Vulcan: Instance-Optimal Systems Heuristics Through LLM-Driven Search
Abstract: Resource-management tasks in modern operating and distributed systems continue to rely primarily on hand-designed heuristics for tasks such as scheduling, caching, or active queue management. Designing performant heuristics is an expensive, time-consuming process that we are forced to continuously go through due to the constant flux of hardware, workloads and environments. We propose a new alternative: synthesizing instance-optimal heuristics -- specialized for the exact workloads and hardware where they will be deployed -- using code-generating LLMs. To make this synthesis tractable, Vulcan separates policy and mechanism through LLM-friendly, task-agnostic interfaces. With these interfaces, users specify the inputs and objectives of their desired policy, while Vulcan searches for performant policies via evolutionary search over LLM-generated code. This interface is expressive enough to capture a wide range of system policies, yet sufficiently constrained to allow even small, inexpensive LLMs to generate correct and executable code. We use Vulcan to synthesize performant heuristics for cache eviction and memory tiering, and find that these heuristics outperform all human-designed state-of-the-art algorithms by upto 69% and 7.9% in performance for each of these tasks respectively.
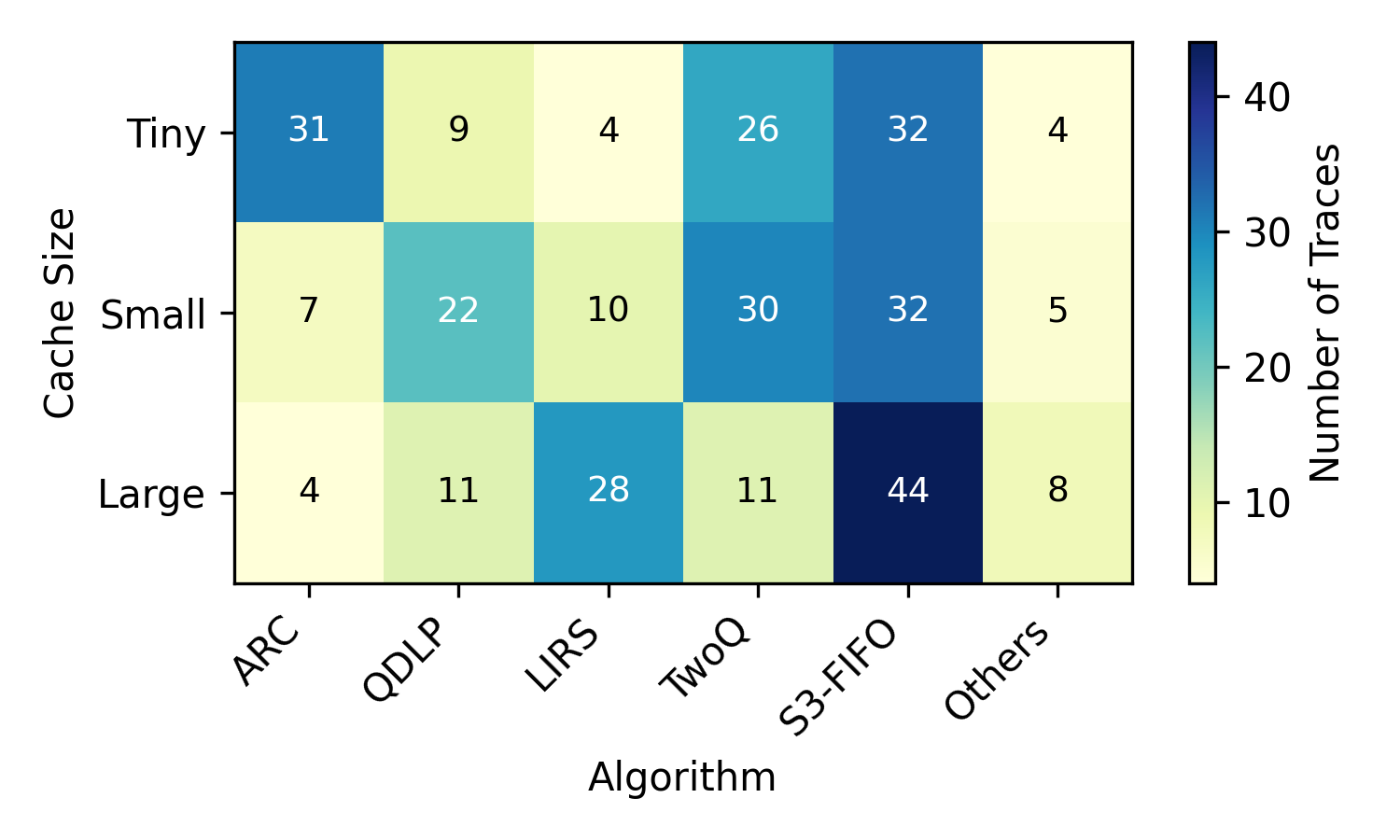
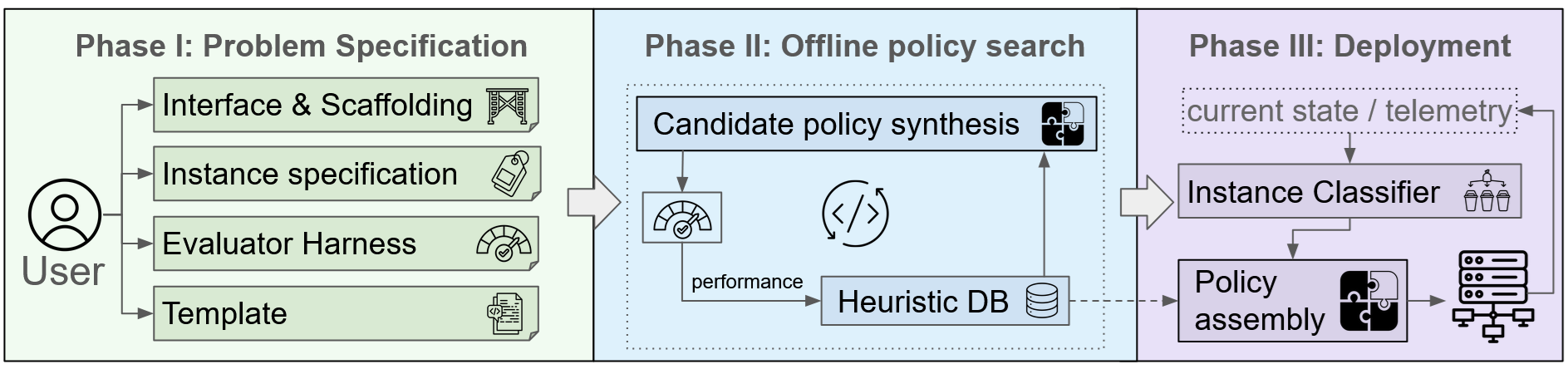
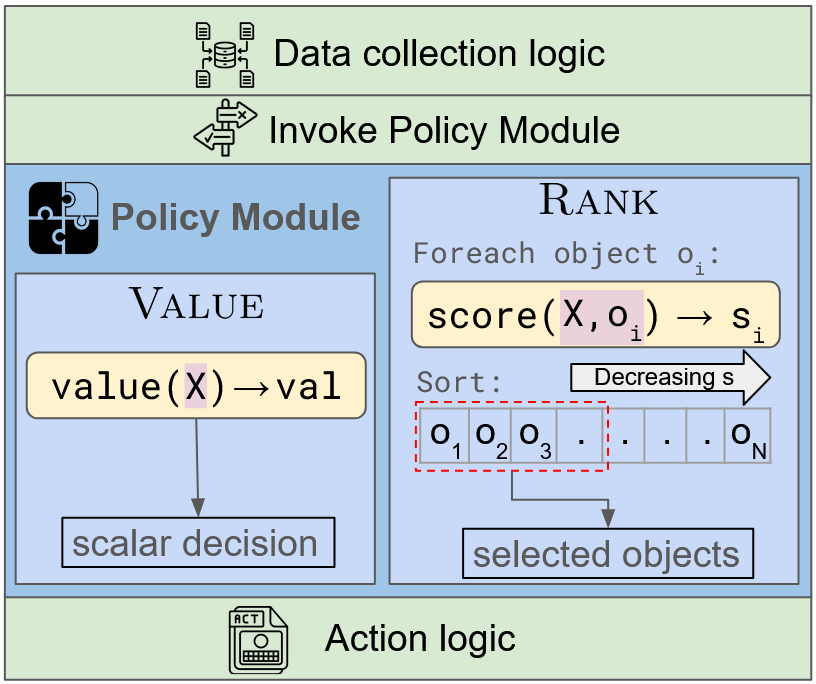
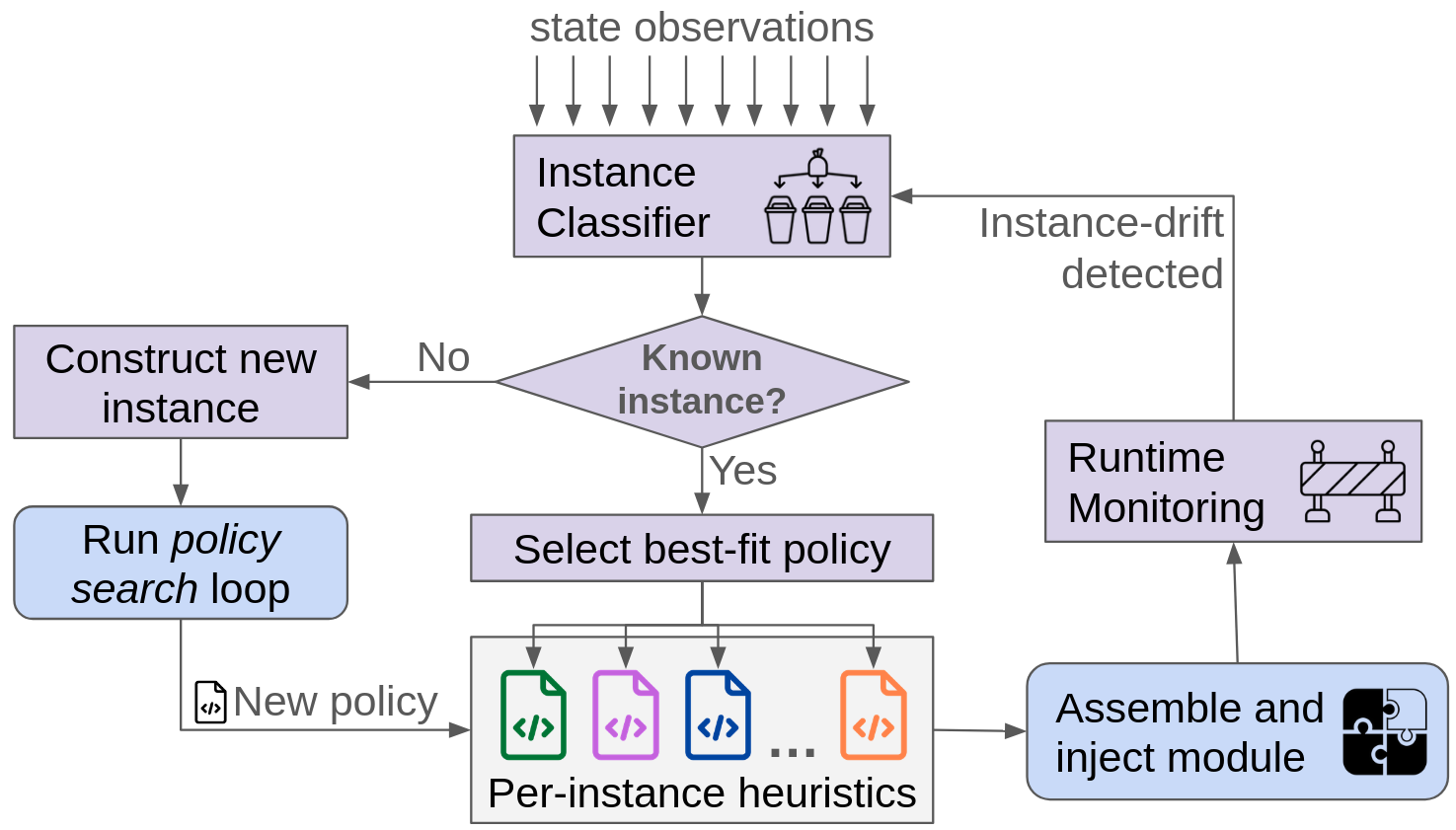
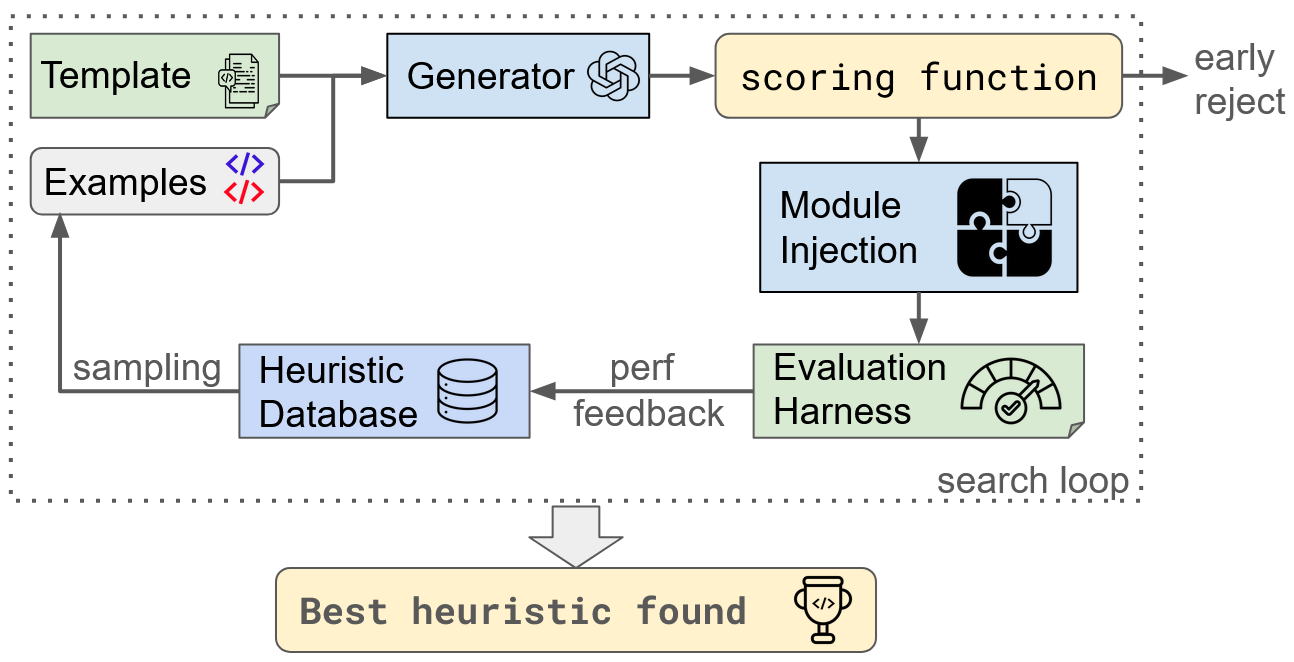
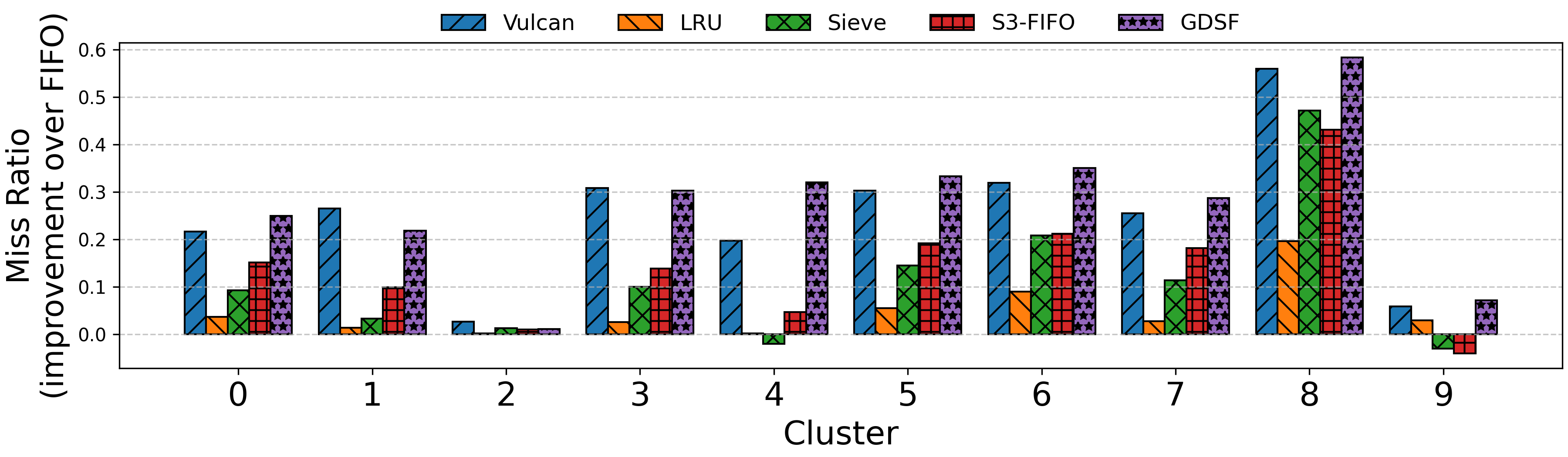
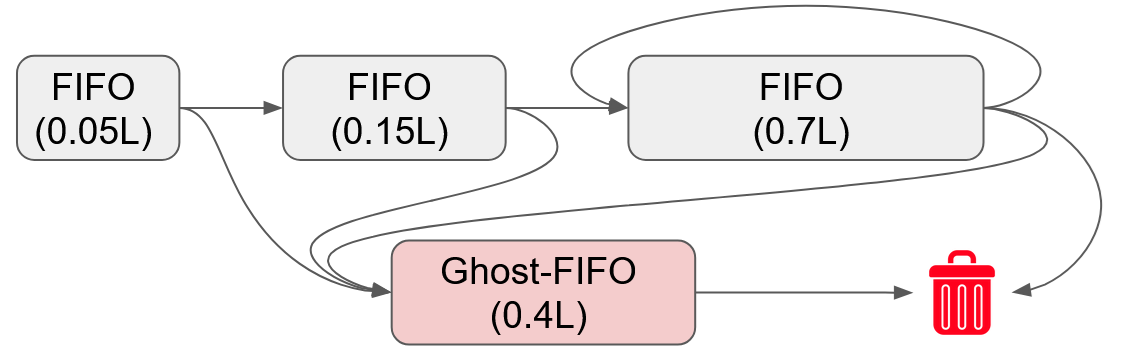
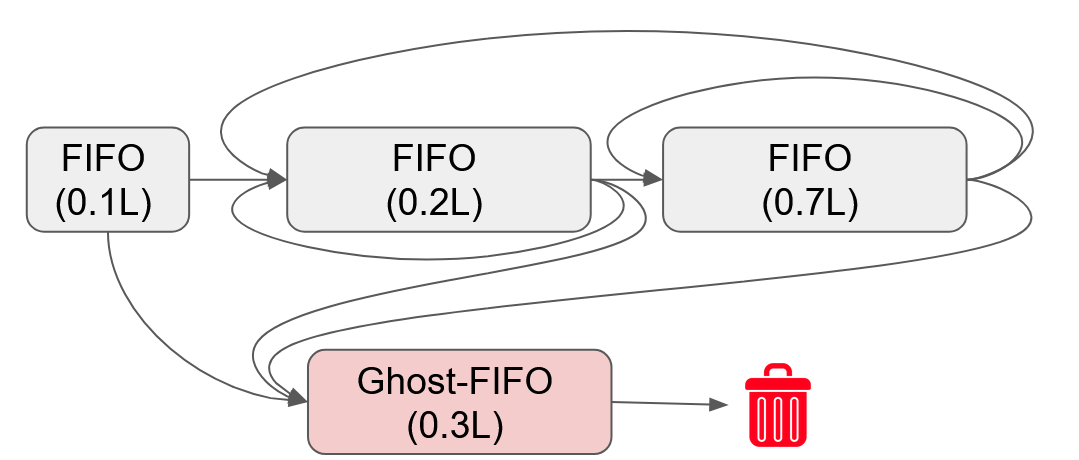
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Overview
This paper introduces Vulcan, a new way to design computer system “rules of thumb” (called heuristics). These rules decide things like which files to keep in a cache, which memory pages to move to faster memory, or how to schedule tasks. Usually, experts hand-tune these rules, but as hardware and workloads keep changing, those rules quickly become out-of-date.
Vulcan uses code‑writing AI (LLMs, or LLMs) to automatically generate small pieces of decision code that are customized for a specific situation (a specific workload on specific hardware). The big idea is to make the problem simple enough for an AI to handle by separating what decision to make (the policy) from how the computer actually carries it out (the mechanism). This lets the AI focus on writing a tiny, safe function, while the rest of the system takes care of the heavy lifting.
What the paper tries to achieve
In simple terms, the paper asks:
- Can we automatically build the “best rule for this exact situation” instead of using one rule for everyone?
- How do we make it easy and safe for an AI to generate these rules?
- Does this actually work better than current methods on real tasks like caching and memory tiering?
How Vulcan works (with simple analogies)
Vulcan follows a three-step process. You can think of it like organizing a school competition where you want to pick the best players for each game, and the games keep changing.
- Choose a simple interface (what the AI must write)
- Two kinds of decisions cover most system tasks:
- Value: “Pick a number.” Example: a thermostat picking the next temperature, or a network algorithm picking how many packets to send next.
- Rank: “Score and pick the top K.” Example: a coach scoring all players and picking the top 5 for the team, or a cache deciding which items to evict by scoring each item.
The AI only writes a small scoring function:
- For Value tasks: value(X) → a number (X are the inputs, like measurements).
- For Rank tasks: score(X, object) → a number per object, and the system then picks the top K by sorting.
This keeps things safe and simple: the AI doesn’t touch complex system code, just a tiny, stateless function that returns a number.
- Define the “instance” (the exact situation)
- An “instance” is a specific workload + hardware combo (like “this app on this machine”).
- Instead of one-size-fits-all, Vulcan finds the best rule for each instance. The paper even shows a way to automatically group workloads into clusters and pick or create a tailored rule for each cluster.
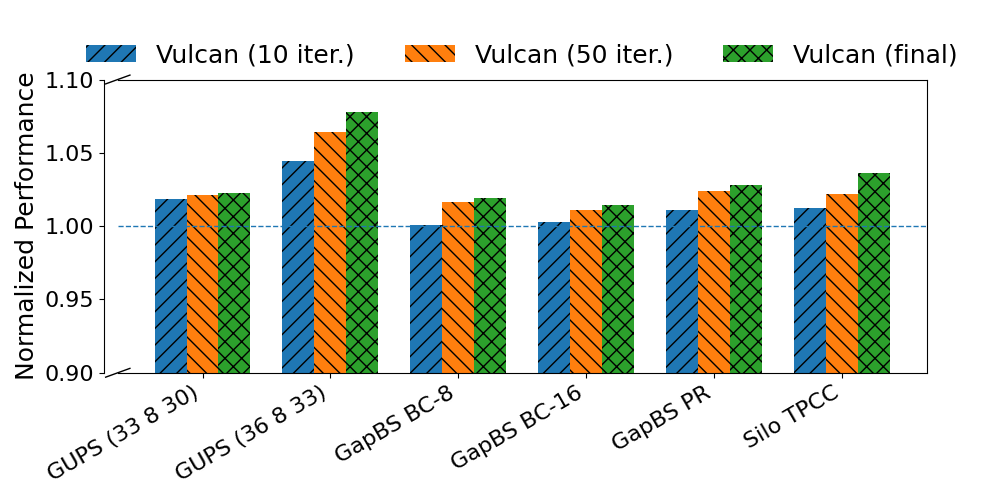
- Search for the best rule using evolutionary search
- Think of tryouts:
- Generate many candidate mini-programs (using the AI).
- Test them in a simulator or on a testbed (an evaluation setup).
- Keep the best ones, tweak them, and repeat.
- Over time, this “survival of the fittest rules” produces a strong, instance‑specific heuristic.
Behind the scenes, for Rank tasks, Vulcan plugs the AI’s score function into one of these mechanisms (picked for speed vs accuracy needs):
- FullSort: score everything and sort fully (simple but slower).
- SampleSort: score only a random subset (faster, approximate).
- PriorityQueue: always keep a live “best-at-the-top” structure (fast picks, updates as things change).
Here’s a small table to make the two decision types concrete:
| Decision type | What it means | Simple examples |
|---|---|---|
| Value | Compute one number from current signals | Next network window size; CPU speed; number of server replicas |
| Rank | Score items and pick top K | Which cache items to evict; which memory pages to promote; which task to run next |
What they found and why it matters
The authors tested Vulcan on two important system tasks:
- Cache eviction (which items to remove from a limited cache):
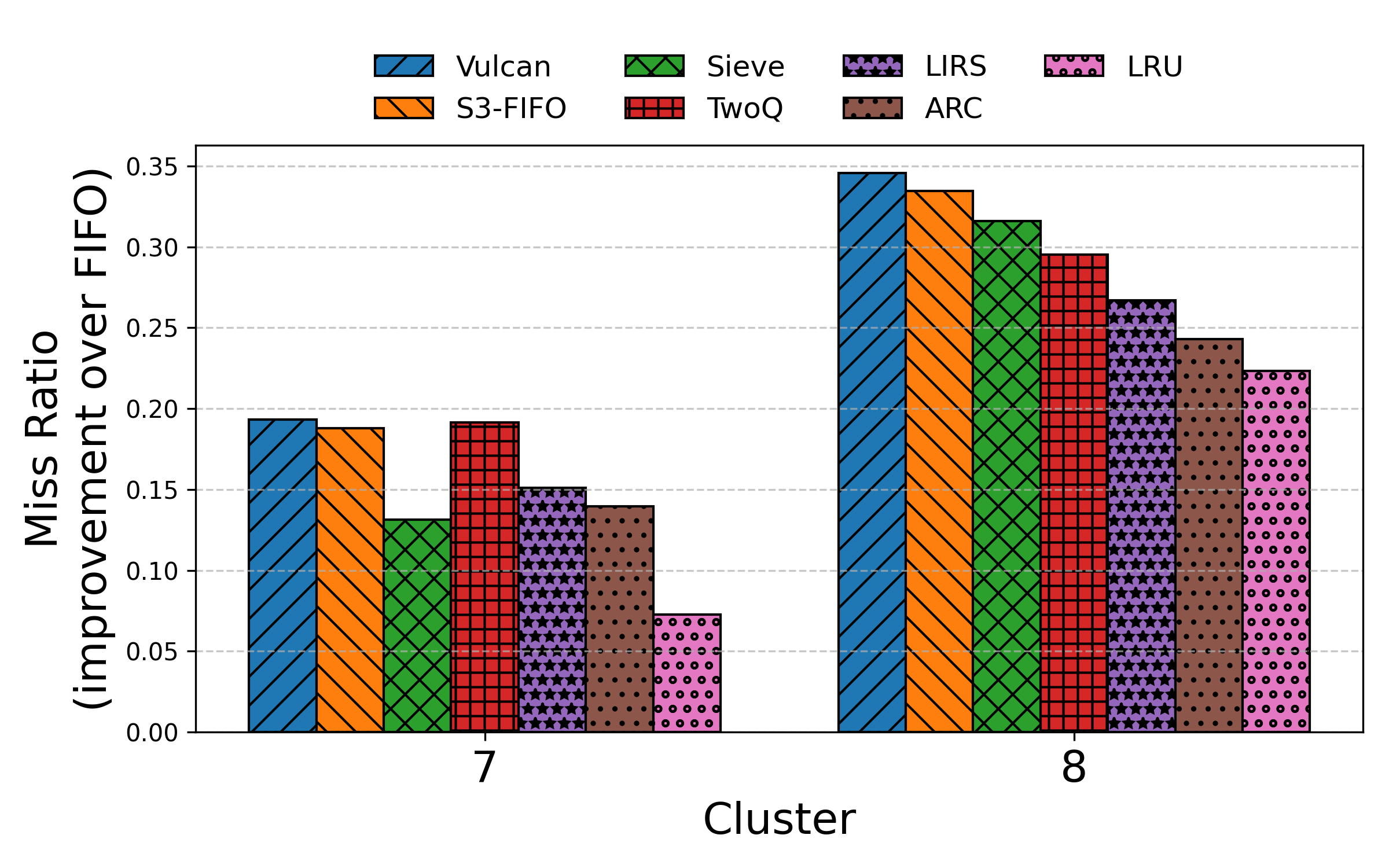
- Vulcan’s learned rules beat the best human-designed algorithms on many test cases, improving performance by up to 69% (and often by a few percent to tens of percent), depending on the instance.
- Memory tiering (which memory pages to move to faster memory):
- Vulcan’s rules improved performance by about 2.5% to 7.9% over strong existing methods across different workloads.
Why this is important:
- Better performance with less manual tuning: Instead of researchers constantly rewriting rules for new conditions, Vulcan quickly discovers rules that fit each exact situation.
- Safer, simpler AI use: The AI generates small, readable code snippets (a single function), not entire complex systems. That makes the result easier to understand, check, and deploy.
- Broad applicability: The paper surveyed many recent systems papers and found that most resource-management tasks can be framed as either Value or Rank — meaning this approach can work in lots of places (like scheduling, autoscaling, congestion control, and more).
What this could change going forward
- Faster adaptation: As workloads or hardware shift (new traffic patterns, new chips), Vulcan can re-run the search and produce fresh, tailored rules. Specialization becomes normal instead of rare.
- Human + AI teamwork: People design the interface, choose what signals to expose, and build the testing setup. The AI explores the space and writes candidate rules. This splits work so each is doing what they’re best at.
- Interpretable and efficient: Since the AI code is small and readable, engineers can inspect and trust it more easily than big black-box neural networks.
- Practical trade-offs: Good results still depend on a solid evaluation harness (simulator or testbed) and smart choices about speed vs realism. Also, “instance-optimal” means “best within the search space for this situation,” not “perfect forever.”
In short, Vulcan shows a clear path to quickly discovering high-performing, situation-specific system rules by letting AI generate small, safe decision functions and by giving it a clean, well-structured playground to search in.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
The paper introduces Vulcan and demonstrates it on caching and memory tiering, but several aspects remain unaddressed or insufficiently validated. Future work could target the following gaps:
- Formal guarantees: Provide convergence analysis and optimality bounds of the evolutionary search within the specified search space; quantify the gap to offline optimal and to strong human baselines with confidence intervals.
- Interface coverage limits: Extend beyond stateless Value/Rank scoring to policies requiring persistent internal state, action-dependent constraints, combinatorial selections (e.g., set coverage with packing/knapsack constraints), and dynamic K; define safe, minimal stateful extensions or DSLs to capture these cases.
- Automated mechanism selection: Develop a principled method to select and configure Rank mechanisms (FullSort, SampleSort, PriorityQueue, hybrids) based on workload, decision frequency, and overhead budgets; jointly synthesize the policy and mechanism parameters (e.g., S, K, queue data structure).
- Feature dependence and acquisition: Systematically study which raw vs engineered features are necessary and sufficient per task; design automated feature synthesis/selection and low-overhead, high-fidelity telemetry pipelines; quantify the overhead and impact of feature collection.
- Evaluation fidelity (sim-to-real gap): Validate cache policies beyond simulators (libcachesim) and memory tiering beyond NUMA-based CXL emulation; measure performance drift on production hardware, at scale, under noisy co-tenancy and real failure modes.
- Instance definition and classifier robustness: Analyze sensitivity of the KMeans-based instance generator to feature choice, window size (first 50k requests), number of clusters, and drift; quantify misclassification rates, policy switching stability, and recovery strategies; compare with alternative online clustering/segmentation methods.
- Search cost and scalability: Report wall-clock time, compute cost, and token usage per instance; study scalability across hundreds of instances; develop budget-aware, parallel, and warm-started search (transfer from nearby instances).
- LLM dependence and reproducibility: Evaluate how model family/size, temperature, prompts, and evolutionary operators affect solution quality and cost; publish prompts, seeds, and heuristic corpora; quantify variance across runs.
- Safety and correctness: Beyond type/signature checks, add static and runtime verification for semantic constraints (e.g., not exceeding resource limits, preventing starvation); sandbox and privilege-separate injected code (eBPF/LD_PRELOAD) to mitigate system risk.
- Multi-objective optimization: Replace single scalarization with Pareto-frontier search and constraint handling (e.g., latency under CPU/energy caps, fairness under throughput targets); define and evaluate trade-off policies.
- Robustness to workload shift: Test synthesized policies under out-of-distribution and adversarial scenarios; quantify degradation under nonstationarity and tail events; add guardrails, fallback policies, and shadow evaluation for safe rollout.
- Interpretability and human-in-the-loop: Provide tools to analyze and simplify synthesized code, extract invariants, and map to known algorithms; measure and limit code complexity; support targeted human edits with search-aware feedback.
- Lifecycle and operations: Define practical triggers for re-synthesis (drift detectors), A/B and canary pipelines, rollback mechanisms, and on-line monitoring; quantify operational burden and time-to-deploy.
- Runtime overhead characterization: Microbenchmark the cost of scoring and data-structure maintenance for large N and high QPS; evaluate impact on tail latency and CPU/memory footprint; compare PQ vs sampling at production scales.
- Broader applicability: Validate on additional tasks promised by the interface taxonomy (e.g., congestion control, kernel qdiscs, CPU scheduling) with high-frequency decision loops and tight real-time constraints.
- Licensing, provenance, and privacy: Address legal and privacy risks of LLM-generated code and prompts containing proprietary workload characteristics; propose governance and auditing for code provenance.
- Failure handling in search: Develop automated repair for compile/runtime failures, diversity maintenance to avoid premature convergence, and mechanisms to prevent code bloat and dead code.
- Constraint satisfaction: Incorporate hard constraints (e.g., memory caps, fairness guarantees) into the search via constraint solvers or repair operators; ensure feasibility-by-construction.
- Comparison with neural policies: Conduct head-to-head studies vs RL/SL approaches on identical harnesses, reporting training/search costs, inference overheads, and stability.
- Quantifying human effort: Measure engineering effort to build scaffolding, templates, and evaluators; derive best practices for prompt and template design to minimize human-in-the-loop time.
- Cross-hardware generalization: Study portability across hardware generations (e.g., A100→H100, DDR→CXL); explore meta-learning or fine-tuning to accelerate adaptation.
- Joint tuning of mechanism parameters: Auto-tune parameters like S (sample size), K (selection size), and update cadences alongside policy synthesis, subject to latency/overhead budgets.
- Precise definition of “instance-optimal”: Rigorously specify the search space and objectives per task; report statistical confidence in policy rankings and sensitivity to harness noise.
- Broader metrics: For caching, go beyond object hit rate to byte hit rate, latency, CPU cost, and write amplification; for tiering, include stall cycles, bandwidth contention, NUMA traffic, and endurance.
- Online adaptation: Explore safe on-the-fly mutation/bandit-style adaptation with guardrails and shadow policies to reduce re-synthesis latency during rapid workload changes.
- Tooling and openness: Release the Vulcan framework, policy templates, harness APIs, and benchmark suites to enable community replication and extension across languages and platforms.
Practical Applications
Immediate Applications
Below is a concise list of deployable applications that leverage Vulcan’s instance-optimal heuristic synthesis, organized by sector and accompanied by tools/workflows and feasibility notes.
- CDN/Web caching eviction tuning (software, telecom, media)
- Use case: Replace hand-tuned eviction policies with Vulcan Rank-type scoring functions specialized per point-of-presence (POP), cache size, and workload (e.g., CloudPhysics-like traces).
- Tools/workflows: PriorityQueue-based Rank mechanism; offline evaluator with libcachesim; automated instance generation via clustering; runtime instance classifier to pick policies; A/B rollout.
- Assumptions/dependencies: Access to request traces and cache metadata; acceptable per-access O(log N) overhead; robust fallback if workload drifts; safe code injection and guardrails.
- Tiered-memory page promotion in NUMA/CXL systems (software, HPC, cloud infrastructure)
- Use case: Deploy LLM-synthesized Rank-type page hotness scoring to promote “top-K” pages from slow to fast memory tiers, improving latency/throughput.
- Tools/workflows: FullSort mechanism for infrequent decisions; LD_PRELOAD for dynamic injection; CloudLab or production servers for fidelity evaluation; stall cycles and bandwidth telemetry.
- Assumptions/dependencies: Decision frequency low enough for FullSort; correct pinning/migration; high-fidelity evaluator for specific applications; safe memory operations.
- Cloud autoscaling with instance-optimal replica counts (software, cloud)
- Use case: Value-type function computes n_replicas per service under workload-specific latency/throughput targets (plug into Kubernetes HPA-like controllers).
- Tools/workflows: Replay-based evaluator; guardrails (min/max replicas, cooldowns); templated constraints (read-only inputs, memory limits).
- Assumptions/dependencies: Reliable metrics (CPU, queue length, response times); fast evaluator to support frequent re-tuning; rollback plan for mispredictions.
- Congestion control tuning for video conferencing/streaming (software, telecom)
- Use case: Value-type cwnd function specialized for network conditions (RTT, loss, ACK timing) to improve QoE (latency smoothness, throughput).
- Tools/workflows: eBPF probes for runtime injection; Mahimahi-based evaluator; multi-objective score (fairness/latency/bandwidth).
- Assumptions/dependencies: Safe deployment under cross-traffic; fairness constraints; robust fallback to standard CC (e.g., Cubic/BBR).
- Database buffer cache management (software, finance, e-commerce)
- Use case: Rank-type scoring of pages/objects to maximize hit rate in DB buffer pools; specialized per application and workload phase.
- Tools/workflows: SampleSort to reduce overhead; trace- or replay-based evaluator; lightweight instance generator using unsupervised clustering.
- Assumptions/dependencies: Accurate per-object features (recency, frequency, size); low sorting overhead; careful isolation in production DB.
- Storage and filesystem prefetching (software, storage appliances)
- Use case: Rank or Value-type prefetch policies tailored to observed access patterns, improving I/O latency.
- Tools/workflows: Block-level telemetry; evaluator using synthetic workloads and real traces; guardrails to cap prefetch bandwidth.
- Assumptions/dependencies: Availability of access histories; minimal runtime overhead; avoidance of cache pollution.
- CPU/task scheduling tuners for OS nodes and container runtimes (software, robotics, HPC)
- Use case: Rank-type scoring to prioritize runnable tasks for specific objectives (latency, fairness, throughput) and workloads.
- Tools/workflows: PriorityQueue or SampleSort in user-space schedulers; evaluator in controlled testbeds; safe constraints in template (e.g., monotonic score semantics).
- Assumptions/dependencies: Feasible integration point (user-space or kernel module); low decision latency; rigorous testing for starvation/fairness.
- Energy-aware DVFS control (energy, mobile, HPC)
- Use case: Value-type frequency selection specialized per application phase to balance QoS with power/thermal limits.
- Tools/workflows: Replay-based evaluator; multi-objective optimization (energy and latency); hardware telemetry integration.
- Assumptions/dependencies: Access to thermal/power signals; platform support for DVFS; safety limits enforced.
- Academic research and teaching toolkit (academia)
- Use case: Rapid prototyping and evaluation of policy heuristics across Rank/Value tasks; reproducible experiments on caching, memory tiering, CC, scheduling.
- Tools/workflows: Shared templates, scoring-function libraries, heuristic DB; simulators/emulators (libcachesim, Mahimahi); standardized evaluation harnesses.
- Assumptions/dependencies: Access to LLMs (small/inexpensive models often suffice); clean separation of policy/mechanism in course infrastructure.
- DevOps/Platform guardrails for AI-generated systems code (policy, industry)
- Use case: Institutionalize Vulcan’s stateless-function pattern, static checks, runtime constraints, and A/B rollout for safe adoption of LLM-synthesized policies.
- Tools/workflows: Templates specifying invariants; static analysis; sandboxed evaluators; staged deployment; incident playbooks.
- Assumptions/dependencies: Organizational buy-in; versioning and audit trails; compliance with internal safety standards.
Long-Term Applications
Below are applications that require additional research, scaling, cross-system integration, or regulatory readiness before broad deployment.
- Continuous policy orchestration platform (“Vulcan Policy Orchestrator”) (software, cloud, telecom)
- Use case: End-to-end platform that auto-clusters workloads, runs evolutionary search, selects policies at runtime, and manages A/B rollouts across fleets.
- Tools/workflows: Automated instance generation, drift detection, multi-tenant rollout manager, feedback loop for re-synthesis.
- Assumptions/dependencies: Scalable evaluators; robust monitoring; safe automation gates; ops maturity.
- Cross-system policy library and marketplace (software ecosystem)
- Use case: Share instance-optimal scoring functions with metadata (workload, hardware, objectives), enabling reuse across organizations and products.
- Tools/workflows: Standardized Rank/Value interfaces; reproducibility records; provenance and licensing.
- Assumptions/dependencies: Community adoption; governance on security and IP; compatibility with diverse scaffolding.
- Multi-objective fairness/efficiency policies for datacenter networking and scheduling (software, telecom, cloud)
- Use case: Joint optimization of latency, throughput, fairness, tail behavior in congestion control and job scheduling at scale.
- Tools/workflows: High-fidelity evaluators (emulators/testbeds); multi-metric objective functions; formal guardrails.
- Assumptions/dependencies: Accurate models of contention; careful fairness constraints; potential standardization across tenants.
- Healthcare IT performance tuning (healthcare)
- Use case: Instance-optimal autoscaling, caching (EHR, imaging), and tiered storage for clinical workloads, reducing latency and cost.
- Tools/workflows: Privacy-preserving evaluators; synthetic data; hospital IT integration; compliance audits.
- Assumptions/dependencies: Strict regulatory compliance (HIPAA, GDPR); safety cases; stakeholder approvals.
- Low-latency finance systems (finance)
- Use case: Tailored CC, scheduling, and caching policies for trading and risk pipelines.
- Tools/workflows: Deterministic replay evaluators; fail-safe deployment; audit trails.
- Assumptions/dependencies: Regulatory constraints; predictable latency budgets; robust fallback policies.
- Critical infrastructure optimization (energy)
- Use case: Instance-optimal Value-type controllers for grid load balancing, storage dispatch, and real-time scheduling.
- Tools/workflows: High-fidelity simulators; digital twins; formal verification; staged rollout.
- Assumptions/dependencies: Access to real grid telemetry; rigorous safety certification; inter-operator coordination.
- Edge/IoT policy synthesis (software, robotics, energy)
- Use case: On-device or near-edge tuning for caching, scheduling, DVFS under constrained compute and intermittent connectivity.
- Tools/workflows: Small LLMs; offline tuning with replay; lightweight evaluators; federated update pipelines.
- Assumptions/dependencies: Resource limits; reliable telemetry; battery and thermal constraints.
- Compiler and GPU kernel tuning integration (software, HPC)
- Use case: Extend the approach to kernel search (e.g., CUDA) with Value/Rank-like abstractions over kernel parameters and schedules.
- Tools/workflows: Kernelbench-style evaluators; hardware-in-the-loop testing; parameterized scaffolding.
- Assumptions/dependencies: Robust compilation pipelines; performance-portability across GPUs; correctness verification.
- Robotics stack-wide heuristics (robotics)
- Use case: Rank/Value policies for real-time task scheduling, sensor fusion buffering, and motion-planning heuristics tailored to platforms and environments.
- Tools/workflows: High-fidelity simulators; safety constraints; formal verification; hardware testbeds.
- Assumptions/dependencies: Certification requirements; strict latency bounds; human-in-the-loop oversight.
- Standards and governance for AI-synthesized systems code (policy, industry)
- Use case: Develop norms and standards for templated constraints, evaluation fidelity, rollout procedures, and auditability of LLM-generated heuristics.
- Tools/workflows: Cross-industry working groups; conformance tests; incident reporting frameworks.
- Assumptions/dependencies: Broad stakeholder engagement; alignment with existing safety/security standards; evolving regulatory landscape.
Notes on feasibility across applications:
- Dependencies on high-fidelity evaluators increase costs; many production deployments will begin with simulator-based tuning and progress to hybrid evaluators.
- Vulcan’s success hinges on clean separation of policy (stateless Rank/Value scoring) from mechanism (data collection and action), plus strong guardrails in templates and evaluators.
- Smaller, inexpensive LLMs are often sufficient for generating correct, executable scoring functions given a constrained interface; however, validation (static checks, runtime constraints, A/B testing) remains essential.
- Assumptions often include access to workload traces, reliable telemetry, the ability to inject or override policy modules, and organizational readiness for safe iterative rollout.
Glossary
- Active queue management: Techniques to manage network queue lengths proactively (e.g., to reduce latency and packet loss) by dropping/marking packets before buffers overflow. "tasks such as scheduling, caching, or active queue management."
- Admission control: A policy that decides whether to accept or reject incoming work/requests based on resource availability or QoS goals. "cluster admission control~\cite{kerveros-admission-control}"
- Belady's MIN: Theoretical offline-optimal cache replacement policy that evicts the item whose next use is farthest in the future. "Belady's MIN~\cite{belady-min-1966}"
- BFQ: Budget Fair Queueing; a Linux I/O scheduler that assigns time budgets to processes to improve responsiveness and fairness. "I/O schedulers such as BFQ~\cite{bfq} encode responsiveness through per-process queues;"
- Block I/O prefetching: Predicting and fetching future disk blocks into memory before they are requested to reduce I/O latency. "Block I/O prefetching~\cite{mithril} & Select blocks to prefetch."
- CFS (Completely Fair Scheduler): Linux’s default CPU scheduler that approximates fair CPU time sharing among runnable tasks using a red–black tree. "Linuxâs CFS scheduler couples its policy with a redâblack tree mechanism~\cite{cfs-linux};"
- Chain-of-thought reasoning: An LLM prompting technique where models generate intermediate reasoning steps to improve problem solving. "chain-of-thought reasoning~\cite{chain-of-thought}"
- ChampSim: A trace-driven simulator for evaluating CPU microarchitecture components like caches and branch predictors. "simulators or emulators~\cite{libcachesim, omnet++, vidur, champsim, mahimahi}"
- CloudLab: A research testbed providing bare-metal servers and configurable networked environments for systems experiments. "CloudLab~\cite{cloudlab}"
- CloudPhysics dataset: A corpus of real-world block I/O traces used to evaluate caching and storage policies. "CloudPhysics dataset~\cite{cloud-physics-dataset}"
- Congestion control: Algorithms that regulate sending rates in networks based on feedback (e.g., loss, delay) to avoid congestion collapse and optimize throughput/latency. "Congestion control algorithms are often tailored for the Internet~\cite{bbr,copa,orca,c2tcp} versus datacenter workloads~\cite{dctcp,swift,timely},"
- cwnd (congestion window): A transport-layer control variable that bounds the amount of unacknowledged data in flight. "Value: compute the {\tt cwnd}"
- CXL (Compute Express Link): A cache-coherent interconnect standard for attaching accelerators and memory expanders to CPUs with low latency. "remote NUMA memory to emulate CXL."
- DRR (Deficit Round Robin): A fair queuing algorithm that schedules flows based on deficits (credits) allowing variable-size packets. "DRR-style qdiscs~\cite{qdisc-scrr,qdisc-drr} achieve fairness by maintaining per-flow subqueues."
- DVFS (Dynamic Voltage and Frequency Scaling): Technique to adjust CPU voltage/frequency to balance performance with power/thermal limits. "DVFS control~\cite{dvfs-sosp-2001}"
- eBPF: Extended Berkeley Packet Filter; a safe in-kernel virtual machine to run user-defined programs for monitoring and control. "injecting logic via eBPF probes."
- Evaluation harness: The experimental setup that compiles, runs, and scores candidate policies against defined metrics on target instances. "defining the evaluation harness used to assess candidate heuristics."
- Evolutionary search: An optimization method that iteratively mutates and selects candidate solutions based on performance to evolve better ones. "via evolutionary search over LLM-generated code."
- Exponential decay counters: Counters that weight recent events more heavily by decaying past counts exponentially over time. "exponential decay counters~\cite{lrb}"
- FullSort: A ranking mechanism that scores all candidates and sorts them to select the top K, with O(N log N) decision-time latency. "\textsf{FullSort} evaluates and sorts all objects at decision time,"
- Ghost lists: Auxiliary lists tracking recently evicted items to inform caching decisions (e.g., ARC). "``ghost lists'' containing items that were recently evicted from cache~\cite{arc,lirs,s3-fifo}"
- Horizontal autoscaling: Automatically adjusting the number of service replicas/pods based on load to meet performance targets. "horizontal autoscaling~\cite{kubernetes-hpa}"
- Instance classifier: A component that identifies which workload/hardware “instance” is currently active to select or trigger synthesis of a specialized policy. "the instance classifier, which is initialized with a set of initial instances,"
- Instance-optimal: Tailored to a specific workload and hardware context to maximize objective performance within a defined search space. "instance-optimal heuristics"
- I/O scheduler: Kernel module that orders block I/O requests to balance throughput, latency, and fairness. "I/O schedulers such as BFQ~\cite{bfq} encode responsiveness through per-process queues;"
- KMeans: A centroid-based clustering algorithm commonly used to partition datasets into K clusters. "into 10 clusters using KMeans."
- LD_PRELOAD: A dynamic linker mechanism to interpose and override symbols by preloading shared libraries. "dynamically injected via {\tt LD_PRELOAD}"
- libcachesim: A cache simulation library used to evaluate caching algorithms efficiently. "libcachesim~\cite{libcachesim}"
- LLM: A neural model trained on large text/code corpora capable of generating and reasoning about language and code. "LLMs."
- Lock-free design: Concurrency strategy avoiding locks to improve scalability and avoid blocking, often relying on atomic operations. "lock-free design~\cite{s3-fifo},"
- Mahimahi: A record-and-replay network emulator for evaluating transport protocols and applications. "Mahimahi emulator~\cite{mahimahi}"
- Memory tiering: Organizing memory into tiers (e.g., fast/slow) and moving data to optimize performance/cost. "memory tiering"
- NUMA: Non-Uniform Memory Access; a memory architecture where access latency depends on the memory’s proximity to the CPU. "remote NUMA memory"
- OMNeT++: A modular discrete-event simulation framework for networks and other systems. "simulators or emulators~\cite{libcachesim, omnet++, vidur, champsim, mahimahi}"
- Page promotion: Moving frequently accessed pages from a slower memory tier to a faster one to reduce access latency. "page promotion in tiered-memory systems"
- PriorityQueue: A maintained global ordering of candidates by score to enable O(K log N) selection at decision time. "\textsf{PriorityQueue} shifts work off the critical path by maintaining a globally ordered structure over all objects."
- qdisc (queueing discipline): Linux traffic scheduling framework that controls how packets are enqueued/dequeued on interfaces. "qdiscs~\cite{qdisc-scrr,qdisc-drr}"
- Rank-type heuristic: A policy that ranks candidate objects and selects the top K according to a scoring function. "which we term a Rank-type heuristic."
- Red–black tree: A self-balancing binary search tree ensuring O(log N) operations, used in many schedulers/structures. "redâblack tree mechanism~\cite{cfs-linux}"
- SampleSort: A selection mechanism that scores only a random subset S of candidates to approximate top-K with lower latency. "\textsf{SampleSort} reduces decision-time work by selecting a random subset of objects,"
- Tail latency: High-percentile response time (e.g., p95/p99) important for user experience and service-level objectives. "tail latency~\cite{robinhood-osdi18}"
- t-SNE: A nonlinear dimensionality reduction method for visualizing high-dimensional data. "visualized using t-SNE~\cite{t-sn"
- Top-K: Selecting the K highest-scoring items from a ranked list of candidates. "select the \textsf{topK} objects"
- Value-type heuristic: A policy that computes a scalar control value from system state (e.g., cwnd, frequency, replicas). "which we term a Value-type heuristic"
Collections
Sign up for free to add this paper to one or more collections.

