- The paper introduces a decomposition framework that splits error evolution into bias, noise, and alignment for robust adaptive control in dynamic environments.
- It demonstrates the method's effectiveness across supervised optimization, reinforcement learning, and meta-learning with empirical traces and diagnostic ablations.
- The approach improves learning stability and interpretability by dynamically modulating learning rates, update magnitudes, and exploration parameters based on real-time diagnostics.
Adaptive Learning Guided by Bias-Noise-Alignment Diagnostics: A Technical Overview
Introduction and Motivation
The paper "Adaptive Learning Guided by Bias-Noise-Alignment Diagnostics" (2512.24445) articulates a unified adaptive learning framework addressing the challenges commonly faced in nonstationary and safety-critical environments—namely, instability, slow convergence, and unreliable adaptation due to evolving learning dynamics. Traditional optimization algorithms and reinforcement learning (RL) protocols primarily respond to instantaneous or averaged gradient statistics and fail to account for the temporal structure of the loss or TD-error signals, leading to issues in robust adaptation, particularly under environmental drift and high variability.
To bridge this gap, the authors introduce a novel, model-agnostic decomposition of the error evolution signal into three orthogonal, interpretable components: bias (persistent drift), noise (stochastic variability), and alignment (repeated directional excitation resulting in overshoot). This decomposition is lightweight and online, providing architecture- and domain-independent adaptive diagnostics that can control learning rate, update magnitude, and exploration parameters.
The decomposition centers on tracking the temporal evolution of scalar error signals—such as loss in supervised learning or TD-error in RL—via the delta Δℓt=ℓt−ℓt−1. The components are formalized as:
- Bias (bt): Defined as an EMA of the incremental error signal, reflecting systematic drift.
- Noise (νt and σt2): Quantifying stochastic variability through EMAs of magnitude and residual variance.
- Alignment (st): A temporal smoothed cosine similarity between the gradient and momentum vectors, revealing persistent directional excitation.
Update rules for adaptive gates are based on normalized ratios (e.g., ρbias, ρnoise), providing scale-invariant indicators to modulate step-size and correction factors. This contributes explicit mechanisms to attenuate learning rates or introduce conservative corrections in the presence of persistent drift, high variability, or oscillatory update patterns.
Unification Across Learning Paradigms
Supervised Optimization (HSAO)
The Hybrid Sharpness-Aware Optimizer (HSAO) augments Adam-like optimizers with multiplicative bias/noise gates and an alignment-based correction term, yielding parameter updates that remain robust as error dynamics shift:
- Learning rates are adaptively reduced in response to high bias or noise.
- Directional correction guards against repeated overshoot by diminishing the component of the update that persistently aligns with past momentum.
Theoretical analysis under standard smoothness assumptions shows that the effective step-size is always upper-bounded, and updates are stable.
Reinforcement Learning (HED-RL)
Hybrid Error-Diagnostic RL (HED-RL) incorporates the diagnostics directly into actor-critic TD-error traces:
- Critic updates: Noise-diagnostic gating dampens updates during periods of high bootstrap target noise.
- Policy updates: Bias-diagnostic gating shrinks step sizes in the face of persistent TD drift.
- Entropy regularization: The entropy coefficient is dynamically tuned according to diagnostics rather than held fixed or manually scheduled, enabling principled exploration control.
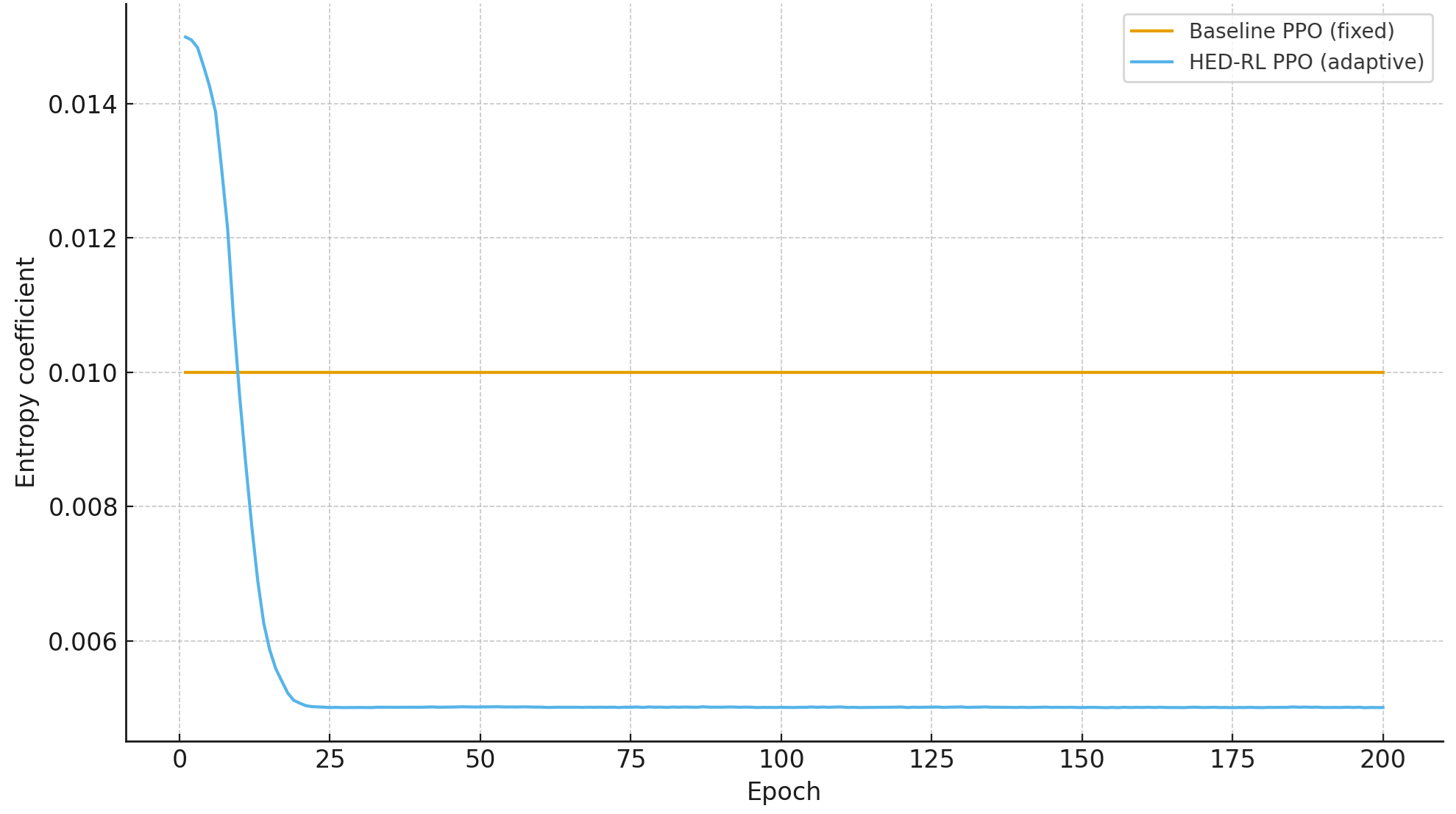
Figure 1: Entropy coefficient during training. Baseline PPO uses a fixed coefficient, while HED-RL adapts it based on TD-error bias/noise diagnostics.
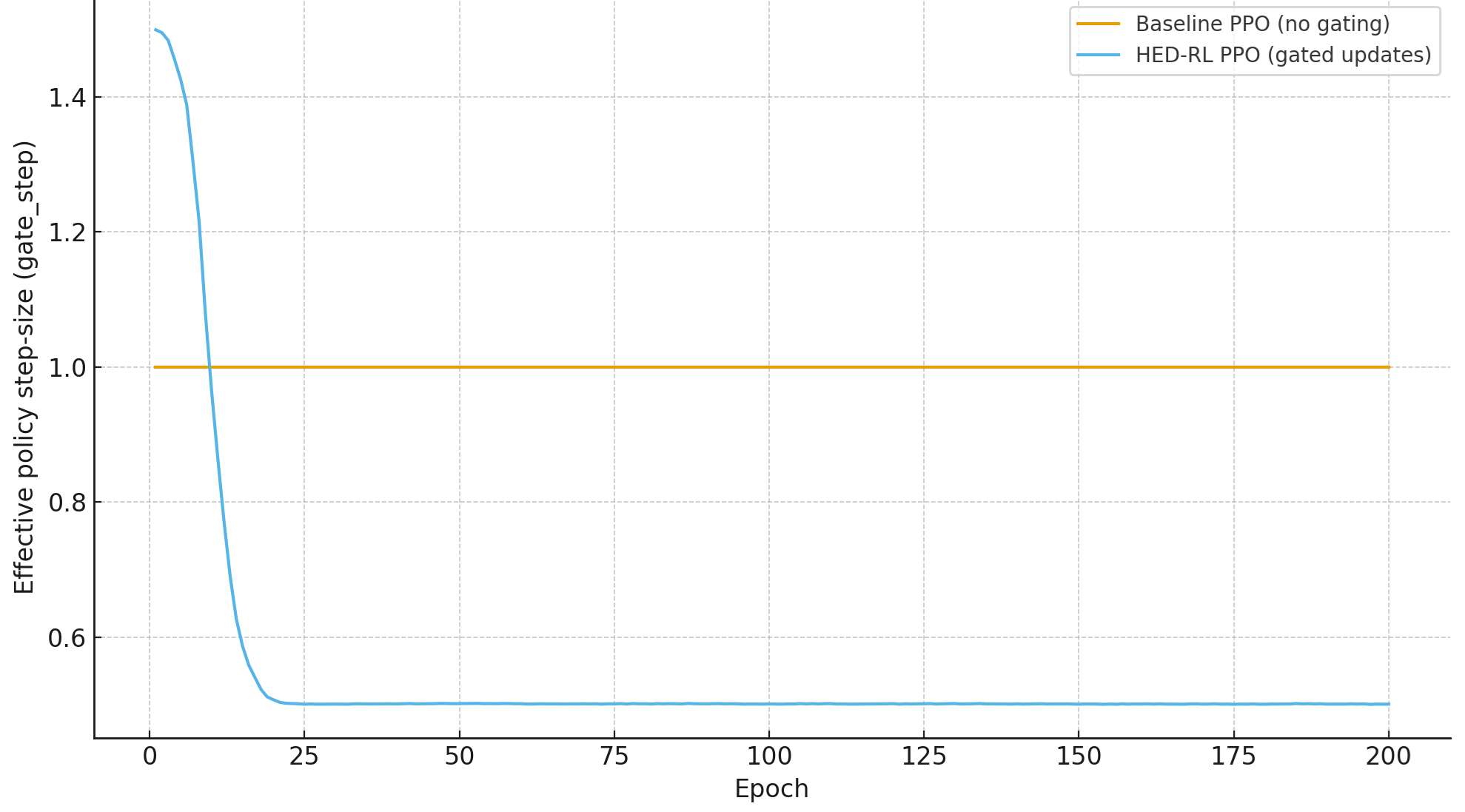
Figure 2: Effective policy update gate during training. Baseline PPO uses a constant update scale, whereas HED-RL automatically shrinks the effective update magnitude when TD-error noise increases.
Empirical traces validate that HED-RL responds adaptively to error statistics, leading to more reliable and interpretable modulation of policy entropy and update magnitudes.
In the meta-learning domain, the Meta-Learned Learning Policy (MLLP) incorporates diagnostic signals as explicit conditioning variables within learned optimizers. These optimizers map gradients, moments, and diagnostics to update proposals, enabling learned policies that are robust and interpretable under cross-task heterogeneity. Conditioning on the diagnostics allows for:
- Aggressive corrections under large bias.
- Conservative updates under high noise.
- Task-adaptive modulation of step-size and direction, grounded in error reliabilities.
Empirical Evidence and Diagnostic Ablations
The empirical section prioritizes the demonstration of diagnostic behavior rather than ultimate benchmarks. Notably:
- Diagnostic traces evolve predictably in response to underlying drift, noise, and oscillatory regimes.
- Adaptive learning rates and update gates show smooth, bounded modulation aligned with theoretical expectations.
- Ablation studies reveal that omission of any diagnostic results in characteristic forms of instability (e.g., overshoot, update explosions, or oscillations), establishing necessity and complementarity of bias, noise, and alignment components.
These results are shown to generalize across classic supervised optimization, RL, and meta-learning settings.
Theoretical Properties and Limitations
Boundedness and stability properties are rigorously established under standard smoothness and variance assumptions. Since adaptation is based entirely on first-order statistics of scalar temporal signals (as opposed to second-order geometry or global parameter space measures), the computational overhead is negligible. Nonetheless, there are important remaining challenges:
- Diagnostic signals can lag in the face of abrupt regime changes due to their reliance on moving averages.
- Sensitivity to hyperparameters governing EMA smoothing and diagnostic-to-adaptation transfer exists, though empirically less significant than raw learning rates.
- Further research is needed for decentralized and distributed learning settings, where error signals may have non-trivial aggregation dynamics.
Implications and Future Directions
The diagnostic-driven perspective constitutes a technically sound bridge between adaptive optimization, RL stabilization, and meta-learning, resonating with principles from robust control theory and biological learning. Key theoretical and practical implications include:
- Control-inspired adaptation mechanisms (gain scheduling) grounded in observable error structure, rather than solely on optimization geometry.
- Increased interpretability, as diagnostics provide actionable signals for system monitoring and intervention.
- Potential integration with uncertainty quantification, probabilistic modeling, and safety-centric AI systems.
The approach also suggests fertile ground for studies on continuous monitoring, early warning for instability, integration with error forecasting, and adaptation in high-noise or adversarial environments.
Conclusion
By decomposing error evolution into bias, noise, and alignment, the diagnostic-driven adaptive learning framework provides a unified, interpretable, and theoretically robust control layer for diverse learning scenarios. Empirical and theoretical evidence in the paper demonstrates the effectiveness of bias-noise-alignment diagnostics for stabilizing and guiding adaptation across supervised, reinforcement, and meta-learning paradigms. The paradigm shift advocated—placing temporal error structure at the center of adaptive mechanisms—opens new avenues for principled, robust, and transparent learning system design under nonstationary and safety-critical conditions.

