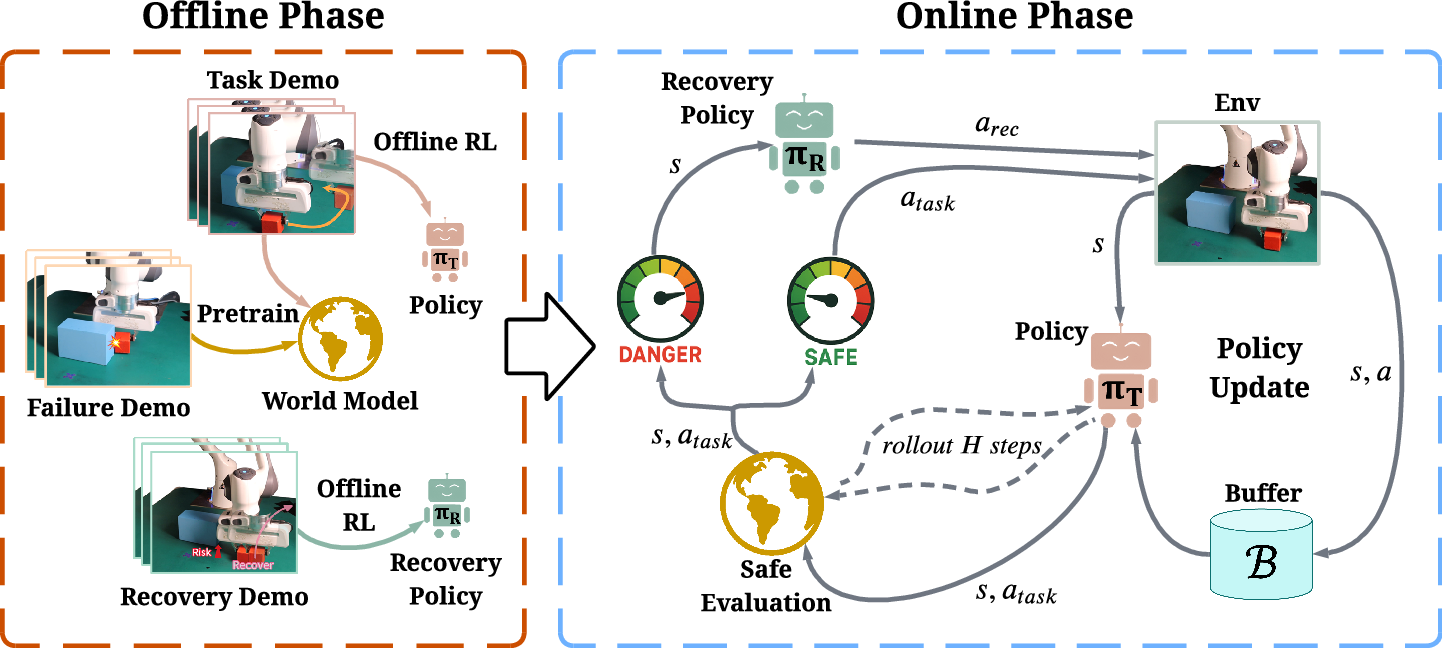
Failure-Aware RL: Reliable Offline-to-Online Reinforcement Learning with Self-Recovery for Real-World Manipulation
Abstract: Post-training algorithms based on deep reinforcement learning can push the limits of robotic models for specific objectives, such as generalizability, accuracy, and robustness. However, Intervention-requiring Failures (IR Failures) (e.g., a robot spilling water or breaking fragile glass) during real-world exploration happen inevitably, hindering the practical deployment of such a paradigm. To tackle this, we introduce Failure-Aware Offline-to-Online Reinforcement Learning (FARL), a new paradigm minimizing failures during real-world reinforcement learning. We create FailureBench, a benchmark that incorporates common failure scenarios requiring human intervention, and propose an algorithm that integrates a world-model-based safety critic and a recovery policy trained offline to prevent failures during online exploration. Extensive simulation and real-world experiments demonstrate the effectiveness of FARL in significantly reducing IR Failures while improving performance and generalization during online reinforcement learning post-training. FARL reduces IR Failures by 73.1% while elevating performance by 11.3% on average during real-world RL post-training. Videos and code are available at https://failure-aware-rl.github.io.

Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What’s this paper about?
This paper is about teaching robots to learn new skills safely. The authors show a way to let a robot keep improving its abilities without causing accidents like knocking things off a table, breaking fragile objects, or getting stuck—situations that usually need a human to step in. Their approach is called Failure-Aware RL (FARL), and it helps robots learn while avoiding dangerous or costly mistakes.
What questions are the researchers trying to answer?
The paper asks simple, practical questions:
- How can a robot keep getting better at a task without making risky moves that cause damage or interruptions?
- Can we predict when a robot is about to do something unsafe and stop it in time?
- If a robot is about to fail, can it switch to a safer plan to recover?
- Do these ideas work not just in simulation, but also on a real robot?
How did they do it? (Methods explained simply)
Think of a robot learning a task like a kid learning soccer:
- First, the kid watches demonstrations (offline learning).
- Then, they practice and refine their skills by trying things on the field (online learning).
- But trying new moves can sometimes lead to mistakes.
To make this safer, FARL uses three parts trained from recorded examples (demonstrations):
- Task Policy: This is the robot’s main “playbook” for how to do the task correctly.
- Recovery Policy: This is a “backup plan” the robot uses to avoid or escape trouble. It’s trained from examples that show how to get back to safety.
- World Model (Safety Critic): This is like the robot’s “mental simulator” and “danger detector.” Before the robot acts, it quickly predicts what is likely to happen in the next few steps and whether that might cause a failure.
Here’s how it works during practice (online fine-tuning):
- The robot picks an action from the task policy.
- The world model checks if this action might lead to a failure soon (like pushing a ball out of bounds).
- If it looks risky, the robot switches to the recovery policy to do something safer instead.
- The robot still keeps learning and improving, but it avoids actions that would cause trouble.
To test these ideas, the authors also built a simulation benchmark called FailureBench with realistic failure cases—like pushing objects out of the workspace, hitting walls, or colliding with obstacles—so they can measure both learning and safety.
What did they find, and why does it matter?
The researchers ran many experiments in simulation and on a real Franka Panda robot arm. They tested tasks like:
- Pushing fragile objects without hitting a wall,
- Pushing while avoiding moving obstacles,
- Playing “robot soccer” while keeping the ball within boundaries.
Key results:
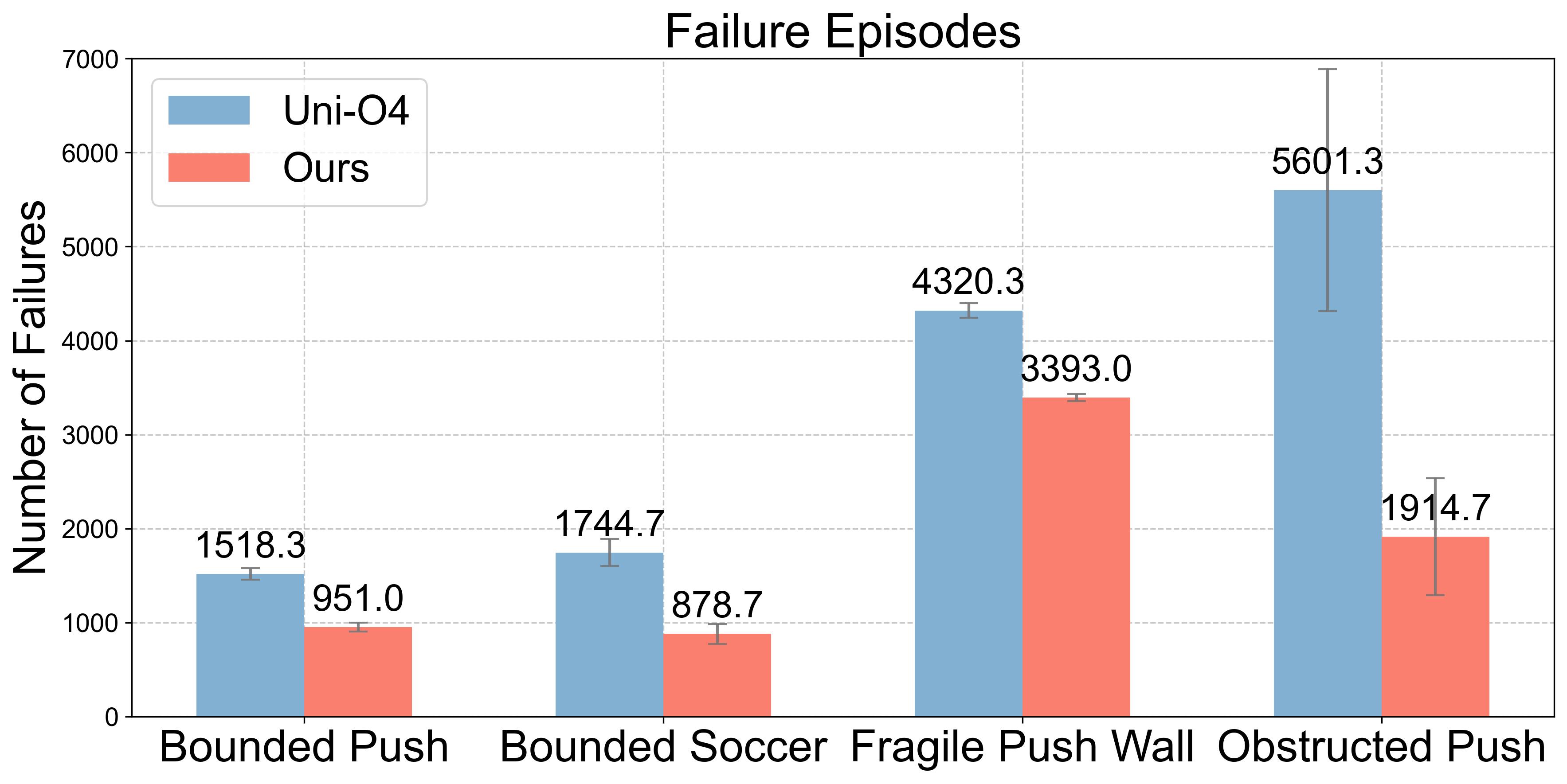
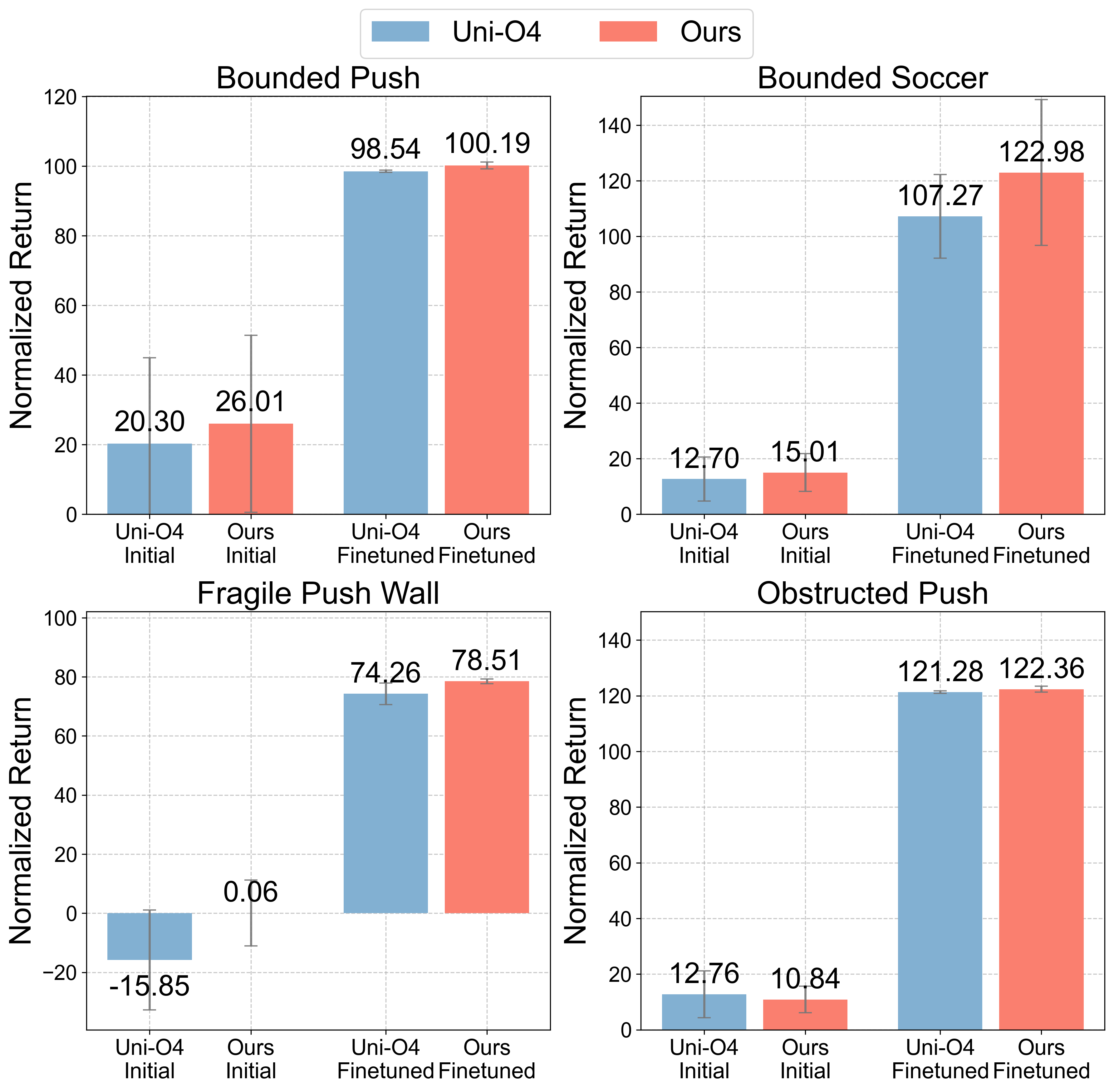
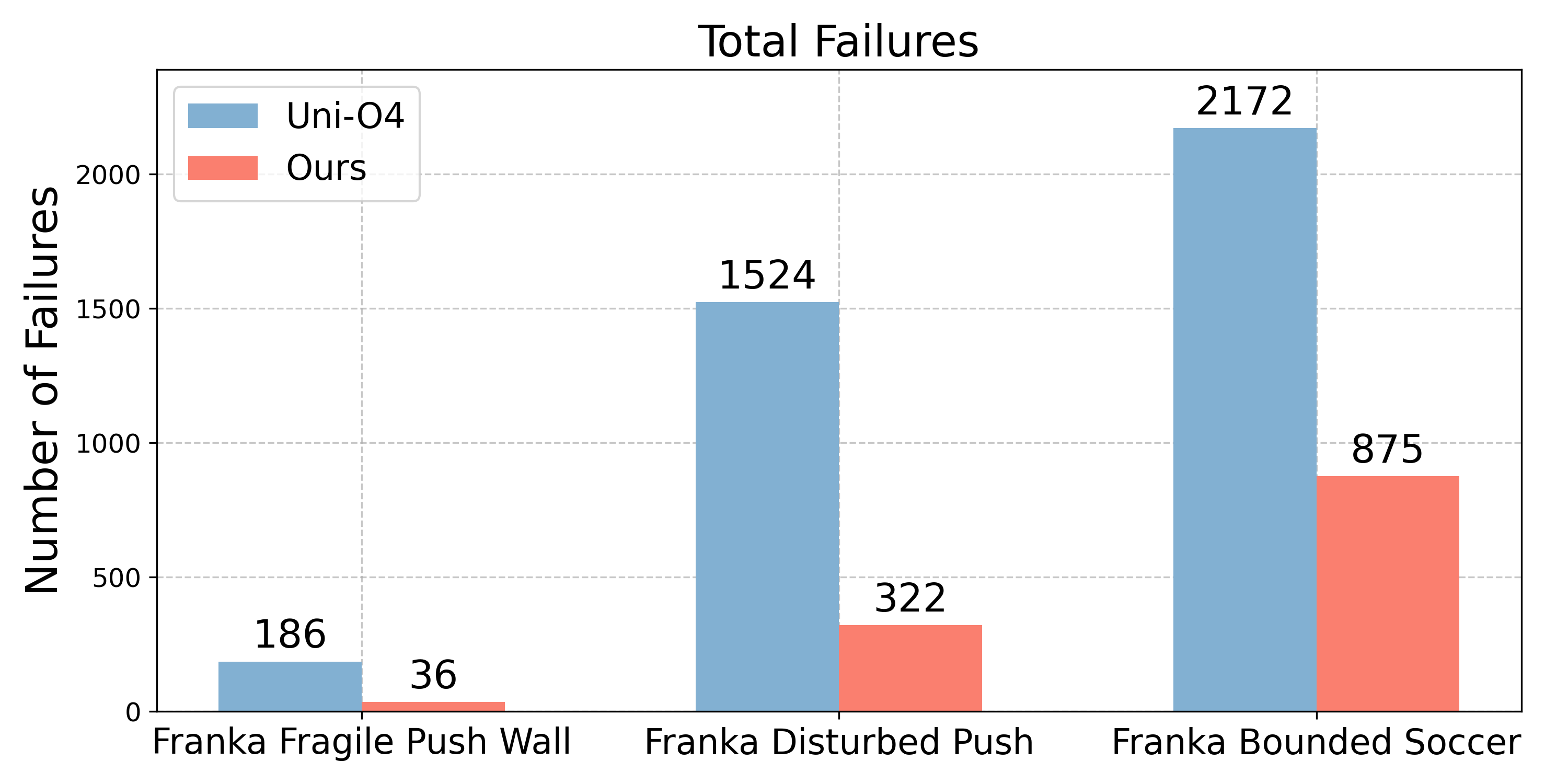
- FARL greatly reduced the number of failures in both simulation and real-world tests.
- In real robot training, FARL cut failures by about 73% and improved performance (task success) by about 11% on average.
- Even with safety checks, the robot still learned effectively and often did better than standard methods.
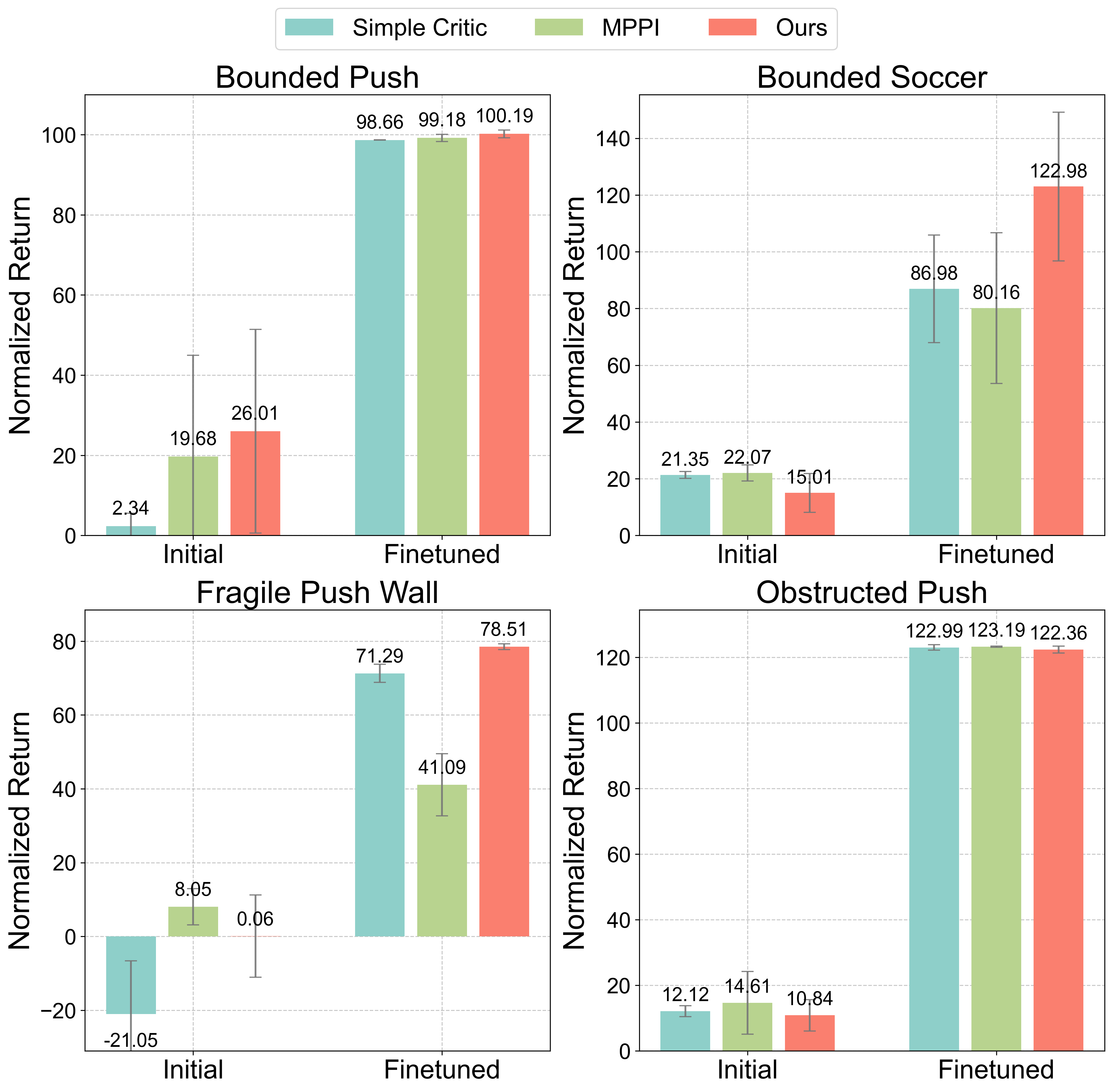
- Traditional “safe RL” methods (designed for learning from scratch) didn’t work well when starting from pre-trained policies. FARL’s design—predicting risk ahead of time and using a recovery plan—worked much better.
Why it matters:
- Fewer failures mean less time humans need to reset tasks or replace broken items.
- Safer learning makes it more practical to use RL in real homes, factories, or labs.
- Robots can keep improving without causing expensive or dangerous mistakes.
What does this mean for the future?
This approach helps make robot learning safer and more reliable. It could:
- Speed up the adoption of learning-based robots in the real world.
- Reduce costs and downtime by avoiding damage and interruptions.
- Make it easier to fine-tune robots for new tasks without constant human oversight.
The authors suggest future steps like:
- Using richer sensors (better vision, 3D cameras, touch) to improve safety predictions,
- Extending to mobile robots or multi-arm systems,
- Training large “failure world models” that generalize across many tasks and robots, so safety works even in new situations.
Overall, FARL shows that robots can keep learning while staying careful—just like a smart player who improves their game without taking reckless risks.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a concise list of what remains missing, uncertain, or unexplored in the paper, framed to guide actionable follow-up research:
- Absent formal safety guarantees under model error: the world-model-based safety critic only predicts near-future risk without certified guarantees. How to provide provable safety (e.g., via control barrier functions, reachability analysis, or certified MPC) and quantify worst-case violation probabilities when the model is misspecified?
- No uncertainty-aware risk estimation: failure predictions are point estimates. How to incorporate and calibrate epistemic/aleatoric uncertainty (ensembles, MC dropout, evidential networks, conformal prediction) and make decisions that are robust to uncertainty inflation near distributional shift?
- Fixed short planning horizon H with no sensitivity analysis: the method assumes near-future planning suffices but does not study how H and γrisk affect safety/performance. What is the trade-off curve and can H be adaptively scheduled based on predicted uncertainty or task phase?
- Threshold selection and calibration: εsafe is chosen but not calibrated or stress-tested. How to systematically choose εsafe (e.g., via ROC/PR analysis, risk budgets, conformal calibration) and adapt it online as confidence changes?
- Frozen world model and recovery policy during online learning: both are trained offline and not updated, risking distribution shift as the task policy evolves. Can safe data aggregation (DAgger-style), selective online fine-tuning with shields, or human-verified updates keep the safety critic and recovery controller aligned with the evolving state distribution?
- Reliance on curated recovery/failure demonstrations: coverage gaps and collection burden (and potential bias) are not quantified. What is the minimum dataset size/coverage needed for target safety levels? Can planning, generative augmentation, or intervention learning reduce human effort while expanding recovery coverage?
- No treatment of model calibration and compounding rollout error: the latent dynamics are used for multi-step constraint prediction without assessing calibration drift across rollout length. How to detect and correct compounding error (e.g., via consistency checks, hindsight relabeling, or rollout ensembles)?
- On-policy learning with mixed actions may bias PPO updates: substituting recovery actions alters the on-policy distribution. What off-policy corrections or importance weighting are needed to ensure unbiased policy gradient estimates and stable convergence?
- Theoretical assumptions unverified empirically: key assumptions (high-probability safe recovery, safe-action advantage gap δ) are not measured. How often do they hold in practice, and how do εrec and δ evolve during training and across tasks?
- Binary constraint modeling only: failures are treated as 0/1 events. Can graded risk costs, multiple simultaneous constraints, or risk-sensitive objectives (CVaR, chance constraints) yield better safety–performance trade-offs?
- Limited task diversity and realism in FailureBench: tasks are push-centric in MetaWorld variants. How does FARL perform on grasping, tool use, deformable objects, contact-rich manipulation, long-horizon assembly, mobile manipulation, and multi-arm settings?
- Sim-to-real generalization unquantified: the paper doesn’t measure transfer from FailureBench to real robots. How to reduce the gap (domain randomization/adaptation) and evaluate zero-shot transfer of the safety critic?
- Sparse and short real-world evaluation: 50 episodes per task at ≈5 Hz with simple perception. How does the approach scale to longer deployments, higher control rates, faster/dynamic hazards, and occlusions? What are latency budgets and worst-case reaction times?
- No explicit measurement of human reset time/cost: the study counts failure events but not the actual intervention burden. Can future evaluations report human time saved, episode downtime, and total training wall-clock reductions?
- Limited perception robustness: YOLOv8 + color filtering without uncertainty propagation or failure detection in perception. How to handle noisy/occluded sensing and propagate state-estimation uncertainty into safety decisions?
- No emergency fallback/shield if the model mispredicts: what is the plan for false negatives from the safety critic? Can a last-resort safety layer (CBF/PID stop/shielded action set) provide hard bounds on risk?
- Baseline coverage gaps: comparisons exclude predictive safety filters, shielded learning, control barrier function methods, and recent model-based safe RL (e.g., SafeDreamer) in offline-to-online settings. How do these methods fare under identical pretraining and real-robot constraints?
- Architectural ablations missing: the contribution of each world-model head (reward, value, constraint, decoder), latent size, and backbone choice (e.g., transformers) isn’t isolated. Which components most improve failure prediction and transfer?
- Adaptive gating strategy: safety gating is binary and static. Could graded action blending, risk-aware KL constraints, or curriculum-based relaxation better balance exploration and safety over time?
- Generalization to unseen failure modes and embodiments: safety critic is trained on task-specific failures. Can large-scale pretraining across tasks/robots enable zero-shot or few-shot detection of novel failure modes?
- Handling non-stationarity and adversarial disturbances: dynamic obstacles are simple and human-driven. How robust is FARL under non-stationary dynamics, adversarial perturbations, or hardware degradation? Can online change-point detection trigger safety recalibration?
- Resource and compute constraints: world-model inference at 5 Hz is feasible here but may be limiting. What optimizations (model compression, hardware acceleration) are needed for higher-rate control and more complex perception?
- Formal CMDP problem definition clarity: the paper’s equations have typographical inconsistencies and omit details about cost definition, discounting, and horizon choices. Providing a precise, reproducible CMDP specification for each task would improve comparability and adoption.
- FailureBench standardization and metrics: failure annotations, constraint definitions, and evaluation protocols could be further standardized. Can the benchmark include unified APIs for constraints, calibrated risk metrics, and human-intervention cost reporting?
Glossary
- ABS: A safe RL method that predicts constraint violations and uses recovery policies to prevent unsafe states. "Recovery RL~\cite{thananjeyan2021recovery} and ABS~\cite{he2024agile} predict constraint violations and employ recovery policies to avoid unsafe states before failures occur."
- Advantage correction: An analytical mechanism to justify performance and safety gains by adjusting how advantages are treated during learning. "We propose a failure-aware offline-to-online framework, including a specifically designed world model and recovery policy to minimize \failures while facilitating learning and adaptation with RL, theoretically justified by an ``advantage correction'' analysis to simultaneously enhance learning and safety."
- Advantage function: In RL, a measure of how much better an action is compared to the policy’s baseline at a given state. "and is the advantage function."
- Behavior cloning: Supervised learning to imitate expert demonstrations to initialize a policy. "Initially, the policy undergoes behavior cloning, followed by fine-tuning using the objective:"
- Constrained Markov Decision Processes (CMDPs): MDPs augmented with constraints (e.g., safety/risk), used to formalize safe RL. "We consider RL-based post-training under Constrained Markov Decision Processes (CMDPs)~\cite{altman2021constrained}."
- Control Barrier Functions (CBFs): Control-theoretic tools ensuring a system remains within a safe set via forward invariance. "Control Barrier Functions~\cite{cbf} that ensure forward invariance of safe sets, and predictive safety filters~\cite{wabersich2021predictive} that use MPC to modify unsafe control inputs."
- Distributional shift: Mismatch between training data distribution and the distribution encountered during deployment or exploration. "Offline RL aims to address distributional shift issues that arise when a policy encounters out-of-distribution (OOD) state-action pairs."
- DreamerV3: A model-based RL framework used for planning; referenced within safe RL integration. "SafeDreamer~\cite{huang2024safedreamer} integrates Lagrangian methods into the DreamerV3 planning process for model-based safe RL."
- Failure-Aware Offline-to-Online Reinforcement Learning (FARL): The proposed paradigm that minimizes failures during real-world RL fine-tuning. "Failure-Aware Offline-to-Online Reinforcement Learning~(FARL), a new paradigm minimizing failures during real-world reinforcement learning."
- FailureBench: A simulation benchmark suite for evaluating failure-aware RL under intervention-requiring scenarios. "To study various failure scenarios in simulation environments, we introduce a new benchmark, FailureBench."
- Forward invariance: Property that once within a safe set, trajectories remain in the safe set indefinitely. "Control Barrier Functions~\cite{cbf} that ensure forward invariance of safe sets"
- Generalized Advantage Estimation (GAE): A variance-reduction technique for estimating advantages in policy gradient methods. "using GAE advantage estimation."
- Hierarchical safe RL: Safe RL approaches that use hierarchical structures or dynamics to ensure safety. "Alternative approaches include hierarchical safe RL~\cite{dalal2018safe, xiao2024safe}, which utilizes structural dynamics, and methods incorporating safety certificates from control theory~\cite{cheng2019end, 2020arXiv200504374N}."
- Importance sampling ratio: The probability ratio between target and behavior policies used in PPO’s clipped objective. "r(\pi)=\frac{\pi\left(a|s\right)}{\pi_k\left(a|s\right)} denotes the importance sampling ratio between the target policy and behavior policy "
- Lagrangian relaxation: A constrained optimization technique that moves constraints into the objective via Lagrange multipliers. "such as Lagrangian relaxation~\cite{liang2018accelerated, tansehoon, lg1}, Lyapunov functions~\cite{chow2018lyapunov, chow2019lyapunov} and robustness guarantees~\cite{liang2022efficient, liu2022robustness, liang2024gametheoretic, liu2024beyond}."
- Latent dynamics: Learned transition dynamics in a latent state space of a world model. "Latent dynamics: \quad \mathbf{z}{t+1} = d{\theta}\left(\mathbf{z}{t}, \mathbf{a}{t}\right)"
- Latent world model: A learned model in latent space that predicts future states, rewards, and constraints for planning and safety. "a safety critic based on a latent world model for failure prediction"
- Lyapunov functions: Functions used to assess and guarantee system stability and safety. "such as Lagrangian relaxation~\cite{liang2018accelerated, tansehoon, lg1}, Lyapunov functions~\cite{chow2018lyapunov, chow2019lyapunov} and robustness guarantees~\cite{liang2022efficient, liu2022robustness, liang2024gametheoretic, liu2024beyond}."
- Model Predictive Control (MPC): A control approach that solves an optimization over a future horizon to choose current actions. "predictive safety filters~\cite{wabersich2021predictive} that use MPC to modify unsafe control inputs."
- Model Predictive Path Integral (MPPI): A sampling-based MPC method that chooses actions by evaluating sampled trajectories via a model. "Model Predictive Path Integral (MPPI)~\cite{williams2015modelpredictivepathintegral}, a sampling-based model predictive control method."
- Offline RL: Learning policies solely from static datasets without further environment interaction. "Offline RL aims to address distributional shift issues that arise when a policy encounters out-of-distribution (OOD) state-action pairs."
- Offline-to-online RL: Pre-training policies offline on demonstrations followed by online fine-tuning. "Specifically, offline-to-online RL~\cite{CQL, iql, lei2024unio}, where the agent is first trained offline on demonstrations and then fine-tuned through online RL"
- On-policy: RL methods that update using data generated by the current policy being optimized. "unify online and offline RL in an on-policy manner."
- Out-of-distribution (OOD): Data points (state-action pairs) not represented in the training dataset’s distribution. "out-of-distribution (OOD) state-action pairs."
- P3O: A safe RL algorithm used for constrained policy optimization and safety. "Additionally, we compare our method with three state-of-the-art online safe RL algorithms, i.e., PPO-Lagrangian~\cite{ray2019benchmarking}, P3O~\cite{p3o}, and CPO~\cite{cpo}, where each is used to fine-tune the same offline pre-trained policy."
- Predictive safety filters: Methods that modify or filter proposed control inputs to avoid constraint violations. "predictive safety filters~\cite{wabersich2021predictive} that use MPC to modify unsafe control inputs."
- PPO-Lagrangian: A variant of PPO that incorporates Lagrangian methods to handle safety constraints. "Additionally, we compare our method with three state-of-the-art online safe RL algorithms, i.e., PPO-Lagrangian~\cite{ray2019benchmarking}, P3O~\cite{p3o}, and CPO~\cite{cpo}"
- Proximal Policy Optimization (PPO): An on-policy RL algorithm with a clipped objective to stabilize policy updates. "Uni-O4~\cite{lei2024unio} directly applies the PPO~\cite{ppo} objective to unify offline and online learning, eliminating the need for extra regularization."
- Q-function safety critic: A critic that estimates discounted future constraint violations using a Q-function. "replacing it with a Q-function safety critic from Recovery-RL~\cite{thananjeyan2021recovery}, which is based on a simple MLP."
- Recovery policy: A policy trained to steer the agent from risky or near-failure states back into safe regions. "The recovery policy is trained with recovery demonstrations that illustrate how to avoid or escape from near-failure states."
- Recovery RL: Safe RL approach that learns recovery behaviors to prevent or escape unsafe states before failures occur. "Recovery RL~\cite{thananjeyan2021recovery} and ABS~\cite{he2024agile} predict constraint violations and employ recovery policies to avoid unsafe states before failures occur."
- SafeDreamer: A safe RL method integrating Lagrangian constraints into DreamerV3’s planning. "SafeDreamer~\cite{huang2024safedreamer} integrates Lagrangian methods into the DreamerV3 planning process for model-based safe RL."
- Safety critic: A learned model estimating the risk of constraint violations to guide safe exploration. "a safety critic based on a latent world model for failure prediction"
- State visitation distribution: The distribution over states visited by a given policy during interaction. "where $\rho_{\pi_{task}$ is the state visitation distribution under policy ."
- Uni-O4: An offline-to-online RL method that applies PPO to unify offline and online learning without extra regularization. "Uni-O4~\cite{lei2024unio} directly applies the PPO~\cite{ppo} objective to unify offline and online learning, eliminating the need for extra regularization."
- World model: A learned predictive model of environment dynamics, rewards, and constraints used for planning and safety. "We also pre-train a world model with both task and failure demonstrations, specifically for predicting future failures."
Practical Applications
Immediate Applications
Below are concrete, deployable applications that can leverage the paper’s FARL paradigm (world-model safety critic + recovery policy, trained offline and used to gate online fine-tuning), together with FailureBench for evaluation. Each item includes sector, potential tools/workflows/products, and assumptions/dependencies that influence feasibility.
Manufacturing and Industrial Robotics
- Safer online post-deployment fine-tuning of manipulation skills involving fragile or constrained objects (e.g., electronics assembly, glassware, precision fixtures, wafer and battery handling, packaging with tight boundaries).
- Tools/workflows/products: Safety-gated PPO/Uni-O4 fine-tuning pipeline; “Safety Critic” module packaged as a ROS2/MoveIt plugin; recovery-policy library for common error modes (e.g., re-centering, retreat maneuvers); dashboard tracking failure likelihood and “intervention-requiring failures” per shift.
- Assumptions/dependencies: Availability of task, recovery, and failure demonstrations; reliable perception and state estimation; ability to override controller actions in real time; safe-set boundaries and constraint definitions are known; near-future failure modes are predictable within short horizons (H steps); sufficient on-robot compute for world-model inference at control rate.
- Rapid bring-up and retuning of new product SKUs or fixtures with minimal scrap/downtime by gating exploration during in-situ adaptation.
- Tools/workflows/products: Changeover workflow that includes quick collection of a small set of recovery/failure demos; automated threshold selection (ε_safe) with guardrails.
- Assumptions/dependencies: Line-side teleoperation or scripted data collection; stable process windows; human approval gates for threshold changes.
Logistics, Warehousing, and Retail
- Safer fine-tuning for bin-picking, sorting, and shelf-stocking with boundary constraints and human co-presence (dropping items off-bounds, knocking items out of reach).
- Tools/workflows/products: FailureBench-like scenarios adapted to racks/totes; warehouse MLOps pipeline that retrains the safety critic nightly from logged “near misses.”
- Assumptions/dependencies: Sensing coverage in clutter; accurate detection of boundaries and no-go zones; action override interface integrated with warehouse control systems.
Lab Automation and Pharma/Biotech
- Reducing spills/breakages during online adaptation of pipetting and plate-handling robots; recovery actions when near walls/obstacles or when slippage detected.
- Tools/workflows/products: Predefined recovery-policy pack for lab tooling (e.g., abort-and-withdraw, regrasp); lab “Safety-Gate SDK” integrated into scheduling/LIMS.
- Assumptions/dependencies: Sterility constraints integrated as binary constraints; fine-grained perception for liquid/fragile containers; short-horizon risk sufficient to catch common failures.
Healthcare and Hospital Logistics
- Service robots (supply delivery, room prep) that can safely refine routes and manipulation skills in cluttered, dynamic hallways while minimizing intervention.
- Tools/workflows/products: Hospital-grade safety critic with curated recovery demonstrations (doorway clearance, stretcher avoidance); monitoring dashboard for safety KPIs.
- Assumptions/dependencies: HIPAA/privacy-compliant data collection; robust human/obstacle tracking; clinical safety reviews for online learning gates.
Agriculture and Food Handling
- Harvesting and packing arms that adapt to crop variability while avoiding bruising or knocking produce off conveyors/bins.
- Tools/workflows/products: Task-/recovery-demo toolkits per crop and season; threshold auto-tuning based on damage-rate KPIs.
- Assumptions/dependencies: Multi-view perception in outdoor conditions; reliable definitions of “damage” as constraints; seasonal domain shifts addressed by periodic retraining.
Field Service, Energy, and Utilities
- Constrained-space manipulation (valves, panels, connectors) where online refinement is safety-gated to avoid collisions or boundary violations.
- Tools/workflows/products: Digital-twin failure generation + FailureBench variants for assets; on-device safety gate integrated with existing PLC/safety relays.
- Assumptions/dependencies: Accurate environment model or sensing; certifiable override path; acceptance within safety management systems.
Academic Research and Education
- A common benchmark (FailureBench) for evaluating offline-to-online RL safety; reproducible baselines for world-model-based safety critics and recovery policies.
- Tools/workflows/products: Course/lab kits with FailureBench tasks and open-source FARL code; canned datasets of task/recovery/failure demos.
- Assumptions/dependencies: Access to simulation and a manipulator; consistent evaluation protocols.
Software and Tooling Vendors
- Productizing a “Safety-Gated Online RL” library: plug-and-play world model, constraint head, and recovery-policy interfaces for popular simulators and real robots.
- Tools/workflows/products: SDKs for Isaac Gym, MetaWorld, PyBullet, ROS2; data collection assistants for recovery/failure demos; monitoring/alerting modules.
- Assumptions/dependencies: Support for diverse robot stacks; performance tuning for low-latency inference; clear APIs for constraints and gating.
Organizational Policy and Governance
- Internal deployment policies requiring a safety critic and recovery policy for any online fine-tuning; standardized failure-rate metrics in acceptance tests.
- Tools/workflows/products: Governance playbooks; “failure-per-1k-episodes” KPIs; audit trails of threshold choices and overrides.
- Assumptions/dependencies: Change-management buy-in; incident reporting integrated with MLOps; ability to pause/rollback fine-tuning.
Consumer and Educational Robotics
- Home/service robot arms that safely self-improve tasks like tidying or table clearing without knocking items off tables or damaging objects.
- Tools/workflows/products: Embedded safety gate and downloadable recovery policy packs; parental/owner controls for thresholds.
- Assumptions/dependencies: Robust perception under household variability; lightweight on-device inference; curated recovery demos for common home setups.
Long-Term Applications
These applications are promising but require additional research, scaling, or engineering (e.g., broader sensors, stronger guarantees, cross-domain generalization).
Foundation “Failure World Models” and Cross-Task Safety
- Pretrained, cross-embodiment safety world models that generalize to new robots and tasks with minimal finetuning; a marketplace of reusable recovery policies.
- Tools/workflows/products: Safety foundation models served via edge/cloud; “Recovery Policy Hub” curated by domain (assembly, retail, lab).
- Assumptions/dependencies: Large, diverse multi-robot datasets of task/recovery/failure episodes; transfer learning that preserves safety; licensing and liability frameworks.
Multimodal Safety and High-Speed Control
- Integration of rich sensing (3D depth, tactile/force, audio, vision-language context) and higher-rate control for fast, dynamic tasks (throwing, tool use, dexterous manipulation).
- Tools/workflows/products: Multimodal world models with tactile/vision fusion; real-time safety co-processors for low-latency gating.
- Assumptions/dependencies: Sensor calibration and sync; efficient inference at kHz rates; model compression/acceleration; robust failure labels at scale.
Mobile Manipulation and Complex Embodiments
- Safety-gated online learning for mobile manipulators, dual-arm systems, and collaborative cells with human co-workers.
- Tools/workflows/products: Spatiotemporal constraint modeling for base+arm; coordination policies for multi-arm recovery; human-intent-aware safety critics.
- Assumptions/dependencies: Accurate joint/base state estimation; social navigation constraints; more complex recovery demonstrations.
Regulatory Standards and Certification
- Sector-wide certification that mandates safety gating for any on-robot learning; standardized metrics (failure episodes, near-miss rates), stress tests, and simulation-to-real protocols.
- Tools/workflows/products: Compliance test suites (FailureBench-Industry); third-party auditing services; safety model documentation templates.
- Assumptions/dependencies: Consensus on definitions of “failure requiring intervention”; traceability tooling; clear liability attribution for learning-enabled robots.
Fleet-Scale and Federated Safety Learning
- Continuous improvement across fleets where robots share anonymized failure and recovery experiences; “near-miss” mining for proactive retraining.
- Tools/workflows/products: Federated MLOps pipelines; privacy-preserving telemetry; auto-curation of failure/recovery datasets.
- Assumptions/dependencies: Data-sharing agreements; robust privacy and cybersecurity; heterogeneous hardware support.
Digital Twins and Synthetic Failure Generation
- Scalable simulation-to-real pipelines that synthesize diverse, rare failure modes to pretrain safety critics before deployment.
- Tools/workflows/products: FailureBench extensions per facility; generative scene perturbation; domain randomization tailored to safety.
- Assumptions/dependencies: High-fidelity simulators; validated sim-to-real transfer for failure distributions; procedures to reconcile simulation bias.
Verified Safety and Formal Guarantees
- Combining FARL’s data-driven gate with control-theoretic shields (e.g., control barrier functions) and formal verification for certifiable safety envelopes.
- Tools/workflows/products: Hybrid safety stacks (learned critic + formal shield); proof-carrying controllers; runtime monitors with provable bounds.
- Assumptions/dependencies: Accurate system models for formal layers; composability of learning and control-theoretic guarantees; regulatory acceptance.
Autonomous Labs and Factories with Minimal Human Intervention
- Fully integrated, continuously learning cells that improve throughput while keeping failure rates below contractual SLAs, with automatic recovery and scheduled safety model refreshes.
- Tools/workflows/products: End-to-end autonomy stack (planning + FARL gate + fleet MLOps); SLA-driven threshold tuning; automated incident triage.
- Assumptions/dependencies: Mature MLOps in OT environments; reliable fallback modes; cost-benefit alignment for continuous learning.
In all cases, the central workflow enabled by this paper is:
- Collect task, recovery, and failure demonstrations (small but targeted sets).
- Train a short-horizon world model with a constraint prediction head and a dedicated recovery policy offline.
- Deploy a safety-gated online fine-tuning loop that uses the world model to predict near-future failures and switches to the recovery policy when needed.
- Monitor failure rates and task returns; periodically refresh the safety critic with newly logged near-misses and failures.
Key global assumptions/dependencies across applications:
- Short-horizon predictability of relevant failure modes.
- High-quality recovery demonstrations (low ε_rec) and accurate constraint definitions.
- Real-time action override capability and sufficient inference throughput.
- Reliable perception/state estimation; distribution shifts handled via periodic retraining.
- Organizational and regulatory acceptance of controlled online learning with safety gates.
Collections
Sign up for free to add this paper to one or more collections.