DIAGPaper: Diagnosing Valid and Specific Weaknesses in Scientific Papers via Multi-Agent Reasoning
Published 12 Jan 2026 in cs.AI | (2601.07611v1)
Abstract: Paper weakness identification using single-agent or multi-agent LLMs has attracted increasing attention, yet existing approaches exhibit key limitations. Many multi-agent systems simulate human roles at a surface level, missing the underlying criteria that lead experts to assess complementary intellectual aspects of a paper. Moreover, prior methods implicitly assume identified weaknesses are valid, ignoring reviewer bias, misunderstanding, and the critical role of author rebuttals in validating review quality. Finally, most systems output unranked weakness lists, rather than prioritizing the most consequential issues for users. In this work, we propose DIAGPaper, a novel multi-agent framework that addresses these challenges through three tightly integrated modules. The customizer module simulates human-defined review criteria and instantiates multiple reviewer agents with criterion-specific expertise. The rebuttal module introduces author agents that engage in structured debate with reviewer agents to validate and refine proposed weaknesses. The prioritizer module learns from large-scale human review practices to assess the severity of validated weaknesses and surfaces the top-K severest ones to users. Experiments on two benchmarks, AAAR and ReviewCritique, demonstrate that DIAGPaper substantially outperforms existing methods by producing more valid and more paper-specific weaknesses, while presenting them in a user-oriented, prioritized manner.
The paper introduces DIAGPaper, a multi-agent framework that diagnoses scientific paper weaknesses through specialized reviewer agents, adversarial rebuttal, and severity-based prioritization.
The methodology employs dynamic multi-agent decomposition and a rebuttal mechanism that filters out 40–60% of invalid critiques to enhance review accuracy.
Empirical results demonstrate state-of-the-art performance on AAAR and ReviewCritique datasets, supporting scalable and reliable AI-assisted peer review.
Diagnosing Valid and Specific Paper Weaknesses via Multi-Agent LLM Reasoning: The DIAGPaper System
Introduction and Motivation
Automated identification of substantive weaknesses in scientific manuscripts is crucial for addressing both the scalability and reliability challenges endemic to peer review processes in rapidly expanding research communities. Prior LLM-driven approaches, including both single-agent and multi-agent configurations, have proved limited by their superficial modeling of review diversity, poor validation of identified critiques, and the lack of prioritization among detected weaknesses. The paper "DIAGPaper: Diagnosing Valid and Specific Weaknesses in Scientific Papers via Multi-Agent Reasoning" (2601.07611) introduces a novel multi-agent framework, DIAGPaper, that explicitly incorporates the human review mechanisms of evaluation criteria separation, author-rebuttal-based validation, and severity-oriented prioritization.
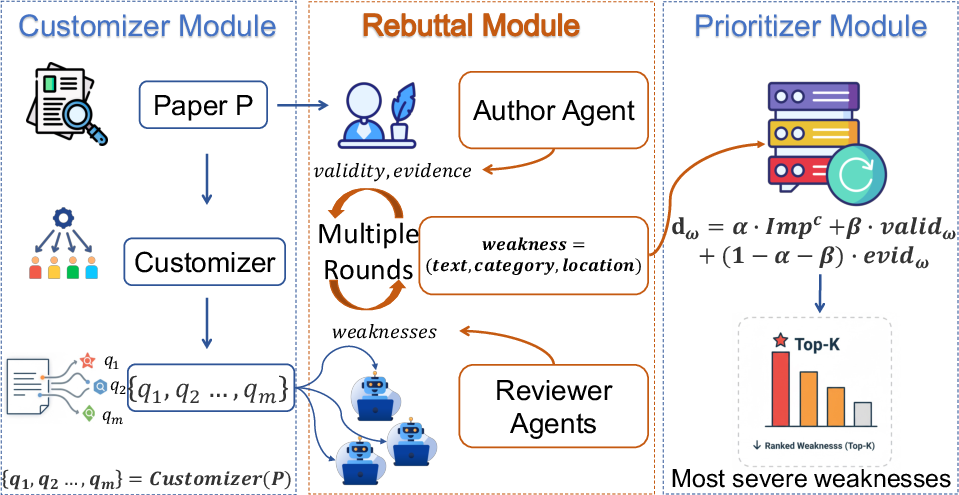
Figure 1: Schematic view of the DIAGPaper pipeline encompassing criterion-driven reviewer agents, adversarial rebuttal, and prioritization.
DIAGPaper presents three tightly integrated modules:
The Customizer module decomposes review into criterion-specific agents matched to paper content.
The Rebuttal module implements a multi-round, evidence-driven reviewer-author adversarial exchange to filter and refine weaknesses.
The Prioritizer ranks weaknesses based on learned severity, closely modeling meta-review decision dynamics.
Methodological Advancements
Criteria-Oriented Multi-Agent Decomposition
Unlike previous multi-agent systems that simulate reviewers or distribute document chunks without explicit criterion grounding, DIAGPaper instantiates reviewer agents along dynamically determined, paper-specific evaluation dimensions. These dimensions, distilled from either a fixed (human-expert derived) or learned set, cover aspects such as methodological clarity, experimental completeness, dataset representativeness, and statistical rigor. The Customizer module is capable of generating these dimensions automatically, allowing the system to dynamically instantiate specialist reviewer agents reflecting the nuanced internal planning strategies of human experts.
Adversarial Rebuttal Mechanism
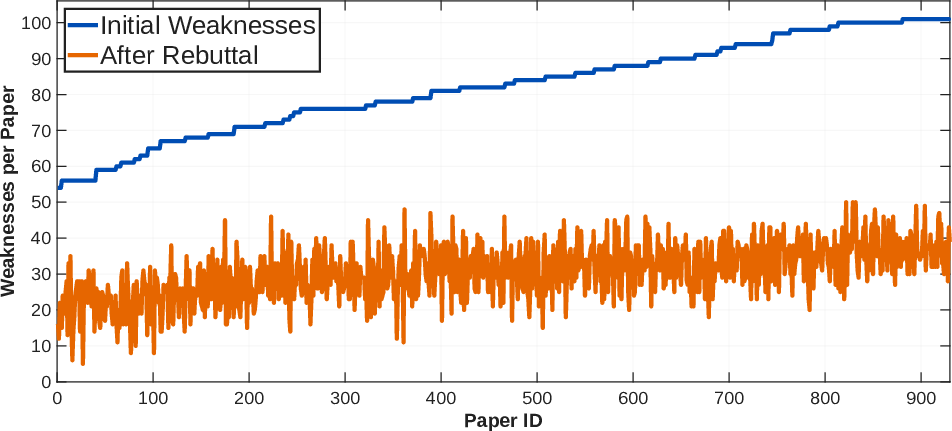
DIAGPaper introduces a fine-grained, weakness-level adversarial rebuttal module. For each critique proposed by a reviewer agent, an author agent systematically challenges its validity by referencing paper content and concrete evidence. This exchange proceeds for up to three iterations, with weaknesses filtered if insufficient evidence accrues. The result is a substantial culling of claims lacking rigorous, context-sensitive support—empirically, 40–60% of initial weaknesses are filtered out in this manner.
Figure 2: Weakness counts before (blue) and after (orange) the rebuttal stage, illustrating substantial invalid critique filtering.
Severity-Based Prioritization
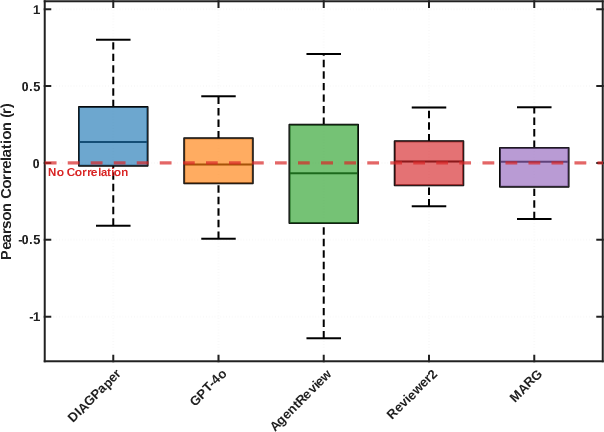
To address practical needs in peer review—especially for meta-review or author response triage—DIAGPaper’s Prioritizer module assigns severity to each retained weakness. The scoring merges a learned, empirically derived category impact measure (from analysis of 15,000+ ICLR/NeurIPS/ICML reviews), the validation score emerging from rebuttal, and a measure of evidential grounding. DIAGPaper then outputs only the top-ranked weaknesses as determined by this composite score, closely reflecting the decision logic of area chairs and senior reviewers.
Figure 3: Positive Pearson correlation between system-assigned severity ranks and semantic F1 against human-accepted weaknesses—contrasted with randomness in prior baselines.
Empirical Results
Evaluations on AAAR and ReviewCritique, two authoritative corpora with fine-grained annotations of critique validity, demonstrate state-of-the-art results for DIAGPaper across all principal metrics:
On AAAR: F1 = 51.89, Specificity = 13.50
On ReviewCritique (Valid): F1 = 50.23, Specificity = 10.25
These outstrip single-agent LLMs, review-specialized agents (e.g., Reviewer2, MARG), and even GPT-4o baselines. Particularly salient is the system's ability to reject invalid weaknesses—as measured by a normalized F1inv diagnostic score—and to generate more paper-specific, less generic points of critique.
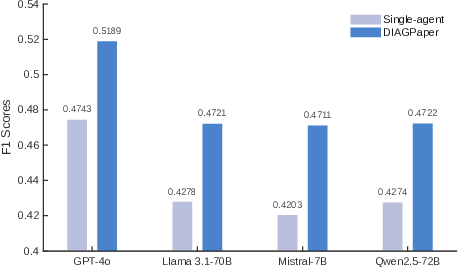
Further, a direct comparison of single-agent vs. multi-agent deployments under DIAGPaper (Figure 4) shows that "multi-agentization" consistently yields substantial performance gains across diverse LLM architectures. Open-source LLMs embedded in DIAGPaper nearly match (and sometimes exceed) closed-source systems, significantly broadening deployment flexibility and resource efficiency.
Figure 4: Performance improvements induced by multi-agentization across foundational LLMs, evidencing cross-family generalization.
Behavioral Analysis and Ablation
Ablation studies reveal that the rebuttal mechanism is the most critical contributor to weakness validity and specificity; removing the Customizer or Prioritizer modules also decreases performance, highlighting the need for criterion diversity and user-oriented ranking. The Customizer is shown to outperform human-fixed dimensions in identifying highly paper-specific or overlooked evaluation axes.
Manual annotation of low-precision weaknesses uncovers that DIAGPaper, while the most specific and valid in absolute terms, tends toward over-stringency—flagging issues that are technically valid but operationally unrealistic to address, a pattern rare in existing LLM-based review agents.
Implications and Future Prospects
DIAGPaper’s integration of dynamic multi-agent collaboration, adversarial validation, and empirically grounded severity quantification positions it as a strong candidate for widespread deployment in AI-assisted peer review—particularly in high-volume venues and researcher-facing platforms. Practically, open-source LLMs leveraged within DIAGPaper now approach closed-source LLM reliability at dramatically reduced cost, supporting scalable and democratized review.
Theoretically, the framework's emphasis on explicit modeling of reviewer diversity, systematic rebuttal, and preference-driven prioritization sets a methodological standard for future research on agent-based scientific reasoning and critique generation. The model's decoupling from fixed roles and reliance on learned dimensions anticipates better adaptation to interdisciplinary submissions and evolving review norms.
Critical limitations remain, including computational overhead (due to multi-agent simulation), the current exclusion of external literature retrieval, and open questions regarding generalizability outside the AI research domain. Future advances may address these via tighter agent orchestration, retrieval-augmented modules, and domain-adaptive customization.
Conclusion
DIAGPaper (2601.07611) establishes a new performance and methodological baseline for multi-agent LLM systems in automated paper critique. By aligning agent roles with human review practices, validating via adversarial rebuttal, and surfacing only the most consequential weaknesses, DIAGPaper achieves a robust combination of validity, specificity, and user relevance across multiple evaluation regimes. This tightly integrated architecture holds strong practical promise for high-stakes, large-scale peer review augmentation and presents several technical avenues for expanding automated scientific reasoning capabilities.