- The paper introduces a memory bank compression method using codebook quantization and online resetting to drastically reduce memory usage while maintaining high QA performance.
- It utilizes a modular KV-LoRA adaptation in attention layers, enabling scalable and efficient online continual learning with minimal parameter overhead.
- Empirical results demonstrate up to 99.2% memory reduction and significant gains in both EM and F1 scores, with strong retention against catastrophic forgetting.
Memory Bank Compression for Continual Adaptation of LLMs
Introduction and Motivation
LLMs have catalyzed major advances in NLP, but their static pretraining paradigm remains a critical bottleneck for knowledge freshness and continual adaptation. Standard fine-tuning and parameter-efficient methods in continual learning are computationally demanding and exacerbate catastrophic forgetting. Memory-augmented approaches, where an external memory bank stores knowledge, have proven promising for online adaptation by decoupling model weights from new knowledge acquisition. However, as document streams scale, the unbounded growth of the memory bank degrades both storage efficiency and inference speed, fundamentally limiting real-world applicability.
This paper introduces Memory Bank Compression (MBC), a model for scalable continual adaptation of LLMs that strategically compresses the memory bank using codebook-based quantization and online resetting, while employing modular low-rank adaptation at the attention layer level. The authors empirically demonstrate that MBC preserves and even improves question-answering (QA) accuracy relative to state-of-the-art baselines, despite reducing memory bank size to just 0.3% of prior approaches (2601.00756).
Model Architecture and Methodology
Modular Memory-Augmented Design
MBC extends memory-augmented adaptation by first encoding documents with an amortization network into context vectors, which are stored in an external memory bank. Unlike previous work that stores high-dimensional continuous representations, MBC applies a vector-quantized codebook, storing only integer indices corresponding to code vectors. This drastically reduces storage costs and lookup times (Figure 1).
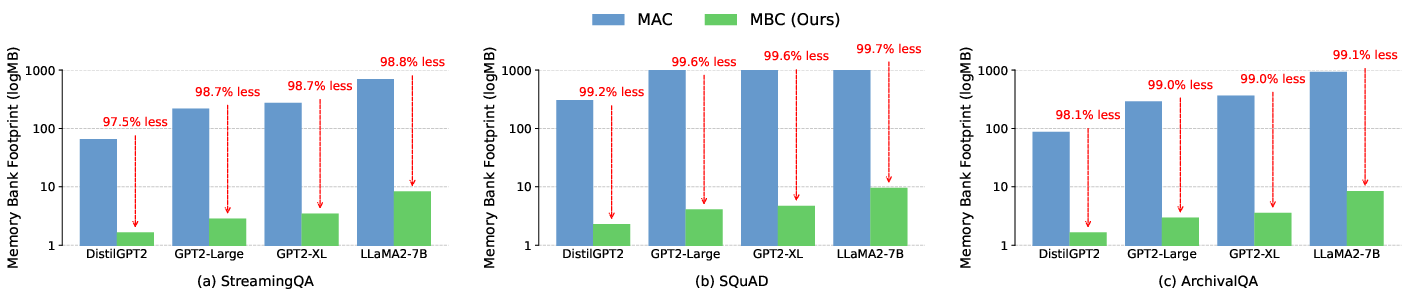
Figure 1: Memory bank footprint (logMB) of MAC and MBC across StreamingQA, SQuAD, and ArchivalQA. MBC achieves several orders of magnitude more efficient storage.
A permutation-invariant aggregation network then takes the query and the codebook-retrieved context vectors to synthesize a modulation vector for injection into the LLM via a soft prefix tuning approach.
Codebook Optimization and Compression
Drawing inspiration from VQ-VAE, MBC introduces a learned codebook E∈RNc×D; each new document's representation is quantized to its nearest code entry, and only this index is stored in the compressed memory. This architectural shift yields an extreme compression ratio, critically enabling large-scale, streaming adaptation.
Preventing Codebook Collapse
A challenge with codebook-based quantization is underutilization and code collapse. MBC addresses this via EMA-tracked usage statistics for each code; rarely used codes are periodically reset based on current batch document encodings, ensuring code diversity and preventing representational bottlenecks. This mechanism is empirically shown to maintain high codebook perplexity and stable training dynamics (Figure 2).
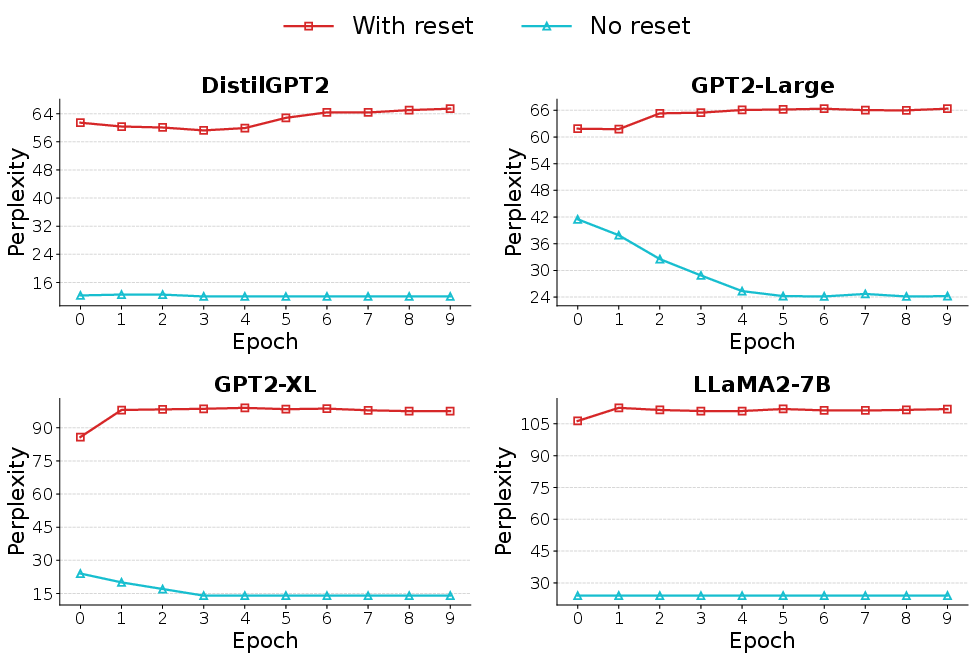
Figure 2: Perplexity over train epochs on StreamingQA with and without codebook resetting in MBC, across all base LLMs, demonstrating stability and prevention of codebook collapse.
KV-LoRA Modulation
Beyond frozen-base approaches, MBC introduces Key-Value Low-Rank Adaptation (KV-LoRA) modules only into attention layers, boosting adaptation without the overhead of full fine-tuning. Modulation vectors generated from aggregated memory are injected via soft prefixes, and low-rank updates provide additional flexibility and performance gain.
End-to-End and Online Adaptation Process
The entire architecture—including the amortization network, codebook, aggregation network, and KV-LoRA modules—is trained end-to-end with a joint objective of QA loss and vector quantization loss, balanced by a hyperparameter. Online adaptation then requires only fast forward passes: each incoming document is encoded and quantized, its code stored; inference performs code lookup and aggregation to produce modulations conditioning answer generation. No retraining or gradient updates are necessary during deployment, making the approach well-suited to nonstationary, high-velocity data streams.
Empirical Results
MBC achieves drastic memory savings across all backbone models and datasets. For instance, while the MAC baseline’s memory requirements scale linearly with the number and size of stored document modulations, MBC’s quantized indices and compact codebook reduce memory usage by up to 99.2% (Figure 1). This enables practical deployment even with millions of documents and large models (up to LLaMA-2-7B).
Despite substantial compression, MBC consistently improves both EM and F1 metrics over all baselines, including parameter-efficient (PEFT) and other memory-augmented methods. On average across datasets and model sizes, MBC achieves gains of 11.84% (EM) and 12.99% (F1) over MAC. Notably, this improvement comes with negligible extra parameter overhead (less than 0.5%).
Retention and Catastrophic Forgetting
The authors measure knowledge retention under continued online adaptation, tracking F1 score on early-adapted documents as new documents are added. MBC retains almost all performance from earlier documents, closely matching (or exceeding) retention rates of memory-augmented baselines, thereby exhibiting strong resistance to catastrophic forgetting—even as memory usage remains orders of magnitude lower.
Codebook Resetting Efficacy
MBC’s EMA-based resetting successfully prevents codebook collapse, as evidenced by stable codebook perplexity throughout training. Ablations without online resetting lead to rapid collapse and degraded representation diversity, especially in larger models (Figure 2). Effective code utilization is thus shown to be crucial for both compression performance and learning stability.
Implications and Prospects
The design and results of MBC have significant implications for both production LLM lifecycles and foundational research on continual learning in NLP.
Practical Implications: MBC removes a major barrier to deploying memory-augmented LLMs in environments where data streams are large, rapidly-evolving, and retention is critical—such as long-term personal assistants, chatbots, or enterprise search. Unlike previous approaches, memory bank growth is no longer prohibitive, and compression does not degrade accuracy.
Theoretical Significance: This work substantiates that aggressive memory quantization is feasible in the context of continual adaptation, provided that codebook health is actively managed. Injecting lightweight adaptation only where it is most effective (i.e., attention mechanisms) offers a new paradigm for balancing stability-plasticity tradeoffs.
Future Directions: The methodology could be extended in several promising directions:
- Dynamic and Adaptive Memory Control: Employing reinforcement learning to optimize memory admission, eviction, and codebook composition based on downstream utility or environment signals.
- Federated and Distributed Continual Learning: Partitioned or sharded memory banks could enable privacy-preserving, cross-institutional knowledge transfer and update without centralization.
- Generalization Beyond QA: Adapting the compression-aggregation approach for generative, multi-hop reasoning, or multimodal continual learning tasks.
Conclusion
MBC constitutes a principled advance in the architectural and algorithmic design of memory-augmented LLMs for continual learning. By combining end-to-end codebook-based memory compression, robust code utilization management, and modular KV-LoRA adaptation, MBC achieves both superior empirical performance and unprecedented scalability for streaming adaptation scenarios. The work lays a foundation for future research into efficient, long-lived, and adaptive LLMs.