MorphAny3D: Unleashing the Power of Structured Latent in 3D Morphing
Abstract: 3D morphing remains challenging due to the difficulty of generating semantically consistent and temporally smooth deformations, especially across categories. We present MorphAny3D, a training-free framework that leverages Structured Latent (SLAT) representations for high-quality 3D morphing. Our key insight is that intelligently blending source and target SLAT features within the attention mechanisms of 3D generators naturally produces plausible morphing sequences. To this end, we introduce Morphing Cross-Attention (MCA), which fuses source and target information for structural coherence, and Temporal-Fused Self-Attention (TFSA), which enhances temporal consistency by incorporating features from preceding frames. An orientation correction strategy further mitigates the pose ambiguity within the morphing steps. Extensive experiments show that our method generates state-of-the-art morphing sequences, even for challenging cross-category cases. MorphAny3D further supports advanced applications such as decoupled morphing and 3D style transfer, and can be generalized to other SLAT-based generative models. Project page: https://xiaokunsun.github.io/MorphAny3D.github.io/.






Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Overview
This paper introduces MorphAny3D, a new way to smoothly transform one 3D object into another (called “3D morphing”). Think of turning a bee into a biplane, or a monkey king statue into a tree, with the change looking natural and happening step by step. The method focuses on keeping the shape believable, the textures (colors and details) consistent, and the whole animation smooth over time—without needing to train a new AI model.
Objectives and Questions
The paper asks:
- How can we make a 3D object change into a very different 3D object (even from another category) in a way that looks realistic and smooth?
- How do we avoid common problems like broken shapes, texture mismatches, flickering between frames, or sudden spins in the object’s pose?
- Can we do all this using existing 3D generators, without extra training?
- Can the method also support cool extras like separating shape from surface details, or transferring styles?
How the Method Works
To make the explanation easier, here are the key ideas using simple analogies.
The 3D Generator and SLAT
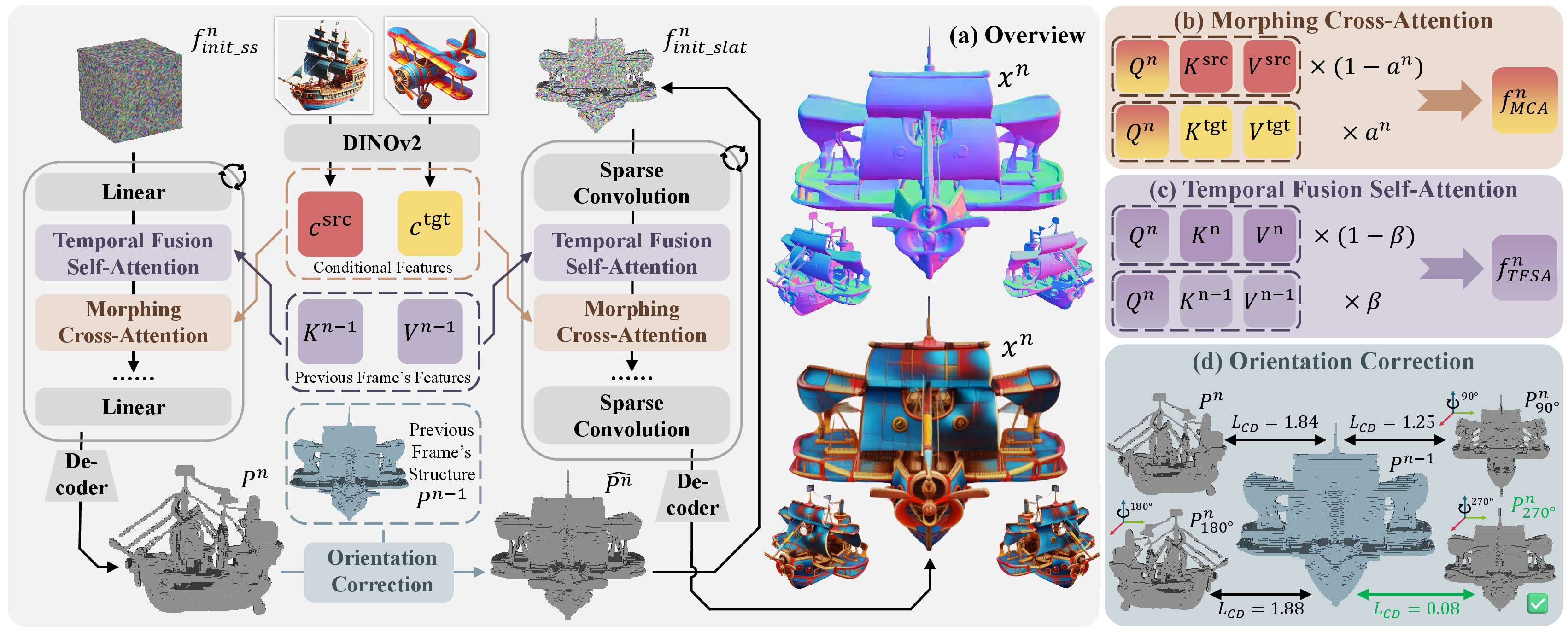
- The system builds on a 3D generator called Trellis. Trellis represents a 3D object using something named SLAT (Structured Latent).
- SLAT is like a map made of tiny “spots” on the object’s surface, each with a small vector of instructions that describe local shape and appearance (like labels telling each spot how to look).
- You can think of it as a 3D grid where only the important spots (voxels) are active, each carrying fine details. This structure makes it easier to edit and combine features.
Attention: How the Model “Focuses” and “Decides”
- Attention in AI is like a smart spotlight or a set of advisors telling the model which parts to focus on and how to combine information.
- Cross-attention: the model looks at external inputs (like pictures of the source and target objects) to guide what to generate.
- Self-attention: the model looks at its own current features to keep things consistent.
- Naively “blending” information from the source and target can cause confusion (like mixing two different instructions into one patch), leading to warped or mismatched results.
The Three Main Tricks
These are the new components the authors propose to make morphing both plausible and smooth:
- Morphing Cross-Attention (MCA):
- Instead of mixing the source and target guidance together, the model asks two separate “advisors”: one focused on the source, one on the target.
- It then combines their outputs based on how far along the morph it is (the “morphing weight” from 0 to 1).
- Analogy: rather than blending two different recipes into one confusing set of steps, you consult the head chef for recipe A and the head chef for recipe B separately, and then mix their final suggestions proportionally. This avoids confusing instructions and keeps the structure sensible.
- Temporal-Fused Self-Attention (TFSA):
- To avoid flickering between frames, the model “remembers” a bit of the previous frame and uses it to steady the current one.
- Analogy: while animating, you look at the last drawing and the current drawing, and blend them slightly so the motion feels smooth.
- Orientation Correction (OC):
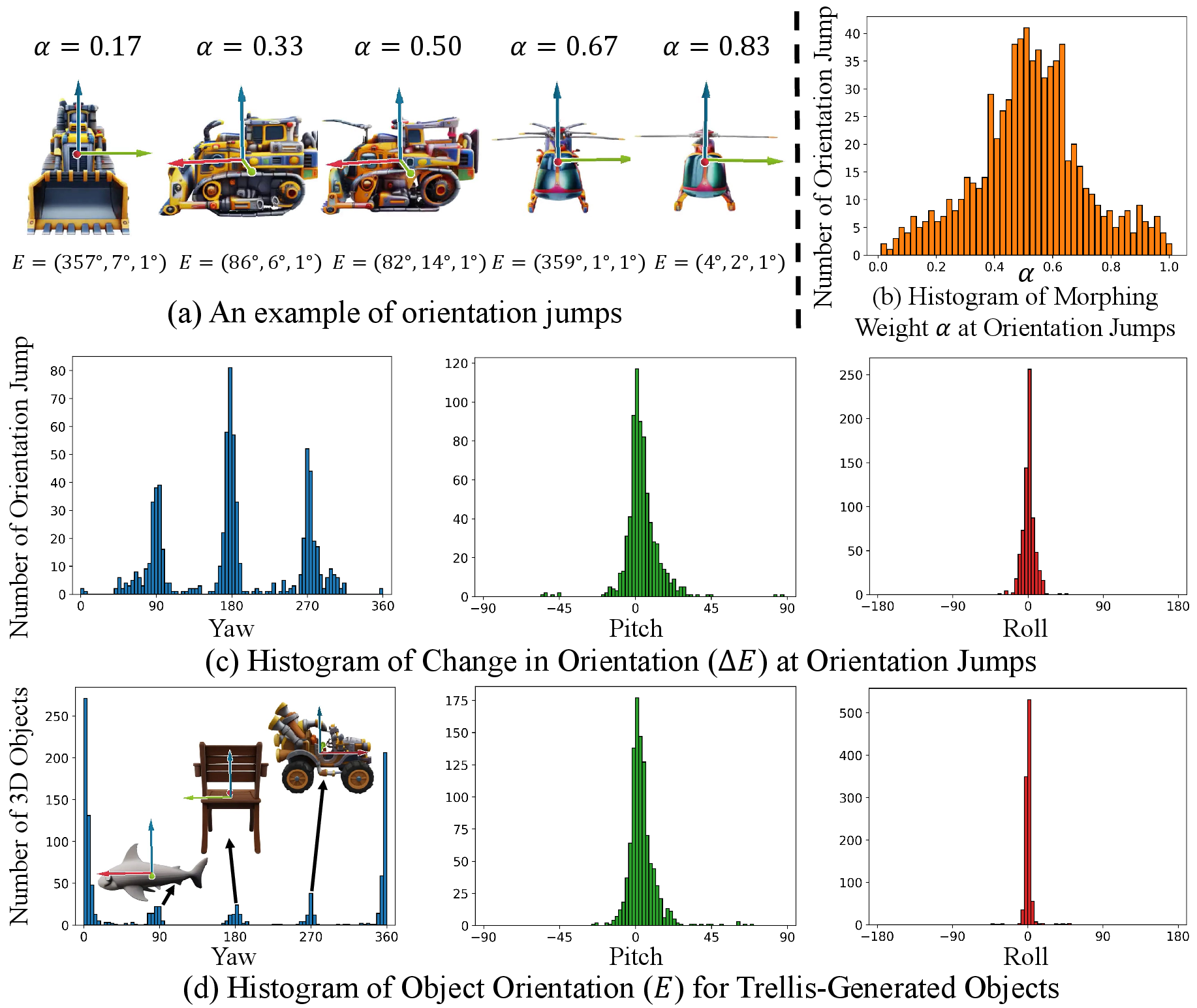
- Sometimes the object suddenly spins 90°, 180°, or 270° mid-morph because the generator has certain pose habits.
- The fix: for each frame’s rough structure, try a few rotated versions (like 0°, 90°, 180°, 270° yaw) and pick the one that best matches the previous frame. This helps prevent sudden spins.
- Analogy: if a dancer suddenly faces the wrong direction on stage, you rotate them to the closest orientation that matches the last position.
Putting It All Together
- Start with the source and target objects (either generated by Trellis or real ones converted into SLAT).
- Create a sequence of frames from the source (0%) to the target (100%), step by step.
- At each step:
- Use MCA to keep the structural guidance clean and semantically correct.
- Use TFSA to remember the previous frame, adding temporal smoothness.
- Apply OC to correct sudden orientation jumps.
- Decode the SLAT back into 3D formats (like meshes or 3DGS) for rendering.
Main Findings and Why They Matter
The authors compare MorphAny3D to several baselines (like matching shapes directly, doing 2D morphing then lifting to 3D, or simple feature interpolation). They measure:
- Visual plausibility (does it look realistic and coherent?),
- Smoothness over time (no flickering or jumps),
- Aesthetics (how appealing it looks),
- Human preference (which users liked).
Key results:
- MorphAny3D achieves the best realism and aesthetics among all methods tested.
- It’s also very smooth, with scores close to the top in smoothness.
- It works well across very different categories (like animal → vehicle) where traditional matching struggles.
- The three components each help:
- MCA reduces local distortions and keeps the structure believable.
- TFSA improves stability from frame to frame.
- OC fixes mid-sequence pose jumps.
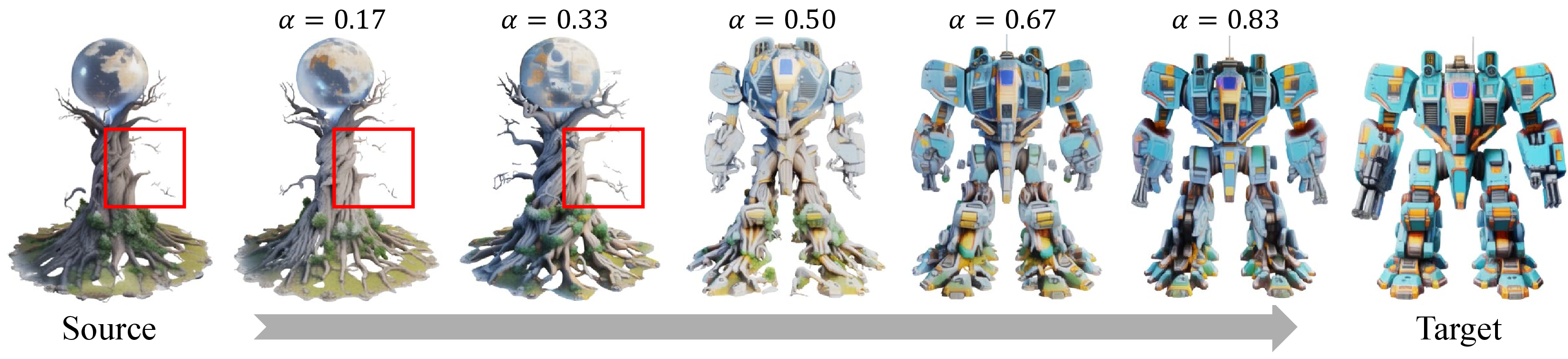
These results matter because they show you can get high-quality 3D morphing without retraining a model, and across very different objects—a big step for animation, games, and creative tools.
Implications and Impact
- Creative tools: Artists and designers can morph between wildly different 3D objects smoothly and convincingly—great for films, games, and art.
- Flexibility: The method can separate global shape from local details, combine two targets (one for shape, one for details), and even do 3D style transfer.
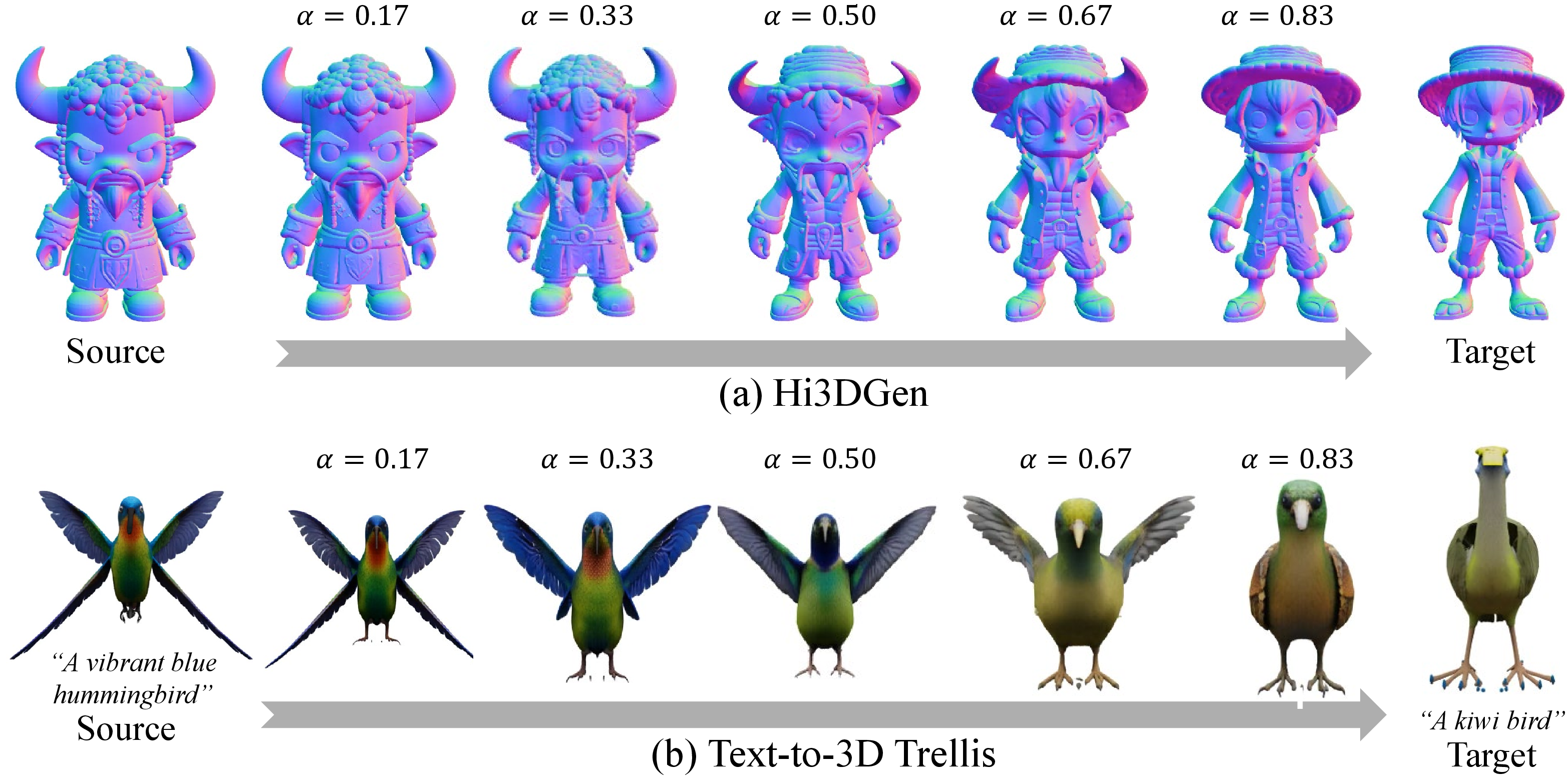
- Generalization: It works not only with Trellis’s image-to-3D but also with other SLAT-based models, making it versatile.
- Practicality: It’s “training-free,” meaning it uses the strengths of existing generators instead of needing a new one trained for morphing.
- Future improvements: Very fine structures can still be tricky; better 3D backbones or enhanced SLAT representations could push quality even higher.
In short, MorphAny3D provides a simple, smart way to morph 3D objects smoothly and realistically by combining clean guidance (MCA), temporal memory (TFSA), and pose stability (OC). It opens the door to more creative, reliable 3D morphing in real-world applications.
Knowledge Gaps
Below is a concise, actionable list of knowledge gaps, limitations, and open questions left unresolved by the paper. These points highlight what is missing, uncertain, or unexplored, and indicate concrete directions for future research.
- Temporal topology/UV consistency: Each frame is generated and decoded independently (mesh/NeRF/3DGS), with no guarantee of consistent topology, vertex correspondence, or UV maps across time—hindering downstream animation/editing workflows. How to enforce time-coherent surface parameterization and topology?
- Orientation correction heuristic: The orientation correction only considers yaw in discrete 90° steps, relies on OrientAnything, and uses a fixed 45° jump threshold. It does not address smaller drifts, pitch/roll, or distinguish intended rotations from spurious ones. Can we design a continuous, model-agnostic, reliability-aware pose stabilization or learn a pose prior integrated into generation?
- Pose prior generality: The observed yaw clusters (90°, 180°, 270°) are tied to Trellis’s learned pose distribution. It remains unclear whether similar priors exist in other SLAT backbones and how to generalize orientation correction across models and training datasets.
- Long-range temporal coherence: TFSA fuses only the immediately previous frame with a fixed β. There is no mechanism for longer temporal memory, adaptive weighting, or preventing error accumulation over long sequences. What are effective designs for multi-frame memory, scheduling, or recurrent/stateful attention?
- Hyperparameter sensitivity and scheduling: The method fixes β=0.2, uses linear α, N=49 frames, and spherical interpolation for initialization. There is no study of sensitivity, adaptive scheduling over time/layers, or non-linear geodesic paths in SLAT space.
- Layer/stage placement: The impact of applying MCA/TFSA at specific layers, heads, or only in SS vs SLAT stages is not dissected. Which layers contribute most to plausibility/smoothness, and can selective placement or per-layer weights further improve results?
- Learnable vs. heuristic fusion: MCA/TFSA are hand-crafted. There is no exploration of learned gating/routing (e.g., token-wise soft selection, mixture-of-experts) that adaptively fuses source/target/prior-frame features per token/region to better manage the plausibility–smoothness trade-off.
- Semantic correspondence quality: Claims of meaningful part transitions (e.g., trunk→boom) are qualitative; there is no quantitative assessment of semantic part correspondences through the morph. Can we integrate or evaluate with automatic 3D part segmentation/labels to measure semantic consistency?
- Handling multi-object scenes and backgrounds: The framework targets single-object morphing. It remains open how to extend to scenes with multiple interacting objects, cluttered backgrounds, or to maintain consistent context and lighting.
- Geometry integrity and physical plausibility: There is no evaluation or constraint for self-intersections, volume preservation, or collision-free deformations during morphing. How to incorporate geometric/physical priors or differentiable regularizers to mitigate implausible deformations?
- Fine structures and materials: The paper notes issues on extremely fine structures and suggests stronger backbones, but does not analyze performance across materials (transparency, specularity), thin shells, or complex topology. A systematic study and targeted improvements are missing.
- Metric suitability and benchmarking: FID (vs “originals” for a morph with no ground truth), PPL/PDV, and VLM-based aesthetics have limitations and biases; user study details are sparse. A standardized 3D morphing benchmark with task-appropriate metrics (temporal geometry continuity, topology stability, semantic consistency) is needed.
- Inversion dependency: Real assets require 3D inversion (e.g., VoxHammer). The impact of inversion errors on morph quality and temporal stability is not quantified. How robust is MorphAny3D to imperfect inversions, and can joint inversion+morphing improve outcomes?
- Efficiency and scalability: Runtime (~30 s/frame on an A6000), memory footprint, and scaling to higher resolutions or longer sequences are not thoroughly profiled or compared to baselines. Can caching, token pruning, or distillation provide real-time or near-real-time performance?
- Decoding representation effects: The choice among 3DGS, NeRF, or mesh decoding likely affects temporal consistency, shading stability, and artifact patterns. A comparative analysis and decoding-time consistency strategies are missing.
- Adaptive path control: The morph path is linear in α. There is no exploration of user- or data-driven path planning (e.g., part-wise schedules, attribute-preserving constraints, non-linear/geodesic trajectories) to steer the morph and avoid ambiguous intermediates.
- Dual-target and disentangled morphing evaluation: Applications (decoupled morphing, dual-target morphing, style transfer) are shown qualitatively only. Quantitative measures of structural/detail preservation and conflict resolution are absent.
- Generalization assessment: Demonstrations on other SLAT models (Hi3DGen, Text-to-3D Trellis) are qualitative; there is no quantitative evaluation or stress-testing across datasets, modalities (text-only), or highly dissimilar categories.
- Camera and lighting stability: The approach does not explicitly control camera pose or illumination across frames. How to ensure temporally consistent rendering conditions and disentangle object morphing from viewpoint/lighting changes?
- Robustness to category disparity: While extreme cross-category morphs are shown, there is no systematic study of failure rates vs. category distance or structural disparity. Can we predict or mitigate failure under large semantic/structural gaps?
- Theoretical understanding: The explanation for why MCA outperforms KV-fused CA is qualitative (attention map inspections). A more formal analysis of attention fusion dynamics in SLAT and conditions under which fusion harms/plausibility would guide principled design.
- Orientation estimation reliability: The accuracy and failure modes of OrientAnything on synthetic/Trellis assets are not validated. What is the error profile, and how does it propagate into orientation correction decisions?
- Fair comparisons: 3DMorpher is not evaluated quantitatively due to code availability. Reproducible, apples-to-apples comparisons with strong contemporary baselines remain open.
- Release and reproducibility: The paper cites 50 curated pairs and Supp. Mat. for details. A public dataset, code, and evaluation scripts for standardized 3D morphing benchmarking would improve reproducibility and progress tracking.
- Extension to rigged/animatable assets: The method outputs per-frame assets without rigging or consistent skinning/part structure. How to integrate morphing with skeletal/part articulation constraints to produce animation-ready, temporally consistent rigs and UVs?
Glossary
- 3D Gaussian Splatting (3DGS): A point-based 3D representation that renders scenes by splatting Gaussian primitives, often used for fast view synthesis. "Moreover, 3DGS-based outputs are not compatible with most commercial 3D software~\cite{blender,maya,unrealengine}."
- 3D inversion: The process of recovering latent and conditioning features of a pre-trained 3D generator from a given 3D asset. "For real assets, we obtain their initial noised latents and , and image conditions , via 3D inversion~\cite{voxhammer}."
- Aesthetics Scores (AS): An automatic metric that ranks visual appeal using vision-LLMs. "Aesthetics Scores (AS) uses vision-LLMs~\cite{chatgpt,gemini} to rank visual appeal;"
- Chamfer Distance (CD): A measure of dissimilarity between two point sets (shapes), used to compare geometric structures. "We select the candidate that minimizes the Chamfer Distance (CD) to the previous frame's structure as the corrected structure $\hat{P^{n}$, which is then passed to the SLAT flow transformer."
- Cross-attention: An attention variant where queries attend to external condition features (e.g., image/text), guiding generation. "MCA fuses information from the source and target objects in the cross-attention layers to ensure the structural coherence and aesthetics of the deformation."
- Diffusion models: Generative models that synthesize data by iteratively denoising from noise, enabling high-fidelity image generation. "The recent success of diffusion models~\cite{diffusion_ddim,diffusion_ddpm,diffusion_sde} has enabled high-fidelity and diverse image generation."
- DINOv2: A self-supervised vision transformer producing robust patch-wise image features widely used as semantic descriptors. "the blended keys and values in cross-attention are derived from patch-wise DINOv2~\cite{dinov2} features."
- Euler angles: A parameterization of 3D rotations using yaw, pitch, and roll angles. "We represent orientation via the Z-Y-X Euler angles (in degrees), estimated using OrientAnything~\cite{OrientAnything}."
- Fréchet Inception Distance (FID): A metric quantifying visual realism by comparing feature distributions of generated and reference images. "FID~\cite{fid} measures visual plausibility by comparing rendered frames to originals;"
- Functional maps: A spectral-shape correspondence framework mapping functions across surfaces, used for 3D matching. "incorporating theories such as optimal transport~\cite{opt_trans1,opt_trans2,morphflow} and functional maps~\cite{functionmap1,functionmap2,functionmap3,functionmap4} to compute correspondences within the same category."
- Generative prior (3D generative prior): Prior knowledge encoded by a generative model that constrains and guides synthesis. "MorphAny3D fully utilizes the 3D generative prior embedded in SLAT to produce structurally plausible and temporally smooth morphing sequences"
- KV-Fused Cross-Attention (KV-Fused CA): A fusion strategy that linearly blends keys/values from source and target conditions before cross-attention. "(1) KV-Fused CA significantly enhances the structural and semantic plausibility of 3D morphing by fusing 2D semantic information from the source and target objects within cross-attention (the lowest FID)."
- KV-Fused Self-Attention (KV-Fused SA): A fusion strategy that blends source and target latent keys/values inside self-attention to improve continuity. "(2) KV-Fused SA effectively improves the smoothness and continuity of the morphing sequence by aggregating 3D latent features from the source and target objects within self-attention (the lowest PPL)."
- Morphing Cross-Attention (MCA): A proposed module that runs cross-attention separately with source and target features and then mixes the outputs to preserve semantic consistency. "MCA computes separate attention outputs for the source and target objects and then combines them to produce the final feature :"
- NeRF: A neural implicit 3D representation that models radiance and density fields for novel view synthesis. "Finally, the generated SLAT is decoded into standard 3D representations such as meshes, NeRF~\cite{nerf}, or 3DGS~\cite{3dgs}."
- Optimal transport: A mathematical framework for matching distributions (or shapes) with minimal transport cost, used for shape correspondence. "incorporating theories such as optimal transport~\cite{opt_trans1,opt_trans2,morphflow} and functional maps~\cite{functionmap1,functionmap2,functionmap3,functionmap4} to compute correspondences within the same category."
- Orientation correction: A post-processing strategy that adjusts object pose to prevent abrupt orientation jumps during morphing. "we propose an orientation correction strategy inspired by statistical orientation distribution patterns in Trellis-generated assets"
- Perceptual Distance Variance (PDV): A metric capturing temporal homogeneity via the variance of perceptual changes between adjacent frames. "(b) Perceptual Path Length (PPL) and Perceptual Distance Variance (PDV)~\cite{diffmorpher} assess transition smoothness and temporal homogeneity via average perceptual change and its variance between adjacent frames;"
- Perceptual Path Length (PPL): A metric measuring smoothness by averaging perceptual differences between consecutive frames. "(b) Perceptual Path Length (PPL) and Perceptual Distance Variance (PDV)~\cite{diffmorpher} assess transition smoothness and temporal homogeneity via average perceptual change and its variance between adjacent frames;"
- Rectified flow models: Flow-based generative models trained with a rectification objective, enabling efficient data generation and transfer. "Trellis employs a two-stage generation pipeline based on rectified flow models~\cite{rectified_flow} tailored for SLAT generation"
- Self-attention: An attention mechanism where tokens attend to other tokens in the same sequence/latent to model internal dependencies. "enhances temporal smoothness by incorporating SLAT features from the previous morphing frame into the self-attention mechanism"
- Sparse Structure (SS): The first Trellis stage that predicts a sparse voxel structure capturing global shape. "Sparse Structure (SS) Stage: SS flow transformer estimates a voxel grid to identify the sparse structure representing the global shape of assets."
- Spherical interpolation: An interpolation method (slerp) on a hypersphere used to smoothly blend latent vectors. "The initial noisy feature for frame , , is computed by spherical interpolation~\cite{diffmorpher} with a deformation weight "
- Structured Latent (SLAT): A regular, explicit 3D latent representation composed of local features anchored to sparse surface voxels. "Its proposed Structured LATent (SLAT) representation not only efficiently encodes rich visual features but is also easily modeled and understood within modern generative frameworks."
- Temporal-Fused Self-Attention (TFSA): A proposed module that injects keys/values from the previous frame into current self-attention to improve temporal consistency. "TFSA promotes temporally consistent 3D morphing by incorporating features from previously generated frames into the self-attention mechanism."
- Trellis: A feed-forward 3D generative model that outputs high-fidelity assets conditioned on text or images. "Trellis~\cite{trellis} is a robust feed-forward 3D generative model that produces diverse, high-fidelity 3D assets from text or image prompts."
- Voxel: A volumetric pixel; a discrete element of a 3D grid used to spatially anchor latent features. "a set of local latent vectors anchored at active sparse voxels on the object surface"
Practical Applications
Immediate Applications
Below are practical, deployable use cases enabled by MorphAny3D’s training-free, SLAT-based 3D morphing (with MCA, TFSA, and orientation correction), with sector links, concrete workflows/products, and feasibility notes.
- Post-production and VFX morph transitions (Media/Entertainment, Software)
- What: Rapidly create smooth, semantically coherent 3D transitions between assets (e.g., creature-to-vehicle, logo evolutions) for films, trailers, TV, and ads.
- Tools/workflows: Integrate MorphAny3D as a Blender/Maya/Unreal plug-in that invokes Trellis/Hi3DGen under the hood; generate 50-frame sequences (default) with α ∈ [0,1], export meshes/3DGS for rendering; use orientation correction (OC) to stabilize mid-sequence poses.
- Assumptions/dependencies: Access to SLAT-based generators (e.g., Trellis), appropriate licenses for pre-trained models; A6000-class GPU or cloud GPU (≈30s/frame reported); source/target asset rights cleared; still-limited fidelity on extremely fine structures.
- Game content pipelines: evolution/upgrade animations (Gaming, Software)
- What: Offline-baked morph sequences for character/item evolutions, “reveal” animations, or boss transformations with cross-category plausibility.
- Tools/workflows: Batch-generate morphs with MCA+TFSA; export to engine-friendly mesh sequences or bake to texture/normal maps; integrate orientation-stabilized outputs into cutscenes.
- Assumptions/dependencies: Offline precomputation (not real-time yet); ensure topology-compatible exports for chosen engine; IP/licensing for blended assets.
- Interactive 3D product unveil and A/B showcase (Marketing, E-commerce, AR/VR)
- What: Smoothly morph legacy product to new model on product pages or AR viewers (e.g., phone model A→B), preserving textures and coherence.
- Tools/workflows: Web viewer with morph slider controlling α; backend invokes MorphAny3D once to precompute sequence; 3D/AR-friendly formats (glTF/mesh) delivered via CDN.
- Assumptions/dependencies: Reliable image-to-3D inversion for real products; consistent lighting/style across inputs; QA for mid-sequence plausibility.
- 3D style transfer for brand-consistent assets (E-commerce, Design, Media)
- What: Apply brand “look” (from 2D style image) to product 3D while keeping geometry intact using SLAT-stage-only target conditioning.
- Tools/workflows: Use decoupled morphing (apply morph to SLAT only) to transfer materials/colors while preserving SS (structure); batch process SKU families.
- Assumptions/dependencies: Style exemplars with clear material cues; mesh export quality sufficient for DCC pipelines; monitor material artifacts on fine details.
- Dual-target creative compositing (Creative Tech, Advertising, Education)
- What: Simultaneously morph structure toward target A and details toward target B (e.g., product shape A with brand texture B) for novel creative assets.
- Tools/workflows: Assign targets separately to SS/SLAT stages; tune α schedules independently; export candidate mixes for art direction review.
- Assumptions/dependencies: Balanced semantic compatibility between targets; art direction for plausibility; legal clearance for mixed IP.
- Design space exploration for industrial design (Manufacturing, Product Design)
- What: Interpolate between design prototypes to explore intermediate forms and textures for stakeholder reviews.
- Tools/workflows: Invert CAD-derived renders/photos to SLAT; generate sequences across prototypes; export meshes for CAD overlays or comparative renders; OC to avoid pose flips.
- Assumptions/dependencies: CAD-to-image fidelity and inversion quality; mesh cleanliness for downstream CAD/CAE is not guaranteed; best for visualization rather than engineering geometry.
- Education and communication of transformations (Education, Museums, Cultural Heritage)
- What: Visualize object metamorphoses (e.g., biological life cycles, artifact restoration “before→after”) with consistent 3D geometry and texture transitions.
- Tools/workflows: Prepare real scans or Trellis-generated proxies; run MorphAny3D; publish interactive viewers for classrooms/museums.
- Assumptions/dependencies: Authenticity and scientific validity require expert-reviewed inputs; orientation correction for consistent viewing.
- 3D data augmentation for shape/recognition research (Academia, AI/ML)
- What: Generate dense intermediate shapes between category exemplars to create curricula for 3D recognition, retrieval, or metric learning.
- Tools/workflows: Scripted batch morphing across curated pairs; export meshes and normal maps; label α as a “shape progression” signal for self-supervised learning.
- Assumptions/dependencies: Augmentations reflect generative priors rather than real correspondences; ensure dataset governance and disclosure.
- Pose-stabilized 3D morph module (Software infrastructure)
- What: Use the OC strategy standalone to reduce pose flips in other SLAT pipelines for any 3D sequence generation task.
- Tools/workflows: Insert OC after SS stage; evaluate yaw candidates (0°, 90°, 180°, 270°) by Chamfer Distance against prior frame; pass corrected structure to SLAT stage.
- Assumptions/dependencies: OC tuned to Trellis’s pose distribution; may require adaptation for other generators.
Long-Term Applications
These use cases require further research, scaling, or engineering before widespread deployment.
- Real-time, interactive morphing in engines (Gaming, AR/VR, Software)
- What: On-the-fly morphing for gameplay, user-controlled transformations in XR, and real-time configurators.
- Tools/workflows: Optimize MCA/TFSA for inference speed; incremental SLAT updates; engine-native shaders for morph visualization.
- Assumptions/dependencies: Model compression and GPU optimization; real-time SLAT decoders; robust pose stabilization beyond Trellis-specific OC.
- CAD/CAM integration for parametric shape ideation (Manufacturing, AEC)
- What: Use SLAT-space morphs as a front-end for conceptual CAD ideation; suggest intermediate forms to inform parametric constraints.
- Tools/workflows: SLAT-to-CAD retopology, constraint extraction from meshes; loop with designers to convert suggestions into parametric models.
- Assumptions/dependencies: Reliable reverse-engineering of clean, watertight CAD from generated meshes; capturing engineering tolerances is nontrivial.
- Robotics training and sim-to-real generalization (Robotics, AI/ML)
- What: Generate families of shape variants (within/between categories) to train grasping/manipulation policies robust to geometry changes.
- Tools/workflows: Morph families around canonical objects; render physics-ready meshes; use α-conditioned curricula for policy training.
- Assumptions/dependencies: Physical plausibility not guaranteed by aesthetic morphs; require simulation validation and possibly physics-aware generators.
- Medical and scientific visualization of morphology progression (Healthcare, Science Communication)
- What: Illustrate organ/tumor shape changes or anatomical development in 3D over time for patient education or teaching.
- Tools/workflows: Domain-adapted SLAT models trained on medical imagery; supervised constraints for anatomical plausibility; clinician-in-the-loop validation.
- Assumptions/dependencies: Requires medically validated 3D generative backbones and regulatory compliance; current Trellis priors are not medical-grade.
- Training 4D generative models and temporal priors (Academia, AI/ML)
- What: Use high-quality morph sequences as pseudo-ground-truth for learning temporally coherent 3D (4D) generative models.
- Tools/workflows: Curate large morph datasets with α/β metadata; train temporal attention modules; evaluate with PPL/PDV-like metrics.
- Assumptions/dependencies: Synthetic supervision must generalize to real dynamics; need benchmarks and standardized protocols.
- Multi-concept blend design tools for creators (Creative Tech, Prosumer Platforms)
- What: Consumer-facing apps for dual-target morphing and style-preserving edits, enabling novel asset creation without 3D expertise.
- Tools/workflows: Simple UI around α sliders for SS/SLAT; content safety filters; one-click export to social media or 3D printing.
- Assumptions/dependencies: UX simplification, IP safeguards, and compute cost management; improved handling of fine, delicate structures.
- Standards and provenance for AI-generated 3D morphs (Policy, Standards, IP)
- What: Develop SLAT-aware interchange formats and provenance metadata (e.g., source/target asset IDs, α schedule, OC usage) for compliance and attribution.
- Tools/workflows: Embed C2PA-like provenance in glTF/USD; watermark meshes; license templates for blended content.
- Assumptions/dependencies: Industry coordination (DCCs, engines, platforms); legal frameworks for derivative 3D assets.
- Physics-aware morphing for engineering and digital twins (Energy, Infrastructure, AEC)
- What: Morph sequences that respect material/structural constraints to visualize maintenance, wear, or retrofit scenarios.
- Tools/workflows: Couple SLAT morphs with FEM/physics constraints; co-optimize plausibility and physical feasibility.
- Assumptions/dependencies: New models incorporating physics priors; validation against real-world measurements.
- High-fidelity SLAT backbones for fine-detail sectors (Jewelry, Biomed, Heritage)
- What: Next-gen SLAT models capturing very fine geometry and micro-texture for sectors needing high precision.
- Tools/workflows: Train/finetune on domain datasets; integrate enhanced decoders; revisit MCA/TFSA hyperparameters for new backbones.
- Assumptions/dependencies: Availability of domain data; compute and training resources; mesh quality suitable for fabrication or archival.
- Content authenticity and moderation in platforms (Policy, Platforms)
- What: Guidelines and automated checks for disclosure and moderation of AI-morphed 3D assets, preventing misuse (e.g., deceptive ads).
- Tools/workflows: Platform-side detectors of morph provenance; mandatory provenance display for commercial use; audit trails.
- Assumptions/dependencies: Consensus on disclosure norms; scalability of verification across formats; balancing creativity and consumer protection.
Collections
Sign up for free to add this paper to one or more collections.