HY-Motion 1.0: Scaling Flow Matching Models for Text-To-Motion Generation
Abstract: We present HY-Motion 1.0, a series of state-of-the-art, large-scale, motion generation models capable of generating 3D human motions from textual descriptions. HY-Motion 1.0 represents the first successful attempt to scale up Diffusion Transformer (DiT)-based flow matching models to the billion-parameter scale within the motion generation domain, delivering instruction-following capabilities that significantly outperform current open-source benchmarks. Uniquely, we introduce a comprehensive, full-stage training paradigm -- including large-scale pretraining on over 3,000 hours of motion data, high-quality fine-tuning on 400 hours of curated data, and reinforcement learning from both human feedback and reward models -- to ensure precise alignment with the text instruction and high motion quality. This framework is supported by our meticulous data processing pipeline, which performs rigorous motion cleaning and captioning. Consequently, our model achieves the most extensive coverage, spanning over 200 motion categories across 6 major classes. We release HY-Motion 1.0 to the open-source community to foster future research and accelerate the transition of 3D human motion generation models towards commercial maturity.


Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What is this paper about?
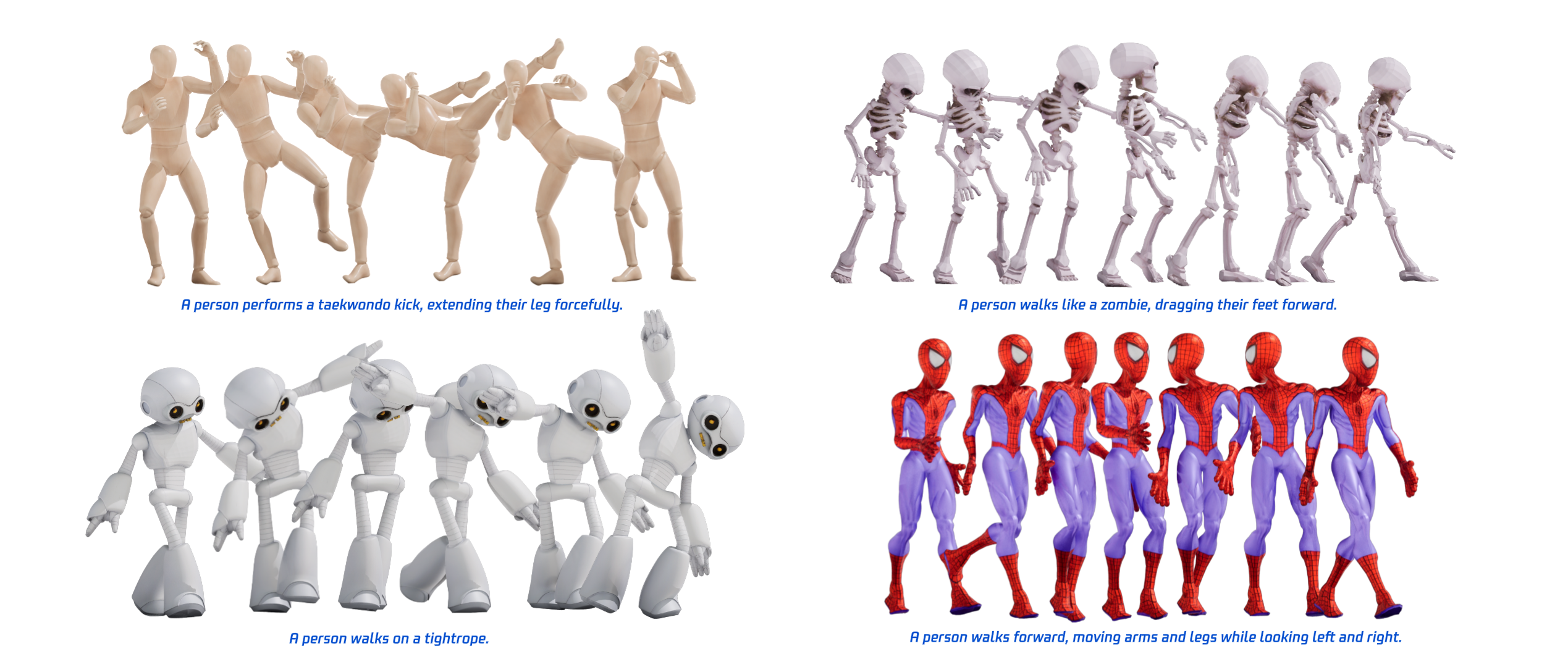
This paper introduces HY-Motion 1.0, a powerful AI system that can create 3D human animations just from text. For example, if you type “a person jogs, then waves their right hand,” the model generates a realistic 3D motion that matches that description. The team built very large models (up to over a billion parameters) and trained them on a huge, carefully prepared motion dataset so the animations look natural and follow instructions well.
What questions did the researchers ask?
The paper focuses on three simple questions:
- Can we make a text-to-motion model that understands complex instructions and follows them accurately?
- Can scaling up the model size and training data (like using a bigger brain and more examples) improve motion quality and instruction-following?
- What training steps and clean data are needed to get motions that look smooth, realistic, and match the text?
How did they build and train the system?
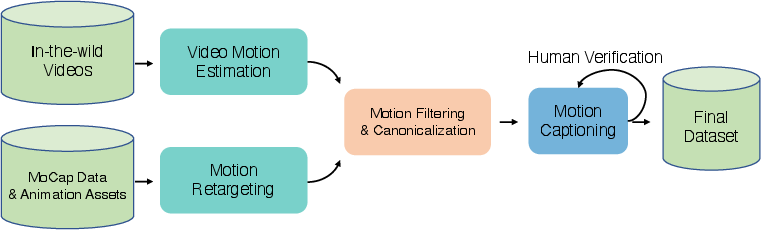
Building a giant motion dataset
Think of the model as a student learning to move like a human. The team gave it a huge “practice set”:
- Over 3,000 hours of motion data gathered from videos in the wild, professional motion capture, and game animation assets.
- A careful cleaning process removed bad clips (like weird poses, foot sliding, and duplicates).
- They converted all motions to the same standard digital skeleton (called SMPL-H), so the model sees the same kind of joint positions and rotations every time.
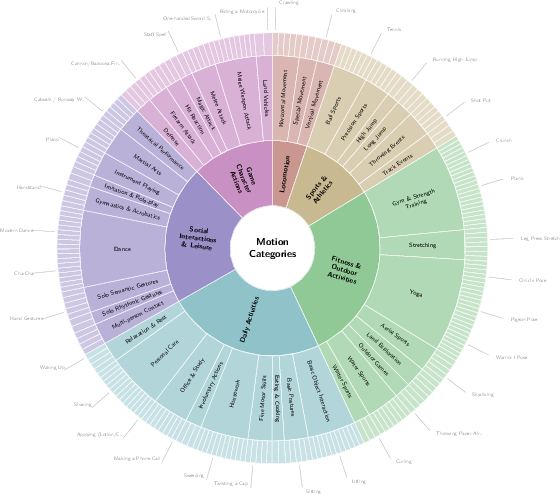
- They wrote or refined text captions for each motion using vision-LLMs and human checks, and organized the data into 6 big categories (like Locomotion and Sports) with 200+ specific action types.
How the model turns words into movement
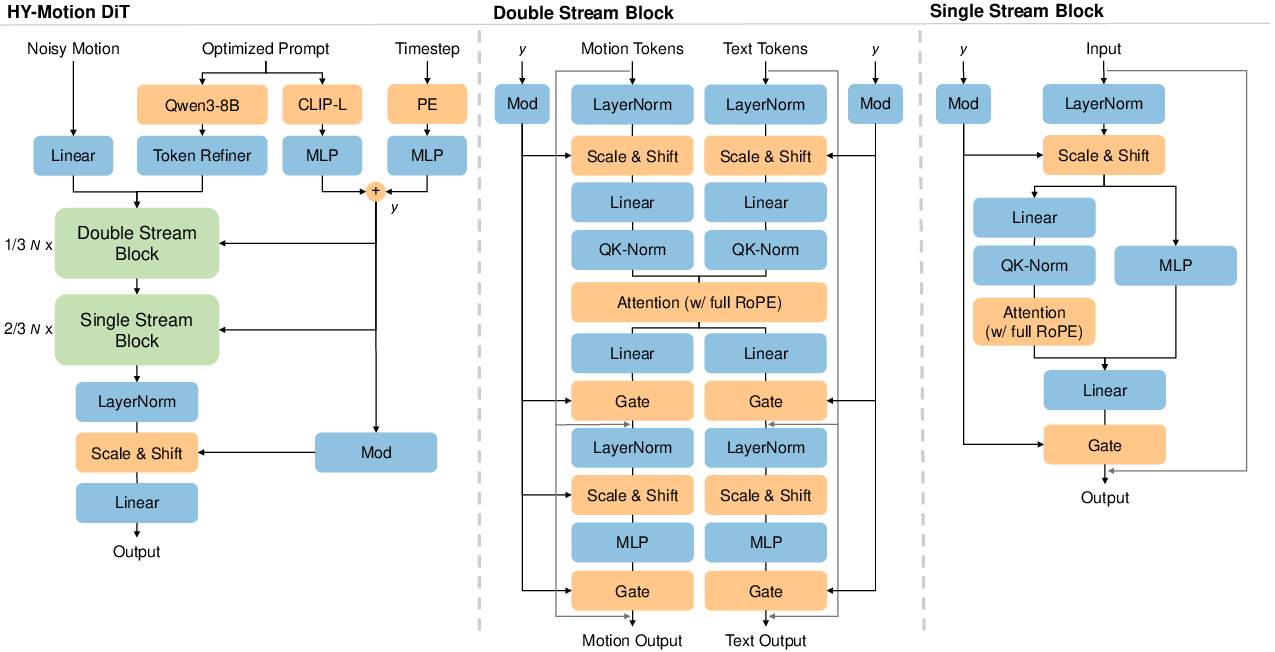
HY-Motion 1.0 uses a Diffusion Transformer with flow matching:
- Transformer: Imagine a team of smart readers that look at both the text and the motion frames, finding connections (like “kick” should match a leg lift at a certain time).
- Dual-stream to single-stream: At first, text and motion are processed separately but can “talk” to each other. Later, they’re combined into a single stream for deeper coordination.
- Attention masks: The model focuses on the most useful parts. For timing, it mainly looks at nearby frames so movements stay smooth. For text and motion, it lets the motion “listen” to the text, but blocks the reverse so noisy motion signals don’t mess up the text understanding.
- Positional encoding (RoPE): It keeps track of where each word and each frame is in sequence so the model knows “what happens when.”
- Flow matching: Instead of slowly removing noise step by step, the model learns the “velocity” (direction and speed) to move from random noise to a clean motion. Think of shaping a sculpture by learning exactly how to push the clay from a messy blob into a detailed pose over time.
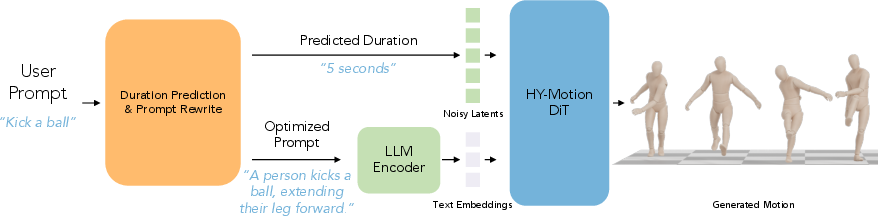
Helping the model understand time and clearer prompts
Sometimes people don’t say how long an action should be. The team trained another LLM to:
- Guess a reasonable duration from the prompt (e.g., a jump is short; a yoga sequence is longer).
- Rewrite messy or vague user prompts into clearer, structured instructions the motion model can follow better.
They first taught this helper model with labeled examples (supervised fine-tuning), then improved it using reinforcement learning, where a stronger judge model scores how well the rewritten text matches user intent and picks realistic durations.
Training in stages
To make the main motion model both smart and precise, they used three steps:
- Pretraining: Train on all 3,000+ hours to learn general human movement and broad text meanings.
- Fine-tuning: Focus on the highest-quality 400 hours to polish details—reduce jitter and foot sliding, and better follow fine-grained instructions (like “left hand” versus “right hand”).
- Reinforcement learning (RL): Go beyond just copying the dataset by using feedback to reward motions that people prefer and that obey physics. They use:
- Human preference learning (DPO): Human judges pick better motions over worse ones for the same prompt, and the model learns those preferences.
- GRPO for flow models: A reward function scores how well the motion matches the text (semantic) and how physically clean it is (no foot sliding or drifting). The model is nudged toward higher-reward behaviors.
What did they find?
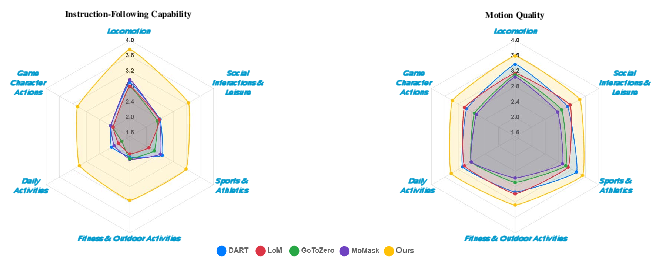
- Stronger instruction following: HY-Motion 1.0 understands and executes complex, multi-step prompts better than other open-source models (like MoMask, DART, LoM, and GoToZero).
- Higher motion quality: Motions look smoother, more stable, and more natural, with fewer artifacts (like foot sliding).
- Scaling matters: Bigger models and more diverse data improve understanding and following instructions. Quality improves a lot with fine-tuning on the clean 400-hour set and then reaches a stable level when models get very large.
- Automatic checks agree: Using a video-based evaluation (SSAE), the model scored notably higher, meaning its generated motions match written descriptions more often.
Why does it matter?
This research helps make 3D animation faster, cheaper, and more accessible:
- Creators in games, VR/AR, film, and social apps can type what they want and get usable animations without hiring large teams or using expensive motion capture.
- Robotics and digital humans can get more accurate, natural motions aligned with plain-language commands.
- The team is releasing HY-Motion 1.0 openly, which means others can build on it, test it, and speed up progress toward real-world products.
Limitations and future steps
Even with strong results, there are areas to improve:
- Very complex or super-detailed instructions can still be hard to follow perfectly, partly because writing flawless captions for tiny motion details is challenging.
- Human-object interactions (like picking up a tool with precise contact) are harder when the dataset doesn’t include detailed object geometry.
Overall, HY-Motion 1.0 shows that carefully scaling model size, data diversity, data quality, and smart training stages can make text-to-motion generation more accurate and realistic, bringing AI-created 3D human movement closer to everyday use.
Knowledge Gaps
Knowledge Gaps, Limitations, and Open Questions
Below is a single, concrete list of what remains missing, uncertain, or unexplored in the paper. Each point is phrased to be actionable for future research.
- Hand and facial modeling: The motion representation uses SMPL-H “22 joints without hands,” excluding fingers and face. How to extend HY-Motion to full-body motions with articulated hands, finger contacts, and facial expressions for gestures and fine manipulation?
- Human–object interaction (HOI): The dataset and model do not include explicit object geometry or contact annotations, limiting physically accurate interactions (e.g., grasping tools, ball handling). What data and modeling are needed to incorporate object meshes, contact points, and force/torque constraints?
- Multi-agent interactions: The architecture and data focus on single-person motions. How to support multi-character scenes (social interactions, competitive sports) with inter-agent kinematics, collision avoidance, and coordinated timing?
- Scene and terrain conditioning: Motions are canonicalized to a flat ground with origin-centered starts; no scene geometry or terrain variation is modeled. How to condition generation on 3D environments (obstacles, slopes, furniture) and enforce terrain-aware foot placement?
- Long-range temporal dependencies: Attention uses a narrow band local window (121 frames ≈ 4s at 30 fps), and training clips are ≤12s. What strategies (memory modules, hierarchical transformers, diffusion schedulers) enable coherent very-long sequences, multi-step activities, and plans beyond these temporal limits?
- Duration predictor generalization: The duration/prompt-rewrite LLM is trained on synthetic “user prompts.” How well does it generalize to real user inputs, diverse languages, and colloquial/ambiguous phrasing? Provide quantitative evaluations on non-synthetic, user-sourced prompts.
- Caption accuracy and coverage: Large portions of the 3,000h dataset rely on VLM-generated captions without full manual verification. What is the caption error rate across categories, and how can iterative human-in-the-loop correction or structured templates reduce misalignment?
- Dataset composition and bias: The paper does not detail category distributions, demographic coverage, body shape variability, or cultural motion diversity. Audit and report dataset biases (e.g., indoor vs. outdoor, sports vs. daily activities) and study their impact on model behavior.
- Retargeting fidelity: All motions are retargeted to SMPL-H via mesh fitting or skeletal mapping. Quantify retargeting errors (e.g., joint-angle residuals, contact drift) and their effect on downstream training; compare alternative retargeters and calibration procedures.
- Physical plausibility metrics: Beyond human ratings and a foot sliding/root drift penalty, standardized physical metrics (contact consistency, joint torque/jerk limits, momentum conservation, ground reaction plausibility) are not reported. Develop and adopt physics-based benchmarks.
- Reward model transparency and reliability: The TMR-based semantic reward and physical reward are central to RL but insufficiently specified (training data, architectures, validation). Provide details and assess robustness, domain transfer, and susceptibility to reward hacking.
- RL stability and side effects: DPO and Flow-GRPO may introduce distributional shifts or mode collapse. Analyze training stability, catastrophic forgetting of diversity, and trade-offs between instruction adherence and motion naturalness; publish diagnostics and hyperparameters.
- Scaling law quantification: Claims of “first to scale DiT to 1B for motion” and benefits from scale are shown qualitatively. Provide formal scaling laws (performance vs. parameters/data), confidence intervals, and compute/energy costs to guide efficient scaling.
- Generalization across languages: While English/Chinese prompts are mentioned, multilingual capabilities (tokenization, semantics, morphology) are not evaluated. Test and improve cross-lingual instruction following, including low-resource languages.
- Prompt-structure dependence: The Bidirectional Token Refiner and dual-conditioning (Qwen + CLIP) design choices lack ablations. Quantify the contribution of each text component, refiner, and attention mask asymmetry; explore symmetric cross-attention or gated fusion.
- Flow matching design choices: The linear optimal transport path and simple Euler ODE solver are used without comparison. Evaluate rectified flows, stochastic interpolants, higher-order solvers, and step schedules for sample quality vs. latency trade-offs.
- Explicit contact/velocity modeling: Velocities and foot-contact labels were removed for faster convergence. Investigate reintroducing explicit contact/velocity features or auxiliary losses to improve physical realism and contact stability.
- Control and conditioning beyond text: The model supports only textual prompts and inferred durations. Add controls for style, identity, tempo, path following, and kinematic constraints; study multi-modal conditioning (audio, music, sketches) and camera trajectory control.
- Benchmarking on standard datasets: Comparisons use a custom prompt set and SSAE with a video-VLM. Report performance on common benchmarks (e.g., HumanML3D, KIT-ML), with standardized metrics, to enable fair cross-paper comparisons.
- Evaluation rigor: Human ratings lack inter-rater reliability (e.g., Cohen’s kappa), confidence intervals, and statistical tests. Include rater agreements, sample sizes per category, and significance analyses.
- SSAE validity for 3D motion: SSAE leverages 2D video-VLM QA on rendered motion clips. Validate whether SSAE captures 3D kinematics and contacts; compare against 3D-aware evaluators and motion-text retrieval metrics.
- Inference speed and deployment: ODE-based generation latency, memory footprint, and real-time viability are not reported. Characterize hardware requirements, batch sizes, and throughput; optimize with distillation or consistency models.
- Safety and content constraints: No discussion of preventing unsafe or harmful motions (e.g., injury-prone actions), age/body-type adaptations, or ethical safeguards. Define safety policies and integrate constraint-aware generation.
- Reproducibility with open tools: Key components rely on proprietary models (Gemini-2.5-Pro, large Qwen variants). Provide open-source substitutes, reproducible pipelines, and instructions to replicate results without closed APIs.
- Data availability and licensing: The paper does not state whether the curated dataset (or subsets) will be released, nor its licensing and consent for in-the-wild videos. Clarify data sharing, permissions, and privacy protections; consider releasing high-quality, audited subsets.
Glossary
- AdaLN: Adaptive layer normalization used to modulate network features with conditioning signals. "via a separated AdaLN~\citep{Peebles2023} mechanism"
- Asymmetric attention mask: An attention scheme where one modality can attend to another but not vice versa, controlling cross-modal information flow. "we enforce an asymmetric attention mask."
- Bidirectional Token Refiner: A module that converts causal LLM features into bidirectional representations for non-autoregressive conditioning. "by adopting a Bidirectional Token Refiner."
- Canonical coordinate frame: A standardized spatial reference system to align all motions consistently. "Each motion was normalized to a canonical coordinate frame: Y-axis up, the starting position centered at the origin, the lowest body point aligned on the ground plane, and initial facing direction along the positive Z-axis."
- Canonicalization: The process of transforming data into a normalized, consistent format for downstream use. "After filtering, we applied canonicalization to standardize the data."
- CLIP-L: A large CLIP variant used to obtain global text embeddings for conditioning. "we utilize CLIP-L~\citep{Radford2021} to extract a global text embedding."
- Causal attention: Attention that restricts tokens to attend only to past tokens, typical of autoregressive LLMs. "LLMs typically utilize causal attention"
- Continuous 6D representation: A rotation encoding using 6D vectors to avoid discontinuities and singularities. "All rotational parameters adhere to the continuous 6D representation~\citep{Zhou2019}."
- Direct Preference Optimization (DPO): A method to train from human preference pairs by maximizing a likelihood margin. "we leverage Direct Preference Optimization (DPO)~\citep{Rafailov2023}"
- Diffusion Transformer (DiT): A Transformer backbone tailored for diffusion-based generative modeling. "scale a Diffusion Transformer (DiT)-based architecture"
- Dual-stream blocks: Transformer blocks that process motion and text tokens in separate streams before fusion. "The network begins with dual-stream blocks"
- Euler (ODE solver): A simple numerical integration method used to solve the generation ODE. "using an ODE solver (e.g, Euler)."
- Flow Matching: A training objective that learns a velocity field to transport noise to data distributions. "We employ Flow Matching~\citep{Lipman2022}"
- Flow-GRPO: A GRPO variant designed for flow matching models to optimize explicit rewards. "We employ Flow-GRPO~\citep{Liu2025}"
- Foot-sliding: An animation artifact where feet slide across the ground during supposed contact. "detection of artifacts such as foot-sliding."
- GVHMR: A state-of-the-art method for reconstructing 3D human motion from video. "a state-of-the-art human motion extraction algorithm GVHMR~\citep{shen2024gvhmr},"
- Group Relative Policy Optimization (GRPO): An RL algorithm that normalizes advantages across groups of samples for stable training. "Group Relative Policy Optimization (GRPO)~\citep{Shao2024}"
- Human detector: An algorithm to identify human presence in video clips. "and a human detector to search for clips containing human subjects."
- HumanML3D: A commonly used representation/dataset for text-conditioned human motion. "which differs from the commonly used HumanML3D~\citep{Guo2022} representation."
- HunyuanVideo: A large-scale source of in-the-wild videos used for motion extraction. "from HunyuanVideo~\citep{hunyuanvideo2025}."
- Joint attention mechanism: Cross-modal attention enabling motion features to query text semantics while keeping modality-specific representations. "interact through a joint attention mechanism"
- Mesh fitting: Optimization to fit a mesh/skeleton to motion data for unified representation. "we employed mesh fitting to convert them into the unified SMPL-H representation."
- Narrow band mask strategy: Restricting temporal attention to a local window to model kinematic continuity efficiently. "we implement a narrow band mask strategy."
- Optimal transport path: A linear interpolation path between noise and data used in flow matching. "We adopt the optimal transport path"
- Ordinary Differential Equation (ODE): Continuous formulation of the generation trajectory driven by the learned velocity field. "formulated as an Ordinary Differential Equation (ODE)"
- Parallel spatial and channel attention: Attention modules operating across token positions and feature channels in parallel. "we employ parallel spatial and channel attention modules"
- QKV projections: Query-Key-Value linear projections used in Transformer attention mechanisms. "via independent QKV projections"
- Qwen3-235B-A22B-Instruct-2507: A large instruction-tuned LLM used as a reward judge for RL. "Qwen3-235B-A22B-Instruct-2507~\citep{Yang2025}"
- Qwen3-30B-A3B: A 30B-parameter LLM variant used to fine-tune duration prediction and prompt rewriting. "Qwen3-30B-A3B~\citep{Yang2025}"
- Qwen3-8B: An 8B-parameter LLM used to extract token-wise semantic embeddings. "Qwen3-8B~\citep{Yang2025}"
- Retargeting tool: Software that maps motion from arbitrary skeletal formats to a target skeleton. "we applied a retargeting tool to map them to the SMPL-H skeleton."
- Root drift: Undesired global motion of the character’s root over time. "artifacts such as foot sliding and root drift."
- Rotary Positional Embeddings (RoPE): Positional encoding that facilitates relative position modeling in attention. "full Rotary Positional Embeddings (RoPE) \cite{su2024roformer}"
- Shot boundary detection: Automatic segmentation of videos into coherent scenes by detecting cuts. "employing shot boundary detection to segment videos into coherent scenes"
- SMPL: A parametric 3D human body model used as a motion/shape reference. "in SMPL~\citep{smpl}"
- SMPL-H: A SMPL variant with hand articulation used as the unified target skeleton. "SMPL-H skeleton"
- SMPL-X: A SMPL variant modeling expressive body including hands and face. "SMPL-X~\citep{smplx} parameters."
- Structured Semantic Alignment Evaluation (SSAE): An automatic VLM-based method to evaluate text-motion alignment. "Structured Semantic Alignment Evaluation (SSAE) \cite{cao2025hunyuanimage}"
- Text-Motion Retrieval (TMR): A model that scores semantic alignment between text prompts and generated motion. "Text-Motion Retrieval (TMR) model"
- Vision-LLMs (VLMs): Models that jointly process visual and textual inputs for tasks like captioning or QA. "vision-LLMs (VLMs)"
Practical Applications
Immediate Applications
Below are concrete use cases that can be deployed now, leveraging the released HY-Motion 1.0 models, the data curation pipeline, and the LLM-based duration/prompt module.
- Text-to-motion copilot for 3D content tools
- Sectors: media/entertainment, software
- What it enables: Natural-language “prompt to animation” for blocking, previz, and iterative refinement inside DCCs and game engines.
- Potential tools/products/workflows: Plugins for Maya/Blender/Unreal/Unity; “Prompt-to-Anim” palette with the duration predictor; retargeting to UE Mannequin, Mixamo, Character Creator rigs; batch generation with auto-SSAE checks.
- Assumptions/dependencies: SMPL-H-to-rig retargeting bridge; sufficient GPU for 1B-parameter inference or use of the 0.46B “Lite” model; licensing alignment for commercial use; artists still perform style polishing.
- Rapid NPC animation library generation and prototyping
- Sectors: games, interactive media
- What it enables: Automated creation of diverse motion sets (walks, idles, emotes, combat, sports, social) from text, accelerating blend tree/state machine authoring.
- Potential tools/products/workflows: Offline batch generation; motion tagging via taxonomy; SSAE-based compliance gates; integration with behavior trees (text → actions → animations).
- Assumptions/dependencies: Quality acceptance criteria per studio; retargeting to in-game skeletons; style-transfer layers for art direction; QA on edge cases (terrain/props).
- Virtual production and previsualization accelerator
- Sectors: film/TV, advertising, virtual production
- What it enables: Fast motion blocking from shot lists; director-friendly prompt iteration; duration-aware sequences for storyboards/animatics.
- Potential tools/products/workflows: Shot generator that consumes script snippets to produce staged e-mocap; LLM rewriting to canonical prompts; SSAE for “spec-matching” of action lists.
- Assumptions/dependencies: Pipeline integration with existing layout/previz tools; compute scheduling for multi-shot batches.
- VTubers, livestream avatars, and social platforms
- Sectors: creator economy, social media
- What it enables: Pre-generated gesture loops and ambient motions; low-latency playback pipelines; on-the-fly prompt-to-clip for scene transitions.
- Potential tools/products/workflows: “Motion packs” for stream overlays; Lite model for near-real-time requests with cached results; retargeting to stylized avatars.
- Assumptions/dependencies: No explicit hand modeling (22 joints without hands); real-time performance depends on hardware and sample steps; community guidelines for motion content.
- Fitness and how-to animation libraries (instructional content)
- Sectors: education, consumer apps, wellness
- What it enables: 3D instructor motions for exercises and daily-activity demos from text; multilingual prompt authoring via the LLM module.
- Potential tools/products/workflows: Exercise packs for apps; LMS integration; duration prediction to match lesson pacing.
- Assumptions/dependencies: Not a medical device; limited HOI and equipment contact realism; legal disclaimers; motion quality review for safety clarity.
- E-commerce mannequin motion and product showcasing
- Sectors: retail/e-commerce
- What it enables: Pose/motion sequences that demonstrate garment behavior (walking, sitting, stretching) for product pages.
- Potential tools/products/workflows: “Motion storyboard” generator for SKU pages; automatic prompt templating per product category.
- Assumptions/dependencies: Requires separate cloth simulation; limited object/prop interactions; brand style controls needed.
- Synthetic data generation for research and model training
- Sectors: academia, robotics (simulation), computer vision
- What it enables: Large-scale text-labeled motion data to train/evaluate retrieval, captioning, segmentation, and downstream multimodal models.
- Potential tools/products/workflows: Scripted prompt sweeps over 200+ categories; curriculum datasets; evaluation splits standardized by the taxonomy.
- Assumptions/dependencies: Manage domain shift to real capture; adhere to open-source license; acknowledge VLM caption noise where present.
- Automatic motion QA with SSAE as a CI step
- Sectors: software, media/entertainment
- What it enables: Automated pass/fail checks on text–motion alignment using VLM-based question answering; spec-driven validation.
- Potential tools/products/workflows: CI pipeline “SSAE grader” for animation drops; dashboards showing alignment metrics by category.
- Assumptions/dependencies: Access to reliable video-VLM APIs (cost, latency); periodic human audits to monitor VLM drift.
- Domain-specific tuning via RL from preference data
- Sectors: studios, enterprise content, branded IP
- What it enables: Style-constrained motion generators (e.g., brand-safe gestures, genre-specific locomotion) using in-house preference labels and reward models.
- Potential tools/products/workflows: Preference labeling UI; Flow-GRPO scripts; brand-instruction evaluators; style libraries.
- Assumptions/dependencies: Human annotation capacity; reward model calibration; governance on what preferences are encoded.
- Data curation, cleaning, and captioning as a service
- Sectors: data providers, research labs, studios
- What it enables: Reuse of the motion cleaning (dedup, velocity/foot-slip filters, canonicalization) and VLM+human captioning pipeline for bespoke datasets.
- Potential tools/products/workflows: Turnkey “motion refinery” service; taxonomy tagging; multilingual caption standardization.
- Assumptions/dependencies: VLM access and QA budget; alignment to internal skeleton standards (SMPL-H conversion/retarget).
- Duration-aware authoring assistance
- Sectors: media/entertainment, education, software
- What it enables: Automatic duration estimation and prompt rewriting to reduce ambiguous requests and ensure timeline-fit for scenes/lessons.
- Potential tools/products/workflows: “Prompt Doctor” panel in DCCs/engines; batch normalization of content briefs; timeline sync.
- Assumptions/dependencies: LLM license for Qwen or equivalents; protected inference endpoints; occasional human override.
- Policy and operations: content governance templates
- Sectors: policy/compliance, platform operations
- What it enables: Use the taxonomy to define prohibited/risky motion classes; embed SSAE checks to flag policy violations (e.g., unsafe stunt replication).
- Potential tools/products/workflows: Rule-based filters using category tags; periodic audits with human review; incident response playbooks.
- Assumptions/dependencies: Organization-specific standards; evolving regulatory guidance; human-in-the-loop oversight.
Long-Term Applications
The following applications require further research or engineering, including HOI modeling, real-time constraints, broader datasets, or cross-modal integration.
- Human–object interaction (HOI) and tool use
- Sectors: media/entertainment, industrial training, e-commerce
- What it enables: Physically accurate contact, grasping, and manipulation (e.g., instruments, tools, sports equipment).
- Needed advances: Object-aware datasets with geometry/contacts, physics-informed training, contact-consistent reward models.
- Assumptions/dependencies: New data collection and simulators; updated motion representation with hands and object states.
- Real-time, on-device motion generation for AR/VR
- Sectors: XR, mobile computing
- What it enables: On-headset prompt-to-motion for in-situ authoring and telepresence with low latency.
- Needed advances: Model distillation/quantization, efficient ODE solvers or learned samplers, caching and streaming.
- Assumptions/dependencies: Hardware acceleration; acceptable quality trade-offs with the “Lite” model or future compact variants.
- Robotics: from human motion priors to robot policies
- Sectors: robotics, manufacturing, service robots
- What it enables: Use synthetic human motions as priors for humanoid skills and imitation learning; text-conditioned policy libraries.
- Needed advances: Retargeting to robot kinematics, dynamics-feasible trajectory generation, sim-to-real transfer with constraints.
- Assumptions/dependencies: Accurate contacts and balance; environment models; safety validation.
- Clinical rehab and coaching with personalized guidance
- Sectors: healthcare, sports science
- What it enables: Tailored target motions and progressions from clinician-written instructions; patient-specific variations.
- Needed advances: Outcome-validated datasets, personalization models, biomechanical constraints, regulatory compliance (e.g., SaMD).
- Assumptions/dependencies: Clinical trials; integration with capture/feedback sensors; liability and safety frameworks.
- Co-speech gesture and affective digital humans
- Sectors: customer service, education, enterprise assistants
- What it enables: End-to-end speech→text→gesture pipelines with emotion/intonation alignment.
- Needed advances: Hand/finger modeling, audio-conditioned motion, style/identity control, multi-turn dialogue grounding.
- Assumptions/dependencies: Expanded datasets (hands/face); latency management for live interactions.
- Autonomous character agents in open-world environments
- Sectors: games, simulation, film
- What it enables: LLM planning → HY-Motion execution → environment-aware adaptation with collision/contact handling.
- Needed advances: Scene understanding, multi-agent coordination, closed-loop control with physics and navigation.
- Assumptions/dependencies: HOI, terrain/obstacle awareness, online replanning.
- Crowd simulation from narrative scripts
- Sectors: urban planning, film/VFX, safety drills
- What it enables: Multi-actor, semantically synchronized crowds from textual scenarios (e.g., evacuations, festivals).
- Needed advances: Multi-agent text-to-motion with inter-person constraints; scalability and diversity control.
- Assumptions/dependencies: Performance optimizations; group-level reward functions; evaluation protocols.
- Provenance, watermarking, and motion IP standards
- Sectors: policy/governance, rights management
- What it enables: Traceable synthetic motion assets, dataset consent tracking, fair-use frameworks for training on human videos.
- Needed advances: Robust motion watermarking/fingerprinting; standardized metadata schemas; cross-industry governance.
- Assumptions/dependencies: Multi-stakeholder consensus; alignment with regional regulations.
- Educational “embodied tutoring” with corrective feedback
- Sectors: education, professional training
- What it enables: Tutors that demonstrate and assess motions (e.g., lab safety, sports drills), offering corrections from text rubrics.
- Needed advances: Reliable pose estimation of learners, error diagnosis models, pedagogical reward shaping.
- Assumptions/dependencies: Privacy-preserving analytics; fairness checks across demographics.
- Energy-efficient inference and hardware co-design
- Sectors: semiconductor, edge computing, XR
- What it enables: Specialized accelerators and kernels tailored to flow matching and hybrid attention for motion.
- Needed advances: Kernel fusion, sparsity, low-bit quantization; algorithm–hardware co-optimization.
- Assumptions/dependencies: Vendor support; standardized benchmarks for motion generation.
- Safety-by-design frameworks for synthetic motion platforms
- Sectors: policy/compliance, platforms
- What it enables: Risk assessment, age-appropriateness filters, and incident handling for generated motions (e.g., dangerous stunts).
- Needed advances: Policy taxonomies linked to motion categories; automated detection of hazardous biomechanics.
- Assumptions/dependencies: Cross-disciplinary input (legal, ergonomics, biomechanics); periodic audits.
General assumptions and dependencies that affect feasibility
- Compute and latency: The 1B-parameter model is high-quality but compute-intensive; the 0.46B “Lite” model can reduce latency with some quality trade-off. Inference speed depends on ODE step counts/samplers.
- Representation and retargeting: Outputs are SMPL-H (22 joints without hands). Production use requires robust retargeters to specific rigs and may need additional hand/face layers.
- Data and licensing: Ensure compliance with open-source licenses and any constraints on training data. For enterprise fine-tuning, establish internal data governance.
- Evaluation reliability: SSAE relies on external video-VLMs that may drift or have biases; keep human-in-the-loop reviews.
- Limitations to note: Complex, highly detailed instructions and precise human–object interactions remain challenging; expect manual cleanup or hybrid pipelines for critical shots.
Collections
Sign up for free to add this paper to one or more collections.