A Brain-like Synergistic Core in LLMs Drives Behaviour and Learning
Abstract: The independent evolution of intelligence in biological and artificial systems offers a unique opportunity to identify its fundamental computational principles. Here we show that LLMs spontaneously develop synergistic cores -- components where information integration exceeds individual parts -- remarkably similar to those in the human brain. Using principles of information decomposition across multiple LLM model families and architectures, we find that areas in middle layers exhibit synergistic processing while early and late layers rely on redundancy, mirroring the informational organisation in biological brains. This organisation emerges through learning and is absent in randomly initialised networks. Crucially, ablating synergistic components causes disproportionate behavioural changes and performance loss, aligning with theoretical predictions about the fragility of synergy. Moreover, fine-tuning synergistic regions through reinforcement learning yields significantly greater performance gains than training redundant components, yet supervised fine-tuning shows no such advantage. This convergence suggests that synergistic information processing is a fundamental property of intelligence, providing targets for principled model design and testable predictions for biological intelligence.
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Overview of the Paper
This academic paper explores how LLMs, which are complex computer programs designed to understand and generate human-like text, develop a component that works in a way similar to specific parts of the human brain. The authors are interested in understanding how these models learn and behave, and they find that certain parts of the models—specifically the "middle layers"—are essential for processing information in a unique way that helps them understand complex tasks.
Key Objectives
The main goal of the research is to see if LLMs, during their training process, form what the authors call a "synergistic core." This is a part of the model where information is not just added together but combined in a way that makes the whole model smarter than just the sum of its parts, similar to how different parts of our brains work together to think and solve problems.
Research Methods
To understand how LLMs process information, the researchers use a concept called "information decomposition." Imagine breaking down a word problem in math: instead of just looking at the numbers separately (like the inputs to a model), you also consider how they interact together to give you the answer (the model's output). The researchers measure how different parts of the LLMs work together in this way, using a special mathematical tool called Partial Information Decomposition (PID).
Main Findings
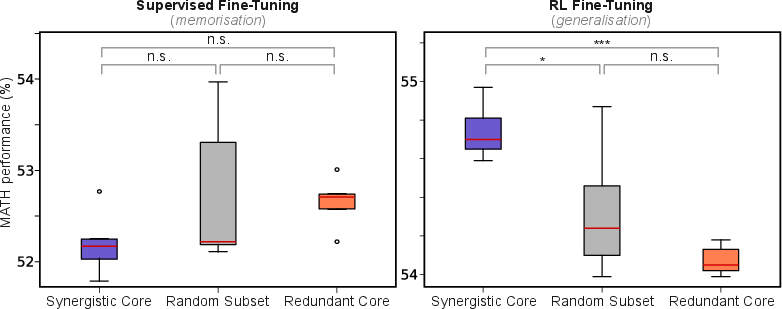
The study finds that the middle layers of these LLMs are crucial for combining information in a special way, which helps the models perform better. When these middle layers are damaged or removed, the models do not work as well. This finding is important because it helps us understand what parts of the model are most important for learning and adapting to new tasks. Moreover, training these key model parts with focused techniques can improve the model's performance significantly.
Implications of the Research
The results of this study suggest that to make smarter artificial intelligence systems, we should pay close attention to how information is combined in the models, especially in the middle layers. This understanding can lead to better-designed AI systems and help improve the way they are trained. Additionally, by comparing these findings to how human brains work, scientists can develop new predictions and theories about both artificial and natural intelligence. This research also opens up new pathways for developing AI with better generalization capabilities, helping machines learn in more flexible and sophisticated ways.
Knowledge Gaps
Below is a single, concrete list of knowledge gaps, limitations, and open questions the paper leaves unresolved. Each item is framed to be actionable for future research.
- Extend information decomposition beyond attention heads and MoE experts to include MLP/FFN layers and neurons, assessing whether synergistic cores also exist in feed-forward components and how they contribute to knowledge storage and reasoning.
- Replace the L2 norm proxy for “activation” with richer representations (e.g., full head output vectors, attention weights, principal components, cosine similarities) and compare whether synergy/topology results are robust to the choice of activation metric.
- Specify and evaluate the statistical estimators used for PID/ΦID (e.g., Gaussian assumptions vs nonparametric), report confidence intervals/significance tests, and assess estimator bias given short sequences (100 tokens) and high dimensionality.
- Move beyond pairwise analysis: quantify multivariate synergy among larger sets of heads/experts using higher-order PID/ΦID, and test whether the “core” changes location or strength when multi-source interactions are included.
- Apply local (pointwise) PID/ΦID to identify exactly when and where synergistic integration occurs at the token/timestep level, and link those moments to specific behaviors (e.g., reasoning steps, tool use, long-range dependencies).
- Characterize task dependence of the synergistic core: measure per-category and per-prompt variability, include OOD tasks, longer contexts, variable temperatures/decoding strategies, and test whether synergy intensifies for tasks requiring integration (e.g., multi-hop reasoning).
- Evaluate on standard large-scale benchmarks (e.g., GLUE/SuperGLUE, MMLU, BIG-bench, multilingual corpora) to correlate synergy metrics with widely used performance indicators and generalization scores across domains and languages.
- Establish scaling laws: quantify how the magnitude and layer position of the synergistic core vary with depth, width, parameter count, and training data size across model families and sizes.
- Broaden architectural coverage: test state-space models, RNNs, transformers with alternative attention mechanisms (e.g., linear/flash attention), and multiple MoE designs to determine whether synergistic cores are architecture-agnostic.
- Track synergy throughout full pretraining (not only fine-tuning): measure its emergence trajectory across checkpoints, relate it to loss curves and learning rate schedules, and test whether synergy-targeted regularization or curricula accelerate generalization.
- Strengthen causal links between synergy and performance: correlate synergy metrics with generalization-centric scores across diverse tasks; perform systematic ablations/perturbations with matched confounds to quantify effect sizes on accuracy rather than KL alone.
- Control for potential confounds in synergy ranking (e.g., head norm/magnitude, connectivity degree, residual pathways, MoE routing frequency), and demonstrate that synergy captures more than “importance” or activity level.
- Exploit the full ΦID lattice: analyze directional atoms (e.g., Syn→Unq, Unq→Red) to probe causal transformation of information types across time and layers, rather than focusing solely on Syn→Syn and Red→Red.
- Test robustness of graph-theoretic conclusions to edge thresholding and weighting choices (e.g., using full weighted networks vs top-k edges), and report sensitivity analyses for global efficiency and modularity estimates.
- Generalize synergy-targeted RL fine-tuning: replicate across models, rewards (sparse/dense), tasks beyond math (coding, planning, multimodal), and response formats (CoT vs non-CoT); quantify sample efficiency, stability, and reproducibility.
- Re-examine supervised fine-tuning: use SFT datasets that require genuine generalization (synthetic algorithmic tasks, compositional generalization) to test whether synergy-targeted updates become beneficial outside memorization-heavy regimes.
- Validate synergy-aware compression: design pruning/distillation pipelines that preserve synergistic components, compare against magnitude/entropy pruning, and measure trade-offs in size, speed, and generalization.
- Link to mechanistic circuits: test overlap between high-synergy heads and known circuits (e.g., induction heads), use sparse autoencoders or causal tracing to uncover the features and algorithms realized by synergistic units.
- Investigate multilingual and multimodal synergy: measure whether core location/strength differs across languages/scripts, and extend analysis to vision–language or speech–LLMs to test cross-modal integration hypotheses.
- Provide richer developmental analyses: evaluate more training checkpoints across multiple model families, quantify relationships between synergy formation and optimizer dynamics, data diversity, and emergent capabilities (e.g., in-context learning).
- Compare how PID/ΦID atoms change under RLFT vs SFT: track shifts in Syn→Syn and other atoms during training to directly test the claim that RL preferentially enhances synergistic integration.
- Map fragility precisely: identify minimal perturbations to synergistic components that selectively degrade specific capabilities (e.g., multi-step arithmetic, multi-hop QA), and quantify resilience in redundant regions.
- Account for MoE routing effects: measure synergy conditioned on expert activation probability and top-k routing, distinguish between active/inactive experts, and analyze whether the core reflects gating behavior rather than information integration.
- Scale ΦID to large models: develop approximate or sampling-based estimators for synergy that retain accuracy while reducing compute, and benchmark their fidelity against exact methods.
- Improve reproducibility: report seeds, variance across runs/prompts, cross-implementation consistency, and create an open protocol/dataset for synergy evaluation to enable independent replication.
- Test biological predictions directly: design AI tasks mirroring default-mode/executive functions, and collaborate with neuroscience to measure whether RL-like learning increases brain synergy and whether stimulation of synergistic regions selectively impairs transfer/generalization.
Practical Applications
Below are practical, real-world applications derived from the paper’s findings, methods, and innovations. Each item lists candidate sectors, an actionable use case, potential tools/products/workflows, and key assumptions or dependencies.
Immediate Applications
- Sector(s): Software/AI, Education, Finance, Robotics
- Action: Parameter-efficient RL fine-tuning that targets the synergistic core
- Tools/Workflows: Identify top-k synergistic heads/experts via ΦID; freeze redundant components; run R1/GRPO-style RLFT with higher learning rates or update frequency on synergistic units; checkpoint selection via synergy metrics
- Assumptions/Dependencies: Access to internal activations and model weights; synergy ranking is stable across task domains; RL rewards available (or proxy rewards/implicit feedback)
- Sector(s): Mobile/Edge, Energy/Cloud Cost Optimization, Consumer Devices
- Action: Synergy-preserving compression and precision scheduling
- Tools/Workflows: Aggressive quantization/pruning on redundant periphery; maintain higher precision/bandwidth/cache on synergistic middle layers; synergy-aware quantization configs integrated into inference runtimes
- Assumptions/Dependencies: Synergy maps computed for the target model/task; accuracy budgets defined; inference stack allows per-layer precision control
- Sector(s): AI Safety, Compliance, Evaluation
- Action: Targeted ablation and red-teaming focused on synergistic components
- Tools/Workflows: Use synergy ranking to select ablation targets; measure behavior divergence (token-level KL) between original and ablated models; add “synergy fragility tests” to red-team protocols
- Assumptions/Dependencies: Internal access to heads/experts; safe deployment sandbox; alignment with organization’s risk taxonomy
- Sector(s): MLOps, Training Platforms
- Action: Training diagnostics and early-stopping based on emergence of a synergistic core
- Tools/Workflows: Periodic ΦID-based synergy tracking during pretraining/fine-tuning; trigger early-stopping or schedule changes (e.g., curriculum shift, LR decay) when an inverted-U synergy profile stabilizes
- Assumptions/Dependencies: Compute budget for periodic analysis; synergy metrics correlate with downstream generalization for the target domain
- Sector(s): AI Dev/Interpretability, Academia
- Action: Synergy dashboards for model introspection
- Tools/Workflows: “SynergyScope” dashboard to visualize synergy/redundancy heatmaps by layer/head/expert; overlay on attention graphs; export synergy-aware model cards
- Assumptions/Dependencies: Acceptable overhead to compute ΦID (or approximations); reproducibility across seeds and prompts
- Sector(s): Cloud AI, Systems, MoE Serving
- Action: Router/gating tuning in MoE to prioritize high-synergy experts
- Tools/Workflows: Route more tokens or allocate larger expert budgets to synergistic experts; incorporate synergy priors into router training or load-balancing heuristics
- Assumptions/Dependencies: MoE architecture with configurable router; synergy measures computed at expert granularity
- Sector(s): Systems/Hardware, Inference Runtimes
- Action: Runtime scheduling that prioritizes the synergistic core
- Tools/Workflows: Allocate memory bandwidth and compute to mid-layer “synergy hubs”; pin synergistic layers to faster devices; apply activation checkpointing asymmetrically
- Assumptions/Dependencies: Programmable inference stack; synergy layout stable across inputs
- Sector(s): Academia/Benchmarking, AI Evaluation
- Action: Generalization-centric evaluation built around synergy
- Tools/Workflows: Introduce benchmarks/tasks that stress multi-source integration; compare SFT vs RLFT improvements conditioned on synergy-targeted updates; track synergy–accuracy coupling
- Assumptions/Dependencies: Public datasets with OOD splits; community acceptance of information-decomposition metrics
- Sector(s): Education/EdTech
- Action: Reasoning-focused tutoring models via synergy-targeted RLFT
- Tools/Workflows: Fine-tune math/logic tutors by updating synergistic heads; distill reasoning traces into RL signals; deploy low-latency versions using synergy-preserving compression
- Assumptions/Dependencies: Access to high-quality rewards or synthetic preference signals; guardrails for CoT usage and privacy
- Sector(s): Enterprise/Vertical AI (Legal, Support, Analytics)
- Action: Domain adaptation that updates synergistic components first
- Tools/Workflows: For reasoning-heavy workflows (triage, summarization with constraints, multi-document QA), run RLFT on synergistic heads; validate with task-specific generalization tests
- Assumptions/Dependencies: Reward design and coverage; monitoring for unintended regressions in memorization-heavy tasks
- Sector(s): Neuroscience/Clinical Research (Academia)
- Action: Translational experiments testing RL vs SFT effects on brain synergy
- Tools/Workflows: fMRI-based PID/ΦID analyses on subjects trained with RL-like tasks vs supervised practice; TMS/EEG to probe predicted fragility of high-synergy regions
- Assumptions/Dependencies: Access to imaging and stimulation facilities; ethics approvals; statistical power for PID estimates
- Sector(s): Governance/Policy
- Action: Transparency artifacts that include synergy maps and fragility summaries
- Tools/Workflows: Add “synergy topology” to model cards; document performance sensitivity to synergy-targeted lesions; include synergy-aware red-team results in assurance reports
- Assumptions/Dependencies: Policy makers/regulators accept such metrics; organizations can disclose internal analyses without IP leakage
Long-Term Applications
- Sector(s): Software/AI, Research
- Action: Synergy-regularized objectives and optimizers in pretraining
- Tools/Workflows: Add regularizers that promote persistent synergy in mid-layers; curriculum that gradually increases integration demands; layerwise LR schedules tuned by synergy
- Assumptions/Dependencies: Scalable ΦID surrogates to keep training overhead low; empirical validation that synergy promotion causally improves OOD generalization
- Sector(s): AI Architecture, Scaling Strategy
- Action: Model designs that concentrate capacity and connectivity in synergistic layers
- Tools/Workflows: Allocate more parameters/interconnects to middle layers; architect global “workspace” modules with high global efficiency; design skip/routing favoring integration
- Assumptions/Dependencies: Replication across tasks/modalities; co-design with training pipelines to avoid optimization instabilities
- Sector(s): Hardware/Systems, Cloud
- Action: Synergy-aware hardware and memory hierarchy co-design
- Tools/Workflows: Accelerators and interconnects optimized for mid-layer bandwidth/latency; schedulers that co-locate synergy hubs; profiling tools that map synergy to hardware counters
- Assumptions/Dependencies: Stable synergy topology across models; compelling performance-per-watt gains in production workloads
- Sector(s): Distillation/Compression
- Action: “Synergy-matching” knowledge distillation
- Tools/Workflows: Add losses that preserve teacher’s synergy structure in student models; prioritize teacher signals from synergistic heads during distillation
- Assumptions/Dependencies: Reliable ways to estimate synergy locally and differentiate through; student capacity sufficient to realize integrated representations
- Sector(s): Safety/Robustness, Governance
- Action: Standards for synergy-based risk assessment and audit
- Tools/Workflows: Require synergy fragility tests; certify synergy-preserving updates; mandate reports on synergy–capability coupling for high-stakes systems
- Assumptions/Dependencies: Multi-stakeholder consensus; reproducible, validated methodologies for PID/ΦID at scale
- Sector(s): Robotics/Autonomy, Multimodal Systems
- Action: Synergy-targeted RL for sensor fusion and policy generalization
- Tools/Workflows: Identify/strengthen integration modules across vision, proprioception, language; update synergistic components under RL; deploy synergy-preserving compression to embedded platforms
- Assumptions/Dependencies: Robust multimodal ΦID estimators; well-specified reward signals; safety-certified training and evaluation
- Sector(s): Healthcare/Neuroscience
- Action: Synergy-informed diagnostics and interventions
- Tools/Workflows: Use brain synergy maps as biomarkers (e.g., consciousness disorders, neurodegeneration); explore closed-loop stimulation targeting synergy cores to restore integration
- Assumptions/Dependencies: Clinical trials; longitudinal datasets; regulatory approvals and safety validation
- Sector(s): Personalization/Privacy
- Action: Federated, on-device synergy adaptation for user-specific reasoning needs
- Tools/Workflows: Local RLFT on synergistic core using privacy-preserving rewards; server-side aggregation of synergy updates
- Assumptions/Dependencies: Efficient on-device ΦID proxies; privacy constraints and acceptance of federated signals
- Sector(s): Fairness/Responsible AI
- Action: Bias mitigation via synergy-centric generalization training
- Tools/Workflows: Emphasize integration over spurious single-source cues; evaluate fairness/OOD parity conditioned on synergy growth; add penalties for reductive reliance
- Assumptions/Dependencies: Empirical confirmation that higher synergy reduces spurious correlations across domains; careful metric design to avoid unintended trade-offs
- Sector(s): Interpretability/Tooling
- Action: Local (pointwise) PID tools for multi-head circuit discovery
- Tools/Workflows: Token/time-step level synergy detectors; rank prompts and positions where high-order interactions drive outputs; guide causal tracing and patching
- Assumptions/Dependencies: Efficient local estimators; integrations with circuit analysis frameworks (e.g., sparse autoencoders, causal scrubbing)
- Sector(s): Data/Training Strategy
- Action: Integration-centric curricula and data selection
- Tools/Workflows: Curate tasks that require combining multiple knowledge sources; active data selection to maximize incremental synergy; stage-wise training where early redundancy is followed by enforced integration
- Assumptions/Dependencies: Reliable online synergy estimates; guardrails to avoid catastrophic interference
- Sector(s): Resilience/Operations
- Action: Dual-mode deployment that trades generalization for robustness
- Tools/Workflows: “Graceful degradation” by throttling or sandboxing the fragile synergistic core under adversarial or constrained conditions; fallback to redundant periphery for safe baseline behavior
- Assumptions/Dependencies: Policy definitions for when to switch modes; monitoring to detect adversarial conditions
Notes on assumptions and dependencies that broadly apply
- Computing ΦID/PID at scale can be costly; practical deployments may rely on approximations, downsampling, or proxy features (e.g., activation norms) and should validate stability across seeds/prompts.
- Access to internal activations/weights is required for most applications; hosted black-box APIs limit feasibility unless providers expose synergy telemetry.
- The paper’s strongest causal results are demonstrated for math/RLFT settings; cross-domain generality (e.g., code, multimodal, dialogue safety) should be empirically verified.
- Synergy topology may shift under heavy quantization, pruning, or distillation; pipelines should re-measure synergy post-transformation.
- For neuroscience and clinical applications, ethical approvals, safety protocols, and replication are prerequisites.
Glossary
- Ablation: The experimental removal or deactivation of model components to assess their functional impact. "Ablating the synergistic core causes greater changes in behaviour and drops in performance."
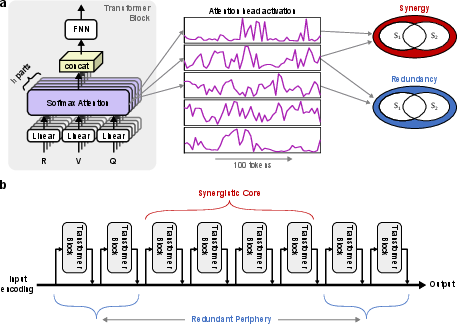
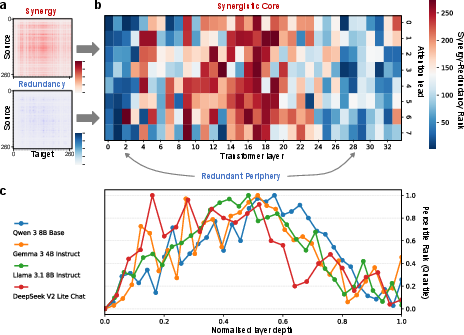
- Attention head: A subcomponent of a transformer’s attention mechanism that independently computes attention over inputs. "Heatmaps showing synergy and redundancy between pairs of attention heads in Gemma 3 4B."
- Attention output vector: The vector produced by an attention head after applying attention weights to value vectors. "define its activation as the L2 norm of its attention output vector"
- Autoregressive generation step: A discrete timestep in sequence generation where the model predicts the next token based on previous tokens. "We define each autoregressive generation step explicitly as a discrete timestep"
- Behaviour divergence: A task-agnostic measure of how much an intervention changes a model’s output distribution. "Behaviour divergence as a function of the fraction of nodes deactivated (experts for DeepSeek V2 Lite and attention heads for the remaining models)"
- Chain-of-Thought (CoT): A prompting and response style where models explicitly produce intermediate reasoning steps. "non-Chain-of-Thought (non-CoT) response format."
- Detokenisation: The transformation from token-level representations to higher-level internal features in early layers. "early layers perform detokenisation, late layers perform tokenisation, while middle layers handle high-level computation"
- Downward causation: An information-dynamic transformation where synergistic source information becomes unique in a target. "We denote this as and corresponds to the notion of downward causation."
- Gaussian noise: Random perturbations drawn from a normal distribution used to disrupt parameters. "injecting Gaussian noise into the query/output projections of selected attention heads"
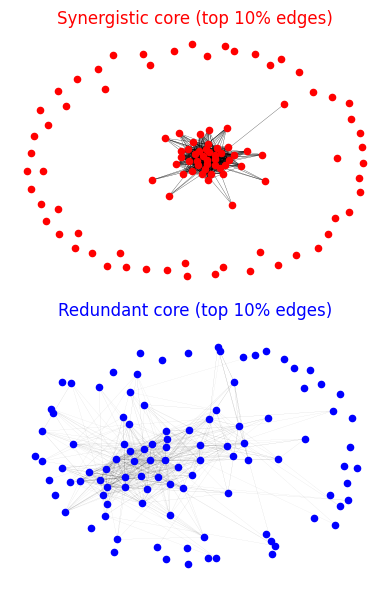
- Global efficiency: A graph-theoretic metric capturing how efficiently information can be integrated across a network. "the synergistic core exhibits greater global efficiency consistently across all examined models"
- Global workspace: A hypothesized integrative cognitive network where disparate information streams converge. "associated with complex cognition and a `global workspace' where different information streams converge"
- GRPO: A reinforcement learning optimization method used for post-training. "using GRPO \cite{shao2024deepseekmathpushinglimitsmathematical} on the MATH train set"
- Hedges' g: An effect size measure indicating standardized differences in performance. "Hedges' "
- Integrated Information Decomposition (ΦID): An extension of PID that decomposes information dynamics across time and multiple targets. "Applying Integrated Information Decomposition (ID) -- an extension of PID to temporal dynamics --"
- Kullback–Leibler (KL) divergence: A measure of divergence between two probability distributions. "the Kullback-Leibler (KL) divergence between the resulting distributions"
- L2 norm: The Euclidean norm of a vector, used here to quantify head or expert activation magnitude. "we record the L2 norm of attention outputs for each head across all response tokens."
- Lattice of information atoms: The structured set of all temporal PID atoms describing information transformations. "introduces temporal combinations of PID atoms which form the lattice of information atoms."
- Min-max scaling: Normalization that rescales values to a fixed range, typically [0,1]. "the synergy-redundancy rank is normalised using min-max scaling to enable comparisons across models of different sizes."
- Mixture-of-Experts (MoE): An architecture where multiple expert modules are selectively routed for computation. "mixture-of-experts (MoE) modules as information-processing units"
- Modularity: A graph-theoretic property measuring the degree to which a network is partitioned into cohesive communities. "the redundant core consistently demonstrates higher modularity"
- Mutual information: An information-theoretic quantity that measures dependency between random variables. "the mutual information between random variables and quantifies the amount of information shared"
- Out-of-distribution (OOD) generalization: The ability to perform well on data that differ from the training distribution. "intermediate layers are specifically responsible for out-of-distribution (OOD) generalization"
- Partial Information Decomposition (PID): A framework that decomposes information into redundant, unique, and synergistic components. "Partial Information Decomposition (PID) formalises this by distinguishing three fundamental information types"
- Polysemantic features: Representations that entangle multiple distinct concepts within a single feature. "the use of sparse autoencoders to disentangle polysemantic features"
- Query-projection: The linear projection that maps hidden states to query vectors in attention heads. "noise is applied to the query-projection rows and output-projection columns associated with each head"
- R1-style post-training: A reinforcement learning post-training regimen emphasizing reasoning improvements. "We investigate the RL setting using R1-style post-training"
- Reinforcement Learning Fine-Tuning (RLFT): Post-training where rewards guide parameter updates to improve behavior and generalization. "reinforcement learning fine-tuning (RLFT)"
- Redundancy: Information accessible independently from multiple sources; often linked to robustness rather than integration. "early and late layers rely on redundancy"
- Redundant core: Network subgraph dominated by redundant interactions, typically more modular and specialized. "the redundant core consistently demonstrates higher modularity"
- Sparse autoencoders: Models that learn sparse latent representations to disentangle features. "the use of sparse autoencoders to disentangle polysemantic features"
- Superposition: The phenomenon where multiple features share the same representational subspace. "the study of superposition"
- Supervised fine-tuning (SFT): Post-training using labeled examples, often associated with memorization rather than generalization. "supervised fine-tuning (SFT)"
- Synergy: Information that emerges only from jointly observing multiple variables, not present in any alone. "the information-theoretic construct of synergy -- information available only through joint observation of multiple variables --"
- Synergistic core: The subset of components with predominantly synergistic interactions, typically located in middle layers. "LLMs contain a ``synergistic core'' in their middle layers,"
- Temporally persistent synergy: A ΦID atom capturing synergy that remains synergistic across time steps. "using the temporally persistent synergy () and temporally persistent redundancy () atoms"
- Time-Delayed Mutual Information (TDMI): Mutual information measured between present sources and future targets to capture dynamics. "Time-Delayed Mutual Information (TDMI)"
- Undirected weighted networks: Graphs without edge direction where edges carry weights representing interaction strength. "as the weights of undirected weighted networks"
Collections
Sign up for free to add this paper to one or more collections.

