Learning and Testing Exposure Mappings of Interference using Graph Convolutional Autoencoder
Published 9 Jan 2026 in econ.EM | (2601.05728v1)
Abstract: Interference or spillover effects arise when an individual's outcome (e.g., health) is influenced not only by their own treatment (e.g., vaccination) but also by the treatment of others, creating challenges for evaluating treatment effects. Exposure mappings provide a framework to study such interference by explicitly modeling how the treatment statuses of contacts within an individual's network affect their outcome. Most existing research relies on a priori exposure mappings of limited complexity, which may fail to capture the full range of interference effects. In contrast, this study applies a graph convolutional autoencoder to learn exposure mappings in a data-driven way, which exploit dependencies and relations within a network to more accurately capture interference effects. As our main contribution, we introduce a machine learning-based test for the validity of exposure mappings and thus test the identification of the direct effect. In this testing approach, the learned exposure mapping is used as an instrument to test the validity of a simple, user-defined exposure mapping. The test leverages the fact that, if the user-defined exposure mapping is valid (so that all interference operates through it), then the learned exposure mapping is statistically independent of any individual's outcome, conditional on the user-defined exposure mapping. We assess the finite-sample performance of this proposed validity test through a simulation study.
The paper introduces a novel framework using graph convolutional autoencoders to learn data-driven exposure mappings for network interference.
The methodology leverages a conditional independence test and doubly robust estimation to validate and estimate causal effects.
Simulation results demonstrate reduced bias and high test power, emphasizing practical improvements in causal inference for complex networks.
Learning and Testing Exposure Mappings of Interference Using Graph Convolutional Autoencoders
Introduction and Motivation
This paper addresses fundamental issues in causal inference under interference—where the outcome of an individual depends not only on their own treatment but also on the treatments administered to others in an observed network. Classical assumptions such as the Stable Unit Treatment Value Assumption (SUTVA) are violated in such contexts, as interference or spillover effects propagate through network connections. The central concept of exposure mapping, which summarizes how network neighbors' treatments affect an individual's outcome, underpins identification strategies for direct and interference effects.
Traditional approaches prespecify exposure mappings a priori, which can result in misspecification, particularly in networks with complex or unknown interference patterns. This work leverages graph convolutional autoencoders (GCAs) to learn exposure mappings directly from networked observational data, facilitating the discovery of complex, data-driven summaries of interference. Crucially, the study introduces a conditional independence-based testing procedure: the learned mapping is used as a statistical instrument to test the sufficiency of a user-defined mapping. This instrumentally motivated framework enables rigorous validation of exposure mapping assumptions critical to identification.
Causal Framework and Identification Under Interference
Let Di be the treatment for individual i, D−i the treatments for all other individuals, and Yi the outcome. In the presence of network-based interference, potential outcomes Yi(d,d) depend on both i's treatment and the network-assigned treatments d.
Exposure mapping abstracts the effect of the network into a lower-dimensional statistic Zi=F(A,D−i,X−i), where A denotes the adjacency matrix of the network, and X−i denotes covariates of others. The key identification approach involves functional restrictions on the exposure mapping and conditional independence assumptions for consistent estimation of direct, interference, and total effects:
The assignment mechanism is separable: Di depends only on Xi;
Conditional exogeneity: Yi(d,z) is independent of (Di,Zi) given observed covariates and the network.
Under positivity (common support), these conditions enable identification via inverse probability weighting (IPW) using a joint propensity score for (Di,Zi).
Learning Flexible Exposure Mappings with Graph Convolutional Autoencoders
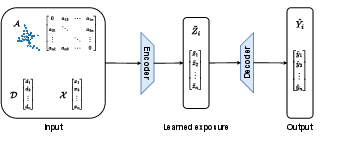
The true functional form of exposure mapping, especially in realistic networks, is typically unknown and may be of high or even unstructured complexity. The proposed approach replaces hand-crafted mappings with exposure mappings learned as node embeddings from a GCA. The encoder comprises graph convolutional layers that aggregate information from each node's neighbors (excluding self-loops) and their covariates and treatments. This architecture inherently aligns with the statistical nature of interference, as the learned embedding for an individual summarizes how their network neighbors' treatments and characteristics relate to the observed outcomes.
The decoder is a regression layer mapping the node embeddings to outcomes, trained via a mean squared error loss (appropriate for continuous outcomes).
Figure 2: Graph convolutional autoencoder architecture, with the encoder aggregating treatment and covariate information from network neighbors and the decoder predicting outcomes.
This structure ensures that the learned exposure for individual i is a function solely of neighbors' treatments and covariates, operationalizing the required exclusion restrictions for causal inference.
Statistical Testing of Exposure Mapping Validity
A critical issue is the correctness of the exposure mapping: does a simple user-defined mapping, Z˙i, capture all network interference inducing variation in Yi? The authors introduce a conditional independence-based statistical testing framework that leverages the GCA-learned mapping Z~i as an instrument.
The central implication is: if Z˙i captures all relevant interference, then, conditional on Z˙i, the learned mapping Z~i must be independent of Yi. Any conditional association remaining implies misspecification of the user-defined mapping. Formally, the test evaluates whether
E[Yi∣Z˙i=z˙i,Z~i=z~i]=E[Yi∣Z˙i=z˙i]
for all (z˙i,z~i).
This is operationalized via a global L2-type test statistic, estimated in a double machine learning (DML) framework with asymptotic normality and n-consistency under suitable regularity. If the null hypothesis of conditional independence is rejected, the researcher-defined mapping is inadequate, necessitating replacement with the machine-learned (possibly less interpretable) mapping.
Doubly Robust Estimation of Causal Parameters
For estimation, the procedure integrates both IPW and outcome regression estimators in a doubly robust (DR) framework, ensuring consistency if either model component is correctly specified. All propensity models and conditional expectation functions are estimated via appropriate machine learning workflows—logistic regression for binary treatments, and GNN/GCA models for network-dependent exposures.
Implementation relies on
user-defined or learned exposure mapping, dictated by the aforementioned testing procedure,
consistent estimation of propensity scores, including those conditioned on embeddings for flexible (possibly non-discrete) learned exposures,
DML-based Neyman-orthogonal score construction for inference on causal estimands (average direct, interference, and total effects).
Simulation Results
Extensive simulations quantitatively validate the proposed testing and estimation approaches. Key findings include:
When the user-defined mapping is correct, the test's empirical rejection rate is $0$ (Type I error) and p-values are high, confirming specificity.
For misspecified mappings (e.g., failing to capture higher-order or nonlinear interference), rejection rates approach $1$ as sample size increases, affirming power.
Estimation of the direct effect using the learned GCA exposure mapping converges to the true effect as sample size increases, with mean bias and variance diminishing in larger samples. For n≥500, results exhibit negligible bias.
Theoretical and Practical Implications
The methodological contributions enable two key advancements:
Data-driven discovery of complex exposure mappings, improving modeling flexibility and potentially reducing interference-induced bias in networked causal inference;
Formal testing and validation of exposure mapping adequacy, yielding diagnostic tools for empirical researchers and supporting rigorous applied work.
These techniques can be generalized to settings involving high-complexity networks and interdependent interventions in epidemiology, social science, and digital platform experimentation.
Practically, adoption of GCA-based exposure learning and inference frameworks can automate much of the otherwise ad hoc specification selection prevalent in the literature, while theoretically, extensions to broader classes of network dependencies and outcomes (non-continuous Yi) present natural avenues for future research.
Conclusion
This study develops an integrated machine learning framework for learning, validating, and applying exposure mappings under arbitrary network interference, combining GCAs for flexible embedding construction and conditional independence-driven validity testing. The double machine learning architecture ensures robust and efficient estimation, with simulations demonstrating the empirical advantages of the approach. This work lays the foundation for further advances in causal inference with complex interference, particularly as large-scale network data become ubiquitous.