- The paper finds that compressing LSTM models to 64 hidden units reduces MAPE from 23.6% to 12.4% while decreasing model size by 73%.
- The methodology leverages systematic evaluation on a Kaggle dataset using time-series cross-validation and TensorFlow on a CPU to simulate resource-constrained settings.
- The study highlights practical implications for SMEs, enabling advanced forecasting with reduced computational demands and cost-effective deployment.
Optimizing LSTM Neural Networks for Resource-Constrained Retail Sales Forecasting: A Model Compression Study
Introduction
This paper investigates the optimization of Long Short-Term Memory (LSTM) neural networks through model compression for retail sales forecasting, specifically targeting resource-constrained environments. Retail forecasting plays a crucial role in minimizing inventory-related losses, yet traditional LSTM models, with their substantial computational and memory requirements, pose challenges for small to medium-sized enterprises (SMEs) with limited IT budgets. The study explores the compression of LSTM models by reducing the number of hidden units, thereby aiming to enhance computational efficiency without compromising predictive accuracy.
Methodology
Dataset and Architecture
The research utilizes the Kaggle Store Item Demand Forecasting dataset, comprising approximately 913,000 daily sales records from 10 stores across 50 items over a five-year period. A systematic evaluation of LSTM architectures with hidden units ranging from 128 to 16 is conducted to identify an optimal configuration that balances accuracy with efficiency.
Model Configurations
Five different LSTM configurations—LSTM-128, LSTM-64, LSTM-48, LSTM-32, and LSTM-16—are examined. Each configuration maintains the same architectural framework apart from the number of hidden units. The methodology incorporates best practices for feature engineering in time-series forecasting and evaluates model performance based on Mean Absolute Percentage Error (MAPE), Root Mean Square Error (RMSE), and efficiency metrics (model size, inference time, RAM usage).
Experimental Setup
Experiments are implemented on a standard CPU setup using TensorFlow, with no GPU deployment to faithfully simulate resource-constrained environments. The training involves an 80/20 temporal split with 30 epochs and a batch size of 64. Performance is validated through cross-validation of time-series data.
Results
Accuracy and Computational Efficiency
The study finds that reducing the hidden units to 64 significantly improves the model's accuracy, achieving a MAPE of 12.4%, a notable reduction from the 23.6% MAPE of the 128-unit baseline. This is accompanied by a 73% reduction in model size (from 280KB to 76KB). Additionally, inference times remain constant across model variants due to TensorFlow's fixed overhead, affirming that the smaller models do not sacrifice speed or memory efficiency.
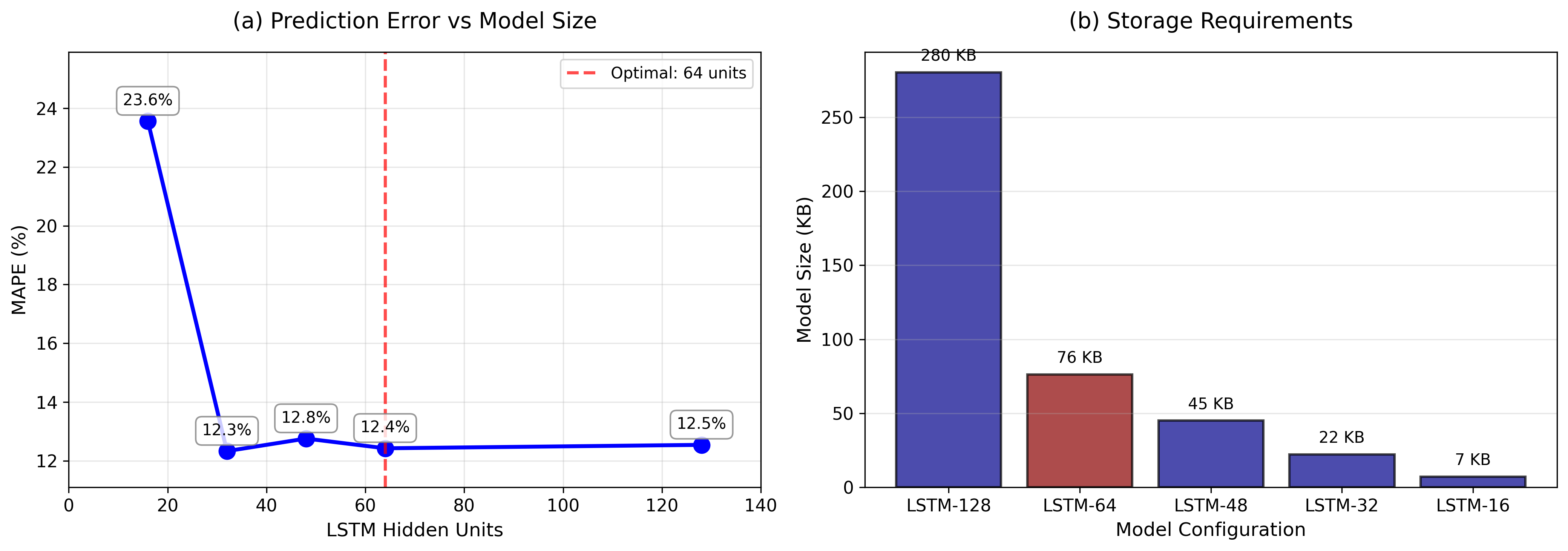
Figure 1: (a) Prediction Error vs. Model Size shows the U-shaped relationship between the size of the model and its accuracy. (b) Storage Requirements showing that the model size goes down in a straight line as the number of hidden units goes down.
The compressed LSTM-64 model demonstrates a strong alignment between predicted and actual sales over a 100-day evaluation period, verifying the model's robustness and practical applicability in real-world scenarios.
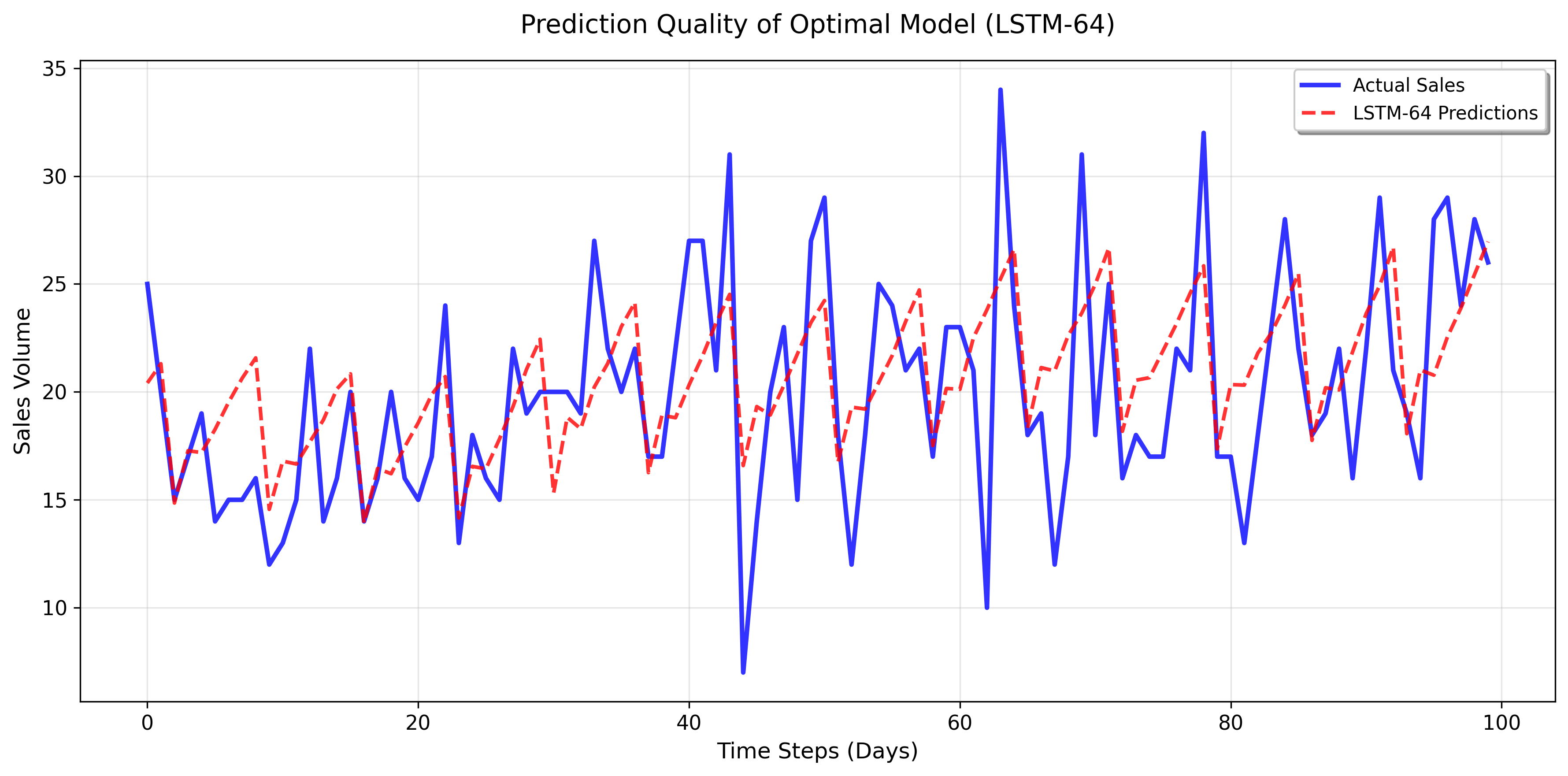
Figure 2: Sample predictions from LSTM-64 showing close alignment between predicted and actual sales over a 100-day period.
Comparative Analysis
Performance analysis, including inference speed and RAM needs, indicates that moderate compression (64 units) provides the best trade-off between model size and accuracy. Statistical tests (paired t-tests) further validate the significance of improvement over larger baseline models.
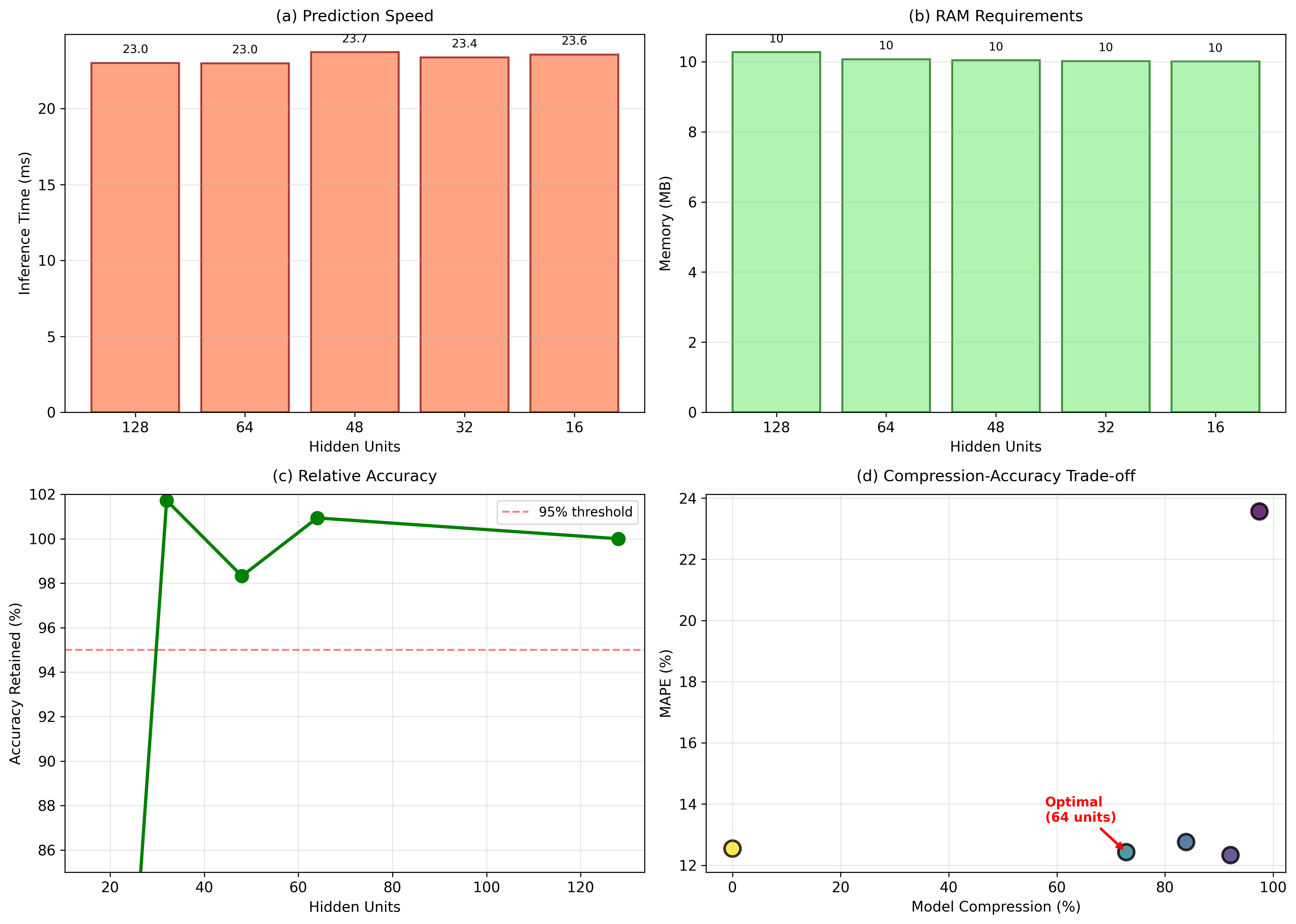
Figure 3: A full performance analysis that shows (a) inference speed, (b) RAM needs, (c) relative accuracy compared to the baseline, and (d) the trade-off between compression and accuracy, with LSTM-64 being the best choice.
Discussion
The study challenges the conventional understanding that larger models yield superior performance. Notably, the LSTM-64 configuration optimally captures temporal dependencies in retail sales data with minimal computational demands. These findings align with the lottery ticket hypothesis and underscore the importance of selecting an appropriate model size.
Practical Implications
For SMEs, adopting the LSTM-64 model offers a practical solution for achieving high forecasting accuracy with significantly reduced computational costs. This enables broader accessibility to advanced predictive analytics without necessitating GPU-based infrastructures, thereby empowering a larger segment of the retail market to leverage sophisticated forecasting techniques.
Limitations and Future Work
The study's generalizability is limited to the specific Kaggle dataset and single-layer LSTM architectures. Future research could explore advanced compression methods such as pruning, quantization, and the integration of multi-layer or transformer architectures to further validate and expand upon these findings across different datasets and domains.
Conclusion
This research articulates the efficacy of LSTM model compression, showing that significant reductions in hidden units can enhance accuracy and efficiency in retail sales forecasting. The findings provide actionable insights for optimizing LSTM architectures, facilitating broader deployment of AI-driven solutions in resource-constrained environments. The study invites further exploration of hybrid and transformer-based models to continue advancing the field of time-series forecasting.