- The paper introduces a framework that extracts fact-focused explanation triplets from user reviews to evaluate factual consistency in recommendation explanations.
- It employs LLM- and NLI-based metrics to reveal significant gaps between surface-level text similarity and true factual grounding, with precision as low as 4%.
- The findings emphasize the need for improved model designs and rigorous evaluation protocols to ensure accuracy and transparency in explainable recommendation systems.
Factual Consistency in Text-Based Explainable Recommendation: An Evaluation Framework
Introduction and Motivation
Text-based explainable recommendation systems have rapidly progressed by leveraging LLMs to generate natural language rationales accompanying item recommendations. While these systems improve transparency and user trust, the critical dimension of factual consistency—ensuring explanations accurately reflect available user-item evidence—remains insufficiently explored. This paper addresses this deficit by presenting a comprehensive framework for factuality evaluation, incorporating both dataset construction and metric design, and revealing a substantial gap between perceived explanation quality and underlying factual correctness.
Framework for Factual Evaluation
The authors introduce a pipeline for extracting fine-grained, fact-focused ground-truth explanations. Using LLM-driven prompting, they decompose user reviews into atomic statement-topic-sentiment triplets, which are then aggregated through rule-based procedures into explicit explanations. This ground-truth formulation emphasizes isolating verifiable, polarized facts rather than surface fluency.
A series of augmented benchmark datasets is constructed from five major Amazon Reviews categories (Toys, Clothes, Beauty, Sports, and Cellphones). For each user-item interaction, the corresponding explanation is paired with triplets capturing key opinions about salient item attributes, enabling statement-level factual comparison across diverse domains.
Metrics for Factual Consistency
Moving beyond n-gram and semantic similarity metrics (e.g., BLEU, ROUGE, BERTScore), the authors propose statement-level factuality metrics grouped into two families:
- LLM-based metrics: Statement-to-Explanation Precision/Recall/F1 (St2Exp-P/R/F1) use LLMs to judge whether individual explanatory statements in generated outputs are supported by evidence, capturing both precision (lack of hallucination) and recall (coverage of ground truth).
- NLI-based metrics: Utilize entailment models to quantify whether generated statements are entailed by or contradict reference statements. Entailment precision and recall, as well as coherence (entailment minus contradiction), are reported.
This metric suite enables detailed dissection of factual consistency, distinguishing between models generating plausible but unsupported statements and those truly reflecting the review evidence.
Experimental Evaluation and Numerical Results
Six state-of-the-art models spanning RNNs, Transformers, and LLM-based approaches are evaluated. Standard text similarity metrics (e.g., BERTScore F1) are uniformly high (0.81–0.90), suggesting strong surface-level performance.
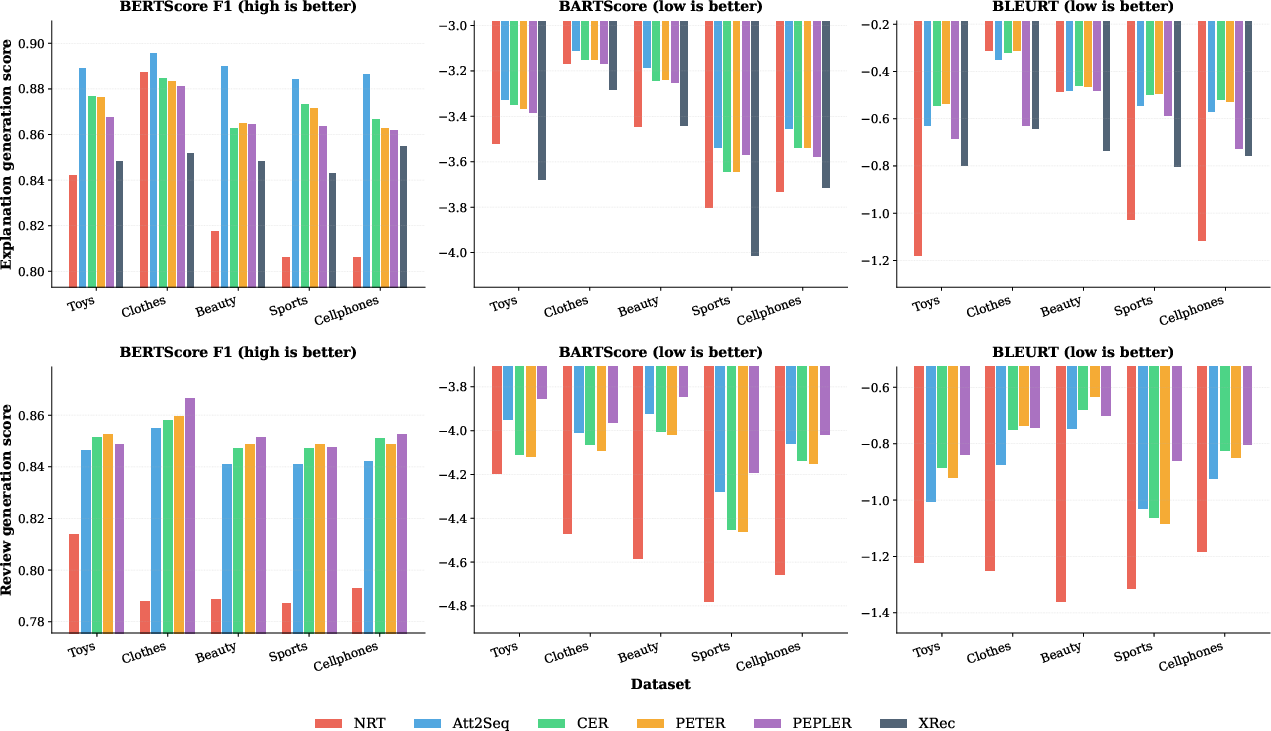
Figure 1: Text similarity metrics for explanation generation (top) and review generation (bottom) across models and domains; high scores mask low factual consistency.
However, when assessed with the proposed factuality metrics, all models display uniformly low performance. LLM-based statement-level precision ranges as low as 4.38% and peaks at only 32.88%; recall is even lower in most cases, with maxima below 30% across all tested domains and models. F1 scores for LLM-based metrics rarely exceed 20%, highlighting both poor precision (hallucination) and recall (missing explanatory evidence).
Notably, NLI-based metrics corroborate these findings: statement entailment precision varies from 4.66% to 24.8%, with recall stagnating below 15% in most cases. The coherence scores further demonstrate that some systems issue statements that contradict available evidence.
This stark divergence is further illustrated by the lack of correlation between BERTScore (semantic similarity) and St2Exp metrics, confirming that surface-level text similarity cannot serve as a proxy for factual correctness.
Discussion and Implications
These findings bring to light a major factuality gap in explainable recommendation: current models routinely generate fluent and plausible explanations that are not grounded in the supporting user-item evidence. This exposes users to potential misinformation, undermining system transparency and trustworthiness.
The implications are two-fold:
- Practical: There is an urgent need to adopt evaluation standards that rigorously assess factual consistency of explanations, especially in user-facing products where transparency and accuracy are paramount.
- Theoretical: Achieving factual consistency may require architectural innovations in model design (e.g., explicit fact selection, evidence retrieval, or controlled generation) or loss functions that directly incentivize factual grounding during training. The use of statement-level metrics as learning objectives could drive progress toward this goal.
Future work may focus on (1) improving triplet extraction reliability (e.g., human-in-the-loop verification), (2) exploring finer-grained, user-aligned aggregation strategies for ground truth, and (3) developing architectures and training paradigms that prioritize the alignment between recommended item rationales and verifiable user evidence.
Conclusion
This paper delivers a rigorous empirical analysis of factual consistency in text-based explainable recommendation, introducing an LLM-assisted framework for statement-level ground-truth extraction and evaluation. Despite high scores on conventional similarity metrics, all evaluated models exhibit low factuality—both in precision and recall—indicating widespread hallucination and omission of salient factual content in generated explanations. The research underscores that semantic fluency alone is inadequate for trustworthy recommendation explanations and establishes a concrete agenda for the next generation of factuality-oriented recommendation systems.