Proof of Time: A Benchmark for Evaluating Scientific Idea Judgments
Abstract: LLMs are increasingly being used to assess and forecast research ideas, yet we lack scalable ways to evaluate the quality of models' judgments about these scientific ideas. Towards this goal, we introduce PoT, a semi-verifiable benchmarking framework that links scientific idea judgments to downstream signals that become observable later (e.g., citations and shifts in researchers' agendas). PoT freezes a pre-cutoff snapshot of evidence in an offline sandbox and asks models to forecast post-cutoff outcomes, enabling verifiable evaluation when ground truth arrives, scalable benchmarking without exhaustive expert annotation, and analysis of human-model misalignment against signals such as peer-review awards. In addition, PoT provides a controlled testbed for agent-based research judgments that evaluate scientific ideas, comparing tool-using agents to non-agent baselines under prompt ablations and budget scaling. Across 30,000+ instances spanning four benchmark domains, we find that, compared with non-agent baselines, higher interaction budgets generally improve agent performance, while the benefit of tool use is strongly task-dependent. By combining time-partitioned, future-verifiable targets with an offline sandbox for tool use, PoT supports scalable evaluation of agents on future-facing scientific idea judgment tasks.
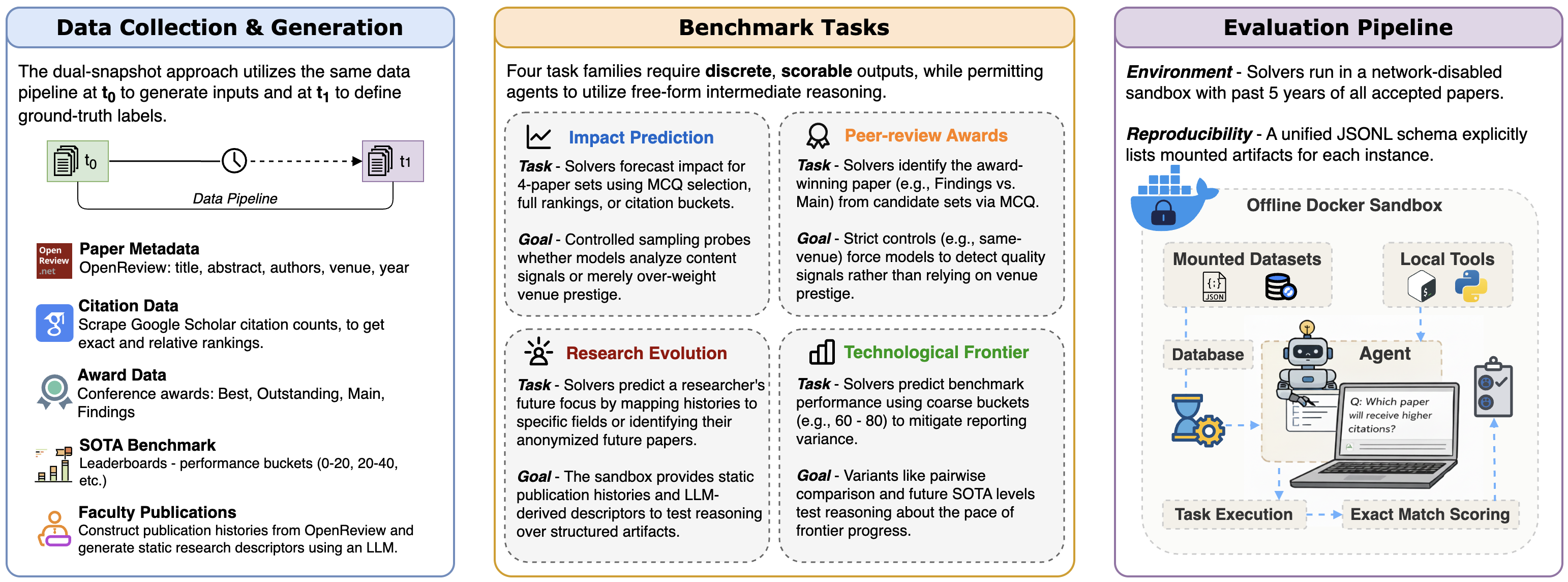
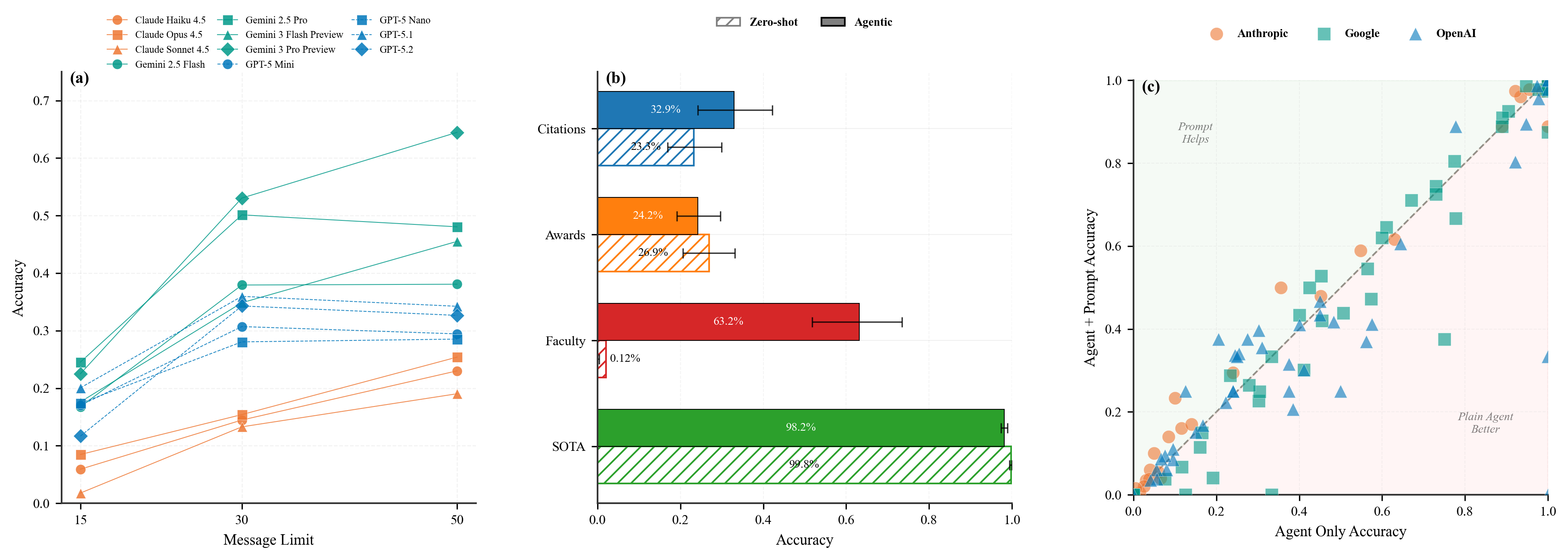
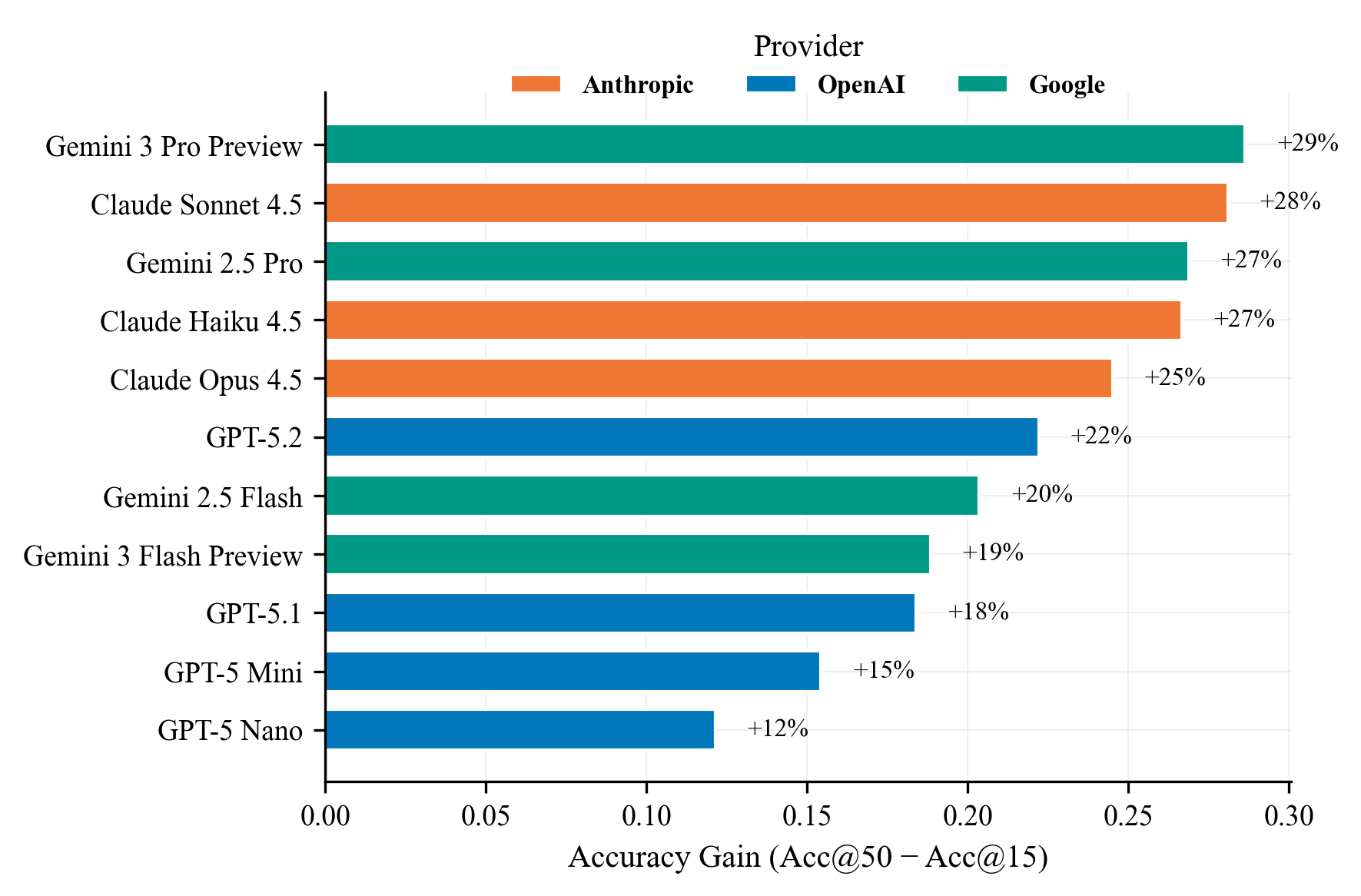
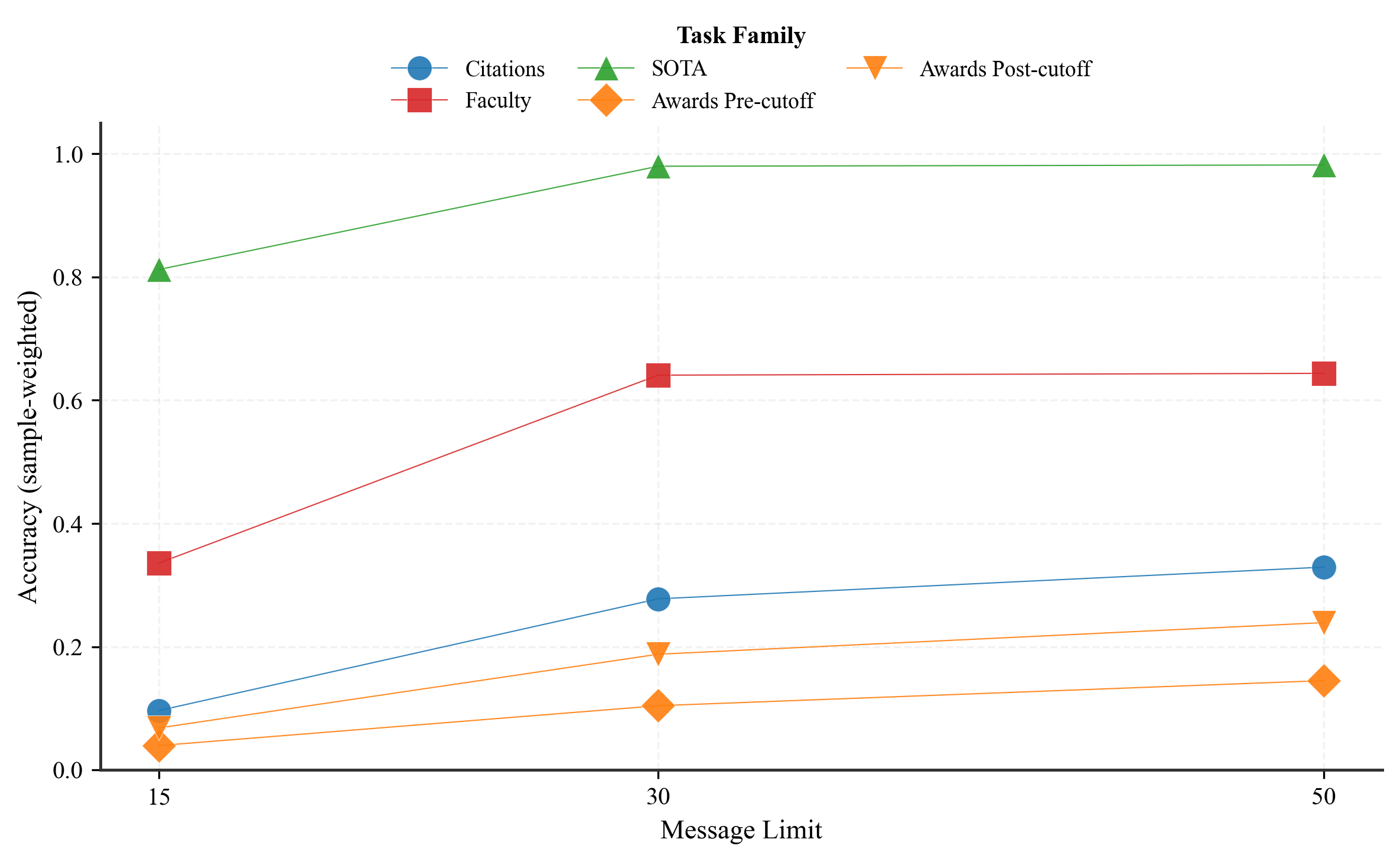
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Proof of Time (PoT): A Simple Guide
What this paper is about
This paper introduces Proof of Time (PoT), a new way to test how well AI systems can judge scientific ideas. In other words, it checks whether AI can look at information available today and make smart predictions about which research ideas will matter in the future.
The big questions the paper asks
The authors wanted to know:
- Can AI predict future signals of a research idea’s importance (like how many citations a paper will get or which papers will win awards)?
- Is there a fair, scalable way to test these predictions without relying on lots of human grading?
- Do “agent” AIs (which can use tools to analyze files and data) make better judgments than regular AIs that just answer directly?
- How does giving an AI more time/steps to think (a bigger “message budget”) change its performance?
How they tested it (in everyday terms)
Think of this like a “time capsule” game for AI:
- Freeze time at a certain date (the “cutoff”). Give the AI only the information that existed before that date (titles, abstracts, old leaderboards, past publications, etc.).
- Ask the AI to make predictions about what will happen after that date (for example, which paper will get the most citations next year).
- Wait until the real results are known, then check if the AI was right. This makes the test fair and verifiable.
To keep things controlled, the AI works in an “offline sandbox.” That means:
- No internet.
- It can only use the files provided (the frozen evidence).
- In “agent” mode, the AI can use simple tools (like reading files or running small Python scripts) to explore and analyze the evidence before answering.
They tested four kinds of future-focused tasks:
| Task Family | What the AI predicts | Why it matters |
|---|---|---|
| Citations (Impact) | Which new papers will be cited more | A proxy for which ideas influence future research |
| Awards (Peer Review) | Which papers will win conference awards | Measures alignment with expert judgments |
| Research Evolution (Faculty) | How a professor’s research will shift (topics, authorship) | Tests understanding of research trajectories |
| SOTA Forecasting (Technological Frontier) | How model performance on benchmarks will improve | Checks whether the AI can read trends and extrapolate |
They compared:
- Zero-shot: the AI answers directly from the prompt (no tools).
- Agentic: the AI explores the evidence with tools inside the sandbox.
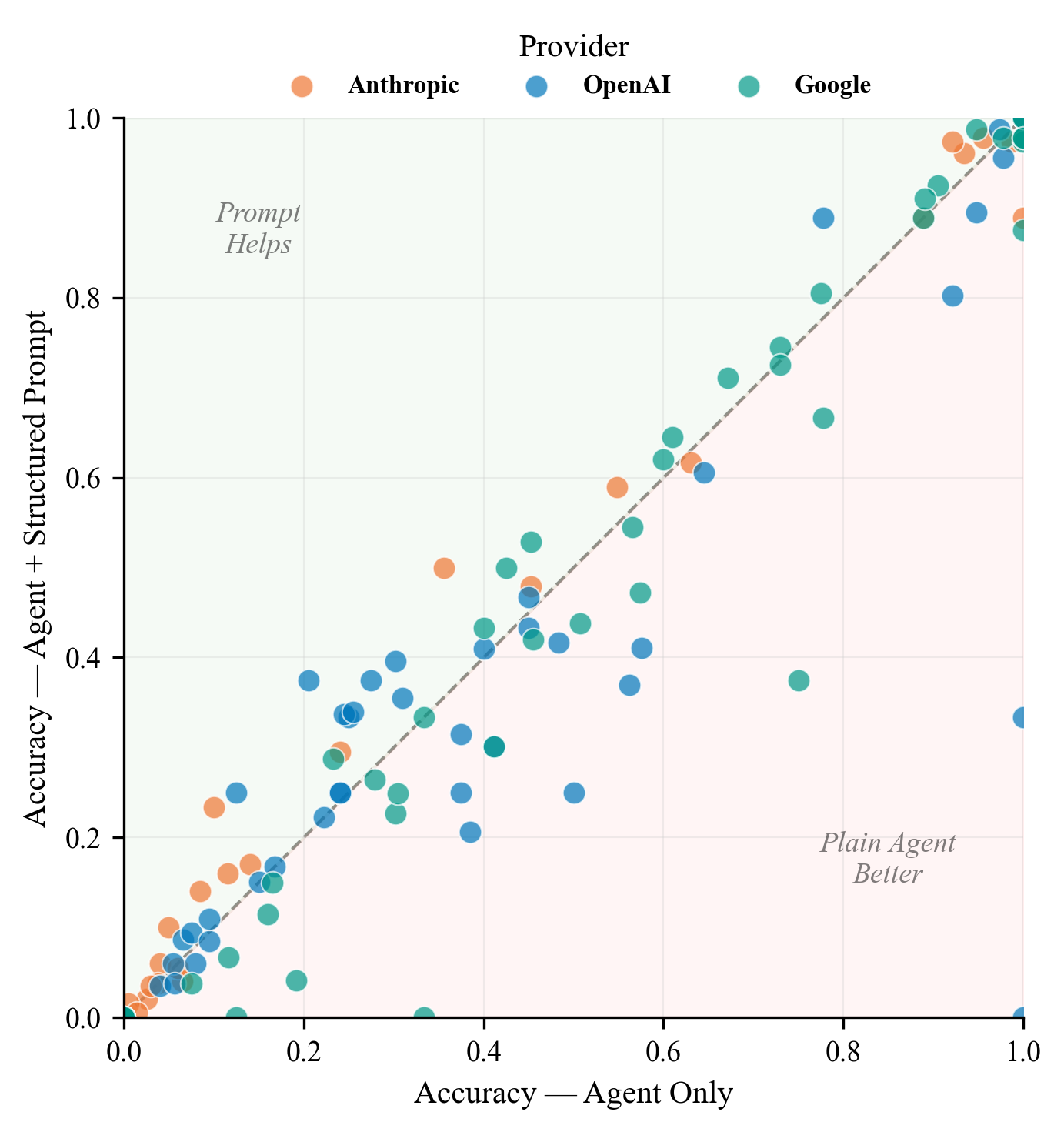
- Agentic + structured prompt: same as above, but with more detailed instructions on how to use tools.
- Different “message limits” (like 15, 30, or 50 steps), which is like giving the AI more time to think and work.
What they found (in clear terms)
Here are the main results:
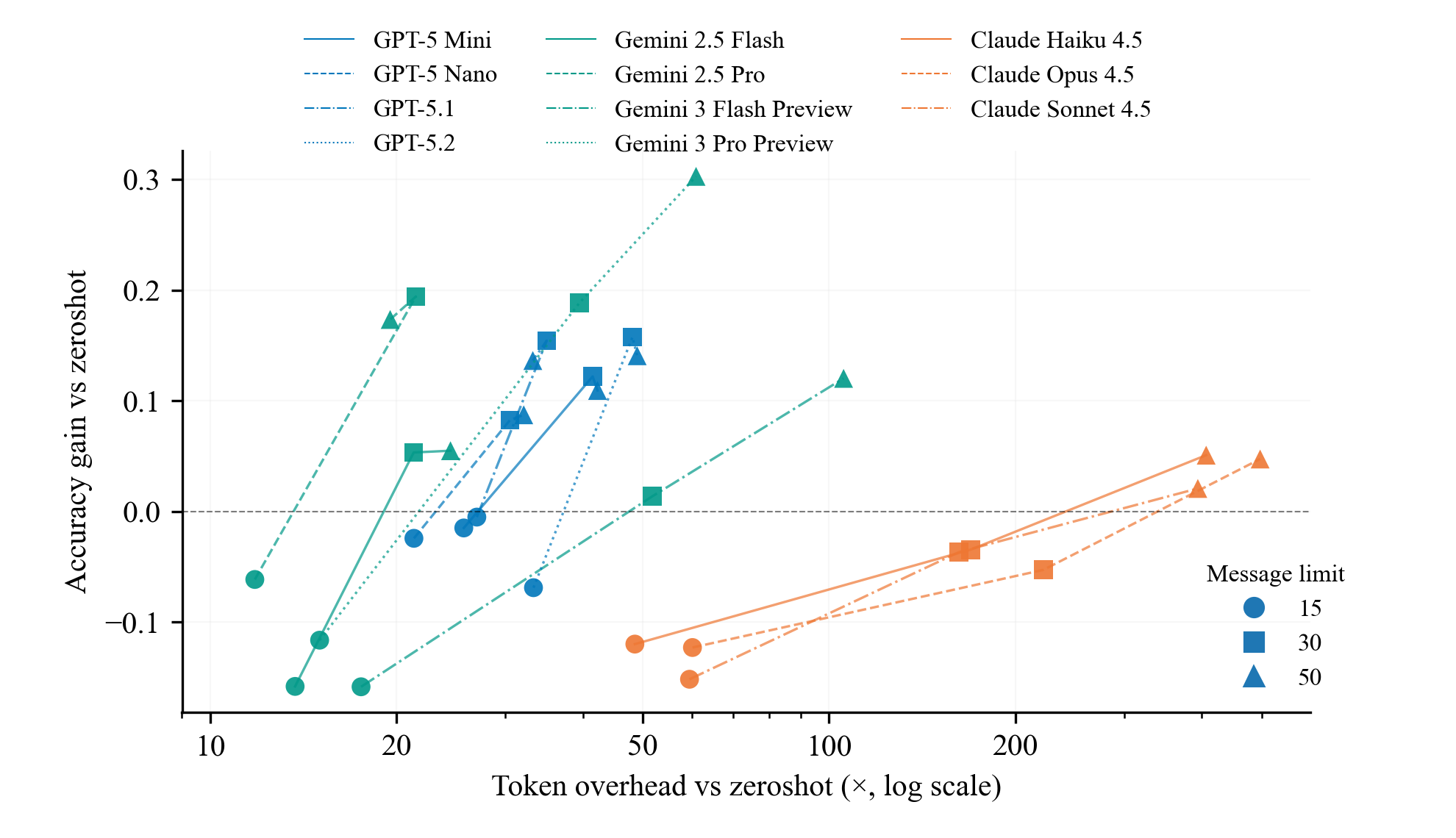
- More thinking time helps: Allowing the agent more interaction steps (a bigger message budget) generally improved results. The AI used the extra steps to find and check more evidence.
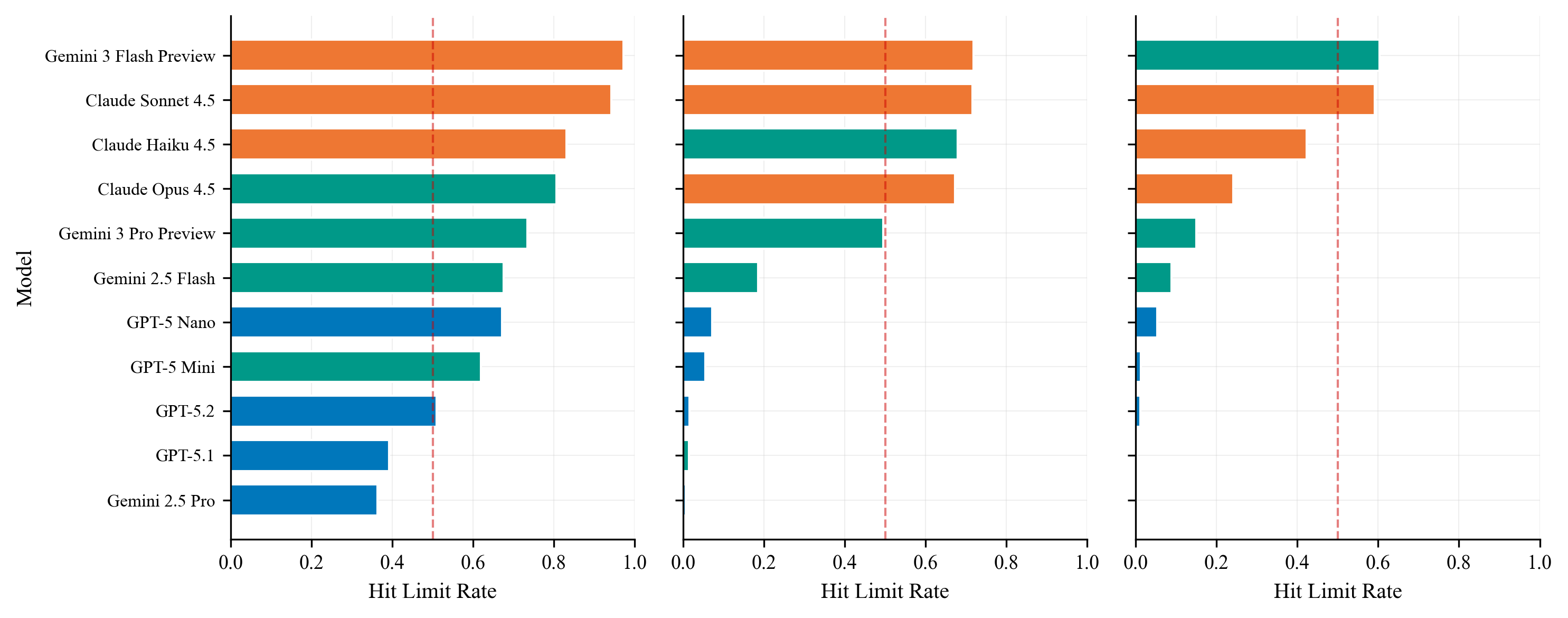
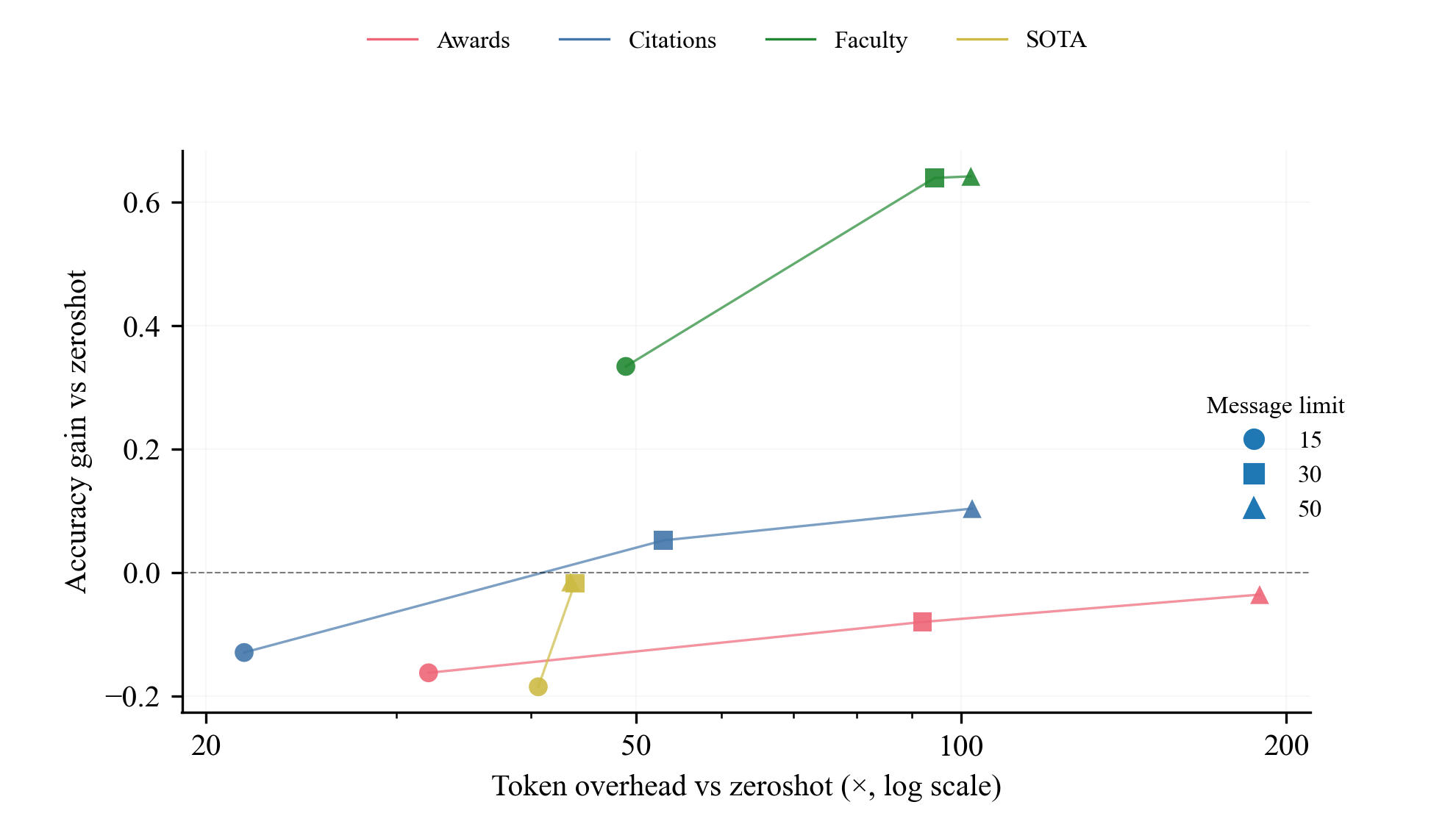
- Agents help most when evidence matters: Tool-using agents did much better than direct answers on tasks where exploring the provided files helps a lot—especially the Faculty (research evolution) tasks. They also improved moderately on Citations.
- Not all tasks benefit equally: For Awards, agent tools didn’t help much on average. For SOTA (predicting benchmark performance in broad buckets), both direct and agent methods were already near the top, so there wasn’t much room to improve.
- Prompts aren’t magic: Adding a structured prompt (extra instructions) sometimes helped, sometimes didn’t. It depended on the model.
- Real-time labels change the story: When they switched from testing on pre-cutoff data to testing on post-cutoff (future) outcomes, some models’ rankings changed a lot. This shows why judging future-focused tasks with future data is important.
- Why agents fail: When agents got things wrong, it was mostly due to:
- Reasoning mistakes (misinterpreting evidence).
- Retrieval/tool issues (finding or parsing the wrong file/data).
- Looping or running out of steps before finishing.
Why this matters
- Fairer, future-focused testing: PoT avoids “cheating” from memorized training data by using post-cutoff outcomes. It tests true forecasting ability, not recall.
- Scalable and refreshable: Because the “answers” come from real-world future signals (like citations and awards), you don’t need huge teams of experts to label everything.
- Practical guidance: The results give a realistic view of when to use agentic AIs. Use them (and give them more steps) for evidence-heavy tasks where careful checking matters; keep it simple for easy or already-saturated tasks.
- Understanding limits: Since proxies like citations or awards aren’t perfect measures of “idea quality,” the framework is “semi-verifiable.” Still, it’s a strong step toward evaluating how well AI can judge scientific ideas over time.
In short
PoT is like asking AI to predict tomorrow using only yesterday’s information, then grading it when “tomorrow” actually arrives. It shows that tool-using agents can be powerful for research judgment—especially when they have time to explore evidence—but their benefits depend on the task, the instructions, and the model. This benchmark gives researchers a fair, scalable way to measure and improve AI’s ability to assess which scientific ideas will stand the test of time.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a single, concrete list of what remains missing, uncertain, or unexplored, phrased so future researchers can act on it.
- Validate proxy constructs: systematically quantify how well each proxy (citations, award tiers, SOTA buckets, faculty topic shifts) maps to “idea quality” across subfields and time, using field-normalized metrics, altmetrics, expert ratings, and long-horizon outcomes.
- Clarify temporal design: explicitly specify and per task, horizon lengths, and update cadence; run sensitivity analyses to show how performance and conclusions change with different cutoffs/horizons.
- Expand domain coverage: extend beyond NLP/AI conferences (ACL/NAACL/EMNLP) to diverse disciplines (e.g., biomedicine, physics, social sciences), journals vs. conferences, and multilingual corpora to assess generalizability.
- Improve ranking evaluation: for “Ranking” tasks, replace exact-match accuracy with rank-aware metrics (Spearman/Kendall, NDCG), confidence intervals, and calibration curves to capture ordering quality and uncertainty.
- Elicit probabilistic forecasts: require and score probability distributions (e.g., citation buckets, award tiers) using Brier score, log-likelihood, and expected calibration error to assess calibration and risk-aware judgments.
- Control for contamination: design counterfactual/perturbed variants (title/abstract paraphrases, masked identifiers, synthetic decoys) and measure how model performance shifts to disentangle parametric memorization from evidence-grounded inference.
- Disentangle style vs. substance: in award-tier prediction, ablate text signals (e.g., mask stylistic markers) to test whether models predict awards based on writing style/venue norms versus core contribution.
- Normalize citation signals: apply field/year normalization (e.g., z-scores within venue-year, co-author network controls) to reduce exposure effects and reveal genuine impact forecasting.
- Address award taxonomy consistency: clarify whether “Findings” is treated as an award tier or track; align tiers to true award categories (e.g., Best Paper, Outstanding Paper) and handle track-specific eligibility cleanly.
- Strengthen faculty-task ground truth: replace or validate LLM-derived keywords/field labels with authoritative sources (ORCID, DBLP, institutional pages) and conduct human validation for author–field mappings.
- Identity disambiguation: implement robust author disambiguation (name variants, common names) and measure its error rate’s effect on faculty and citation tasks.
- Long-horizon impact: add multi-year horizons (e.g., 3–5+ years) to capture slow-burn impact and measure temporal stability of early forecasts.
- Benchmark refresh governance: define versioning, periodic refresh schedules, data sources (OpenAlex/Crossref vs. Google Scholar), and reproducible joining heuristics; publish change logs and drift diagnostics.
- Trace annotation reliability: replace single LLM-as-judge with multi-judge ensembles, report inter-rater reliability, and include human adjudication for a sampled subset of agent traces.
- Failure-to-fix studies: for each failure mode (reasoning, retrieval/tooling, looping), run targeted interventions (e.g., last-mile verification steps, better search formulation, parsing guards) and quantify error reduction.
- Agent architecture ablations: compare single-agent ReAct against planning agents, multi-agent debate, memory-augmented agents, and learned tool-use policies (e.g., RL fine-tuning) under identical sandbox constraints.
- Adaptive budget policies: develop cost-aware inference strategies (e.g., early-exit criteria, bandit-based budget allocation per instance) and measure accuracy–cost efficiency frontiers in tokens, wall-clock time, and energy.
- Tooling diversity: test richer offline tools (vector search over snapshot, lightweight citation graphs, structured metadata indices) and measure their incremental value while preserving isolation from post-cutoff data.
- Decoding settings and robustness: standardize and report temperature, top-p, seed settings; run robustness sweeps to ensure conclusions are not artifacts of sampling policies.
- Human–model misalignment analysis: quantify where models diverge from peer-review outcomes (topic areas, institutions, novelty classes), and study whether divergences correlate with documented biases or known failure modes.
- Bias and fairness audits: instrument tasks with demographic/institutional covariates (when ethically feasible), measure disparate performance, and test mitigation strategies (reweighting, fairness-aware objectives).
- SOTA forecasting granularity: move beyond coarse buckets to fine-grained performance deltas, uncertainty intervals, and distributional forecasts; account for benchmark evolution (dataset changes, metric redefinitions).
- Open-world realism: complement sandbox evaluation with controlled retrieval-enabled settings to estimate the gap between constrained and realistic workflows and identify where up-to-date information is critical.
- Evidence attribution requirements: require agents to cite specific snapshot files/rows used for decisions, and audit attributions to ensure answers are grounded in the offline evidence rather than parametric priors.
- Distribution shift diagnostics: compare pre- vs. post-cutoff splits for composition and difficulty shifts; report stratified performance (topic, venue, length) and control for confounders.
- Token-to-performance tradeoffs: report standardized token accounting per configuration and instance, and study diminishing returns at higher budgets across models and task families.
- Data licensing and reproducibility: assess licensing, stability, and coverage differences between Google Scholar and open bibliographic sources; quantify label drift and replicate runs across sources.
- Negative/corrective signals: incorporate “negative” impact indicators (retractions, errata) and topic corrections to test whether models avoid forecasting impact for problematic or debunked ideas.
- Manipulation resilience: explore whether public knowledge of benchmark instances enables gaming (e.g., citation padding, leaderboard overfitting) and design defenses (hidden splits, randomized targets).
- Error bars and significance: provide bootstrap confidence intervals, multiple-comparison corrections, and significance tests for model/ranking differences; publish per-task sample sizes and variance estimates.
- Cross-lingual evaluation: add non-English papers and multilingual faculty to test whether agents generalize across languages and translation noise.
- Ethical safeguards: study potential feedback loops where model forecasts influence researcher behavior, and propose guardrails (disclosure, non-deployment policies, impact reviews) for responsible use.
Practical Applications
Immediate Applications
The following applications can be piloted or deployed now using the PoT benchmark, code, and design patterns (time-partitioned targets, offline sandbox, agent-vs-zero-shot comparisons, message-budget scaling).
- Model procurement and benchmarking for AI research assistants (Industry, Software)
- Use case: Evaluate vendor models/agents marketed for literature review, paper triage, and “AI for Science” assistance using PoT’s frozen-evidence, post-cutoff scoring to avoid contamination and judge subjectivity.
- Tools/products/workflows: Internal “PoT runner” service; offline Docker sandbox with read-only corpora; dashboards showing accuracy vs. token cost vs. message budget; contract acceptance criteria tied to PoT scores on tasks like citation prediction and SOTA trajectory buckets.
- Dependencies/assumptions: Access to domain-relevant pre-cutoff corpora; agreement on target horizons; acceptance that citation/award signals are imperfect proxies.
- Evidence-grounded agent design and cost-performance tuning (Industry, Software, Academia)
- Use case: Optimize agent loops, toolkits, and message limits by measuring accuracy gains vs. token overhead on PoT’s tasks; deploy auto-tuners that pick low/medium/high budgets depending on task family (e.g., higher budgets for evidence-heavy Faculty/Citations tasks).
- Tools/products/workflows: “Budget tuner” module; trace logging and failure taxonomies (retrieval errors, looping) to guide prompt/tool revisions; structured prompts when helpful.
- Dependencies/assumptions: Comparable sandbox/tooling across models; cost constraints for high-budget runs.
- Contamination-aware evaluation for live ML systems (Industry, Research labs)
- Use case: Add PoT-style time splits to internal eval suites to reduce benchmark data contamination and retroactive memorization; quantify post-cutoff performance shifts that affect model ranking.
- Tools/products/workflows: Quarterly “post-cutoff refresh” jobs; auto-scoring pipelines linked to new leaderboards and citation updates; regression alerts when rankings shift after cutoff.
- Dependencies/assumptions: Stable data pipelines (e.g., Google Scholar, leaderboards); governance for periodic dataset refreshes.
- Metascience analyses of human–model alignment (Academia, Publishing)
- Use case: Compare model forecasts vs. peer-review award outcomes to study alignment, bias, and variance; identify venues or tasks where agentic exploration adds value.
- Tools/products/workflows: Misalignment reports by venue/year; reviewer calibration workshops using PoT instances; reproducible notebooks operating entirely offline.
- Dependencies/assumptions: Ethical use of award and review signals; awareness that awards reflect community processes and may be biased.
- Conference/journal tooling for submission triage and audit (Academia, Publishing)
- Use case: Pilot PoT-style “forecasting tracks” where models/agents predict post-cutoff indicators for accepted papers; use aggregate trends as a diagnostic (not a decision rule) to audit review consistency across areas.
- Tools/products/workflows: Offline submission bundles per track; dual-mandate dashboards (forecast vs. realized signals); no-influence safeguards so forecasts can’t affect acceptance decisions.
- Dependencies/assumptions: Clear policy boundaries to avoid automating merit decisions; legal/ethical approval for post-hoc analysis.
- R&D portfolio horizon scanning (Industry, Finance)
- Use case: Use SOTA trajectory buckets and citation forecasts to inform portfolio bets (e.g., which benchmarks/directions are accelerating) with explicit uncertainty bands.
- Tools/products/workflows: Quarterly “frontier watch” reports; offline, field-specific snapshots (e.g., vision, robotics); cross-task ensemble forecasts.
- Dependencies/assumptions: Proxies can over/underestimate real-world adoption; domain shift when moving beyond NLP/AI benchmarks.
- Domain adaptation to biomedicine for literature triage (Healthcare)
- Use case: Build a PoT-like offline sandbox on PubMed (pre-cutoff metadata, abstracts) to triage which new papers to prioritize for journal clubs, guideline committees, or systematic reviews.
- Tools/products/workflows: Hospital firewall-deployed PoT; agents that summarize evidence linking past cohorts to predicted influence or topic drift; token budget set lower for routine triage.
- Dependencies/assumptions: IRB and privacy review; biomedical-specific proxies (e.g., clinical guideline mentions) may be preferable to raw citations.
- Internal knowledge-base impact forecasting (Industry)
- Use case: Predict which internal tech notes/whitepapers are likely to drive downstream adoption; plan documentation and enablement accordingly.
- Tools/products/workflows: Offline corpora snapshots; quarterly impact buckets; feedback loop with enablement teams.
- Dependencies/assumptions: Need internal engagement metrics as better proxies than public citations; author disambiguation.
- Curriculum and training for “AI for Science” (Academia, Education)
- Use case: Classroom labs where students build and evaluate agents under PoT constraints to learn evidence-grounded forecasting, agentic tool-use, and scientific metrology.
- Tools/products/workflows: Course Docker images; assignments comparing zero-shot vs. agentic vs. structured prompts; trace-based failure analysis.
- Dependencies/assumptions: Compute quotas for message-limited agents; up-to-date pre-cutoff packages per term.
- MLOps and compliance checklists for offline evaluation (Industry, Policy)
- Use case: Standardize “no-net” offline evaluation as a compliance step for models making future-facing claims; generate auditable traces to support procurement and regulatory reviews.
- Tools/products/workflows: Signed evaluation manifests (cutoff dates, sources, tools); artifact locking; third-party reproducibility scripts.
- Dependencies/assumptions: Agreement on acceptable proxies; versioned evidence snapshots; legal readiness for audits.
Long-Term Applications
These applications require further research, cross-domain scaling, governance, or infrastructure maturation before high-stakes deployment.
- Decision support in grantmaking and peer review (Policy, Academia)
- Use case: Use PoT-style forecasts as a calibrated, audited secondary signal to help panels surface overlooked proposals, stress-test hype, and track long-term review calibration.
- Tools/products/workflows: “Forecast overlay” in reviewer dashboards; periodic post-cutoff audit panels; bias diagnostics by field/demographics.
- Dependencies/assumptions: Strong governance to avoid automating acceptance decisions; validated domain-specific proxies beyond citations/awards; community acceptance.
- RL/learning-to-search from delayed, verifiable signals (Software, ML research)
- Use case: Train agents using delayed outcomes (e.g., next-year citation buckets, benchmark progress) as reward to improve long-horizon evidence gathering and commitment strategies.
- Tools/products/workflows: Offline policy optimization with frozen snapshots; counterfactual evaluation; off-policy safety constraints.
- Dependencies/assumptions: Sparse, delayed rewards; proxy misspecification risk; need for stable, refreshable datasets.
- Cross-domain expansion to patents, standards, and regulation (Industry, Policy, IP law)
- Use case: Forecast patent citations/claims, standards adoption, or regulatory inflection points using PoT’s time-partitioned design.
- Tools/products/workflows: Patent office snapshots; standards body minutes; policy tracker sandboxes; “tech readiness” bucket forecasts.
- Dependencies/assumptions: Data licensing; robust entity resolution; different lag structures than academic citations.
- Clinical and translational science forecasting (Healthcare)
- Use case: Predict which preclinical findings will translate to clinical trials or guideline updates; prioritize replication and funding.
- Tools/products/workflows: Multimodal pre-cutoff snapshots (preprints, trial registries); outcome proxies (trial initiation, Phase progression); conservative, human-in-the-loop workflows.
- Dependencies/assumptions: Very high cost of error; medical ethics; better proxies than citations; long horizons.
- National technology foresight dashboards (Policy, National labs)
- Use case: Government horizon scanning across strategic areas (AI, energy, materials), combining SOTA trajectory forecasts with trend acceleration alerts.
- Tools/products/workflows: Federated PoT instances per domain; uncertainty-aware visual analytics; periodic public reports with audit trails.
- Dependencies/assumptions: Data-sharing agreements; standard taxonomies across agencies; governance to avoid policy overreliance.
- Editorial and venue process redesign (Publishing)
- Use case: Post-accept forecasting challenges with delayed scoring to inform awards, tracks, and reviewer calibration; detect systematic mismatches between novelty and eventual impact.
- Tools/products/workflows: Venue-integrated PoT pipelines; anonymization protocols; delayed feedback loops to program chairs.
- Dependencies/assumptions: Community buy-in; careful framing to avoid “gaming” future metrics; fairness safeguards.
- Enterprise innovation underwriting and risk pricing (Finance, Insurance)
- Use case: Use future-verifiable proxies to underwrite R&D risk or price innovation-linked instruments (e.g., milestone financing keyed to benchmark progress).
- Tools/products/workflows: PoT-based scorecards; instrument triggers tied to post-cutoff signals; independent verification services.
- Dependencies/assumptions: Legal structuring; avoidance of self-fulfilling loops; robust anti-manipulation controls.
- Research career planning and advising tools (Academia, Education)
- Use case: Advisors and scholars use PoT-style topic-drift and agenda continuity forecasts to plan collaborations, grants, and reading priorities.
- Tools/products/workflows: Privacy-preserving faculty sandboxes; interactive “trajectory what-ifs”; integration with ORCID/GS profiles.
- Dependencies/assumptions: Consent and privacy; risk of narrowing exploration; improved field taxonomies.
- Safety and governance audits for agentic systems (Policy, Standards bodies)
- Use case: Create certification schemes where future-facing claims by agents must be backed by PoT-like, time-indexed, offline evaluations with verifiable post-cutoff scoring.
- Tools/products/workflows: Compliance test suites; third-party attestation; standardized reporting (cutoff dates, tools, budgets).
- Dependencies/assumptions: Standards harmonization; reproducibility infrastructure; enforcement mechanisms.
- Marketplaces and leaderboards for “evidence-grounded” agents (Industry, Platforms)
- Use case: Platform ratings for agents that must demonstrate accuracy-cost trade-offs on PoT tasks under offline constraints, with continuous post-cutoff updates.
- Tools/products/workflows: Public leaderboards with delayed ground truth; token-efficiency badges; model cards with post-cutoff deltas.
- Dependencies/assumptions: Sustainable refresh cadence; anti-contamination policies; clear licensure of evaluation datasets.
Notes on feasibility across applications:
- Proxy risk: Citations, awards, and benchmarks are imperfect proxies for “quality”; sectors may need domain-specific alternatives (e.g., clinical guideline adoption, patent grants).
- Data and horizons: Quality of results depends on stable pre-/post-cutoff data pipelines and appropriate horizons () for each domain.
- Offline realism: Sandbox constraints improve auditability but may understate performance when live retrieval is allowed; dual-mode eval (offline + controlled retrieval) may be needed.
- Cost-performance trade-offs: Agentic gains depend on message budgets; operational costs and latency must be managed in production.
- Ethics and governance: Avoid using model forecasts as sole decision criteria in high-stakes settings; ensure transparency, fairness audits, and human oversight.
Glossary
- Ablation: Systematic removal or variation of components to test their impact on performance. "controlled ablations over tool access, offline prompting, and message-budget scaling."
- Agent-native evaluation: An evaluation setup tailored to agent systems that measures tool use and interaction under controlled constraints. "Agent-native evaluation: we introduce an offline sandbox protocol that makes tool use measurable and supports controlled ablations over tool access, structured offline prompting, and message-budget (test-time) scaling"
- Agent overhead: The extra cost and complexity introduced by running agentic processes at inference time. "where agent overhead yields diminishing returns."
- Agentic: Pertaining to autonomous, tool-using model behavior and reasoning via multi-step interactions. "higher interaction budgets generally improve agentic performance"
- Award tier: A categorical level of conference recognition (e.g., Findings, Main, Outstanding, Best). "the task is to predict the paper's award tier."
- Benchmark Data Contamination (BDC): Leakage of benchmark content into training data that inflates evaluation scores. "Web-scale pretraining makes static benchmarks increasingly vulnerable to benchmark data contamination (BDC)"
- Benchmark trajectories: The evolution of benchmark performance or state-of-the-art over time. "technological frontier forecasting (SOTA benchmark trajectories)"
- Bibliometric features: Metadata-derived variables (e.g., citation counts, author networks) used to study scientific impact. "using bibliometric features, topic signals, and network structure"
- Budget exhaustion: Running out of the allotted interaction or message budget before completing a task. "Budget exhaustion"
- Contamination-resistant: Designed to prevent or reduce training-data leakage into evaluation sets. "contamination-resistant variants of classic test sets"
- Downstream signals: Later-observed outcomes used as proxies for impact or quality, such as citations or awards. "links scientific idea judgments to downstream signals that become observable later"
- Efficiency frontiers: Curves characterizing the trade-off between performance gains and resource costs. "efficiency frontiers that show accuracy gain over zeroshot against token overhead"
- Exact-match accuracy: A strict scoring metric that counts a prediction as correct only if it exactly matches the gold label. "We report exact-match accuracy for all tasks."
- Evidence snapshot: A frozen, pre-cutoff set of artifacts and metadata available to the solver. "where is the evidence snapshot available up to cutoff "
- Exposure effects: Differences in outcomes due to visibility or timing rather than intrinsic quality. "so comparisons are not driven by natural exposure effects such as earlier publication or venue-wide visibility."
- Frontier models: The latest, most capable models available at evaluation time. "covering the latest frontier models from Anthropic, Google, and OpenAI."
- Gold labels: Ground-truth outcomes used for scoring that can be verified externally. "gold labels are not subjective annotations but outcomes that can be checked later."
- Headroom: Remaining potential for improvement on a task given current performance levels. "limited headroom for tool use on this coarse bucketed variant."
- Interaction budget: The allowed number of agent interaction steps during inference. "higher interaction budgets generally improve agentic performance"
- Leaderboard: A ranked listing of model performance on a benchmark. "popular benchmarks and leaderboards as of October 2025"
- LLM: A model trained on vast text corpora to perform language understanding and generation. "LLMs are increasingly being used to assess and forecast research ideas"
- LLM-as-judge: Using an LLM to evaluate or classify agent traces or outputs. "using an LLM-as-judge protocol (Gemini 3 pro)"
- Looping/thrashing: Repetitive agent behavior that fails to make progress and wastes budget. "Looping / thrashing"
- MCQ (Multiple-Choice Question): A discrete-answer format where models select from predefined options. "In MCQ instances, the solver selects which candidate will have the most citations by the target horizon."
- Message-budget scaling: Varying the number of allowed messages to study performance vs. compute. "message-budget (test-time) scaling"
- Message limit: The cap on environment interaction turns before a final answer must be given. "we vary a message limit: the maximum number of environment interaction turns before the agent must finalize an answer."
- Metascience: The study of how science is conducted and evolves. "This progress has renewed interest in metascience"
- Misalignment analysis: Examining divergences between model assessments and human judgments. "supports misalignment analysis: because some outcomes reflect human judgment (e.g., peer-review awards)"
- Network-isolated sandbox: A restricted environment without internet access used to control evidence exposure. "inside a network-isolated sandbox"
- Non-convergence: Failure of an agent run to reach a final, correct answer within constraints. "failure modes such as non-convergence"
- Offline constraints: Limitations arising from operating without live web access and using only pre-cutoff data. "under fixed offline constraints"
- Offline sandbox: A local, network-disabled environment containing the frozen evidence for tasks. "placed in an offline sandbox"
- Parametric-only forecasting: Making predictions using only the model’s internal parameters, without external tools. "This tests parametric-only forecasting ability."
- PoT (Proof of Time): A time-partitioned, semi-verifiable benchmarking framework linking judgments to future signals. "We introduce PoT, a semi-verifiable benchmarking framework"
- Post-cutoff evaluation: Scoring predictions against outcomes that occur after a designated time cutoff. "Post-cutoff evaluation can materially change conclusions about model performance"
- Pre-cutoff: The time window before the benchmark’s cutoff when evidence is frozen. "pre-cutoff snapshot of evidence"
- Prospectively verifiable: Targets that can be checked once future outcomes become available. "(ii) defining targets that are prospectively verifiable as time passes."
- ReAct: An agent paradigm that interleaves reasoning and acting steps. "All agentic runs use a single-agent ReAct loop"
- Scientometrics: Quantitative analysis of scientific literature and impact. "Scientometrics has long studied how papers accrue impact over time"
- Semi-verifiable: Using verifiable signals as proxies for constructs that are not directly observable. "We call PoT semi-verifiable because the benchmark uses verifiable downstream outcomes as imperfect proxies for idea quality."
- SOTA (State of the Art): The best-known performance on a benchmark at a given time. "The SOTA task measures whether solvers can reason about frontier model performance and the pace of benchmark progress."
- State tracking: Maintaining and updating task-relevant information across multi-step interactions. "success depends on multi-step interaction, state tracking, and adherence to constraints."
- Structured prompt: A prompt that prescribes explicit steps or policies for agent behavior. "the structured agent prompt has family-dependent effects."
- Taxonomy: A structured categorization of fields or topics used for classification. "choose from a fixed taxonomy"
- Test-time compute: The computational resources or interactions used during inference. "corresponding to low, medium, and high test-time compute."
- Time-indexed: Tied to specific points in time, affecting what can be known or predicted. "Many consequential scientific questions are intrinsically time-indexed"
- Time-partitioned: Split by time to separate training-era evidence from future outcomes. "we formalize PoT as a time-partitioned benchmark design"
- Tool-using agents: Agents that invoke external tools (e.g., bash, python) to process evidence and reason. "comparing tool-using agents to non-agent baselines"
- Zero-shot: Producing answers without task-specific examples, tools, or additional context. "Zero-shot (direct generation)."
Collections
Sign up for free to add this paper to one or more collections.

