- The paper highlights that LSTM networks effectively capture complex nonlinear patterns and long-term dependencies in financial data, significantly outperforming ARIMA.
- The methodology leverages both raw sequence data and feature-engineered inputs, revealing that reduced feature noise can enhance LSTM performance.
- The findings imply that deep learning models, particularly LSTM networks, offer robust tools for financial forecasting and can guide future market prediction research.
Forecasting S&P 500 Using LSTM Models
Introduction
This paper examines the application of Long Short-Term Memory (LSTM) networks in forecasting the S&P 500 Index (SPX), highlighting its effectiveness against traditional models like ARIMA. Financial data introduces challenges due to its high volatility and complex nonlinear dependencies. Traditional models such as ARIMA, although effective for linear and short-term forecasting, fall short in capturing these nonlinear and long-term patterns. In contrast, LSTM networks address these limitations by utilizing their unique architecture capable of handling both short- and long-term dependencies, making them more suitable for financial data forecasting.
Methodology
Data Sources and Features
The dataset encompasses daily data for the SPX from October 2013 to September 2024, including metrics such as moving averages, RSI, pricing, volume, volatility, and various market indices. Selecting features based on their correlation with SPX closing prices (Figure 1) ensures the LSTM model utilizes the most predictive information.
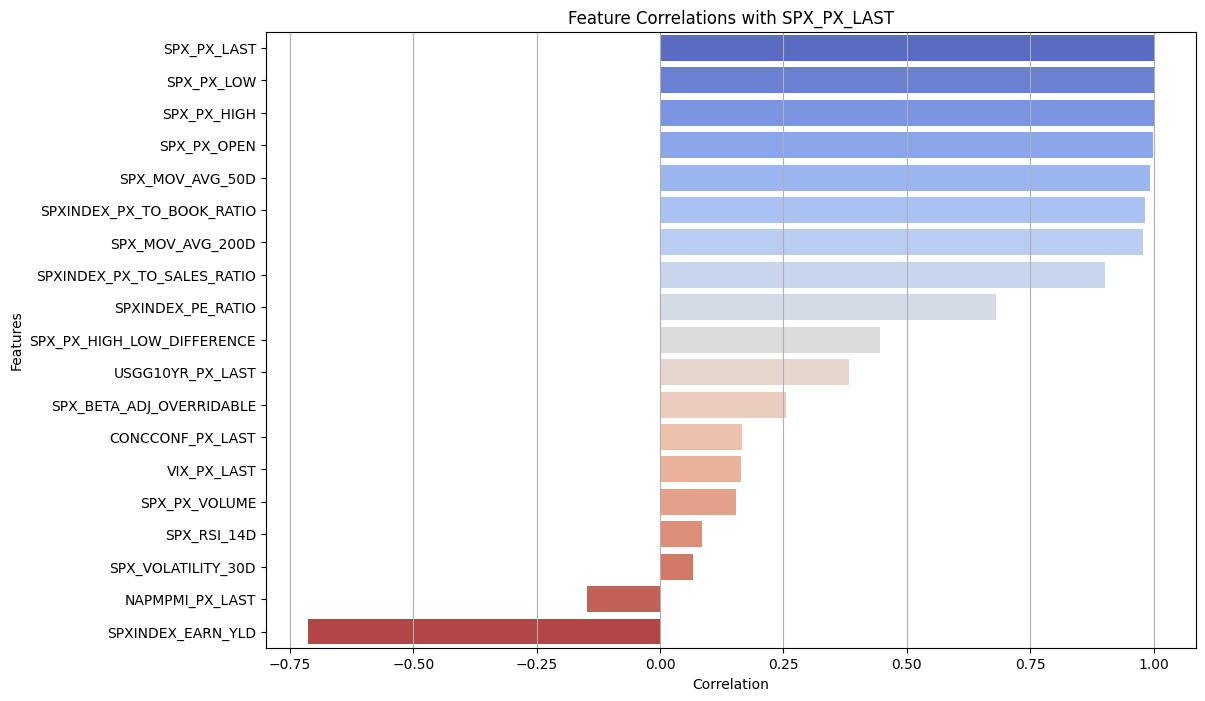
Figure 1: Price Correlation with Features.
Models Overview
- ARIMA: A statistical model requiring stationary data, applied using Auto-ARIMA to select optimal parameters.
- LSTM: A deep learning model featuring two LSTM layers with 64 neurons each, optimized with dropout layers and using the Adam optimizer. It utilizes sequences of past values as inputs to predict future index levels.
Experimentation
The performance of both models was measured using MAE, RMSE, and accuracy, with data splitting ensuring rigorous training and testing phases. ARIMA focused solely on the SPX closing price, while LSTM also incorporated additional features to refine predictions.
ARIMA Model
The ARIMA model captured short-term trends effectively but was constrained by its linear assumption, yielding an MAE of 462.1, an RMSE of 614, and an accuracy of 89.8%. Its performance decreased over time as it struggled with longer-term dependencies inherent in financial data (Figure 2).
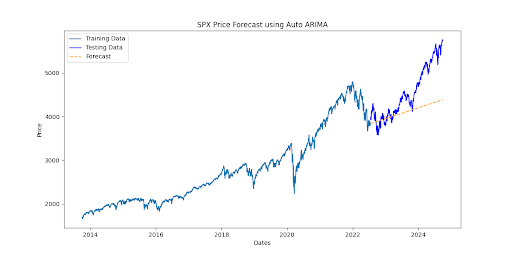
Figure 2: ARIMA model.
LSTM Model
LSTM, both with and without additional features, outperformed the ARIMA model significantly. The model with features achieved an MAE of 369.32 and an RMSE of 412.84, with an accuracy of 92.46% (Figure 3). Interestingly, the LSTM model without additional features demonstrated superior performance with an MAE of 175.9, an RMSE of 207.34, and an accuracy of 96.41% (Figure 4). This indicates that LSTM's intrinsic ability to capture temporal patterns suffices without supplementary data, although further improvements could be addressed with additional feature engineering.
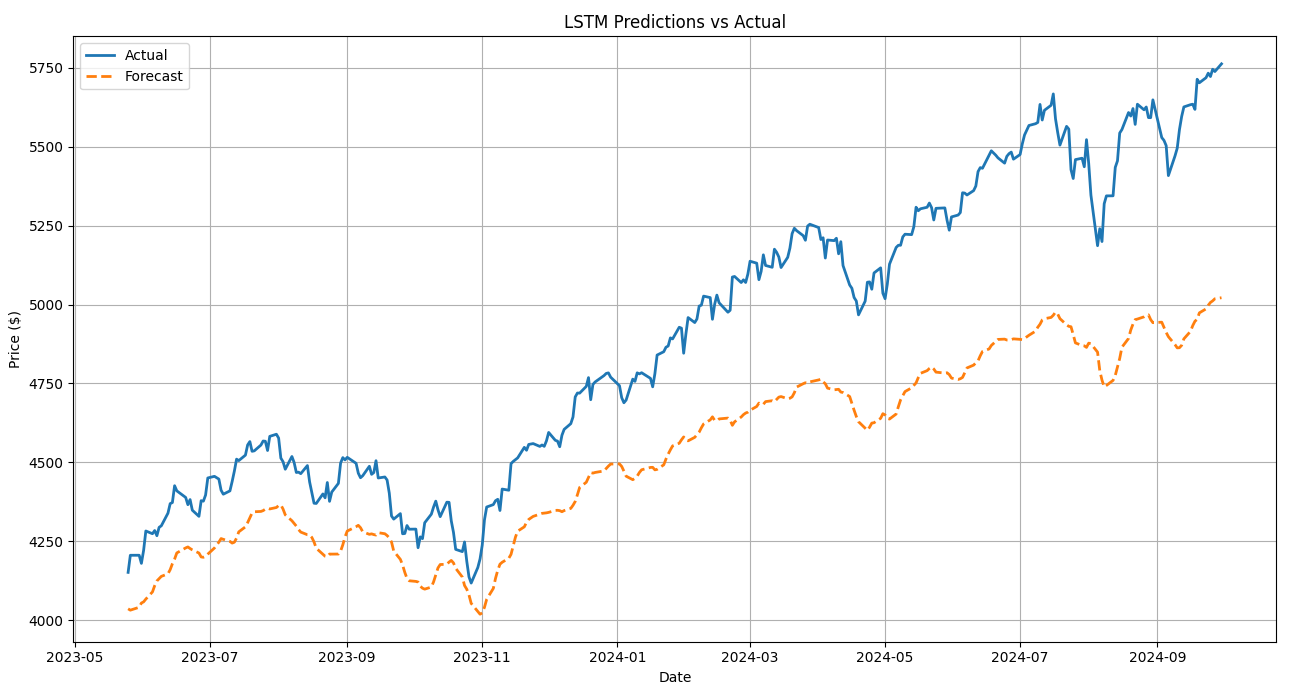
Figure 3: LSTM model with features.
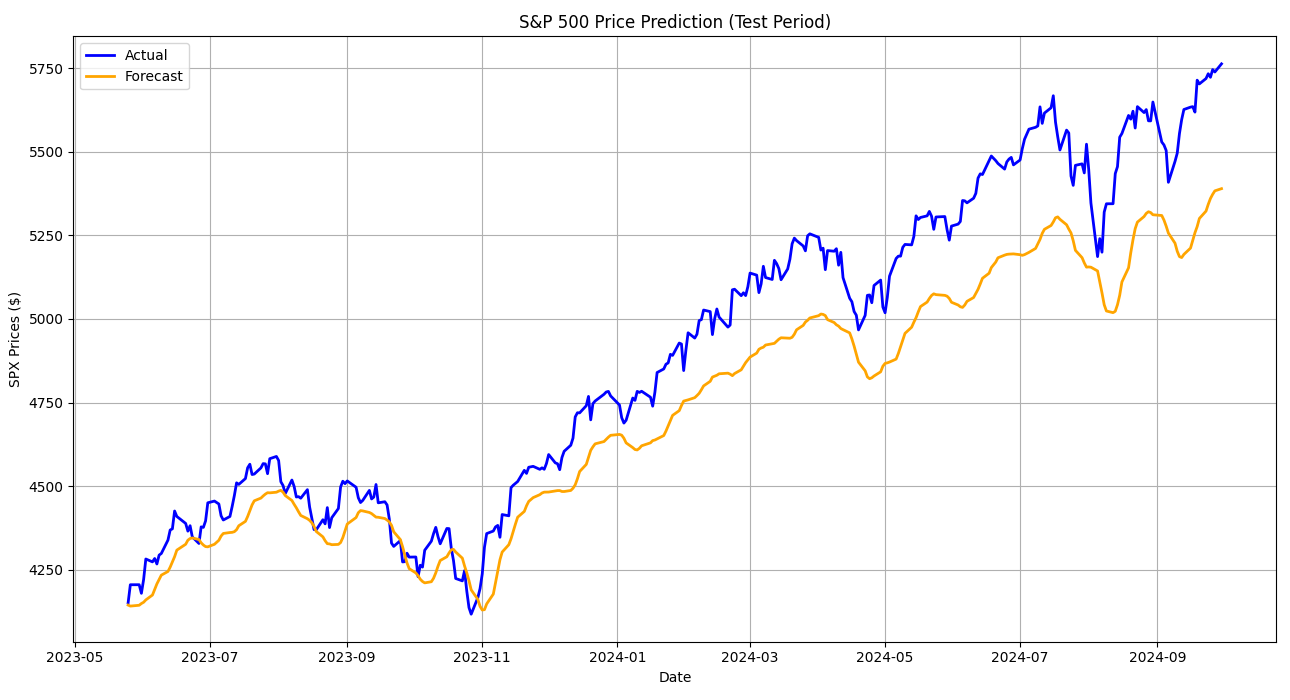
Figure 4: LSTM model without features.
Results Analysis
The LSTM model's superior performance highlights its efficacy in capturing complex data patterns, surpassing the conventional ARIMA approach. While ARIMA is limited to short-term trend forecasting, LSTM effectively models nonlinearities and long-term dependencies. The absence of additional features resulted in improved performance, potentially due to noise reduction and LSTM's ability to exploit inherent sequential patterns.
Conclusion
The study successfully demonstrates the advantages of LSTM networks over traditional statistical models like ARIMA for forecasting the SPX. LSTM's ability to handle sequential data and model complex, nonlinear dependencies makes it a robust choice for financial forecasting. Future research directions include hybrid model integration, LSTM architecture optimization, and broader application across different markets. Through these findings, LSTM networks confirm their potential as a sophisticated tool catering to the intricate demands of financial market prediction.