Taming Hallucinations: Boosting MLLMs' Video Understanding via Counterfactual Video Generation
Abstract: Multimodal LLMs (MLLMs) have made remarkable progress in video understanding. However, they suffer from a critical vulnerability: an over-reliance on language priors, which can lead to visual ungrounded hallucinations, especially when processing counterfactual videos that defy common sense. This limitation, stemming from the intrinsic data imbalance between text and video, is challenging to address due to the substantial cost of collecting and annotating counterfactual data. To address this, we introduce DualityForge, a novel counterfactual data synthesis framework that employs controllable, diffusion-based video editing to transform real-world videos into counterfactual scenarios. By embedding structured contextual information into the video editing and QA generation processes, the framework automatically produces high-quality QA pairs together with original-edited video pairs for contrastive training. Based on this, we build DualityVidQA, a large-scale video dataset designed to reduce MLLM hallucinations. In addition, to fully exploit the contrastive nature of our paired data, we propose Duality-Normalized Advantage Training (DNA-Train), a two-stage SFT-RL training regime where the RL phase applies pair-wise $\ell_1$ advantage normalization, thereby enabling a more stable and efficient policy optimization. Experiments on DualityVidQA-Test demonstrate that our method substantially reduces model hallucinations on counterfactual videos, yielding a relative improvement of 24.0% over the Qwen2.5-VL-7B baseline. Moreover, our approach achieves significant gains across both hallucination and general-purpose benchmarks, indicating strong generalization capability. We will open-source our dataset and code.

Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What is this paper about?
This paper tackles a common problem in AI that watches videos and answers questions about them: the models often “hallucinate.” That means they give answers that sound reasonable in words but don’t match what’s actually in the video. The authors build a way to create tricky, “what-if” videos and questions that force the AI to pay attention to the visuals, not just guess from common sense. They also design a new training method to make the models more grounded and reliable.
What questions are they trying to answer?
- How can we stop video AI models from relying too much on common sense or language patterns and instead focus on what the video truly shows?
- Can we create lots of high-quality, tricky training data—without huge manual effort—that teaches models to notice small but important visual changes?
- Can a better training strategy make models both less likely to hallucinate and still strong on regular video tasks?
How did they do it?
The authors introduce two main things: a data-making system called DualityForge and a training recipe called DNA-Train.
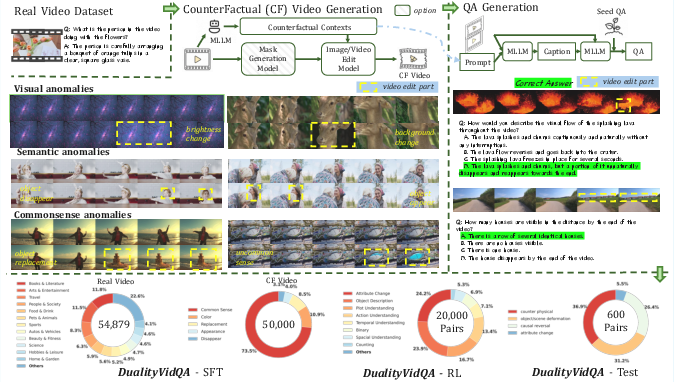
DualityForge: Making “what-if” videos at scale
Think of a “spot-the-difference” game, but for videos. DualityForge takes a real video and makes a carefully edited version that breaks expectations. It embeds clear information about what was changed, and then automatically writes questions and answers that hinge on that change.
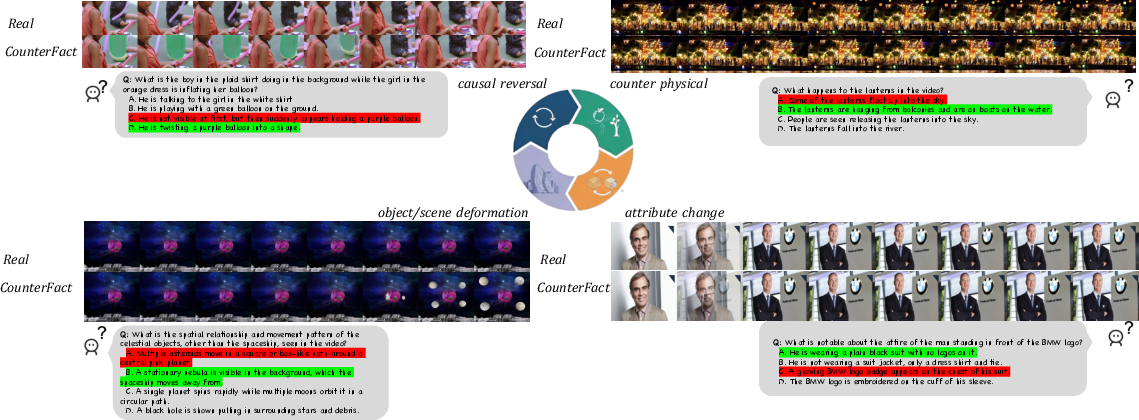
They create three kinds of “counterfactual” (what-if) edits:
- Visual anomalies: Basic pixel tweaks (like changing brightness or contrast) that don’t change the meaning of the scene but can trip up models.
- Semantic anomalies: Object-level changes (like making an object disappear midway).
- Commonsense anomalies: Breaking physical rules (like impossible motion or illogical events).
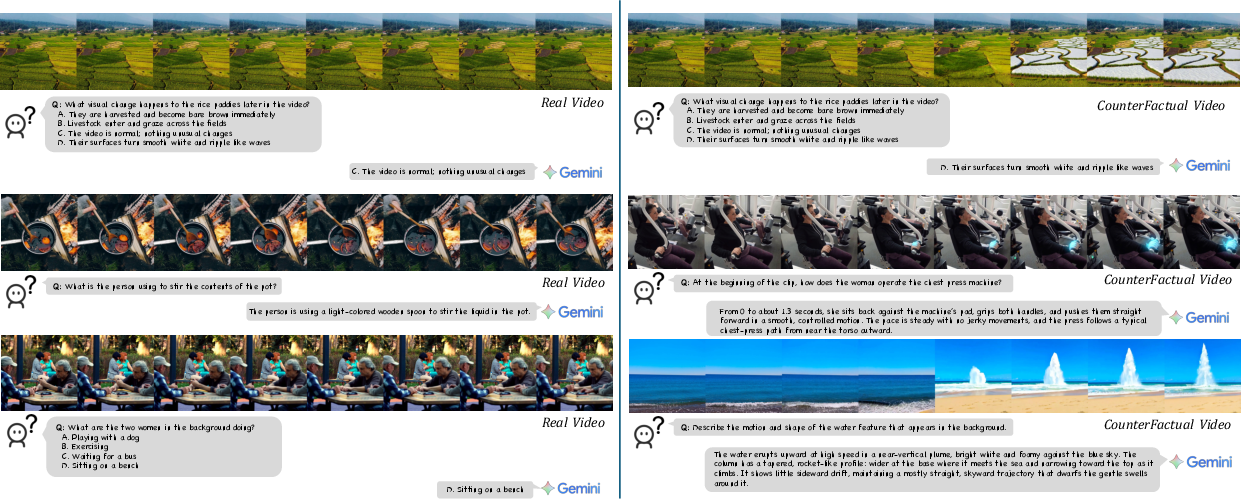
Here’s the clever part: the system produces pairs—an original video and an edited video—and the same question should have different correct answers for the two videos. This forces the model to look, not guess.
What they built:
- A large dataset called DualityVidQA with about 144,000 video–question–answer examples.
- Around 81,000 unique videos totaling roughly 100 hours.
- A special test set of 600 tough pairs to measure hallucinations.
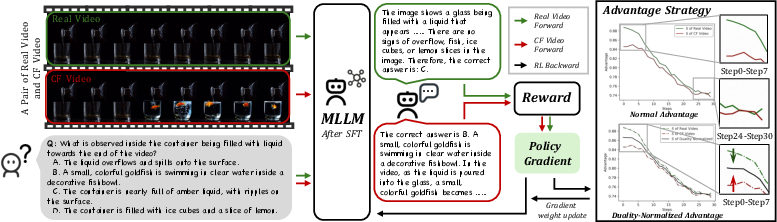
DNA-Train: A two-step training recipe
To make the most of these paired videos, they train models in two stages:
- Supervised Fine-Tuning (SFT): First, the model learns from both real and edited videos so it can handle normal footage and spot anomalies. This is like guided practice with answers provided.
- Reinforcement Learning (RL): Next, the model is asked to produce answers, gets a score (reward) for correct ones, and adjusts itself to do better. This strengthens good habits like checking the video carefully.
A key twist: “Duality-Normalized Advantage”
- Imagine training on both real and edited videos is like lifting weights with both arms. If one arm (say, real videos) is stronger, it will do more work and get more gains, and the other arm (edited videos) falls behind.
- The authors balance the “training effort” from real vs. edited video pairs by normalizing the learning signal, so both contribute equally. This keeps training stable and ensures the model learns to pay attention in both cases.
What did they find?
- Big drop in hallucinations: On their new test (DualityVidQA-Test), their method improves performance by about 24% compared to a strong baseline (Qwen2.5-VL-7B).
- Better on hard, counterintuitive videos: The model handled “counter-physical” cases (like breaking physics) much better than others.
- No trade-off with general skills: The improved model also gets better scores on standard video benchmarks (like TempCompass, MVBench, TOMATO, and TVBench), meaning it didn’t just specialize in tricks—it became broadly stronger.
- Strong generalization: Gains are seen across different model sizes and even with different model families.
Why does this matter?
AI that understands videos needs to trust its eyes, not just its “gut feelings” about what usually happens. This work:
- Makes video AI more reliable in unusual or deceptive situations.
- Shows that generating smart, “what-if” training examples can make models understand better, not just memorize patterns.
- Provides a large, open dataset and code that others can use to build safer, more accurate video systems (e.g., for safety monitoring, sports analysis, education, or media tools).
In short, by teaching models with carefully crafted “spot-the-difference” video pairs and training them to balance attention between real and edited clips, the authors significantly reduce hallucinations and boost overall video understanding.
Knowledge Gaps
Knowledge Gaps, Limitations, and Open Questions
Below is a concise list of concrete gaps and open problems left unresolved by the paper that future work could address:
- Synthetic-to-real gap: The training signal primarily comes from diffusion-edited counterfactual videos; it is unclear how well the learned robustness transfers to naturally occurring anomalies and real-world counterfactual events.
- Artifact exploitation risk: Models may key on editing artifacts (temporal flicker, mask edges, texture inconsistencies) rather than genuine counterfactual semantics; no analysis isolates artifact-driven shortcuts or quantifies artifact prevalence.
- Limited human validation: Training data are automatically generated/verified by MLLMs; there is no large-scale human audit of QA correctness, edit fidelity, or perceptual realism to ensure label quality and avoid cascading model bias.
- Small test set: DualityVidQA-Test contains only 600 pairs; statistical power, category coverage, and reliability under fine-grained strata (e.g., rare object classes, subtle temporal manipulations) remain unquantified.
- Short-clip bias: 80% of videos are 2–6 seconds; performance and stability on long-horizon counterfactual reasoning, multi-step causal chains, and events beyond 30 seconds are not evaluated.
- Narrow modality scope: The framework ignores audio; many real counterfactual cues (e.g., mismatched sound-source causes, temporal asynchrony) are audio-visual. How to synthesize and evaluate multimodal counterfactuals remains open.
- Category coverage and balance: The paper does not report category/attribute distributions (objects, scenes, actions) or imbalance corrections; it is unknown whether improvements generalize beyond the dominant categories in the generated data.
- Commonsense validity: “Commonsense anomaly” edits may be visually implausible or physically unrealistic; there is no metric for physical plausibility or a human study validating realism across categories.
- Grounding evaluation: The method claims better visual grounding, but evaluation is QA-only; there is no spatial/temporal grounding test (e.g., spatio-temporal localization of the anomaly) to confirm evidence-based reasoning.
- Free-form generalization: RL uses verifiable multiple-choice rewards; it is unclear whether gains transfer to open-ended responses (generation, rationale, captioning) or to tasks without deterministic verifiers.
- Explanation quality: The approach does not assess quality, faithfulness, or calibration of generated explanations/rationales, nor whether reduced hallucinations correspond to better self-reported uncertainty.
- Reward design robustness: The correctness/format reward may be gamed by formatting heuristics or spurious option patterns; no analysis of reward hacking, adversarial prompts, or robustness to perturbed answer sets.
- Advantage normalization theory: The proposed pair-wise ℓ1 advantage normalization lacks theoretical convergence guarantees and sensitivity analysis (e.g., to non-binary/noisy rewards, differing group sizes, or heterogeneous trajectory lengths).
- Hyperparameter sensitivity: No systematic study of DNA-Train sensitivity to group size G, normalization constants, batch composition, or sampling ratios; practical stability regions are unknown.
- Scaling behavior: Gains diminish at larger model scales (e.g., 72B) but confounded by shorter RL schedules; scaling laws with respect to model size, data size, and RL steps are not established.
- Compute and efficiency: The pipeline requires heavy video editing, multi-MLLM verification, and RL with 16 samples per prompt; there is no compute/efficiency analysis or comparison to inference-time anti-hallucination methods under equal budgets.
- Cross-model bias leakage: The same families of MLLMs are used to propose contexts, verify edits, and train target models; potential bias leakage or circularity (teaching-to-the-test) is not quantified.
- Cross-dataset generalization: While some external benchmarks are used, there is no evaluation on long-form or domain-shift datasets (egocentric video, medical, surveillance, driving) to test out-of-domain robustness.
- Failure mode taxonomy: The paper reports aggregate accuracies but lacks a granular error analysis (e.g., temporal misbinding vs. attribute errors vs. causal confusion), limiting insights for targeted improvements.
- Negative side effects: The method may increase “false suspicion” (over-detection of anomalies) on real videos; a trade-off analysis of false positives vs. hallucination reduction is missing.
- Safety and ethics: The generation of counterfactuals (e.g., accidents, harmful events) is not audited for safety, content moderation, or misuse risks; licensing and provenance of edited web videos are not discussed.
- Contamination checks: It is unclear whether web-sourced videos overlap with those in evaluation benchmarks; no data contamination or near-duplicate audit is reported.
- Task breadth: The impact on other video tasks (temporal localization, action detection, retrieval, step-by-step reasoning) is untested; applicability beyond QA remains unknown.
- Multilinguality: The dataset and evaluations appear English-centric; cross-lingual robustness and the effect of language priors in non-English settings are not assessed.
- Streaming/online settings: The approach is untested for streaming video, limited context windows, or latency-constrained inference—important for real-world deployment.
- Edit quality metrics: No quantitative video-editing quality measures (e.g., temporal consistency metrics, realism scores) are reported to benchmark the underlying synthesis pipeline.
- Pair-missing scenarios: DNA-Train assumes paired real–CF samples; how the method performs with unpaired or partially paired data, or in domains where pairing is infeasible, is not addressed.
- Benchmark diversity in hallucinations: Beyond EventHallusion and the authors’ test set, broader hallucination taxonomies (e.g., linguistic hallucinations, identity confusion, spatial reasoning illusions) are underexplored.
- Decoding policy robustness: All evaluations use greedy decoding; performance under temperature sampling, nucleus sampling, or constrained decoding (common in practice) is unknown.
Practical Applications
Practical, real-world applications derived from the paper
Below are actionable applications that leverage the paper’s key contributions—DualityForge (controllable counterfactual video generation with embedded context), DualityVidQA (large-scale paired video-QA dataset), and DNA-Train (two-stage SFT+RL with pair-wise ℓ1 advantage normalization). Each item names specific use cases, sectors, potential tools/products/workflows, and critical assumptions or dependencies.
Immediate Applications
The following can be deployed or piloted with current tooling (diffusion-based video editors, open MLLMs, RLVR frameworks) and standard ML engineering practices.
- Robustness hardening for video MLLM products (software, media, robotics, education)
- Use DNA-Train to fine-tune existing video-capable MLLMs on paired real/counterfactual data, reducing visual ungrounded hallucinations and improving general video QA performance.
- Tools/workflows: integrate LLamaFactory for SFT and SWIFT/DAPO for RLVR; adopt pairwise accuracy checks using DualityVidQA-Test; add contract-level reliability gates in CI.
- Assumptions/dependencies: availability of the released DualityVidQA/code; compatibility with the base MLLM; GPU capacity for short RL runs; adherence to the paper’s formatting/verifier rules.
- Counterfactual stress-testing suite for multimodal AI (security/surveillance, autonomous systems QA, robotics)
- Generate domain-specific counterfactual videos (object disappearances, causal reversals, attribute changes) with DualityForge to audit model grounding and quantify hallucination risk before deployment.
- Tools/products: “Counterfactual Video Red-Team Kit” (API for FLUX-Kontext/VACE editing + shared-question contrastive QA generation + multi-MLLM verification); reliability dashboards with pairwise metrics.
- Assumptions/dependencies: licensing for diffusion editors (VACE, FLUX-Kontext), access to domain video assets, governance to prevent misuse of edited videos.
- CCTV analytics with anomaly-aware question answering (security, retail loss prevention, transportation hubs)
- Replace prior-heavy captioning/QA with DNA-trained models that answer operator questions grounded in visual evidence (e.g., “Did the bag vanish between frames?”).
- Tools/workflows: short-clip ingestion (2–6s), operator prompt templates, pairwise drift monitors; on-prem inference for privacy.
- Assumptions/dependencies: privacy-compliant data pipelines, alignment for sensitive use, model latency budgets for near-real-time response.
- Post-production continuity and plausibility checking (media/entertainment)
- Editors can auto-generate counterfactual variants of scenes and use contrastive QA to catch continuity errors or physics violations that assistants might miss.
- Tools/products: “Continuity QA Assistant” (DualityForge + contrastive QA prompts + verification), plug-ins for NLEs.
- Assumptions/dependencies: tight integration with existing editing suites; consistent handling of creative edits vs. true anomalies.
- Courseware for teaching physics and logic with counterfactuals (education)
- Create short counterfactual clips that violate norms (e.g., causal reversal) and auto-generate grounded quizzes; students justify corrections.
- Tools/workflows: DualityForge authoring + MLLM QA generation with embedded context; LMS integration.
- Assumptions/dependencies: educator oversight; transparent disclosure that clips are edited; age-appropriate curation.
- Internal reliability auditing for legal/evidence review workflows (policy/legal operations)
- Use paired contrastive QA tests to calibrate and certify video summarization assistants to minimize hallucinations in pre-review (not for evidentiary conclusions).
- Tools/workflows: “Video Reasoning Reliability Audit” harness; mandatory pass thresholds on pairwise metrics.
- Assumptions/dependencies: strict governance; clear separation of audit vs. evidentiary workflows; watermarking of edited content.
- RL advantage normalization plug-in for multimodal training (ML platforms, MLOps)
- Adopt Duality-Normalized Advantage to balance gradients across real/counterfactual batches, stabilizing RLVR fine-tuning without entropy collapse.
- Tools/products: “DNA-Train” optimizer module compatible with GRPO/DAPO RLVR stacks; scripts for per-group ℓ1 scaling.
- Assumptions/dependencies: access to verifiable rewards (single correct answer), policy codebase amenable to advantage re-weighting.
- E-commerce product video QA for attribute correctness (e-commerce)
- Use semantic anomaly edits to test if assistants accurately report product attributes (color, size, brand) under occlusions or substitutions.
- Tools/workflows: domain-specific DualityForge presets (attribute change class), acceptance tests before deployment.
- Assumptions/dependencies: curated product video corpus; tolerance for short-clip focus; bias checks for brand-sensitive contexts.
- Consumer video assistants with fewer hallucinations (daily life)
- Improve home security clip summaries and sports highlight Q&A with better grounding under unusual events (e.g., object appearing/disappearing).
- Tools/workflows: DNA-trained model behind consumer apps; “pairwise self-test” mode for on-device reliability checks.
- Assumptions/dependencies: mobile/edge deployment constraints; user consent and privacy safeguards.
- Industrial process monitoring via video QA (energy, manufacturing)
- Audit assistants that monitor equipment and workflows; use counterfactual edits to ensure models detect abnormal states rather than defaulting to priors.
- Tools/workflows: DualityForge templates for machinery/scene deformation; acceptance tests in digital twins.
- Assumptions/dependencies: domain video availability; safety protocols; integration with SCADA/digital twin systems.
Long-Term Applications
The following require further research, scaling, domain adaptation, or regulatory validation before broad deployment.
- Safety-critical perception in autonomous driving and mobile robotics (transportation, robotics)
- Train/evaluate perception QA modules resilient to rare and counterfactual events (e.g., causal reversals, impossible motions) to reduce prior-driven errors.
- Potential products: “Autonomy Reliability Suite” with counterfactual generators and contrastive QA for scenario coverage; integration with simulation.
- Assumptions/dependencies: extensive domain-specific datasets, standardized safety benchmarks, certification pathways, real-time constraints beyond short clips.
- Medical video decision support with audited grounding (healthcare)
- Ultrasound/endoscopy assistants audited with counterfactual stress tests to ensure anomaly detection relies on visuals, not priors; gradual deployment as assistive tools.
- Potential workflows: clinical-grade DualityForge variants, verified QA curricula, post-market surveillance with pairwise metrics.
- Assumptions/dependencies: rigorous clinical validation, regulatory approval, medical data stewardship; dedicated medical benchmarks beyond general short videos.
- Regulatory benchmarks and procurement standards for multimodal AI grounding (policy, compliance)
- Establish pairwise contrastive QA as a standard hallucination audit; require pass thresholds for public-sector AI procurements and safety assurance.
- Potential tools: “Grounded Video Reasoning Certification” programs; public DualityVidQA-like test suites with governance.
- Assumptions/dependencies: multi-stakeholder consensus, transparent evaluation protocols, model cards documenting stress-test outcomes.
- Synthetic counterfactual data services for rare-event training (AI/data services, media tech)
- Commercialize DualityForge-like pipelines to generate audited counterfactual corpora for clients (e.g., rare factory faults, emergency scenarios).
- Products: “Counterfactual DataOps Platform” with AIGC video editing, embedded context, multi-MLLM verification, and legal compliance.
- Assumptions/dependencies: robust watermarking, provenance tracking, ethical use policies; scalable diffusion models with domain adapters.
- Deepfake and deceptive content detection via grounded QA (trust & safety)
- Use the framework to build detectors that query videos with contrastive prompts, flagging content that presents counter-commonsense cues or inconsistent grounding.
- Tools: “Grounded QA Anti-Deception” APIs; auditor agents cross-checking visual evidence vs. generated narratives.
- Assumptions/dependencies: domain-specific deception benchmarks; careful handling to avoid false positives; collaboration with platforms for moderation.
- Cross-modal extension to audio and sensor streams (multimodal AI R&D)
- Extend DualityForge/DNA-Train principles to audio, time-series, and multi-sensor fusion, synthesizing counterfactual anomalies and contrastive QA pairs for grounding across modalities.
- Workflows: paired real/counterfactual sensor traces; RLVR with verifiable outcomes.
- Assumptions/dependencies: suitable generative editors for non-visual modalities; verifiers; domain-appropriate reward functions.
- AR wearables and assistive perception under unusual conditions (consumer devices, accessibility)
- Grounded video understanding on-device to reliably assist navigation or task guidance when environments are atypical.
- Products: “AR Grounded Reasoning Module” with compact DNA-trained models.
- Assumptions/dependencies: energy-efficient architectures, on-device RLVR alternatives, privacy-by-design.
- Simulation-enhanced training with counterfactual curricula (enterprise ML)
- Combine simulators and DualityForge to produce structured curricula of increasing anomaly complexity, optimizing the “intermediate difficulty” regime where learning signals peak.
- Tools: curriculum schedulers; automated advantage normalization across scenario types.
- Assumptions/dependencies: scalable simulators; curriculum design research; automated verification of generated tasks.
- Enterprise reliability SLAs based on pairwise metrics (MLOps, governance)
- Define service-level objectives using pairwise accuracy (must-answer both original and edited correctly) to measure and enforce grounded visual reasoning.
- Tools: reliability dashboards; continuous red-team pipelines; audit trails.
- Assumptions/dependencies: standardized acceptance criteria; periodic re-certification; integration with model versioning and deployment controls.
Notes on assumptions and dependencies that affect feasibility
- Dataset/code release: The paper states an intent to open-source; immediate adoption depends on public availability or internal replication of DualityForge/DualityVidQA.
- Editing stack: Pipelines reference VACE, FLUX-Kontext, OpenCV, and multi-MLLM verification; licensing, compute, and domain adapters are required for production.
- Scope of clips: Most data involves short (2–6s) videos; long-horizon reasoning will need additional datasets and possibly new verification/reward designs.
- Verifiable rewards: RLVR relies on deterministic correctness checks; domains without clear ground-truth answers (e.g., free-form narration) require adapted verifiers.
- Ethics and governance: Synthetic counterfactuals can be misused; watermarking, provenance, disclosures, and policy frameworks are essential—especially in legal, medical, and public-sector settings.
- Compute and latency: RL fine-tuning and inference budgets must match deployment constraints (edge devices, real-time monitoring).
- Domain generalization: Performance gains shown on specific benchmarks; transferring to safety-critical domains requires new datasets and rigorous validation.
Glossary
- advantages (RL): In policy gradient methods, the advantage quantifies how much better an action is than a baseline, scaling the gradient update. "We use the norm of advantages, , as a proxy for the total learning signal magnitude from a group of responses"
- AI-Generated Content (AIGC): Media produced by generative AI systems (e.g., images, videos, audio) used here to synthesize training data. "Inspired by the recent advances in AI-Generated Content (AIGC)~\cite{openai2023dalle3, openai2024sora, agostinelli2023musiclm}"
- auxiliary distribution: A secondary probability distribution used to contrast or adjust a model’s outputs (e.g., in contrastive decoding). "Training-free contrastive decoding reduces this effect by contrasting the original logits with an auxiliary distribution~\citep{li2022contrastive,chuang2023dola}"
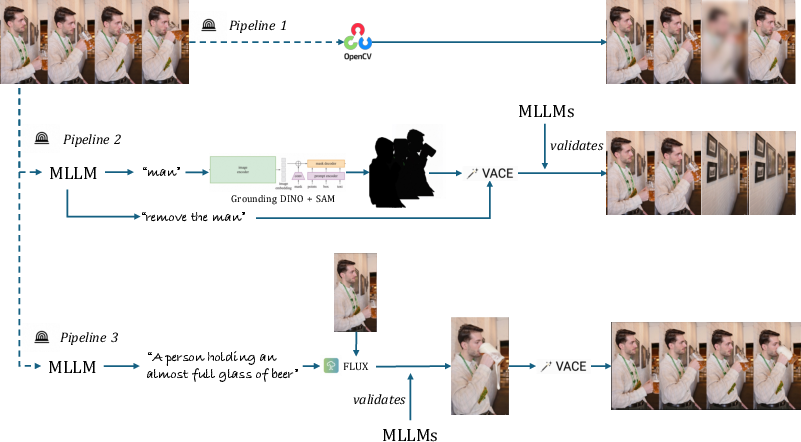
- commonsense anomaly: A counterfactual edit violating physical laws or everyday plausibility in a video. "Common Sense Anomaly: an MLLM propose commonsense violations, FLUX-Kontext edits frames, edits are re-verified by multiple MLLMs, and VACE interpolates the final video."
- contrastive decoding: An inference technique that contrasts model outputs with an auxiliary distribution to reduce hallucinations. "Training-free contrastive decoding reduces this effect by contrasting the original logits with an auxiliary distribution~\citep{li2022contrastive,chuang2023dola}"
- contrastive QA: A training/evaluation setup requiring different answers to the same question across paired (original vs. edited) videos to enforce visual grounding. "we leverage the dual nature of our data (original vs. edited videos) to construct shared-question contrastive QA pairs."
- counterfactual context: Structured specifications of alterations (visual, semantic, or commonsense) embedded into videos to induce counterfactual scenarios. "We categorize counterfactual context into three hierarchical levels of increasing complexity."
- counterfactual video: A video intentionally edited to depict events that violate typical expectations or physics. "counterfactual videos that defy common sense."
- cross-entropy loss: A standard supervised learning loss measuring the difference between predicted and true token distributions. "The training objective follows the cross-entropy loss: $\mathcal{L}_{\text{SFT} = -\sum_{i=1}^{N} \log p_\theta(y_i|x_i)$"
- DAPO: A reinforcement learning algorithm variant designed for stable optimization over long trajectories. "DAPO~\cite{yu2025dapo} was specifically designed to overcome these limitations with enhancements for stable optimization over long trajectories."
- deterministic verifier: A rule-based or programmatic function that deterministically assigns rewards based on correctness, avoiding noisy evaluators. "which uses a deterministic verifier to provide unbiased, ground-truth rewards."
- diffusion models: Generative models that iteratively denoise random noise to synthesize images or video content. "powered by diffusion models~\cite{ho2020denoising,song2020denoising}"
- divergence measure: A function quantifying the difference between probability distributions. "where is a divergence measure, and are small and large thresholds, respectively."
- DNA-Train (Duality-Normalized Advantage Training): A two-stage SFT+RL scheme that normalizes advantages across paired real/counterfactual samples for balanced optimization. "we propose DualityâNormalized Advantage Training (DNAâTrain), a two-stage SFT-RL training regime where the RL phase applies pairâwise advantage normalization"
- DualityForge: The proposed data synthesis pipeline that performs controllable, diffusion-based edits and generates grounded QA. "we introduce a novel data synthesis framework DualityForge that leverages controllable video editing~\cite{liu2025step1x, mao2025omni}, powered by diffusion models~\cite{ho2020denoising,song2020denoising}"
- entropy collapse: A failure mode in RL where the policy becomes overly deterministic too quickly, reducing exploration and diversity. "have shown promise but often suffer from instability and entropy collapse on complex, long-chain-of-thought tasks"
- FLUX-Kontext: A video editing tool/model used to create commonsense-violating frame edits. "FLUX-Kontext edits frames"
- greedy decoding: A deterministic decoding strategy selecting the highest-probability token at each step. "For evaluation, we use greedy decoding (temperature=$0$) to ensure deterministic outputs."
- GRPO (Group Relative Policy Optimization): A policy optimization algorithm variant used in RL for language/vision models. "algorithms like GRPO~\cite{shao2024deepseekmath} have shown promise"
- language priors: Statistical regularities learned from text that models may over-rely on, ignoring visual evidence. "an over-reliance on language priors, which can lead to ``visual ungrounded hallucinations''"
- L1 (ℓ1) advantage normalization: Scaling advantages by their ℓ1 magnitude to balance learning signals across groups (e.g., real vs. counterfactual). "the RL phase applies pairâwise advantage normalization, thereby enabling a more stable and efficient policy optimization."
- logits: The raw, pre-softmax outputs of a model used to compute probabilities. "contrasting the original logits with an auxiliary distribution"
- Monte Carlo Tree Search: A heuristic search algorithm using randomized simulations, here used to mine hard cases in RL training. "ThinkLiteVL~\citep{wang2025sota} mines hard cases through Monte Carlo Tree Search;"
- OpenCV: An open-source computer vision library used for pixel-level video editing. "Visual Anomaly: pixel-level video editing via OpenCV"
- oracle caption: A description treated as ground-truth guidance generated with access to embedded context. "enabling an MLLM to first generate an ``oracle'' caption"
- pairwise accuracy: An evaluation metric requiring correct answers on both elements of a paired sample to count as correct. "we employ a stricter pairwise accuracy, where a sample is only counted if the model correctly answers for both the original and edited videos."
- policy optimization: The process of adjusting a policy’s parameters to maximize expected reward in RL. "thereby enabling a more stable and efficient policy optimization."
- Reinforcement Learning (RL): A learning paradigm where agents learn by receiving rewards or penalties for actions. "a two-stage SFT-RL training regime where the RL phase applies pairâwise advantage normalization"
- Reinforcement Learning with Verifiable Rewards (RLVR): An RL setup using deterministic, programmatic reward signals that can be verified. "the Reinforcement Learning with Verifiable Rewards (RLVR) paradigm~\cite{guo2025deepseek,team2025kimi}"
- semantic anomaly: Object/scene-level inconsistencies introduced via editing (e.g., disappearance, substitution). "Semantic Anomaly: an MLLM selects an object for editing, followed by mask generation, VACE-based editing"
- SFT (Supervised Fine-Tuning): Post-pretraining supervised training on curated instruction/QA data to specialize a model. "Our training begins with a supervised fine-tuning (SFT) stage on DualityVidQA-SFT."
- temporal localization: Identifying the time segments in a video where specific events occur. "across tasks such as action recognition, temporal localization, retrieval, and question answering."
- token-level advantages: Advantage values computed per generated token to weight policy gradients at each timestep. "where is the average of token-level advantages."
- VACE: A video editing model/framework used to perform semantic-level content edits and interpolation. "VACE-based editing"
- visual anomaly: Low-level pixel distortions affecting visual quality without changing semantics. "Visual Anomaly: pixel-level video editing via OpenCV"
- visual ungrounded hallucinations: Outputs that are linguistically plausible but inconsistent with the actual visual content. "an over-reliance on language priors, which can lead to ``visual ungrounded hallucinations''"
Collections
Sign up for free to add this paper to one or more collections.

