Bellman Calibration for V-Learning in Offline Reinforcement Learning
Published 29 Dec 2025 in stat.ML, cs.LG, and econ.EM | (2512.23694v1)
Abstract: We introduce Iterated Bellman Calibration, a simple, model-agnostic, post-hoc procedure for calibrating off-policy value predictions in infinite-horizon Markov decision processes. Bellman calibration requires that states with similar predicted long-term returns exhibit one-step returns consistent with the Bellman equation under the target policy. We adapt classical histogram and isotonic calibration to the dynamic, counterfactual setting by repeatedly regressing fitted Bellman targets onto a model's predictions, using a doubly robust pseudo-outcome to handle off-policy data. This yields a one-dimensional fitted value iteration scheme that can be applied to any value estimator. Our analysis provides finite-sample guarantees for both calibration and prediction under weak assumptions, and critically, without requiring Bellman completeness or realizability.
The paper introduces Bellman calibration algorithms for offline RL that adjust value function estimators using post-hoc one-dimensional regressions.
The methodology employs histogram binning and isotonic regression to achieve finite-sample error guarantees and reduce off-policy bias.
Empirical results show up to 10–15% RMSE reduction in value estimation, emphasizing practical benefits in undertrained or misspecified regimes.
Bellman Calibration for Value Function Learning in Offline RL
Motivation and Problem Formulation
Offline reinforcement learning (RL) necessitates accurate estimation of state-value functions under a target policy using data previously collected by a potentially different behavior policy. Conventional estimators—including fitted value iteration, Q-iteration, neural networks, and gradient-boosted regressors—are susceptible to systematic biases: overestimation, instability, and off-policy error accumulation. Such misspecification, especially in the offline setting, undermines both uncertainty quantification and the reliability of counterfactual reasoning in RL deployments.
This paper introduces a formal notion and set of algorithms for calibrating value-function estimators in infinite-horizon MDPs, based on what the authors term Bellman calibration. The essential criterion is that for any two states s1 and s2 with similar predicted values v^(s1)≈v^(s2), the actual one-step return plus continuation value should statistically obey the Bellman equation under the target policy (i.e., the continuation reward, not just the immediate reward), conditional on the value prediction. The authors propose post-hoc, model-agnostic calibration algorithms—iterated histogram and isotonic regression on doubly robust Bellman pseudo-outcomes—that can be retrofitted atop any fitted value estimator. They supply finite-sample guarantees for both calibration and prediction and, crucially, do not require Bellman completeness or realizability.
Bellman Calibration: Notions and Targets
Let v^ denote an estimated value function for policy evaluation, and v0 the true value function under π. The Bellman calibration map Γ0(v^)(s), central to the method, is defined as the conditional expectation of the "Bellman target" given the predicted value: Γ0(v^)(s)=Eπ[R+γv^(S′)∣v^(S)=v^(s)]
Perfect Bellman calibration is achieved when v^(s)=Γ0(v^)(s) for all s; the mean one-step Bellman update matches the model prediction conditioned upon the predicted value. More stringent "strong" calibration would require calibration with respect to the true value function, which the authors correctly argue is unattainable without further estimation of occupancy ratios or Q-functions. The focus is on this weaker, but operationally meaningful, form.
The practical calibration error, which the algorithms aim to minimize, is
Calℓ2(v^)=∥v^−Γ0(v^)∥L2(ρ)
where ρ is typically the data-generating distribution.
Iterated Bellman Calibration Algorithms
The algorithms operate via iterative one-dimensional regressions. For a given estimator v^, initially learned fully out-of-sample, a calibration dataset is used to construct pseudo-outcomes based on a doubly robust (DR) Bellman target: (πq^v)(S)+w^π(A∣S)[R+γv(S′)−q^v(S,A)]
with w^π, q^v, r^, P^ suitably estimated, and doubly robustness ensuring unbiasedness if either set of nuisance estimators is accurate.
At each iteration, the current value predictor is regressed onto the DR Bellman targets using a low-complexity calibrator function θ∈F. This produces a new predictor of the form v^(k+1)=θn(k+1)∘v^. The procedure is repeated K times, with K logarithmic in n. The primary choices for F are:
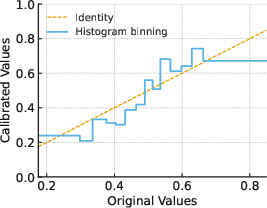
Piecewise constant (histogram binning): divides predictions into B bins and regresses within-bin means.
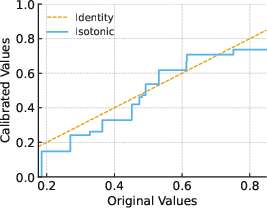
Monotonic functions (isotonic regression): adapts bin structure to the monotonic relationship between prediction and the DR target.
Hybrid approach: initial isotonic step to induce an adaptive partition, then fixed-bin histogram calibration.
Figure 1: Illustration of piecewise-constant Bellman calibration maps via histogram binning (left) and isotonic regression (right), mapping predictions to calibrated values.
Both the histogram and isotonic approaches admit efficient, stable, 1D implementations and avoid the computation and sample complexity challenges of adversarial dual or min-max RL algorithms.
Theoretical Guarantees
The authors provide detailed finite-sample guarantees on the calibration and prediction errors under mild regularity assumptions (boundedness, sample-splitting/cross-fitting). Bellman completeness is not required—even with severe function class misspecification, calibration can be achieved in the sense that for any value predictor v^, a calibrated, piecewise transformation of v^ can be obtained through these algorithms.
Calibration error decays at optimal rates:
Histogram binning: calibration error O(nBlogBn), with B≍n1/3 optimal for the minimax rate.
Estimation error for the calibrated value function enjoys the following properties:
It never exceeds that of the original value estimator. In certain regimes, the calibration step can strictly improve the estimation error.
The estimation error admits a decomposition into "refinement" (intrinsic informativeness of the base estimator v^ for v0 up to a monotone or piecewise transformation) and "calibration" (how well the calibrated estimator satisfies the Bellman calibration condition).
The hybrid (isotonic-histogram) algorithms combine the tuning-free adaptivity of isotonic regression with the stronger theoretical guarantee for estimation error previously available only for fixed-bin histogram binning.
Empirical Results
Experiments on a synthetic customer-relationship-management MDP demonstrate:
Substantial reduction in off-policy value estimation RMSE, especially for neural-network-based value estimators, with up to $10$--15% improvement after a single calibration step.
Improvement is most pronounced in undertrained or severely misspecified regimes and remains beneficial for well-trained models.
Isotonic calibration is robust and tuning-free, while the hybrid approach marginally outperforms in nearly all settings.
Importantly, the calibration procedure does not introduce estimation instability nor degrade performance of already well-calibrated predictors.
Practical Implications and Future Directions
The methodology applies post hoc atop any fitted value estimator—neural, linear, tree-based, or even ensemble methods. It is especially suitable for offline settings (model selection, policy evaluation, batch RL) where the risk of instability and misspecification is highest. The central computational step reduces to 1D regression with an easily visualized and interpretable fitted map.
A potential limitation is that calibration guarantees—both in term of calibration and estimation error—are distribution-dependent: calibration is measured in L2(ρ), and reduced overlap between behavior and target policies can amplify uncertainty in underrepresented domains. Thus, Bellman calibration, while mitigating bias and variance given support, is not a solution for distributional mismatch, which remains a core challenge in offline RL.
The proposed algorithms are adaptable to extension. Future research could target:
Calibration under reweighted or estimated stationary distributions to further align with the target policy’s support.
Incorporation of density-ratio or occupancy MLE corrections.
Extension to multi-dimensional value estimation (e.g., distributional RL, risk-sensitive objectives).
Theoretical analysis of end-to-end generalization in non-Markovian or partially observable settings.
Downstream integration in model selection, confidence interval estimation, and robust causal effect inference.
Conclusion
This paper establishes a rigorous framework for post-hoc Bellman calibration in value-function learning. The main contribution is a set of simple, computation- and assumption-light algorithms for calibrating off-policy value estimators, with strong finite-sample error guarantees holding without Bellman completeness or realizability. The methods are especially advantageous in offline RL and long-horizon sequential prediction problems where model misspecification is acute. By decoupling calibration from realization of the true value function and directly targeting distributionally appropriate one-step Bellman self-consistency, the algorithms provide a practical tool for robust, reliable value prediction and policy evaluation in the unstructured, high-stakes settings characteristic of modern RL.
“Emergent Mind helps me see which AI papers have caught fire online.”
Philip
Creator, AI Explained on YouTube
Sign up for free to explore the frontiers of research
Discover trending papers, chat with arXiv, and track the latest research shaping the future of science and technology.Discover trending papers, chat with arXiv, and more.