DreamID-V:Bridging the Image-to-Video Gap for High-Fidelity Face Swapping via Diffusion Transformer
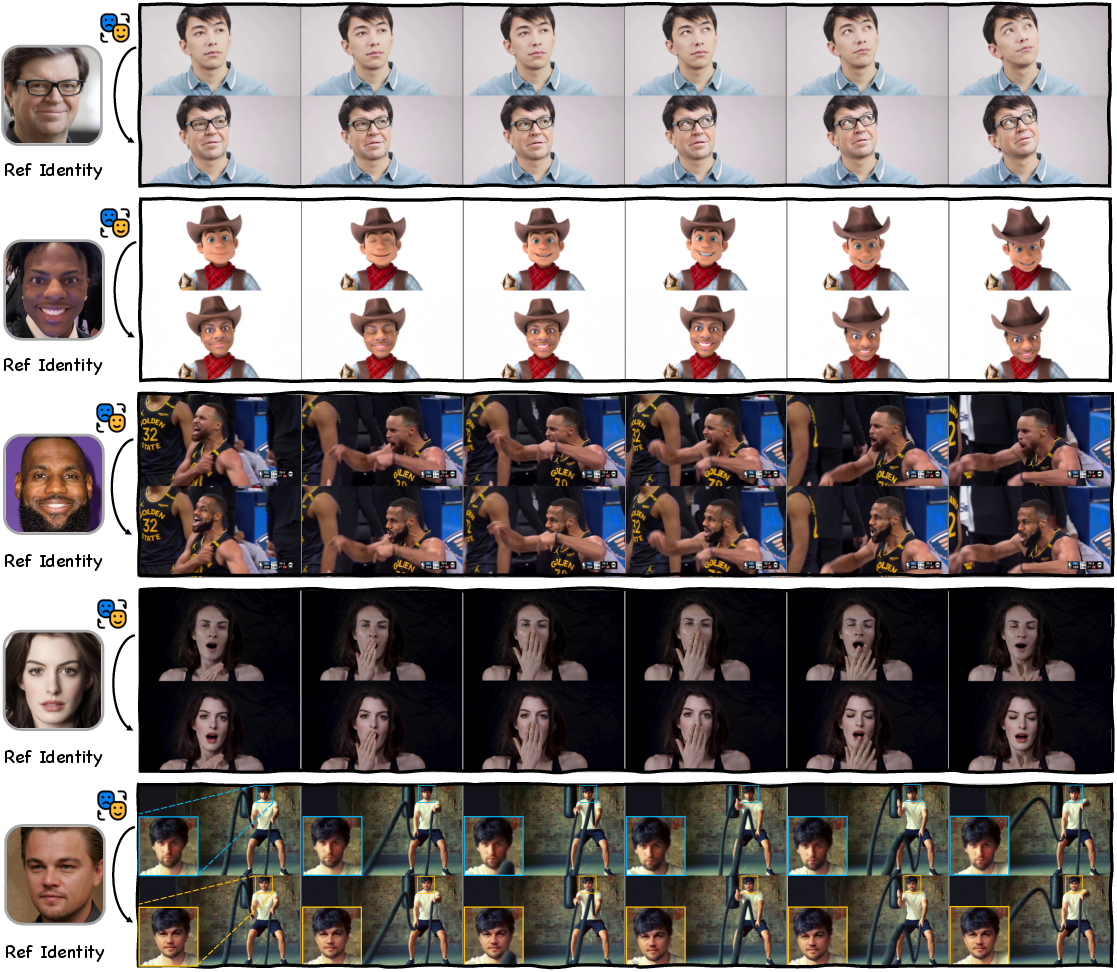
Abstract: Video Face Swapping (VFS) requires seamlessly injecting a source identity into a target video while meticulously preserving the original pose, expression, lighting, background, and dynamic information. Existing methods struggle to maintain identity similarity and attribute preservation while preserving temporal consistency. To address the challenge, we propose a comprehensive framework to seamlessly transfer the superiority of Image Face Swapping (IFS) to the video domain. We first introduce a novel data pipeline SyncID-Pipe that pre-trains an Identity-Anchored Video Synthesizer and combines it with IFS models to construct bidirectional ID quadruplets for explicit supervision. Building upon paired data, we propose the first Diffusion Transformer-based framework DreamID-V, employing a core Modality-Aware Conditioning module to discriminatively inject multi-model conditions. Meanwhile, we propose a Synthetic-to-Real Curriculum mechanism and an Identity-Coherence Reinforcement Learning strategy to enhance visual realism and identity consistency under challenging scenarios. To address the issue of limited benchmarks, we introduce IDBench-V, a comprehensive benchmark encompassing diverse scenes. Extensive experiments demonstrate DreamID-V outperforms state-of-the-art methods and further exhibits exceptional versatility, which can be seamlessly adapted to various swap-related tasks.




Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Plain-English Summary of “DreamID‑V: Bridging the Image‑to‑Video Gap for High‑Fidelity Face Swapping via Diffusion Transformer”
What is this paper about?
This paper is about making video face swapping look more real and consistent. Face swapping means putting one person’s face (the “source”) onto another person’s video (the “target”) while keeping everything else—like the pose, expression, lighting, and background—unchanged. The authors introduce a new system called DreamID‑V that makes video face swaps look like the same person across all frames, with fewer flickers and mistakes, even during fast movements or tricky angles.
What questions did the researchers ask?
- How can we bring the strengths of image face swapping (which is already very good) into videos, where motion and consistency are much harder?
- How can we train a video model to keep a person’s identity accurate while also preserving the target video’s pose, expressions, and background?
- How can we reduce flickering and keep the swapped face consistent across the whole video?
- How can we fairly test and compare different methods for video face swapping?
How did they do it?
To explain the approach, imagine three main steps: creating smart training data, designing a model that understands different kinds of information, and training it in the right order.
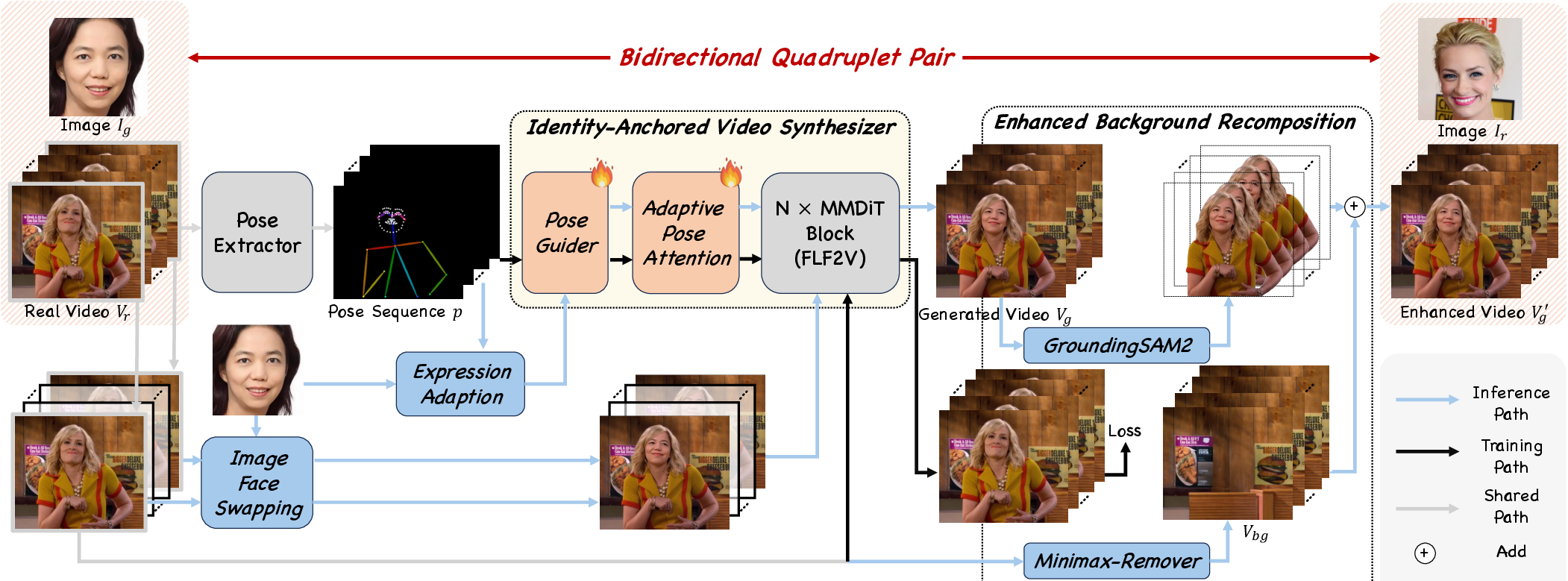
1) Building better training data: SyncID‑Pipe
- Problem: Image face swapping works great on single pictures, but videos need smooth motion and consistent identity across frames.
- Solution: The authors built a data pipeline called SyncID‑Pipe that “teaches” the video model using pairs of carefully matched examples.
Key pieces:
- Identity‑Anchored Video Synthesizer (IVS): Think of this like a video “fill‑in‑the‑middle” tool. It’s given the first and last frames of a video and a “pose sequence” (a plan for head movements and expressions) and generates a full video that follows those motions.
- Bidirectional ID quadruplets: For training, they create sets of four items {source image, source video, target image, target video}. This gives the model clear, paired examples to learn from—what to change (identity) and what to keep (pose, expression, background).
- Expression adaptation: They separate identity from expression using a 3D face tool. This lets the system transfer the target person’s identity while preserving the original video’s expressions and head movements.
- Enhanced background recomposition: They remove and rebuild backgrounds to make sure the training pairs match real scenes, so the model won’t learn messy background artifacts.
In short: They generate clean, controlled training examples so the model learns exactly what to swap and what to keep.
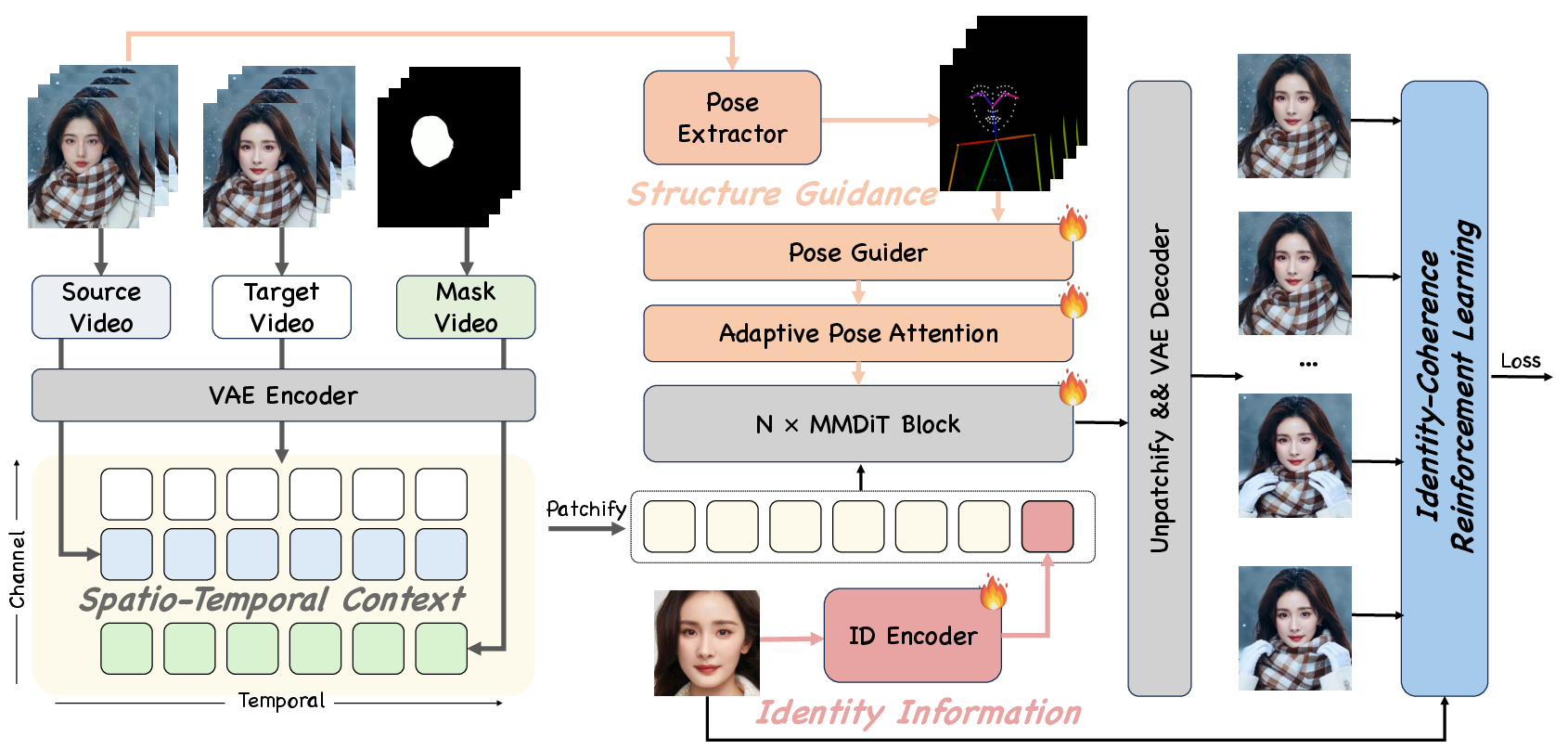
2) The DreamID‑V model: a Diffusion Transformer that understands “what is what”
DreamID‑V is built on a Diffusion Transformer (DiT), a modern AI that turns random noise into high‑quality videos step by step. It uses attention (a way to “focus” on important details) to stay consistent across frames.
The key idea is Modality‑Aware Conditioning: the model receives three types of information, each injected in the best way:
- Spatio‑Temporal Context (what should stay the same): The target video and a face mask tell the model where the face is and what the scene/background looks like.
- Structural Guidance (how the face should move): A pose guide (like a choreography for head turns and expressions) helps keep motion and lip sync accurate.
- Identity Information (whose face to swap in): An identity encoder turns the source person’s image into a compact “ID embedding” so the model knows exactly which face to generate.
This separation makes the model better at keeping identity, motion, and background each clean and consistent.
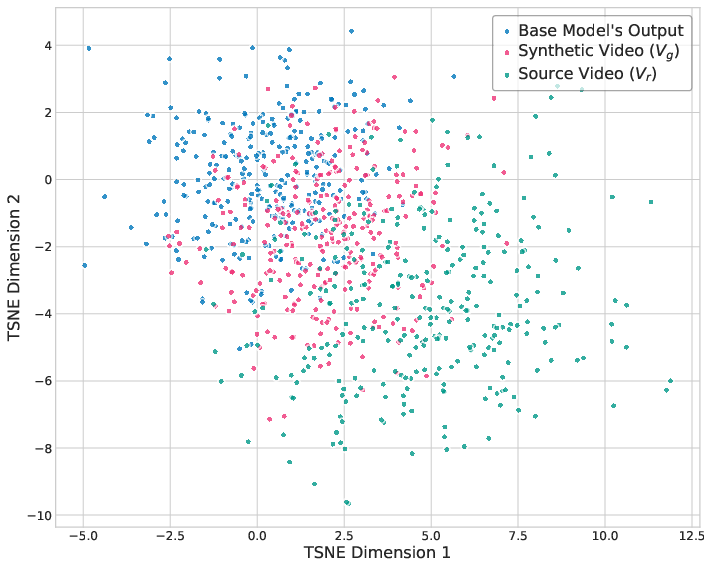
3) Training strategy: from “easy” to “real,” plus a boost for hard frames
The authors train the model in two stages, then add a final improvement step.
- Synthetic Training (easy start): First learn from generated pairs that match the model’s own style. This helps the model quickly learn accurate identity.
- Real Augmentation Training (step up the realism): Then fine‑tune on “realistic” paired data with carefully rebuilt backgrounds, improving realism and scene preservation.
- Identity‑Coherence Reinforcement Learning (IRL): Finally, the model runs on a video, measures which frames have weak identity matches (like side views or fast motion), and focuses extra learning on those “hard” frames. This reduces flicker and keeps the face consistent across time.
What did they find, and why does it matter?
Here are the main takeaways, based on tests and comparisons on a new benchmark they built (IDBench‑V), which includes challenging cases like occlusions, big head turns, small faces, and complex expressions:
- Stronger identity match: The swapped face looks more like the source person than with other top methods, and stays consistent across frames.
- Better motion and expression preservation: Because the model uses pose and expression guidance, lip movements and facial expressions follow the video naturally.
- More stable videos: Less flicker and jitter, especially during fast movement or profile views, thanks to the IRL step.
- Background and lighting are well preserved: The scene looks natural; the system doesn’t accidentally change the environment.
- Works in tough situations: Occlusions (like hands), big head angles, cartoons/animation styles, and small faces are handled robustly.
- New benchmark: They release IDBench‑V so others can test methods fairly.
- Versatility: The same framework can be adapted beyond faces—for example, to swap hairstyles, outfits, and accessories in videos.
Why it matters: Realistic video face swapping can be useful for movie production, dubbing, creative effects, and privacy tools. This work pushes the field forward by combining high identity accuracy with smooth, believable motion.
What’s the impact and what comes next?
- Practical uses: Filmmakers and creators can replace faces seamlessly without re‑filming. It can also help privacy protection by masking identities while keeping motion and expression.
- Research value: The data pipeline (SyncID‑Pipe), the model design (modality‑aware conditioning), and the training recipe (synthetic‑to‑real + IRL) offer a reusable roadmap for other video editing tasks.
- Beyond faces: The framework can swap other human‑related details (like clothes or accessories) in video with high realism.
- Responsibility: As with any face‑swapping tech, it should be used ethically—such as with consent, watermarking, and detection tools—to prevent misuse.
In short, DreamID‑V shows a clear way to bring the best parts of image face swapping into video: clean data, a smart model that knows what to keep versus what to change, and a training plan that targets the hardest moments.
Knowledge Gaps
Knowledge Gaps, Limitations, and Open Questions
Below is a single, consolidated list of concrete gaps and unresolved questions that future work could address:
- Dataset transparency and diversity: The portrait pretraining corpus for IVS and the filtered OpenHumanVid training set are insufficiently described (scale, demographics, identities, age ranges, occlusion types, lighting, motion blur, compression). Release and characterize the datasets to assess bias and coverage.
- Benchmark scale and availability: IDBench-V contains only 200 pairs; it is unclear if it is publicly released, has standardized splits, or includes annotations for controlled analyses (e.g., occlusion level, motion intensity). Expand, release, and stratify the benchmark.
- Multi-person control: Handling and evaluation for multi-person scenes is under-specified (e.g., how faces are selected/disambiguated; behavior under overlapping faces or face-to-face occlusions). Provide explicit multi-face selection mechanisms and metrics.
- Audio-driven mouth motion: The pipeline does not use audio or quantify lip-sync. Add audio conditioning and evaluate mouth motion accuracy with audio-visual sync metrics.
- Long-video scalability: Maximum supported video lengths, chunk-boundary artifacts, and temporal continuity across VAE chunks are not analyzed. Quantify identity drift/flicker across long sequences and chunk stitching strategies.
- Inference speed and compute cost: Training/inference latency, memory footprint, throughput, and scalability to production settings are missing. Report runtime profiles and optimize for real-time or near-real-time usage.
- Robustness to real-world degradations: Performance under compression, motion blur, low-light, rolling shutter, camera shake, and extreme resolution changes is not measured. Add stress tests and robustness evaluations.
- Pose/expression estimation failure modes: The 3DMM-based expression adaptation and landmark retargeting may fail under occlusion, extreme angles, or non-frontal views. Characterize failure rates and add fallback strategies.
- Background recomposition reliability: SAM2 and MiniMax-Remover may fail on complex dynamics; the impact of segmentation errors and feathering artifacts is not quantified. Provide error analyses and alternative compositing strategies.
- Identity leakage assessment: While expression adaptation aims to decouple identity and expression, leakage of source identity into swapped results is not directly measured. Introduce metrics that explicitly quantify identity leakage to the original subject.
- Modality-Aware Conditioning (MC) design ablation: The choice of channel concatenation for context, pose-attention for structure, and token concatenation for identity is not compared to alternative injection schemes (e.g., FiLM, cross-attention, adapters). Conduct systematic ablations.
- Choice and sensitivity of λ in pose-attention: The strength of pose injection via the λ parameter lacks sensitivity analysis. Report robustness ranges and adaptive scheduling strategies.
- Flow Matching vs DDPM training: The pipeline adopts Flow Matching; there is no comparison to DDPM/score-based training or analysis of convergence, stability, and sample quality differences. Provide training-method ablations.
- IRL formulation and stability: The “Q-weighted” IRL uses 1/(cosine similarity + δ) as Q without theoretical guarantees or stability analysis; per-chunk weighting and full sampling overhead are not quantified. Study stability, variance, and compute trade-offs; compare to alternative reward shaping.
- Identity encoder details and bias: The ID encoder and ArcFace/InsightFace/CurricularFace embeddings may introduce demographic biases. Audit performance across age, gender, skin tone, and cultural attire; consider debiased embeddings.
- Evaluation metric limitations: FVD’s content bias is acknowledged but not mitigated; motion smoothness from VBench may not capture flicker/identity drift. Include dedicated temporal identity consistency metrics, flicker metrics, and perceptual user studies with larger samples.
- Fair comparison scope: VividFace and DynamicFace are only qualitatively compared due to lack of code; image-based baselines perform frame-by-frame processing. Seek standardized evaluation or reproduce comparable pipelines to ensure fairness.
- Failure-case catalog: The paper highlights success in occlusions and extreme expressions but does not catalog systematic failure cases (e.g., accessories covering key landmarks, fast head turns, extreme profile shots). Provide detailed error taxonomy.
- Mask generation and dilation sensitivity: The quality and source of face masks, dilation parameters, and their impact on artifacts are not reported. Perform sensitivity studies and refine mask strategies.
- Identity-coherence variance analysis: Identity similarity variance is reported but not broken down by pose bins (frontal vs profile), motion intensity, or occlusion level. Provide pose- and motion-conditioned analyses.
- Generalization to non-human or stylized domains: Claims include animation handling, but generalization to cartoons, stylized content, or non-human faces is not systematically evaluated. Add domain-specific benchmarks.
- Ethical safeguards and misuse mitigation: Consent, watermarking, provenance tracking, and deepfake detectability are not discussed. Integrate ethical guardrails, detection resistance/compatibility, and responsible release practices.
- Privacy and licensing: The licensing and consent of OpenHumanVid and other sources, plus the handling of sensitive identities, are not detailed. Clarify licensing, consent procedures, and privacy protections.
- Versatility beyond faces: Extension to outfits/accessories/hairstyles is shown qualitatively but lacks task-specific metrics (e.g., garment consistency, accessory placement accuracy, hair boundary naturalness). Develop quantitative evaluations for these tasks.
- RoPE alignment under variable frame rates/resolutions: Reusing RoPE indices for pose-latent alignment may be brittle across frame rate changes or resolution mismatch. Evaluate alignment robustness and propose normalization strategies.
- First–Last-Frame reliance in IVS: The dependency on keyframes for IVS may limit complex motion interpolation or identity changes mid-sequence. Explore multi-keyframe conditioning and adaptive interpolation.
- Handling extreme lighting/shadows: Attribute preservation for lighting is claimed but not measured against photometric metrics. Add lighting consistency metrics and physically plausible shading assessments.
- Release artifacts and reproducibility: Some key components (e.g., expression adaptation, enhanced background recomposition parameters) are “in supplementary.” Ensure full reproducibility via code, configs, and model checkpoints.
Practical Applications
Immediate Applications
The following applications can be deployed with the methods, data pipeline, and benchmark described in the paper, primarily in offline or near–real-time settings using current GPU infrastructure.
- High-fidelity face replacement in post-production
- Sector: Film/TV, advertising, creator economy
- What: Replace an actor’s face while preserving pose, expressions, lighting, background, and motion without temporal flicker (using DreamID-V with Modality-Aware Conditioning, Synthetic-to-Real curriculum, and IRL for identity coherence).
- Tools/products/workflows:
- NLE/VFX plugins (Premiere/After Effects/Nuke/DaVinci) that take source identity images and a target video and run DreamID-V as an offline batch.
- Studio pipelines integrating SyncID-Pipe to build internal paired data for studio-specific identities and shot conditions.
- Assumptions/dependencies: Proper rights/consent for identities; GPU compute; high-quality reference frames; shot-appropriate masks; adherence to studio safety and disclosure policies.
- ADR and localization without reshoots (lip and expression preservation)
- Sector: Media localization, education content
- What: Replace the on-screen identity or align expressions/mouth shapes to new audio while maintaining original scene attributes (leveraging structural guidance via pose and IRL to reduce temporal drift).
- Tools/products/workflows:
- “Localization pass” service using DreamID-V on dialogue-heavy content with pose/expression control.
- Assumptions/dependencies: Quality audio-to-expression drivers or reliable expression extraction; legal/union compliance; multi-lingual QA.
- Consent-based privacy protection and de-identification for video
- Sector: Journalism, healthcare operations, public safety, enterprise compliance
- What: Replace faces with authorized alternatives that preserve scene context, body motion, and timing (better than simple blurring), supporting auditability.
- Tools/products/workflows:
- Policy-driven anonymization pipelines (e.g., newsroom redaction tools) using DreamID-V with masks and pose guidance.
- Assumptions/dependencies: Organization-specific consent policies; watermarking/provenance; latency tolerances; risk review for re-identification.
- Creator tools for safe identity transfer in user-generated content
- Sector: Social media, livestreaming studios (offline or scheduled content)
- What: High-quality, low-flicker face swap for skits and remixes where rights/consent exist; better attribute preservation than frame-by-frame IFS.
- Tools/products/workflows:
- Cloud API/SDK offering DreamID-V “video swap” jobs; moderation hooks; visible disclosure labels.
- Assumptions/dependencies: Platform policy gates, consent capture, content moderation, usage quotas.
- Synthetic data generation to improve video identity tasks
- Sector: Vision/ML (academia and industry)
- What: Use SyncID-Pipe and IVS to generate paired, identity-consistent video data for training or evaluating tracking, re-identification, or face recognition under motion and occlusion.
- Tools/products/workflows:
- Data engine that constructs bidirectional ID quadruplets for curriculum training or robustness evaluation.
- Assumptions/dependencies: Domain shift management; dataset licensing; demographic coverage; detection/mitigation of bias.
- Benchmarking and procurement using IDBench-V
- Sector: Academia, technology procurement, standards bodies
- What: Evaluate identity consistency, attribute preservation, and video quality across methods; compare vendors; establish internal acceptance thresholds for production.
- Tools/products/workflows:
- Model scoring dashboards; regression tests for updates; acceptance checks in MLOps.
- Assumptions/dependencies: Public availability of IDBench-V and metric implementations; agreement on threshold metrics.
- Generalized human-centric swaps beyond faces (accessories/outfits/hairstyles)
- Sector: E-commerce (try-on), fashion, advertising, virtual production
- What: Extend SyncID-Pipe by swapping IFS with image editing models to build paired data for accessory/outfit/hair swaps in video, preserving scene dynamics.
- Tools/products/workflows:
- “Virtual try-on” video services for products (headphones, hats, glasses, hairstyles); catalog-to-video fitting room.
- Assumptions/dependencies: Product digitization/image priors; robust mask extraction (e.g., SAM2); IP agreements with brands.
- Storyboard-to-shot previsualization with pose-driven IVS
- Sector: Previz, animation, game cinematics
- What: Use IVS (First–Last–Frame + pose) to quickly synthesize plausible motion between keyframes for planning camera, blocking, and timing.
- Tools/products/workflows:
- Previz tool that ingests keyframes and pose sequences and outputs motion prototypes; downstream swap with DreamID-V as needed.
- Assumptions/dependencies: Access to or training of IVS on studio data; director-tuned pose sequences; compute availability.
- Flicker reduction and robustness improvements for existing video diffusion pipelines
- Sector: Software/ML infrastructure
- What: Adopt Identity-Coherence Reinforcement Learning (IRL) and the Synthetic-to-Real curriculum as drop-in training recipes to stabilize identity and motion in other video-editing/generation models.
- Tools/products/workflows:
- Training scripts and adapters porting Q-weighted flow-matching to current models; before/after quality dashboards.
- Assumptions/dependencies: Availability of per-frame identity or structural quality signals; training compute; reproducible sampling.
- Editorial continuity and scene integrity tooling
- Sector: Post-production QC
- What: Enhanced Background Recomposition and MC-driven masking to preserve scene backgrounds and subject consistency; automated checks with VBench metrics.
- Tools/products/workflows:
- QC modules verifying background consistency and motion smoothness before delivery.
- Assumptions/dependencies: Reliable segmentation (SAM2), removal (MinimaxRemover), and feathering; edge-case handling in crowded scenes.
Long-Term Applications
These applications are feasible but require further research, scaling, real-time optimization, broader safety infrastructure, or ecosystem alignment.
- Real-time or low-latency face swapping for live scenarios
- Sector: Live broadcasting, telepresence, gaming, conferencing
- What: On-device or edge-accelerated DreamID-V variants delivering stable identity transfer with minimal delay.
- Tools/products/workflows:
- Hardware-accelerated inference pipelines; model distillation/quantization; streaming SDK integrations.
- Assumptions/dependencies: Significant model optimization; hardware support (NPUs/GPUs on edge); robust safety layers (watermarking, live consent flows).
- Personalized virtual presenters and AI avatars at production quality
- Sector: Education, corporate training, customer support, entertainment
- What: Persistent avatar doubles with high-fidelity expressions and identity coherence across long-form content and multiple scenes.
- Tools/products/workflows:
- Avatar CMS linking identity embeddings, wardrobe/accessories swaps, and scene templates; voice and gesture control.
- Assumptions/dependencies: Long-context temporal consistency, multi-scene continuity, rights management, cross-modal alignment.
- Forensic watermarking, provenance, and policy toolkits for synthetic video
- Sector: Policy, platform trust/safety, standards
- What: Standardized provenance tagging for swap-based edits and automated detection calibrated on IDBench-V–like evaluations.
- Tools/products/workflows:
- Mandatory watermark insertion modules; C2PA-like manifests; detection benchmarks and red-team suites derived from IDBench-V.
- Assumptions/dependencies: Multi-stakeholder standards adoption; low false-positive/negative rates; legal frameworks.
- Large-scale, demographically balanced training and evaluation for fair deployment
- Sector: Academia, regulators, enterprise compliance
- What: Expanded paired video corpora using SyncID-Pipe to measure and mitigate identity, lighting, and motion biases at scale.
- Tools/products/workflows:
- Fairness auditing pipelines; bias dashboards; curriculum schedules per subgroup.
- Assumptions/dependencies: Access to diverse, consented datasets; governance boards; transparent reporting requirements.
- Cross-modal editing: audio-driven expression and multilingual face relighting/retargeting
- Sector: Media localization, accessibility
- What: Robust audio-to-expression control fused with pose and identity modules for multilingual, emotion-preserving dubbing and relighting.
- Tools/products/workflows:
- Joint training with speech-to-expression models; controllable MC interfaces for editors (pose, expression, identity sliders).
- Assumptions/dependencies: Accurate audio-expression mapping; generalization across languages; fine control over relighting.
- End-to-end production suites for human-centric swaps (face, hair, outfit, accessories) with continuity management
- Sector: Virtual production, fashion media, commerce
- What: Unified pipeline that manages wardrobe continuity, product placement, and identity consistency across entire episodes/campaigns.
- Tools/products/workflows:
- Asset libraries; continuity trackers; auto-resolve tools for occlusions and multi-person shots.
- Assumptions/dependencies: Complex multi-identity, multi-shot constraint solving; asset IP agreements; robust scene understanding.
- Training data engines for downstream perception models
- Sector: Robotics, autonomous systems, security analytics
- What: Generate controlled, identity-consistent video under varied motion, occlusion, and lighting to train perception systems without privacy exposure.
- Tools/products/workflows:
- Scenario generators (pose programs, occluder libraries); evaluation harnesses for temporal coherence.
- Assumptions/dependencies: Demonstrated transfer to real-world distributions; acceptance by regulators; synthetic–real gap quantification.
- Mobile on-device private editing
- Sector: Consumer software
- What: Privacy-preserving local swaps for diaries, family videos, or masked sharing (no cloud upload).
- Tools/products/workflows:
- Compressed DiT variants; on-device segmentation; peer-to-peer provenance tagging.
- Assumptions/dependencies: Strong model compression; battery/thermal constraints; intuitive UX and consent UX.
- Interactive directing of motion with pose programs
- Sector: Creative tools, animation
- What: Creator-facing “pose programming”—design motion via 3D landmarks/pose sequences that IVS/DreamID-V realize with identity preservation.
- Tools/products/workflows:
- Pose timeline editors; libraries of motion motifs; real-time previews.
- Assumptions/dependencies: Authorable pose abstractions; stable control over long durations; artist-in-the-loop interfaces.
- Regulatory sandboxing and certification processes
- Sector: Policy, compliance
- What: Formal evaluation regimes where vendors certify identity preservation, attribute fidelity, temporal stability, and watermark compliance using standardized benchmarks (e.g., IDBench-V variants).
- Tools/products/workflows:
- Certification kits; periodic re-testing; incident reporting integrations.
- Assumptions/dependencies: Regulator–industry alignment; evolving standards; verifiable audit trails.
Notes on feasibility and cross-cutting dependencies
- Compute and performance: Diffusion Transformers are compute-intensive; immediate deployments are better suited for offline/batch workflows. Real-time use requires significant optimization, distillation, or specialized hardware.
- Data and consent: All identity transfers require explicit consent, rights management, and disclosure. Practical deployments should include watermarking/provenance and audit logs.
- Tooling dependencies:
- Segmentation (e.g., SAM2) and background handling (MinimaxRemover) quality affect edge cases (occlusions, crowded scenes).
- 3D face reconstruction for expression adaptation and pose retargeting must be robust across demographics and lighting.
- Pose/keyframe foundation models (IVS/FLF2V) availability and licensing affect reproducibility.
- Generalization and bias: Performance on diverse demographics, extreme poses, and low-light scenes depends on curation breadth in SyncID-Pipe and training data scale.
- Safety and platform policy: Deployment in consumer or live settings requires detection, provenance, rate limits, and human-in-the-loop review to mitigate misuse.
Glossary
- Adaptive Pose-Attention: An attention mechanism that injects motion/pose information into a diffusion transformer while preserving existing features. "we introduce an Adaptive Pose-Attention mechanism to inject motion information."
- ArcFace: A face recognition model/loss that measures identity similarity via angular margins in embedding space. "For Identity Consistency, we employ ArcFace~\cite{deng2019arcface}, InsightFace~\cite{insightface_website}, and CurricularFace~\cite{huang2020curricularface} to compute ID similarity."
- Bidirectional ID quadruplets: Paired supervision data consisting of source/target images and videos in both forward (synthetic) and backward (real) directions. "we construct bidirectional ID quadruplet training data, anchored by IFS, to enable explicit supervision."
- Canonical space: A normalized, identity-agnostic space where face operations are performed before mapping back to real videos. "CanonSwap~\cite{luo2025canonswap} proposes a canonical space, performing face swapping within this space before projecting back to the real domain."
- Conditional inpainting: Generative filling of masked regions conditioned on guidance (e.g., identity), used here for face swapping. "VividFace~\cite{shao2024vividface} models video face swapping as a conditional inpainting task"
- CurricularFace: A face recognition loss that adapts difficulty over training to improve embedding quality. "For Identity Consistency, we employ ArcFace~\cite{deng2019arcface}, InsightFace~\cite{insightface_website}, and CurricularFace~\cite{huang2020curricularface} to compute ID similarity."
- Diffusion Transformer (DiT): A diffusion-based generative model that replaces U-Nets with transformers for scalable video generation. "we develop DreamID-V, the first video face swapping framework based on Diffusion Transformer (DiT) models"
- Enhanced Background Recomposition: A data augmentation module that replaces backgrounds to better align with real video dynamics. "we design an Enhanced Background Recomposition module."
- Expression adaptation: A process to decouple identity and expression for clean expression transfer without identity leakage. "we use an expression adaptation module to decouple identity and expression"
- First-Last-Frame video foundation model (FLF2V): A keyframe interpolation model conditioned on the first and last frames to generate intermediate video. "conditioning a First-Last-Frame video foundation model (FLF2V)~\cite{gao2025seedance}"
- Flow Matching: A training objective for generative models aligning trajectories between noise and data distributions via vector fields. "The model is optimized using Flow Matching~\cite{lipman2023flow}."
- Fréchet Video Distance (FVD): A perceptual metric for video quality comparing feature distributions between real and generated videos. "using the Fréchet Video Distance (FVD)~\cite{ge2024content}"
- Identity-Anchored Video Synthesizer (IVS): A pose-driven video generator conditioned on keyframes and pose sequences to produce identity-consistent videos. "we introduce a simple yet effective Identity-Anchored Video Synthesizer (IVS) to generate pair data for explicitly supervised training."
- Identity-Coherence Reinforcement Learning (IRL): A reinforcement learning strategy that emphasizes frames with low identity fidelity to improve temporal consistency. "we introduce the Identity-Coherence Reinforcement Learning (IRL) mechanism"
- Image Face Swapping (IFS): Swapping identity in images while preserving target attributes; used here to bootstrap video supervision. "Unlike Image Face Swapping (IFS), Video Face Swapping (VFS) presents more challenges"
- InsightFace: A toolkit/model suite for face recognition used to compute identity similarity metrics. "For Identity Consistency, we employ ArcFace~\cite{deng2019arcface}, InsightFace~\cite{insightface_website}, and CurricularFace~\cite{huang2020curricularface} to compute ID similarity."
- Keyframe interpolation models: Video models that synthesize in-between frames given keyframes (e.g., first and last frames). "a growing number of keyframe interpolation models~\cite{gao2025seedance} have emerged (e.g., First-Last-Frame models)"
- Latent diffusion methods: Generative diffusion models that operate in a compressed latent space rather than pixel space. "Early latent diffusion methods~\cite{ho2022video, blattmann2023stable, guo2023animatediff} extended Text-to-Image models"
- MinimaxRemover: A video object removal tool used to obtain clean backgrounds by removing foreground subjects. "We then utilize MinimaxRemover~\cite{ravi2024sam2} to remove the foreground from "
- Modality-Aware Conditioning (MC): A conditioning design that injects identity, structure, and context into the model in a disentangled, modality-specific way. "we first introduce a Modality-Aware Conditioning (MC) mechanism"
- Patchification: Converting images/videos into non-overlapping patches to form tokens for transformer-based processing. "we concatenate them with the latent noise after patchification along the token dimension"
- Pose Guider: A lightweight module that encodes pose sequences into features aligned with latent representations for attention injection. "We employ a lightweight Pose Guider composed of several simple convolutional layers"
- Q-value: A scalar measure of action quality in RL; here inversely related to identity similarity to emphasize hard frames. "we ... define an efficient and explicit Q-value."
- Rotary Position Embedding (RoPE): A positional encoding that enables relative position awareness in attention via rotations in feature space. "we reuse the Rotary Position Embedding (RoPE)~\cite{su2024roformer} indices from the noisy latents"
- SAM2: A segmentation model (Segment Anything 2) used to extract foreground masks in videos. "we first extract foreground masks from and using SAM2~\cite{ravi2024sam2}."
- Synthetic-to-Real Curriculum: A training strategy that starts with synthetic pairs for easier convergence, then fine-tunes on real pairs for realism. "we design a novel Synthetic-to-Real Curriculum learning strategy"
- VAE-encoded chunk: A segment of video encoded by a Variational Autoencoder, used here for loss weighting in training. "for each VAE-encoded chunk."
- VBench: A benchmark suite providing metrics to evaluate video generative models, such as background and motion consistency. "we incorporate three metrics from VBench~\cite{huang2024vbench}"
- Video Face Swapping (VFS): Swapping the identity of a person into a target video while preserving the original video’s attributes and temporal coherence. "Video Face Swapping (VFS) requires seamlessly injecting a source identity into a target video"
Collections
Sign up for free to add this paper to one or more collections.