- The paper's main contribution is a variational optimization scheme that dynamically balances gradient estimators to overcome exploding gradients and TBPTT bias.
- The proposed method demonstrates faster convergence and lower test losses on CNN tasks compared to traditional optimizers like SGD and Adam.
- Improved training stability and promising generalization to out-of-distribution tasks pave the way for practical deployment of learned optimizers.
Understanding and Correcting Pathologies in the Training of Learned Optimizers
This essay provides an authoritative summary of the paper "Understanding and Correcting Pathologies in the Training of Learned Optimizers" (1810.10180). The paper addresses the challenges associated with training learned optimizers, focusing on two primary difficulties: exploding gradients and biases introduced by truncated backpropagation through time (TBPTT). It proposes a novel training scheme to overcome these pathologies, facilitating efficient learning of optimizers that outperform traditional hand-designed methods on specific tasks.
Introduction and Problem Statement
The training of learned optimizers refers to the process of developing optimization algorithms that are themselves learned components, often neural networks, rather than being hand-designed. This approach is inspired by the success of automatically learned features in deep learning, which have surpassed handcrafted features across various domains. However, unlike hand-designed optimizers (e.g., Adam, SGD), learned optimizers face significant training challenges, particularly energy bias and gradient explosion when performing TBPTT over many unrolled optimization steps.
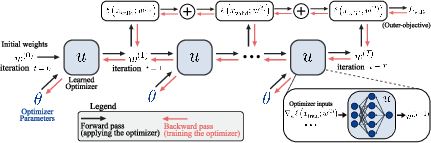
Figure 1: Top: Schematic of unrolled optimization. Bottom: Definition of terms used in this paper.
The core problem emerges from the need to compute gradients of meta-parameters (parameters of the optimizer) through the optimization process of another model. This is computationally expensive and can lead to pathologies such as unstable gradient norms and biased updates, complicating the use and implementation of learned optimizers in practice.
Approaches to Unrolled Optimization
Unrolled optimization involves backpropagating gradients through the unrolled application of an optimizer on a target model. The paper highlights two critical issues in this process: gradient explosion and bias.
- Exploding Gradients: When many optimization steps are unrolled, the gradient norm can grow exponentially, particularly if the sequence of steps forms a highly sensitive system.
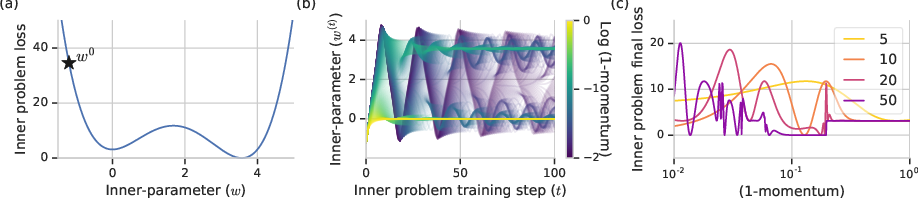

Figure 2: Outer-problem optimization landscapes can become increasingly pathological with increasing inner-problem step count.
- Bias with Truncated Backpropagation: To alleviate computational costs, TBPTT is often employed, truncating the unrolled steps. However, this introduces bias, resulting in suboptimal updates for the optimizer parameters.
- Proposed Solution: The paper introduces a variational optimization approach combining two unbiased gradient estimators: a reparameterization-based gradient and an evolutionary strategy (ES) based gradient. By dynamically weighting these estimators inversely proportional to their variances, the approach mitigates both exploding gradients and bias.
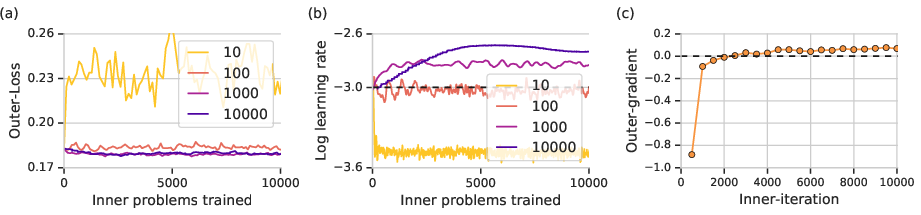
Figure 3: Large biases can result from reducing the number of steps per truncation in unrolled optimization.
Experimental Evaluation
The proposed method was evaluated on tasks involving training convolutional neural networks (CNNs). The experiments highlighted the following:
- Performance Improvements: The learned optimizer trained using the proposed scheme demonstrated faster wall-clock convergence compared to tuned first-order methods like SGD+Momentum and Adam. It achieved lower test losses on image classification tasks, indicating improved performance generalization.
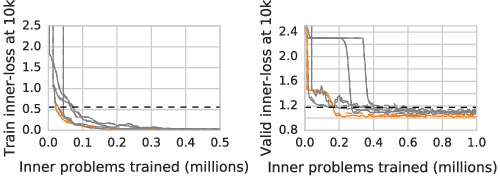
Figure 4: Performance after 10k iterations of inner-training for different learned optimizers over the course of outer-training.
- Stability: The dynamic scheme for combining gradient estimates resulted in stable training of learned optimizers, enabling the use of long unrolls, which were previously limited by exploding gradient norms.
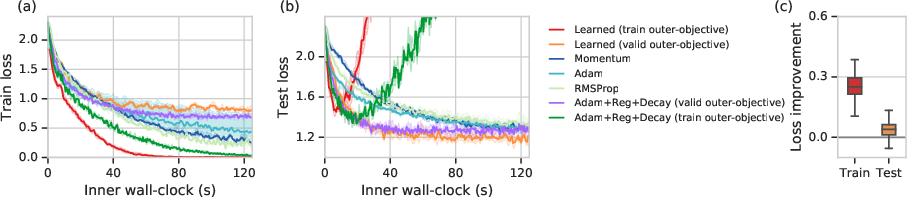
Figure 5: Learned optimizers outperform existing optimizers on training loss (a) and test loss (b).
- Generalization: Despite being specifically trained for certain types of inner problems, the learned optimizers demonstrated promising generalization capabilities on out-of-distribution tasks.
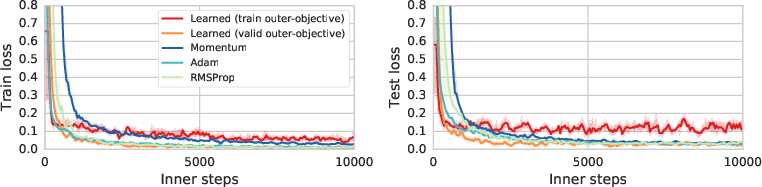
Figure 6: Train and test learning curves for an out-of-distribution training task consisting of a six-layer convolutional neural network trained on 28x28 MNIST.
Discussion on Results and Future Work
The study marks a significant step forward in the training methodology for learned optimizers by addressing foundational issues that limited their practicality and effectiveness. It opens pathways for learning optimizers that adapt to specific problem structures, exceeding the performance of traditional methods.
While this work has shown impressive improvements on specific tasks, further research is required to explore the boundaries of these methods, particularly their generalization across diverse tasks and environments. The insights gathered from this research can guide the development of both automated optimizers and enhancements to hand-designed methods.
Conclusion
The paper presents a robust methodology for overcoming common pathologies in the training of learned optimizers, leveraging variational optimization techniques. By dynamically balancing gradient estimators, it resolves issues associated with gradient explosion and TBPTT bias. These advances facilitate the effective deployment of learned optimizers in areas where traditional methods may not fully exploit problem-specific structures. Future work may extend these methods to broader classes of problems and further tailor them to real-world applications.