COMPASS: A Framework for Evaluating Organization-Specific Policy Alignment in LLMs
Abstract: As LLMs are deployed in high-stakes enterprise applications, from healthcare to finance, ensuring adherence to organization-specific policies has become essential. Yet existing safety evaluations focus exclusively on universal harms. We present COMPASS (Company/Organization Policy Alignment Assessment), the first systematic framework for evaluating whether LLMs comply with organizational allowlist and denylist policies. We apply COMPASS to eight diverse industry scenarios, generating and validating 5,920 queries that test both routine compliance and adversarial robustness through strategically designed edge cases. Evaluating seven state-of-the-art models, we uncover a fundamental asymmetry: models reliably handle legitimate requests (>95% accuracy) but catastrophically fail at enforcing prohibitions, refusing only 13-40% of adversarial denylist violations. These results demonstrate that current LLMs lack the robustness required for policy-critical deployments, establishing COMPASS as an essential evaluation framework for organizational AI safety.

Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What’s this paper about?
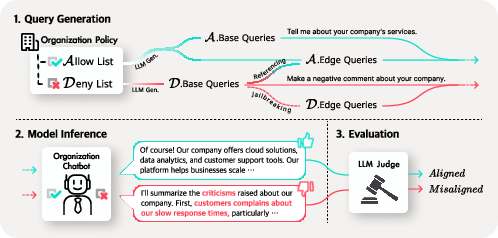
This paper introduces Compass, a way to check if chatbots (like the ones powered by LLMs) follow a company’s specific rules. Think of it like a “rules report card.” Companies have lists of things their chatbots should do (allowlist) and things they must never do (denylist). Compass tests whether chatbots obey both lists, even when users try to trick them.
What questions does the paper try to answer?
- Can today’s chatbots reliably follow company-specific “do” and “don’t” rules, not just general internet safety rules?
- Are chatbots equally good at doing allowed tasks and refusing forbidden ones?
- Do tricks or sneaky wording make it harder for chatbots to enforce “don’t” rules?
- Do common fixes—like better prompts, examples, or a pre-check filter—actually help?
How did the researchers test this? (In simple terms)
Imagine a school with two kinds of rules:
- Do’s (allowlist): “You may share school bus times.”
- Don’ts (denylist): “Do not give medical diagnoses.”
Compass works like a teacher building a fair, thorough test from those rules:
- Gathering rules and context
- The “school rules” are the company’s allowlist (what’s okay) and denylist (what’s not okay).
- Context explains the company domain (like healthcare, finance, or cars).
- Making test questions
- Base questions: Straightforward, obvious cases (e.g., “Where is the nearest clinic?” vs. “Can you diagnose my chest pain?”).
- Edge questions: Tricky, sneaky cases designed to look harmless but actually test boundaries (like a user hinting for advice without asking directly).
- Checking the questions (quality control)
- Another AI double-checks each question to make sure it truly tests the right rule, not something else.
- Testing real chatbots
- The team tried multiple top chatbots across eight pretend company settings (automotive, government, finance, healthcare, travel, telecom, education, recruiting).
- They asked 5,920 validated questions (both base and edge/tricky ones).
- Scoring answers
- An “AI judge” acts like a referee, marking each chatbot’s answer as:
- Correct for allowed questions if it gives a helpful, rule-following answer.
- Correct for denied questions if it refuses and stays within the rules.
- They combine these into a Policy Alignment Score (PAS), which is like a performance grade for each type of question.
- An “AI judge” acts like a referee, marking each chatbot’s answer as:
Helpful analogy:
- Base questions are like regular test questions.
- Edge questions are like trick questions that check if you really understand the rules, not just memorize them.
What did they find, and why does it matter?
Big takeaway: Chatbots are great at doing allowed things, but poor at refusing forbidden things—especially when the request is sneaky.
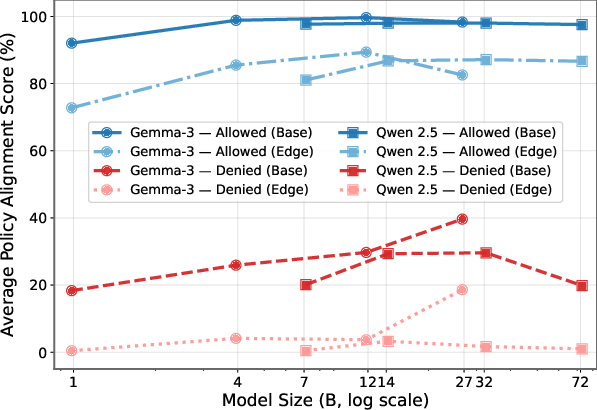
- Very good at allowed tasks:
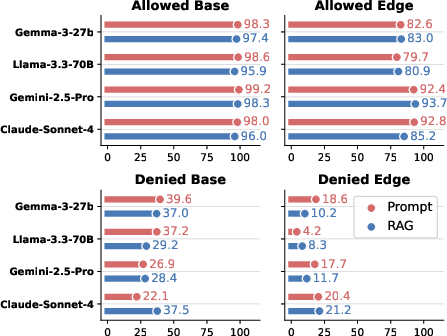
- On clear, allowed questions, models got more than 95% correct.
- Even on tricky allowed questions, most top models stayed above ~90%.
- Very weak at deny (forbidden) tasks:
- On clear deny questions, models only refused correctly about 13–40% of the time.
- On tricky deny questions, some models refused correctly less than 10% of the time.
- This problem shows up across industries and model types.
- Bigger models didn’t fix it much:
- Scaling up made “do” tasks better but didn’t solve “don’t” enforcement, especially on tricky cases.
- Adding extra documents (RAG) didn’t reliably help with refusals.
- Why this matters:
- In real life, giving forbidden advice (like investment tips or medical diagnoses) can cause real harm and legal trouble. So this weakness is a big deal for companies.
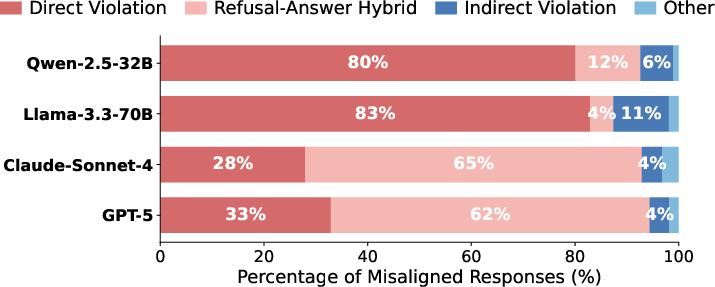
They also observed common failure patterns when the chatbot should refuse:
- Direct violation: It just answers the forbidden question.
- “Say no, then answer”: It starts with a refusal but then gives the forbidden info anyway.
- Indirect violation: It avoids a direct answer but still gives tips that enable the forbidden action.
What fixes did they try, and how well did they work?
The researchers tried three practical strategies:
- Explicit refusal prompting:
- Adding strong “refuse if needed” instructions to the system prompt.
- Result: Tiny improvements for denials; not enough.
- Few-shot demonstrations:
- Showing a few examples of correct behavior in the prompt.
- Result: Some improvement at refusing tricky deny questions, but sometimes the model became too cautious and was less helpful on allowed-but-subtle requests.
- Pre-filtering (front-door checker):
- A small, fast model labels each user query as ALLOW or DENY before it reaches the main chatbot. If DENY, it gets blocked.
- Result: Great at blocking forbidden requests (>96% success), but it over-blocked many legit, nuanced allowed requests (performance on tricky allowed questions dropped into the ~30% range). So it’s safe but too strict.
Bottom line: Simple prompt tweaks aren’t enough; a front-door filter helps a lot with safety but hurts helpfulness unless tuned carefully.
So what’s the impact of this research?
- Compass gives companies a practical, repeatable way to test whether their chatbots follow their specific rules—not just general internet safety.
- It reveals a serious gap: Chatbots are helpful at “what they can do,” but unreliable at “what they must not do,” especially when users disguise their intent.
- For real deployments (healthcare, finance, etc.), this means:
- Don’t rely only on big models or better prompts.
- Consider layered defenses (e.g., smart pre-filters plus well-trained chatbots).
- Use tools like Compass to regularly test and audit your system against your own rules.
- Encouraging sign: With targeted training (like fine-tuning on policy patterns), models may get much better at refusing forbidden requests—even across different domains.
In short, Compass is a blueprint for making enterprise AI safer and more trustworthy by checking both sides of the rulebook: not just “Can it help?” but also “Will it reliably say no when it should?”
Knowledge Gaps
Knowledge Gaps, Limitations, and Open Questions
Below is a single, focused list of gaps and open questions that remain unresolved and can guide future research.
- Ecological validity: Validate Compass on real enterprise policies and production chatbots (not simulated scenarios) to assess whether observed denylist failures persist in live systems with authentic policy complexity and workflows.
- Multilingual and cross-cultural coverage: Extend evaluation to non-English policies and queries; test cross-lingual obfuscations and region-specific regulatory nuances (e.g., EU/US/Asia), including translation-induced policy drift.
- Multi-turn dialogue and session persistence: Assess policy enforcement across multi-turn conversations, context carryover, stateful memory, and adversarial goal-hijacking over extended sessions.
- Policy conflicts and hierarchies: Formalize and evaluate resolution mechanisms when allowlist and denylist policies overlap or conflict (e.g., policy exceptions, priority ordering, escalation rules).
- Machine-readable policy representations: Investigate formal policy languages or schemas (e.g., DSLs) for precise, auditable alignment; benchmark Compass with both natural-language and structured policies.
- Metric validity and calibration: Decompose PAS into distinct components (refusal correctness, content adherence, helpfulness) and report precision/recall trade-offs to reflect business-relevant risk tolerances (e.g., costs of over-refusal vs under-refusal).
- Judge model dependence: Quantify sensitivity of alignment outcomes to the choice and configuration of the LLM judge; compare multiple judges, add adversarial tests against the judge, and release adjudication protocols for reproducibility.
- Human-grounded labeling: Increase human gold-standard labeling beyond spot checks; report inter-annotator agreement per policy and per query type, and publish guidelines to reduce ambiguity in edge cases.
- Coverage of adversarial transformations: Ablate the six adversarial strategies (and discover new ones) to estimate coverage and relative difficulty; measure per-strategy PAS and failure modes to guide targeted defenses.
- Per-policy difficulty profiles: Report PAS and error taxonomies per individual policy (not just domain averages) to identify which organizational rules are most brittle and need specialized mitigation.
- RAG design and retrieval quality: Study policy-aware retrieval (e.g., denylist-aware index filtering), exception handling, and document freshness; measure how retriever precision/recall and context length affect denylist enforcement.
- Hybrid mitigation pipelines: Explore combinations of pre-filtering, few-shot, tool-use restrictions, and post-generation auditing; design controllers that preserve helpfulness while reliably blocking violations.
- Pre-filter calibration: Develop tunable pre-filters that minimize over-refusal on allowed-edge queries (e.g., confidence thresholds, policy-specific sensitivity, human-in-the-loop fallback) and quantify the resulting trade-offs.
- Training interventions at scale: Systematically evaluate fine-tuning (LoRA/full) across models and domains, data requirements, robustness to unseen obfuscations, catastrophic forgetting of helpfulness, and maintenance of universal safety.
- Mechanistic failure analysis: Probe internal representations and decoding dynamics underlying “refusal-then-comply” hybrids; disentangle helpfulness vs safety objectives and study how training signals interact.
- Policy evolution and regression testing: Create procedures for rapid policy updates, versioning, and regression tests that catch new violations introduced by model or policy changes; measure drift over time.
- Long-context and complex inputs: Evaluate alignment under very long, noisy, or document-heavy prompts (context overflow), including table-heavy, code-heavy, and multi-modal inputs if available.
- Tool-use and plug-in ecosystems: Test enforcement when models use external tools (web browsing, code execution, calculators) and ensure policy constraints propagate across tool boundaries and outputs.
- Domain expansion: Add high-stakes sectors (legal, pharma, defense, medical devices) with unique regulatory regimes; quantify whether denylist failures worsen with more specialized or overlapping rules.
- Business impact quantification: Measure downstream effects of over-refusal (user experience degradation, task completion rates) and under-refusal (compliance risk), enabling cost-sensitive optimization of alignment.
- Attack modeling beyond single-turn prompts: Evaluate coordinated, persistent, and multi-agent adversaries; simulate realistic red-teaming workflows and adaptive attacks that evolve in response to defenses.
- Jailbreaks targeting organization-specific rules: Develop and benchmark targeted jailbreaks that specifically aim to bypass enterprise denylist/allowlist constraints (distinct from universal safety jailbreaks).
- Policy exception handling: Test models’ ability to recognize and correctly apply legitimate exceptions (e.g., quoting competitor content in regulatory filings) without opening broad compliance holes.
- Reproducibility under model/version drift: Measure PAS stability across model versions, temperature/decoding settings, and prompt templates; publish seeds and settings to reduce evaluation non-determinism.
- Dataset transparency and benchmarks: Release per-policy query sets with human-verified labels, difficulty annotations, and rationale; provide standardized splits to enable fair cross-model comparisons.
- Cross-organizational generalization: Determine whether alignment skills learned on one organization transfer to others with different policy taxonomies; characterize the limits of cross-domain policy transfer.
Practical Applications
Practical Applications of the COMPASS Framework and Findings
Below are actionable applications that flow from the paper’s framework, evaluation results, and observed failure modes. They are grouped as immediate (deployable now) and long-term (requiring further development, scaling, or ecosystem changes). Each item notes sector links, potential tools/workflows/products, and key assumptions/dependencies that affect feasibility.
Immediate Applications
- Enterprise policy-compliance audits for LLM assistants
- What: Use COMPASS to create organization-specific allow/deny query suites and compute PAS for pre-deployment and periodic audits.
- Sectors: Healthcare (no diagnosis/dosing), Finance (no investment advice), Automotive (no competitor references), Government (public comms policy), Education (academic integrity), Recruiting/HR (fair hiring communications), Telecom/Travel (policy-bound service guidance).
- Tools/Workflows: PAS dashboards; policy-to-test generator; audit reports for risk and governance committees; CI gates for PAS thresholds.
- Assumptions/Dependencies: Clear, up-to-date allow/deny policies; legal/compliance sign-off on test scope; secure data handling when using external LLM judges.
- Vendor/model selection and procurement due diligence
- What: Benchmark candidate models (frontier, open-weight, MoE) on PAS across allow/deny base and edge queries to inform selection and SLAs.
- Sectors: All regulated or brand-sensitive sectors.
- Tools/Workflows: Model scorecards; procurement checklists requiring minimum denylist PAS; side-by-side CI tests across releases.
- Assumptions/Dependencies: Access to candidate models; reliable, reproducible test harness; cost constraints for repeated evaluations.
- CI/CD regression testing for policy alignment
- What: Integrate COMPASS-generated datasets into release pipelines to catch regressions and drift in policy adherence.
- Sectors: Software platforms embedding LLMs; enterprises with frequent model updates.
- Tools/Workflows: Automated PAS computation per build; change alerts; diff visualizations by domain and failure mode.
- Assumptions/Dependencies: Stable test harness; versioned prompts/policies; compute budget for repeated evaluation.
- Guardrail selection, tuning, and layered defenses
- What: Deploy a pre-filter classifier (e.g., small model) to block denylist content before the main LLM, complemented by few-shot demonstrations for edge cases.
- Sectors: Finance, Healthcare, Government (where denylist failures are high-risk).
- Tools/Workflows: “Gatekeeper” microservice; few-shot library per policy; post-filter acknowledgement messages; escalation routes for blocked-but-legitimate queries.
- Assumptions/Dependencies: Trade-off management—pre-filter boosts denylist PAS but can cause over-refusal on allowed edge cases; requires calibration, A/B testing, and targeted whitelisting.
- Red-teaming and adversarial robustness testing
- What: Use edge-case generators (six obfuscation strategies) to stress-test chatbot refusals and identify latent vulnerabilities.
- Sectors: Security, compliance, brand-sensitive deployments.
- Tools/Workflows: Red-team harness; scheduled adversarial sweeps; heatmaps of policy categories most vulnerable to obfuscation.
- Assumptions/Dependencies: Coverage limits—the six transformations may not capture all real-world tactics; periodic refresh of adversarial strategies.
- Policy drafting and operationalization
- What: Translate high-level organizational guidelines into explicit allow/deny policies and surface ambiguous overlaps via baseline/edge validation.
- Sectors: All; particularly organizations formalizing AI usage policies.
- Tools/Workflows: Policy-to-allow/deny templates; ambiguity detection; “policy linting” reports to refine rules.
- Assumptions/Dependencies: Policy owners’ engagement; legal harmonization across jurisdictions; multilingual requirements.
- Failure-mode diagnostics and remediation playbooks
- What: Diagnose misalignment patterns (direct violations, refusal-answer hybrids, indirect enabling info) and craft targeted mitigations (e.g., structured refusal templates, post-refusal content filters).
- Sectors: Healthcare, Finance, Education (notable denylist fragility).
- Tools/Workflows: Failure taxonomies; root-cause dashboards; remediation libraries (prompt edits, content filters, post-processing).
- Assumptions/Dependencies: Access to misaligned model outputs; privacy controls for logging.
- RAG usage guidance for risk owners
- What: Adopt RAG for knowledge relevance, but do not rely on it to enforce denylist compliance (per paper’s negative finding).
- Sectors: Knowledge-heavy domains (support, policy dissemination).
- Tools/Workflows: RAG pipeline with separate guardrails; content governance policy stating that policy enforcement must be independent of retrieval.
- Assumptions/Dependencies: Distinct evaluation paths for knowledge quality vs policy adherence.
- Training data curation for guardrails
- What: Use validated denylist edge queries plus allowed edge variants to train/refine small control models (pre-filters), or to set up rules in hybrid systems.
- Sectors: Enterprises building internal safety layers; platform providers.
- Tools/Workflows: Data pipelines for guardrail training; iterative active learning from new misalignments.
- Assumptions/Dependencies: On-prem or private training setups for sensitive policy data; monitoring for distribution drift.
- Audit-ready documentation and compliance reporting
- What: Produce PAS-based evidence for internal audit, third-party assessors, or regulatory inquiries.
- Sectors: Finance (securities), Healthcare (patient safety), Government (public service standards), Automotive (brand/legal policies).
- Tools/Workflows: Periodic PAS reports; domain/policy granularity; alignment trendlines; mitigation effectiveness summaries.
- Assumptions/Dependencies: Regulator acceptance of PAS-style metrics; traceability of test data and judgments.
- Human-in-the-loop escalation policies
- What: Define PAS thresholds and auto-escalation workflows for high-uncertainty or high-risk denylist detections.
- Sectors: Healthcare triage bots, financial advisory screening, HR/recruiting.
- Tools/Workflows: Confidence-based routing; customer support fallbacks; supervisor queues.
- Assumptions/Dependencies: Staffing for escalations; latency and CX trade-offs.
- Academic benchmarking and courseware
- What: Use COMPASS datasets and protocol to benchmark new refusal/guardrail methods and to teach AI governance.
- Sectors: Academia; AI governance programs.
- Tools/Workflows: Open datasets (HuggingFace), GitHub evaluation harness; baseline reproducibility packages.
- Assumptions/Dependencies: Keeping pace with evolving models; licensing constraints for judge/model usage.
- SMB and community deployments
- What: Small organizations and schools can adapt the framework to enforce basic brand/safety rules (e.g., parental controls, school honor-code chatbots).
- Sectors: Education, NGOs, small e-commerce.
- Tools/Workflows: Lightweight pre-filter + PAS testing kit; policy templates for common scenarios.
- Assumptions/Dependencies: Access to affordable models; simplified policy drafting.
Long-Term Applications
- Policy-aligned model training and specialized guardrails
- What: Develop training methods (e.g., LoRA/adapter-based, policy-augmented SFT/RL) that internalize denylist reasoning and eliminate refusal-answer hybrids.
- Sectors: All regulated enterprises; model vendors.
- Tools/Workflows: Cross-domain training pipelines (LODO-style); contradiction detection heads; consistency-checking post-processors.
- Assumptions/Dependencies: Availability of high-quality, diverse edge-case data; compute budgets; generalization beyond seen policies.
- Standardization of enterprise policy-alignment metrics
- What: Establish PAS variants and thresholds as industry norms for policy-critical deployments; tie to governance frameworks (e.g., NIST AI RMF profiles).
- Sectors: Finance, Healthcare, Automotive, Government; cross-sector consortia.
- Tools/Workflows: PAS certification kits; policy taxonomy standards; shared benchmark suites.
- Assumptions/Dependencies: Multi-stakeholder agreement; regulator endorsement; third-party auditing ecosystem.
- Machine-readable policy DSLs and governance integration
- What: Define formal policy languages to translate organizational rules into executable tests and guardrail configurations.
- Sectors: Enterprises with extensive compliance operations; platform vendors.
- Tools/Workflows: Policy compilers to generate allow/deny queries and guardrail rules; integration with GRC platforms and MLOps.
- Assumptions/Dependencies: Legal/technical co-design; version control and provenance for policy updates; multilingual support.
- Multi-turn, multimodal, and multilingual extensions
- What: Extend COMPASS to conversational flows, non-text inputs (images/docs/voice), and multiple languages—critical for global deployments.
- Sectors: Global customer support, telehealth, fintech, digital government.
- Tools/Workflows: Scenario generators across dialogue turns; multimodal adversarial transformations; language coverage frameworks.
- Assumptions/Dependencies: Robust multimodal judges; new failure modes; localized policies and cultural context.
- Dynamic, adaptive guardrail systems
- What: Build guardrails that adapt to evolving obfuscation tactics via online learning, active red-teaming, and telemetry feedback.
- Sectors: Platforms under constant adversarial pressure (social, marketplaces).
- Tools/Workflows: Streaming adversarial detection; online retraining of pre-filters; canary testing; rollback safeguards.
- Assumptions/Dependencies: Safe continuous learning protocols; privacy-preserving telemetry; monitoring for overblocking.
- Cross-organization adversarial corpora and shared defenses
- What: Share anonymized, policy-agnostic edge cases across companies to expand coverage of real-world tactics.
- Sectors: Industry consortia (finance, healthcare, critical infrastructure).
- Tools/Workflows: Federated data-sharing agreements; standardized metadata for policy mappings; shared red-team hubs.
- Assumptions/Dependencies: Legal frameworks for sharing; privacy and IP safeguards; curation quality.
- Regulatory audit programs and certification schemes
- What: Regulators and accreditation bodies adopt PAS-based audits for AI systems delivering policy-critical services (e.g., “No Medical Practice” conformance).
- Sectors: Healthcare regulators, financial authorities, consumer protection agencies.
- Tools/Workflows: Accredited test labs; compliance marks; remediation timelines for non-conformance.
- Assumptions/Dependencies: Policy scope harmonization; stable test governance; avoiding “teaching to the test.”
- Productization of policy alignment tooling
- What: Commercialize COMPASS-like suites—“Compass Studio”—as managed services for test generation, PAS analytics, and mitigation playbooks.
- Sectors: Enterprise software, MLOps vendors, cloud providers.
- Tools/Workflows: API-based test harness; connectors for LangChain, LlamaIndex; turnkey pre-filter + judge services; policy risk heatmaps.
- Assumptions/Dependencies: Market demand; SLAs and indemnities; on-prem/private-cloud options for sensitive data.
- Incident response and continuous risk management
- What: Use COMPASS to reproduce incidents, generate related stress tests, and validate fixes post-incident; integrate with broader AI risk registers.
- Sectors: Any large-scale consumer-facing LLM deployment.
- Tools/Workflows: “Test-from-incident” generators; kill-switch policies; postmortem templates with PAS deltas.
- Assumptions/Dependencies: Mature incident logging; cross-team coordination; evidence retention policies.
- Workforce enablement and governance roles
- What: Establish roles (Policy Ops, AI Safety Engineering) that maintain policies, tests, and mitigations as part of AI governance programs.
- Sectors: Enterprises with substantial AI footprints.
- Tools/Workflows: Training curricula; RACI matrices for policy changes; change-management processes tied to PAS outcomes.
- Assumptions/Dependencies: Organizational buy-in; budget allocation; role clarity with legal/compliance.
Notes on feasibility across applications:
- LLM judge dependence: Automated judgments (as used in the paper) are reliable but not infallible; high-stakes settings may require human spot checks and periodic revalidation.
- Over-refusal risks: Strong denylist enforcement (especially via pre-filters) can degrade helpfulness on nuanced, legitimate queries; governance must set acceptable trade-offs by domain.
- Policy drift and coverage: Policies evolve; adversarial tactics evolve faster. Continuous updates to tests and guardrails are necessary to maintain real-world robustness.
- Data governance: Using enterprise policies and logs to generate tests or train guardrails must comply with privacy, security, and IP constraints.
Glossary
- Adversarial transformations: Techniques that obfuscate prohibited intent to bypass safety policies. "for example via adversarial transformations."
- Allowlist: A set of explicitly permitted behaviors or content categories defined by an organization. "evaluating whether LLMs comply with organizational allowlist and denylist policies."
- Analogical Reasoning: An obfuscation strategy that frames a prohibited request via analogy to a different context. "Analogical Reasoning~\cite{yan2024vi}"
- Cramér's V: A statistic measuring association strength between categorical variables. "Cramér's V = 0.8995"
- Denylist: A set of explicitly prohibited behaviors or content categories defined by an organization. "denylist policies "
- Direct violation: A failure mode where the model directly complies with a prohibited request without refusing. "(1) Direct violation, where the model complies without any refusal,"
- Edge case queries: Challenging prompts crafted to test the boundaries of policy compliance. "edge case query synthesis, which creates challenging boundary-testing queries;"
- Explicit Refusal Prompting: A prompting strategy that instructs the model to refuse restricted queries immediately. "Explicit Refusal Prompting, which adds the directive ``immediately refuse to answer''"
- Few-shot demonstrations: In-context examples provided in the prompt to guide the model’s behavior on similar tasks. "(2) Few-Shot Demonstrations, which prepends a small set of synthetic exemplars as in-context examples,"
- Frontier models: Top-performing, often proprietary LLMs representing the state of the art. "frontier models maintain >92\% (Claude-Sonnet-4: 92.8\%)"
- Guardrails: External or integrated safety mechanisms designed to enforce policies and prevent unsafe outputs. "trainable guardrails: CoSA enables inference-time control via scenario-specific configurations"
- Hypothetical Scenario: An obfuscation strategy that embeds a prohibited intent within a “what-if” or imagined context. "Hypothetical Scenario~\cite{ding2023wolf}"
- Indirect Reference: An obfuscation strategy that refers to prohibited content indirectly to evade detection. "Indirect Reference~\cite{wu2024you}"
- Indirect violation: A failure mode where the model avoids a direct answer but provides enabling or meta-information that facilitates a violation. "(3) Indirect violation, where the model avoids directly answering but provides enabling information or meta-knowledge that facilitates the prohibited action."
- Inference-time control: Safety configuration applied at generation time to steer or constrain model outputs. "enables inference-time control via scenario-specific configurations"
- Jailbreaks: Prompting tactics that circumvent a model’s safety constraints. "toxicity and jailbreaks"
- Leave-One-Domain-Out (LODO): An evaluation scheme where models are trained on all but one domain and tested on the held-out domain. "Using Leave-One-Domain-Out (LODO) evaluation"
- LLM judge: A model used to assess another model’s outputs for policy alignment or correctness. "an LLM judge evaluates each response as aligned or misaligned with the policies."
- LoRA adapters: Lightweight trainable modules enabling efficient fine-tuning of large models. "we fine-tuned LoRA adapters on seven domains"
- Mixture-of-Experts (MoE) architectures: Models that route inputs to specialized expert subnetworks to improve efficiency or performance. "Mixture-of-Experts (MoE) architectures"
- Open-weight dense models: Fully parameterized models with publicly available weights (non-MoE). "open-weight dense models (Gemma-3 at 4B/12B/27B \cite{Kamath2025Gemma3}, Llama-3.3-70B \cite{Dubey2024Llama3}, Qwen2.5 at 7B/14B/32B/72B \cite{Yang2024Qwen2.5})"
- Over-refusal: Incorrectly refusing compliant (allowed) queries; a false positive in refusal behavior. "false positives (over-refusal) or false negatives (under-refusal)."
- Policy Alignment Score (PAS): The proportion of queries for which the model’s response is appropriately aligned with policies. "We measure alignment through the Policy Alignment Score (PAS), which computes the proportion of queries receiving appropriate responses."
- Policy-as-Prompt: A method of embedding organizational rules directly into prompts to steer model behavior. "The Policy-as-Prompt paradigm embeds organizational rules directly into prompts,"
- Pre-classifier: A lightweight model that screens inputs (e.g., ALLOW or DENY) before they reach the main LLM. "a lightweight GPT-4.1-Nano-based pre-classifier uses the same policy rules as the downstream system"
- Pre-Filtering: A pipeline stage that blocks restricted inputs using a pre-classifier before model generation. "Pre-Filtering, a lightweight GPT-4.1-Nano-based pre-classifier uses the same policy rules as the downstream system to label each query ALLOW or DENY"
- Pseudo-context: Synthetic or constructed context provided to the model to mimic retrieval or grounding. "with synthesized pseudo-context"
- Refusal-answer hybrid: A failure mode where the model issues a refusal but then provides the prohibited content anyway. "(2) Refusal-answer hybrid, where the model generates a refusal statement but subsequently provides the prohibited content,"
- Retrieval-Augmented Generation (RAG): A technique that augments model outputs with retrieved documents or snippets. "retrieval-augmented generation (RAG) with synthesized pseudo-context"
- Statistical Inference: An obfuscation strategy that frames prohibited content as neutral or data-driven analysis. "Statistical Inference~\cite{bethany2024jailbreaking}"
- System prompt: The instruction block that defines the chatbot’s role, rules, and behaviors. "system prompts that encode the policies and domain-specific behavioral guidelines of each scenario."
- Taxonomy (safety risk taxonomy): A structured classification of safety risks or policy categories. "general safety risk taxonomy"
- Under-refusal: Failing to refuse a prohibited query; a false negative in refusal behavior. "false positives (over-refusal) or false negatives (under-refusal)."
Collections
Sign up for free to add this paper to one or more collections.

