after generation (like filters) instead of relying only on the warning.
- For model understanding: This study shows how to move from “the model messed up” to “here’s the internal reason why.” It connects behavior (breaking the rule) to mechanisms (attention focus, FFN boosts, late-layer overrides).
Limitations and Scope
- The study focuses on one strong open model and single-word answers in controlled settings. Bigger or different models, or longer and messier tasks, may have differences.
- Still, the core idea—naming a forbidden word often primes it, and late-layer boosts can override warnings—likely shows up in many models.
Takeaway
Negative instructions can backfire because they highlight the very word you want to avoid. When the model already “feels” a strong pull toward that word, a simple “don’t” often isn’t enough—especially since the model’s later thinking steps can boost that word back to the top. The fix is to design prompts that don’t prime the forbidden word, and to use extra checks when the obvious answer is exactly what must be avoided.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a single, concrete list of what remains missing, uncertain, or unexplored in the paper, framed so future researchers can act on each item.
- Cross-model generalization: Verify whether the pressure–violation logistic relationship and the two failure modes (priming vs. override) hold across model scales (e.g., 7B, 13B, 70B+), training regimes (RLHF variants, Constitutional AI), and architectures (Mixture-of-Experts, state-space models).
- Layer localization generality: Test if the late-layer locus of override (layers 23–27 in Qwen2.5-7B-Instruct) maps to analogous layer ranges in other models or is model-specific.
- Head-/neuron-level causality: Identify specific attention heads and FFN neurons responsible for priming and override via fine-grained patching/knockout (per-head, per-MLP neuron), causal scrubbing, and circuit tracing.
- Multi-token targets: Extend analysis from single-token targets to multi-token words and phrases (e.g., “New York”), measuring how sequential commitment affects priming and override dynamics.
- Category-level and semantic constraints: Evaluate negative constraints that forbid categories (e.g., “do not mention any cities”) or semantic sets, including how models represent and comply with set membership without explicitly naming targets.
- Alternative phrasing effectiveness: Systematically compare constraint formulations that avoid target naming (e.g., indirect reference, positive reframing, rhyming hints) on compliance, utility, and task success, across pressure regimes.
- Decoding interventions vs. instructions: Quantify how generation-time controls (logit bias/token bans, constrained decoding, grammar-guided decoding, beam vs. nucleus sampling) interact with or supersede negative instructions, especially under high semantic pressure.
- Post-generation filtering efficacy: Benchmark output filtering (regex/semantic filters, classifier gates) against instruction-based constraints on compliance, false positives/negatives, and latency for high-pressure cases.
- Pressure metric robustness: Assess how the semantic pressure varies across tokenizers, languages, casing/whitespace/punctuation conventions, and whether alternative pressure definitions (e.g., log-prob mass, normalized entropy) yield tighter or more general predictive fits.
- Dataset selection biases: Examine whether pressure gating and prompt construction (e.g., unique best answers, OOD prompts) introduce confounds that inflate the logistic fit; replicate on more naturalistic, noisy datasets.
- Long-form and interactive contexts: Move beyond one-word outputs to multi-sentence responses and multi-turn dialogues to test if priming and override persist, amplify, or attenuate with longer contexts and memory.
- Role and position of constraints: Measure how constraint location (system vs. user vs. assistant message), ordering (before/after the question), formatting (markdown/emphasis), and distance from the decision token affect compliance.
- Cross-lingual behavior: Evaluate negative constraints in non-English languages and multilingual models, including tokenization effects (e.g., character vs. subword) on priming and detection.
- Ambiguity and polysemy: Investigate cases where the forbidden token is a substring of other words, has multiple senses, or shares morphology with allowed tokens; refine detection to handle lemmatization and word-boundary edge cases.
- Attention causality: Move beyond attention-weight correlations by performing targeted interventions (e.g., attention head ablations, attention redirection) to establish whether negation-related heads are necessary/sufficient for suppression.
- FFN mechanism detail: Determine whether late-layer FFNs implement direct target-concept promotion, residual bypass, or interaction effects with attention; use techniques like ROME/MEMIT or neuron-level concept probing to edit or dampen target-specific activations.
- Training-time remedies: Test whether fine-tuning with curriculum-based negative-constraint data, adversarial examples, or regularizers (e.g., penalizing target activation when negation is present) reduces priming/override without degrading task utility.
- Safety-oriented constraints: Apply the analysis to safety-relevant forbidden content (e.g., self-harm methods, PII) to quantify whether the same mechanisms drive constraint failure and how to mitigate them in deployment.
- Real-time diagnostics: Develop and evaluate runtime indicators (e.g., Priming Index thresholds, layer-wise logit lens monitors) that predict impending constraint violation early enough to steer decoding away from the forbidden token.
- Temporal dynamics of priming: Test whether the timing/order of target mention versus negation (e.g., “do not say [X]” vs. “[X] is forbidden; do not say it”) modulates priming strength, and whether delayed mention or masked reference reduces activation.
- Confounders in logistic fit: Probe whether category differences, prompt naturalness, or baseline entropy drive the observed slope; fit multi-variable models to rule out spurious correlations and estimate causal contributions.
- Impact of sampling hyperparameters: Systematically vary temperature, top-p/top-k, and repetition penalties to map how decoding stochasticity alters violation rates under matched pressure.
- Compliance definition and detection: Strengthen violation detection for edge cases (compound words, hyphenation, capitalization variants, punctuation, diacritics), and report precision/recall of the detector against human annotations.
- Interaction with helpfulness priors: Test whether RLHF-style helpfulness incentives implicitly bias models to provide the “most useful” answer (the forbidden one) despite negation, and whether reward shaping can realign priorities.
- Memory/KV-cache effects: Investigate whether the inclusion of the forbidden token in the prompt (and its representation in the KV cache) directly facilitates later emission; explore cache editing or gating strategies to mitigate priming.
- Theoretical modeling of competition: Develop a formal model of semantic vs. constraint pressure (e.g., energy-based or probabilistic graphical interpretations) that predicts when suppression can overcome activation and guides principled intervention design.
- Scalability of patching: Evaluate the practicality, latency, and reliability of activation patching or steering in real-time systems, including robustness across inputs and resistance to distribution shift.
Practical Applications
Immediate Applications
The following applications can be deployed now using existing models, tooling, and the paper’s released code and datasets. Each item notes sectors, potential tools/workflows, and key assumptions.
- Prompt design patterns that avoid priming
- Sectors: customer support, education, marketing/brand safety, creative writing tools, policy/compliance teams
- What to do: replace “do not say X” with category-level constraints (“avoid city names”), positive reframing (“use general geographic terms”), or indirect references (“avoid the word that rhymes with …”), especially when semantic pressure for X is high
- Tools/workflows: prompt libraries/prompt linters that automatically rewrite negative constraints; integration into prompt templates in LangChain/LlamaIndex
- Assumptions/dependencies: effectiveness may vary by model; avoids explicit target naming (the dominant priming failure mode)
- Semantic pressure probe (pre-flight risk scoring)
- Sectors: LLMops, content moderation, enterprise AI platforms, safety engineering
- What to do: compute baseline probability P0 for candidate forbidden tokens before applying a constraint to predict violation risk using the reported logistic relationship; dynamically escalate safeguards when P0 is high
- Tools/workflows: a middleware microservice that does a baseline forward pass to estimate P0, tags requests with a “risk score,” and routes to different policies; integrates with orchestration frameworks
- Assumptions/dependencies: requires an extra forward pass; coefficients are model-specific (paper’s fit is for Qwen2.5-7B-Instruct); for closed models, approximate P0 using a shadow/open model
- Risk-adaptive guardrails and routing
- Sectors: healthcare (PHI), finance (MNPI/tickers), HR (bias-sensitive entities), social platforms (profanity/PII), legal
- What to do: if P0 exceeds a threshold, switch from generation-time constraints to stricter post-generation filters, human-in-the-loop review, or retrieval of safe paraphrases
- Tools/workflows: policy routers in inference pipelines; automated escalation paths; human review queues for high-risk prompts
- Assumptions/dependencies: organizational processes for escalation; tuned thresholds derived from validation on in-domain data
- Token-level decoding constraints/logit biasing where available
- Sectors: enterprise chat, brand safety, regulated domains
- What to do: at decode time, apply negative logit bias or hard masks to all tokenizations of the forbidden word (as enumerated by the paper’s tokenizer-aware S(X)) to counter late-layer FFN overrides
- Tools/workflows: use provider features (e.g., logit bias) or open-weight hooks to adjust logits; maintain an S(X) variant list from the paper’s method
- Assumptions/dependencies: requires API support for logit bias/masking or open-weight access; may reduce fluency if overused; multi-token spans need careful handling
- Post-generation filtering plus safe paraphrase rewrite
- Sectors: consumer apps, education, documentation tooling, safety-critical assistants
- What to do: detect violations with tokenizer-aware matching and either redact and paraphrase or regenerate with a rephrased constraint
- Tools/workflows: deterministic violation detector from the paper (case-insensitive, word-boundary aware) in an output filter; automatic paraphrase step that avoids explicit target mentions
- Assumptions/dependencies: small latency cost; must maintain full variant lists for detection; careful UX to avoid user confusion
- Negative-constraint compliance test suite in CI/CD
- Sectors: industry model providers, applied research labs, academic groups releasing models
- What to do: adopt the paper’s dataset and scoring pipeline as a regression test; track violation rates by pressure bins during model or policy updates
- Tools/workflows: continuous evaluation harness; dashboards showing violation curves vs. P0; release gating on maximum allowable violation rate at high pressure
- Assumptions/dependencies: tests reflect single-word settings; extend with domain-specific targets for better coverage
- Attention/Priming Index diagnostics for open-weight deployments
- Sectors: model hosting platforms, research engineering teams
- What to do: compute real-time Priming Index (attention to target mention minus negation cue) at the decision step to flag likely failures and trigger mitigation (e.g., rewrite or filtering)
- Tools/workflows: hooks to extract attentions at inference; alerting or automatic rerouting when PI > 0
- Assumptions/dependencies: requires internal access to attention weights; attention is a routing signal, not strictly causal—use as a heuristic
- UX and policy guidance updates
- Sectors: product management, trust & safety, policy/governance
- What to do: update internal style guides to discourage “don’t say X” prompts; require dual guardrails (pre-flight scoring + post-generation filters) for high-stakes use
- Tools/workflows: design guidelines; red-teaming checklists incorporating semantic pressure and priming risks
- Assumptions/dependencies: organizational adoption; cross-functional alignment
- Multi-agent “negation rewriter” pre-processor
- Sectors: developer tooling, assistants, agent frameworks
- What to do: insert a lightweight agent that rewrites user-provided negative constraints into safer, non-priming instructions before passing them to the main model
- Tools/workflows: agent graph in LangGraph or similar; cache successful rewrites by domain
- Assumptions/dependencies: small latency overhead; rewrite quality evaluation loop recommended
Long-Term Applications
These applications need further research, scaling, or engineering—especially to generalize beyond the studied model and to integrate at training/architecture levels.
- Training-time alignment against priming
- Sectors: model providers, safety research, academia
- What to pursue: contrastive finetuning where explicit target mentions should reliably suppress outputs; curriculum with high-P0 examples; loss terms penalizing emission under negative constraints
- Tools/workflows: curated datasets combining the paper’s task design with synthetic domain lists (PII, sensitive entities); RLHF signal focusing on constraint adherence
- Assumptions/dependencies: risk of capability-behavior trade-offs; needs cross-model validation
- Late-layer intervention and regularization
- Sectors: foundation model teams
- What to pursue: regularizers or edit techniques (ROME-like) targeting late-layer FFNs that drive overrides; learned gates that dampen contributions toward forbidden tokens when negation is present
- Tools/workflows: neuron/head-level patching pipelines; layer-wise loss shaping; causal tracing-guided finetuning
- Assumptions/dependencies: layer indices are model-specific (paper: layers 23–27 in Qwen2.5-7B); may affect other behaviors
- Architecture-level negation circuits
- Sectors: research on safer architectures
- What to pursue: explicit negation-aware modules (e.g., control tokens or adapters) that route away from named targets without naming them in the generation path; constraint memory buffers gating logits
- Tools/workflows: adapters/LoRA modules trained on negation tasks; control-vector injection at decode
- Assumptions/dependencies: requires careful generalization; potential latency/complexity costs
- Next-generation constrained decoding
- Sectors: model serving, search/assistant platforms
- What to pursue: lexically constrained decoding that guarantees exclusion while preserving fluency (e.g., improved constraint-aware beam search for subword tokenizations)
- Tools/workflows: decoding algorithms that account for multi-token variants S(X) and their prefixes; quality-preserving constraint heuristics
- Assumptions/dependencies: computational overhead; integration with streaming outputs
- Cross-model benchmarks and certification
- Sectors: standards bodies, regulators, enterprise procurement
- What to pursue: a “Negative Constraint Compliance” benchmark and certification (report violation curves vs. P0, suppression asymmetry, priming/override rates)
- Tools/workflows: public leaderboard; audit protocols; sector-specific target lists (PHI, finance tickers, protected attributes)
- Assumptions/dependencies: community adoption; domain coverage; governance for updates
- Model-agnostic proxies for internal diagnostics
- Sectors: users of closed-source APIs
- What to pursue: external proxies for semantic pressure (shadow models, n-best lists), priming risk (prompt features), and override likelihood; meta-models predicting failure from observable signals
- Tools/workflows: telemetry collection; prompt feature extractors; calibration to each API/model version
- Assumptions/dependencies: proxy quality depends on domain alignment; needs periodic recalibration
- Robust PHI/PII leak prevention pipelines
- Sectors: healthcare, finance, government
- What to pursue: end-to-end systems that combine P0-based pre-flight risk scoring, constrained decoding, and high-precision redaction/paraphrase, with audit logs tied to pressure bins
- Tools/workflows: policy engines; audit dashboards; incident response workflows
- Assumptions/dependencies: domain-specific lexicons; strict latency budgets; legal/compliance sign-off
- Developer tools for “pressure-aware” design
- Sectors: IDEs, prompt engineering platforms
- What to pursue: “pressure heatmaps” and prompt lints that visualize risky spans and suggest rewrites; auto-generation of safe alternatives
- Tools/workflows: editor plugins; CI comments on pull requests for prompts; A/B evaluation harnesses
- Assumptions/dependencies: needs fast approximate P0; integration with team workflows
- Fine-grained causal interpretability toolkits
- Sectors: research, model interpretability vendors
- What to pursue: head/neuron-level patching libraries that automate localization of negation and target-activation circuits across models; reproducible pipelines like in the paper
- Tools/workflows: standardized activation-patching APIs; dataset suites spanning domains; visualization of component contributions
- Assumptions/dependencies: open weights or cooperative vendor instrumentation; compute budget for causal experiments
- Policy templates acknowledging negation risk
- Sectors: regulators, enterprise governance
- What to pursue: guidance that discourages reliance on negative constraints alone; requires multi-layer guardrails and performance reporting by pressure regime
- Tools/workflows: procurement checklists; compliance attestations; incident reporting formats tied to violation metrics
- Assumptions/dependencies: coordination across stakeholders; harmonization with existing AI risk frameworks (e.g., NIST AI RMF)
Notes on feasibility and dependencies across applications:
- Model specificity: The logistic failure curve, layer indices, and contribution magnitudes were measured on Qwen2.5-7B-Instruct; replication and recalibration are needed for other models and sizes.
- Access constraints: Internal diagnostics (attention, activation patching) and late-layer interventions require open weights or vendor support; closed-model users can rely on proxies and post-generation guardrails.
- Tokenization variance: All token-level methods must enumerate S(X) variants for the specific tokenizer to avoid misses.
- Latency/compute: Pre-flight P0 estimation and post-generation filtering add overhead; apply adaptively based on risk.
- Multi-token and long-form outputs: The paper focuses on single-word targets; real-world constraints often span multiple tokens and longer contexts—tooling should extend to multi-token sequences and streaming behavior.
Glossary
- Activation patching: A causal interpretability technique that replaces intermediate activations to test which components drive a behavior. "Activation patching confirms that layers 23--27 are causally responsible: replacing these layers' activations flips the sign of constraint effects."
- Attention analysis: Inspection of attention patterns to determine what parts of the input the model focuses on. "Using attention analysis, we find that 87.5% of failures exhibit a 'priming signature'"
- Bootstrap 95% CI: A confidence interval estimated via bootstrap resampling to quantify uncertainty. "bootstrap 95% CI for slope: [2.21, 2.33]"
- Byte Pair Encoding (BPE) tokenizer: A subword tokenization method that splits text into frequent byte-pair units. "Whitespace: with/without leading space (per BPE tokenizer behavior)"
- Causal interventions: Experimental manipulations that establish whether a component is necessary or sufficient for a behavior. "Activation patching \citep{meng2022locating, wang2023interpretability} enables causal interventions that establish which components are necessary or sufficient for particular behaviors."
- Feed-forward network (FFN): The transformer sublayer (MLP) that transforms token representations independently to promote certain outputs. "Feed-forward networks in layers 23--27 generate strong positive contributions toward the forbidden token— +0.39 in failures versus +0.10 in successes at layer 27 alone."
- Head-level patching: A fine-grained causal method that patches individual attention heads to localize functional roles. "Head-level patching: Which specific attention heads process negation versus target activation?"
- Instruction Attention Ratio (IAR): The fraction of attention allocated to instruction tokens versus the question tokens. "Instruction Attention Ratio (IAR): Fraction of attention to instruction tokens (vs. question tokens)"
- Instruction-tuned model: A LLM fine-tuned to follow natural-language instructions. "Qwen2.5-7B-Instruct, a 7-billion parameter instruction-tuned model with 28 transformer layers."
- KV-caching: Storing key/value attention states to efficiently compute probabilities under teacher forcing. "Probability computed via teacher-forced forward pass with KV-caching."
- Logistic regression: A model that predicts probabilities via a logistic (sigmoid) link applied to a linear combination of features. "Fitting a logistic regression: p(violation) = σ(β0 + β1 * P0)"
- Logit lens: A technique that projects hidden states through the unembedding matrix to inspect token probabilities at intermediate layers. "The 'logit lens' \citep{nostalgebraist2020logitlens} and related techniques \citep{geva2022transformer} allow inspection of intermediate probability estimates by projecting hidden states through the unembedding matrix."
- Mixture of Experts: An architecture that routes inputs to specialized expert subnetworks. "Different architectures (Mixture of Experts, state-space models)"
- Multi-head self-attention: The transformer mechanism that computes attention in multiple parallel heads over the input. "Each transformer layer consists of two main components: multi-head self-attention and a feed-forward network (FFN)."
- Negation Focus (NF): The share of attention directed to the negation cue within the instruction. "Negation Focus (NF): Within instruction, attention to 'do not'"
- Out-of-distribution (OOD): Inputs that differ substantially from the training distribution. "Out-of-distribution (): Surreal or counterfactual prompts spanning the full pressure spectrum."
- Pressure gating: Filtering prompts by a minimum baseline probability threshold to ensure sufficient semantic pressure. "We apply pressure gating () to ensure sufficient baseline probability and bin balancing to cover the full pressure range."
- Priming Index (PI): A metric defined as TMF − NF indicating whether the instruction’s target mention receives more attention than the negation. "Priming Index (PI): TMF - NF—positive values indicate more attention to the target mention than to the negation"
- Reinforcement Learning from Human Feedback (RLHF): A training paradigm where models are optimized using human preference signals. "Different training procedures (RLHF variants, Constitutional AI)"
- Residual stream: The running representation in the transformer updated via residual connections at each layer. "cache the residual stream at each layer."
- Semantic pressure: The model’s baseline probability of producing the target word absent any constraint. "We introduce semantic pressure, a quantitative measure of the model's intrinsic probability of generating the forbidden token"
- Sigmoid (σ): The logistic function mapping real-valued scores to probabilities. "p(\text{violation}) = \sigma(\beta_0 + \beta_1 \cdot P_0)"
- State-space models: Sequence models based on continuous state dynamics rather than attention. "Different architectures (Mixture of Experts, state-space models)"
- Target-Mention Focus (TMF): The attention directed to the position where the target word is mentioned in the instruction. "Target-Mention Focus (TMF): Within instruction, attention to where appears"
- Teacher-forced forward pass: A procedure that feeds the model the true tokens to compute exact sequence probabilities. "Probability computed via teacher-forced forward pass with KV-caching."
- Top-p sampling: Nucleus sampling that draws from the smallest set of tokens whose cumulative probability exceeds p. "temperature 1.0, top- 0.9"
- Unembedding matrix: The matrix that maps hidden states to vocabulary logits for decoding. "by projecting hidden states through the unembedding matrix."
Collections
Sign up for free to add this paper to one or more collections.