- The paper presents a SIMD-enabled repair algorithm for ill-formed UTF-16 surrogate pairs, achieving notable throughput improvements.
- It uses parallel mask comparisons and branchy logic to efficiently replace orphaned surrogates with the Unicode replacement character.
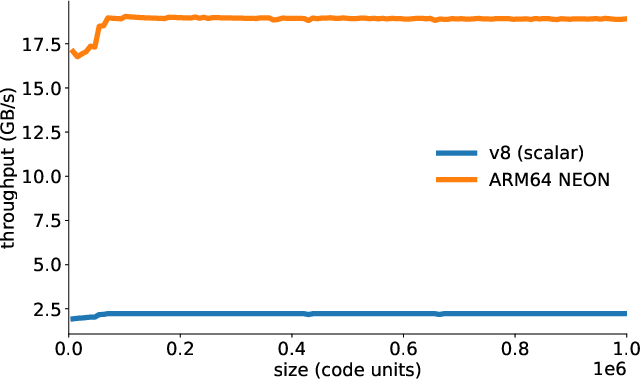
- Experimental results show up to 18.9GB/s on ARM and 7.5–7.8GB/s on x64, vastly outperforming traditional scalar methods.
Introduction
UTF-16 remains a ubiquitous Unicode encoding across major platforms such as Windows, Java, and ECMAScript engines, employing surrogate pairs (high/low surrogate code units) for characters outside the BMP. Ill-formed surrogate pairs, encountered due to data corruption, erroneous transcoding, or hostile input, can undermine both security and reliability in applications. Many environments, notably JavaScript, require transforming ill-formed UTF-16 sequences into well-formed ones by replacing orphaned surrogates with the Unicode replacement character (U+FFFD).
This work presents a SIMD-enabled algorithm for rapid identification and correction of ill-formed UTF-16 surrogates on both x64 (SSE2, AVX2, AVX-512) and ARM NEON architectures. The implementation is part of simdutf and has been deployed in V8, impacting high-throughput scenarios in web browsers.
The utility of SIMD for Unicode transcoding and validation is established. SIMD-based algorithms have enabled near-memory bandwidth UTF-8 validation [keiser2021validating] and efficient transcoding pipelines [lemire2022transcoding, clausecker2023transcoding], but these works do not address in-place UTF-16 surrogate correction. Scalar implementations remain in ICU and Boost, while recent work investigates SIMD validation for related encodings like CESU-8 [schroder2024validating].
This work is distinguished by a focus on robust SIMD-based correction rather than mere validation and by targeting the surrogate structure specific to UTF-16, achieving in-place and copy-based operation with branchy acceleration for the dominant well-formed input case.
SIMD Algorithm Overview
The proposed algorithm segments the UTF-16 input into aligned blocks (8 to 32 code units, dependent on vector register width). For each block, two overlapping vectors are loaded: the "lookback," offset by -1, and the current block. The algorithm uses parallel comparisons to produce binary masks indicating high surrogates in the lookback and low surrogates in the current block.
A bitwise XOR between these masks flags mismatches—a high surrogate not followed by a low surrogate, or a low surrogate without a preceding high surrogate. Only if the XOR detects an anomaly, expensive fix-up logic is triggered: indices with illegal sequence are selectively overwritten with U+FFFD; otherwise, the block is copied as-is.
(Figure 1)
Figure 1: Example of mask-based SIMD detection and correction of illegal surrogate pairs in a 512-bit block.
This method is branchy: it skips the fix-up path for well-formed input, minimizing the hot-path cost. As a corollary, tail handling for misaligned input and short sequences falls back to scalar routines.
AVX-512 and x64 Implementation
On recent Intel/AMD CPUs, AVX-512 enables block sizes of 32 code units (64 bytes), with direct mask register support. Early SIMD families (SSE2, AVX2) yield similar logic with smaller blocks and movemask aggregations for extracting lanewise results. Architectural specifics, including dual unaligned loads and absence of loop-carried dependencies, are tuned for throughput on wide-issue out-of-order cores. Notably, mask-driven blends and masked stores further minimize shuffle overhead when correcting.
ARM NEON Implementation
ARM NEON is constrained to 128-bit vectors (8 code units) but compensates with high instruction-level parallelism (e.g., Apple M1 Firestorm). Unique to NEON, the LD2 family of instructions enables deinterleaving of high bytes, so that high/low surrogate ranges can be detected in parallel via bytewise comparisons rather than full 16-bit operations, doubling the element throughput per cycle. The fix-up path amortizes the cost of vector-to-scalar reduction (e.g., via vmaxvq_u32) over larger concatenated chunks (64 code units) before branching for rare corrections.
Experimental Evaluation
The evaluation suite benchmarks throughput (GB/s), instructions per byte, and instructions per cycle across Apple Silicon (M4/Aarch64) and Intel Xeon (Icelake, Haswell, Westmere), with both near-perfect and adversarially-mismatched surrogate occurrence rates.
Across million-unit string workloads, SIMD implementations deliver substantial acceleration:
These results confirm that vectorized correction outpaces scalar approaches by an order of magnitude in practical, browser-relevant settings, at near-peak memory bandwidth.
Practical and Theoretical Implications
Practical
The SIMD-based UTF-16 correction routine is now integral to major JS engines (V8), relevant to all ECMAScript host environments, offering robust and low-latency string sanitization in real-world browsing and server applications. The architecture-specific logic is generalizable for adoption in any processing pipeline that normalizes or repairs UTF-16 inputs, e.g., text databases, network-driven content servers, or any scenario where string well-formedness is a hard requirement at the ABI or API boundary.
Theoretical
The work illustrates the value of branchy SIMD logic in the low-error regime, where short-circuiting expensive paths is effective. The chosen data-parallel design guarantees that SIMD width extension correlates directly to increased throughput, provided downstream bandwidth is not a bottleneck—a critical result for high-performance I/O-bound Unicode processing.
Future Directions
The approach can be extended to other SIMD architectures (e.g., SVE/SVE2 on ARM, PowerPC VMX/VSX), higher-level encodings (UTF-32, CESU-8), or even out-of-place repair algorithms. Further, integrating SIMD-based correction into fast transcoding paths (e.g., simultaneous well-formedness check and UTF-16 → UTF-8 conversion) would yield highly-efficient, universal string pipelines suited to heterogeneous cloud backends.
Potential also exists for combining vectorized correction with hardware-specific features (e.g., prefetching, gather/scatter) as newer CPU generations continue to expand vector widths and execution resources.
Conclusion
This work establishes that SIMD acceleration for UTF-16 well-formedness correction is not only feasible but production-ready. The deployed algorithms achieve up to 18.9 GB/s on ARM and 7.5–7.8 GB/s on x64, rendering them an order of magnitude faster than scalar baselines. The technique is broadly applicable wherever UTF-16 surrogate sanitization is required, and generalizes well to future SIMD extensions and Unicode pipeline design (2601.06349).