Dynamic Subspace Composition: Efficient Adaptation via Contractive Basis Expansion
Abstract: Mixture of Experts (MoE) models scale capacity but often suffer from representation collapse and gradient instability. We propose Dynamic Subspace Composition (DSC), a framework that approximates context-dependent weights via a state-dependent, sparse expansion of a shared basis bank. Formally, DSC models the weight update as a residual trajectory within a Star- Shaped Domain, employing a Magnitude-Gated Simplex Interpolation to ensure continuity at the identity. Unlike standard Mixture-of-LoRAs, which incurs O(M rd) parameter complexity by retrieving independent rank-r matrices, DSC constructs a compositional rank-K approximation from decoupled unit-norm basis vectors. This reduces parameter complexity to O(M d) and memory traffic to O(Kd), while Frame-Theoretic regularization and spectral constraints provide rigorous worst-case bounds on the dynamic update. The code is available at https://github. com/VladimerKhasia/DSC
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What is this paper about?
This paper introduces a new way to make big LLMs (like GPT-style models) smarter without making them slow. The idea is called Dynamic Subspace Composition (DSC). It’s a different take on “Mixture of Experts” (MoE), a method where a model picks a few “experts” to help with each input instead of using all of its parts every time. DSC tries to keep the benefits of MoE—high capacity and good accuracy—while cutting the memory and speed costs that often make MoE hard to run.
What questions did the researchers ask?
They asked:
- Can we get the power of MoE models without dragging around huge chunks of data from memory every time?
- Can we make the model’s “expert picking” more stable, so it doesn’t get stuck using only a few experts or make wild jumps when it’s unsure?
- Can we build complex, high-quality changes to the model’s behavior using many tiny, reusable building blocks instead of big, heavy pieces?
How does their method work?
Think of the model as having a toolbox. Traditional MoE stores lots of full-size tools (big matrices). DSC instead stores a shared set of small, lightweight “tool parts” (vectors) and assembles the tools it needs on the fly.
Here’s the idea in everyday terms:
- Building blocks instead of big pieces:
- Traditional MoE (or Mixture-of-LoRA) often fetches full panels to rebuild a wall (large matrices). This is slow because pulling big panels from memory is expensive.
- DSC uses many slim sticks (rank-1 vectors) and composes them to build the same wall. Pulling thin sticks is faster and lighter on memory.
- Picking a few good parts:
- For each input (like a sentence), a router chooses the top K most helpful building blocks from a large shared bank.
- This keeps the compute “sparse,” meaning only a few parts are active each time.
- Direction vs magnitude (magnitude-gated simplex):
- The method separates “which direction to go” from “how far to go.”
- If the model isn’t confident, the “how far” part shrinks toward zero, so the update becomes tiny. This avoids sudden, noisy jumps when the router isn’t sure.
- Staying safe and stable (spectral bounds):
- Each tiny building block is normalized (kept within a safe size), and the combined update is capped by a scale. This helps prevent “blow-ups” in training where numbers get too big and unstable.
- Keeping the building blocks diverse (frame regularization):
- The paper encourages the building blocks to point in different directions rather than all being similar. It’s like arranging compass needles so they’re spread out evenly, giving broader coverage of possibilities.
- Preventing bad habits in routing:
- The router is given extra training nudges to:
- Balance load across choices (so it doesn’t overuse the same blocks),
- Keep the overall signal strong enough (so it doesn’t collapse to doing nothing),
- Avoid letting scores get too extreme (so it stays in a good learning zone).
In short: DSC picks a few small parts, decides how much to use them, assembles them into a custom “update” for that input, and makes sure the process is stable, efficient, and balanced.
What did they do to test it?
- Task: Language modeling on WikiText-103 (predicting the next word).
- Fair comparison: They matched the amount of “active compute” (roughly, how much the model actually uses per token) across models so results are about design, not just size.
- Compared three systems:
- A dense Transformer (no experts),
- A standard MoE layer (top-2 experts),
- DSC (their method) using many shared small vectors and selecting K=4 per input.
What did they find, and why is it important?
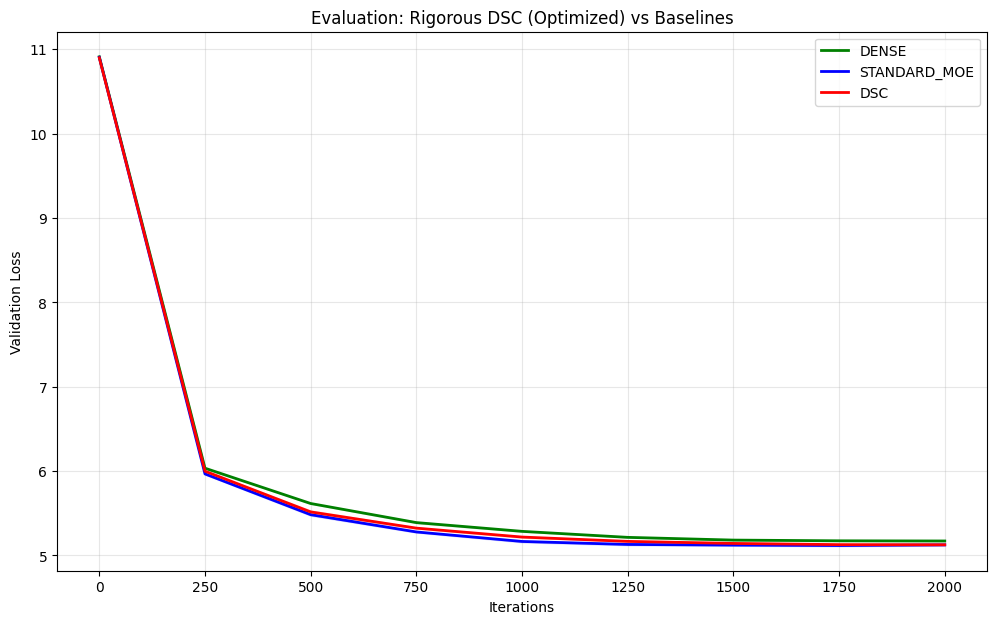
- Accuracy: DSC matched the standard MoE’s predictive performance (their validation losses were essentially the same).
- Speed: DSC was about 15% faster in inference than the standard MoE in their setup.
- Why this matters:
- MoE models can be fast in theory, but in practice they often wait on memory to load large expert matrices. DSC reduces this by fetching small vectors instead of big matrices.
- This makes it more practical to run powerful, sparse models on real hardware where memory bandwidth (not raw compute) is often the bottleneck.
What could this change in the future?
- Faster, cheaper large models: If you can build high-quality model updates from tiny, shared parts, you can keep the model agile without dragging memory down. That means faster responses and lower costs.
- More stable training: Because DSC carefully limits how big updates can get and shrinks them when the model is unsure, it can reduce the “jitter” and instability common in expert-based systems.
- Flexible scaling: DSC decouples “how expressive the update is” from “how much you need to store.” That makes it easier to scale up expressiveness without exploding memory usage.
Overall, DSC is like replacing bulky, specialized tools with a shared kit of lightweight pieces that can be quickly assembled. You get similar power, less memory traffic, and smoother behavior—promising steps toward faster and more efficient AI systems.
Knowledge Gaps
Knowledge Gaps, Limitations, and Open Questions
Below is a concise list of concrete gaps, limitations, and open questions that remain unresolved in the paper and can guide future research.
- Scalability to larger models and longer training: Results are limited to a small 6-layer model trained for only 2,000 steps on WikiText-103 with T=256. It is unknown how DSC behaves at larger scales (e.g., >1B parameters), longer schedules, or longer contexts.
- Generalization across tasks and modalities: The study focuses solely on causal language modeling. Performance on other NLP tasks (e.g., instruction tuning, reasoning, translation), as well as non-text modalities (vision, speech), is unexplored.
- Baseline coverage and fairness: There is no empirical comparison to Mixture-of-LoRAs (MoLoRA), LoRA, or other recent PEFT/MoE variants despite strong claims about MoLoRA’s suboptimality. The chosen MoE baseline (5 experts, top-2) may not reflect state-of-the-art configurations.
- Ablations on key DSC hyperparameters: No systematic ablations for , , routing clamp , magnitude gate parameters (e.g., ), channel scaling , or the balance of regularizers (). The sensitivity and optimal regimes are unknown.
- Expressivity and approximation guarantees: There is no theoretical or empirical bound on how well a -term sum of rank-1 atoms approximates the ideal update compared to rank- adapters or full experts. Conditions under which DSC matches MoE expressivity or when it degrades are not characterized.
- Unresolved Top-K discontinuity: Although “magnitude-gated simplex” aims at continuity at the identity, the Top-K selection remains discrete. The paper does not specify how gradients are handled (e.g., STE, relaxation) nor quantify the impact of switching sets on optimization stability.
- Load balancing and utilization metrics: The paper includes an auxiliary balancing loss but reports no diagnostics (e.g., utilization histograms, entropy of routing, fraction of experts used over time). Whether DSC avoids representation collapse in practice remains unverified.
- Router signal “budget” trade-offs: The proposed signal budget loss () to prevent and the logit range constraint () to avoid saturation lack empirical analysis. The risk of under-/over-activation and their impact on accuracy/latency are not quantified.
- Lipschitz bound tightness and practical effect: The spectral bounds are conservative (triangle inequality) and may be loose. It is unknown how these constraints affect optimization and generalization, or how to set/learn or to balance stability and capacity.
- Frame-theoretic regularization efficacy: While minimizing frame potential is motivated by ETF theory, the extent to which the learned bases approach an ETF, and how this correlates with task performance or spectral coverage, is not assessed.
- Complexity accounting omissions: Storage and traffic analyses ( storage, memory traffic) do not clearly account for both basis banks (; doubling parameters) and the router matrix (additional ). A full parameter/traffic budget and break-even analysis versus MoE/MoLoRA is missing.
- Compute vs bandwidth trade-offs: The factorized pipeline introduces additional compute (e.g., projections with , expansions with , all-to-all gathers). FLOPs and kernel-launch overheads versus MoE are not profiled or reported.
- Latency generality across hardware/settings: The reported ~15% latency reduction is on a single T4 with a specific batch/sequence length. No throughput (tokens/sec), memory footprint, or latency results across GPUs (A100/H100), CPUs, different batch sizes, , , or sequence lengths.
- Distributed and systems aspects: Behavior under tensor/model/sequence parallelism, sharded basis banks, cache locality, and communication overhead (e.g., multi-GPU all-gathers for active atoms) is untested.
- Placement within the Transformer: It is unclear in which layers/blocks DSC was applied (FFN only? attention projections? all layers?), and how layer placement affects accuracy, stability, and overhead.
- Stability and gradient diagnostics: Despite claims about spectral stability, there is no empirical analysis of gradient norms, training variance, or failure modes (e.g., exploding/vanishing gradients, router collapse) over longer horizons.
- Robustness and OOD behavior: While magnitude gating should suppress low-confidence updates, its effect on robustness (OOD inputs, adversarial perturbations) and potential under-adaptation is untested.
- Large- regime unverified: The paper claims DSC enables , but experiments use . Performance, stability, and latency for larger values are not evaluated.
- Interaction with normalization: The refined algorithm uses LayerNorm for routing normalization, but alternatives (RMSNorm, no norm) and their effects on routing quality and stability are not studied.
- Quantization and low precision: Compatibility with 8-bit/4-bit inference/training for and the effect on routing accuracy and speed are unknown.
- Alternative routing/relaxation schemes: The benefits and trade-offs of replacing Top-K with differentiable relaxations (e.g., Gumbel-Softmax, Sparsemax/Entmax, soft top-k) are not explored.
- Measuring expert overlap and redundancy: The degree to which different tokens use overlapping basis atoms, and whether redundancy builds up over training, has not been analyzed.
- Implementation detail gaps: Gradient handling through Gather/TopK, batching strategies, fusion opportunities, and memory coalescing are not specified; these could materially impact real-world speedups.
- Reporting reliability: Only two random seeds are used; there is no statistical testing (e.g., confidence intervals, significance tests). Reproducibility under different seeds and data orders is uncertain.
- Editorial/math clarity: Some equations have syntax/brace errors (e.g., normalization and projection definitions), and shapes/notations (, vs. ) are occasionally ambiguous. This impedes unambiguous reimplementation.
- Practical guidance for hyperparameters: There is no principled procedure to set , , , , or the regularization weights; automated tuning or heuristics are not provided.
- Cross-layer coordination: Whether to share basis banks across layers, maintain per-layer banks, or reuse atoms across modules is not addressed; the impact on parameter efficiency and interference remains unknown.
- Comparison to structured atoms: Potential benefits of structured atoms (e.g., convolutional, Toeplitz, butterfly) for better cache locality and expressivity at equal parameter counts are unexplored.
Practical Applications
Immediate Applications
The following items can be deployed now with moderate engineering effort, using the paper’s DSC layer, training objective, and routing strategy as described.
- Low-latency LLM serving on bandwidth-limited GPUs
- Sector: Software, Cloud/AI Infrastructure, Energy
- Action: Replace MoE or Mixture-of-LoRAs adapters in Transformer FFN blocks with the DSC layer (Algorithms 1–2), keeping the same active-parameter budget. Expect lower memory traffic by fetching vectors instead of matrices and a ~10–20% latency reduction on hardware like T4/A10/A100 when memory bandwidth is the bottleneck.
- Tools/workflows: PyTorch module wrapping DSC; integration with serving stacks (DeepSpeed, vLLM, TensorRT-LLM/FasterTransformer) by implementing efficient Gather/TopK kernels and preloading the shared basis bank into GPU memory.
- Assumptions/dependencies: Router stability requires the provided regularizers (aux load balancing, budget, z-loss, frame potential). Gains depend on memory bandwidth, gather kernel quality, and K/M hyperparameters. The paper demonstrates results at small scale (WikiText-103, 6-layer model); modest engineering validation is needed per deployment.
- Cost and energy reduction for multi-tenant model hosting
- Sector: Cloud/AI Infrastructure, Finance (cost), Energy/Sustainability
- Action: Consolidate multiple tenants/tasks on a single shared basis bank with DSC, routing per tenant/request, to reduce per-tenant adapter memory and inference-time memory traffic. Track energy and cost KPIs at the “active parameter per token” level.
- Tools/products: “DSC-Serving” profile mode that logs S (signal strength), K, gather bandwidth, and z-loss; dashboards in Prometheus/Grafana.
- Assumptions/dependencies: Requires capacity planning for shared M (number of basis atoms) and guardrails (minimum S via budget regularization) to avoid signal collapse across tenants.
- Parameter-efficient fine-tuning (PEFT) with high-rank adaptation at low storage
- Sector: Software, Enterprise NLP
- Action: Replace per-task LoRA matrices with a shared DSC basis bank and per-task routers. Achieve high effective rank via composition depth K without linear storage growth.
- Tools/workflows: Adapter library integration (e.g., Hugging Face PEFT) providing DSC as a “drop-in LoRA alternative,” export/import of basis banks and routers.
- Assumptions/dependencies: Requires careful setting of λ_frame to keep bases diverse. Ensure consistency in LayerNorm placement as per Algorithm 2 for stability.
- On-device and edge inference for privacy-sensitive NLP
- Sector: Healthcare, Finance, Edge/IoT, Mobile
- Action: Deploy smaller LLMs with DSC adapters on hospital servers, call centers, kiosks, or Jetson-class devices to reduce VRAM bandwidth requirements and latency while keeping quality near MoE-like adapters.
- Tools/products: Mobile/edge inference SDK with DSC-enabled FFN layers; quantization-aware training that keeps U/V vectors quantization-friendly.
- Assumptions/dependencies: Benefit hinges on efficient vector gather kernels on ARM/embedded GPUs and stable router training; quantization may require calibration to preserve Lipschitz bounds.
- Real-time assistants and copilots with steadier behavior under uncertainty
- Sector: Education, Productivity Apps, Customer Support
- Action: Use the magnitude-gated simplex to suppress low-confidence updates (ΔW → 0 when S is small), reducing instability and spiky behaviors in streaming or low-signal contexts (e.g., noisy ASR input).
- Tools/workflows: Inference-time diagnostic that monitors S and triggers fallbacks or response throttling when S < threshold; A/B testing with MoE vs DSC adapters in live assistants.
- Assumptions/dependencies: Objective requires maintaining the non-saturating regime for logits via z-loss; improper tuning can under-activate the residual branch.
- Safer training of sparse conditional computation layers
- Sector: Academia, Industrial Research
- Action: Adopt DSC’s spectral normalization and frame-potential regularization to prevent gradient explosions and representation collapse in sparse models.
- Tools/workflows: Training templates that include: unit-norm projection of basis vectors, λ_frame search, and router-specific LR multipliers (as in paper).
- Assumptions/dependencies: Stability relies on consistent enforcement of unit-norm constraints and diagonal scaling (γ or γ⃗) as described.
- Federated/personalized adaptation with minimal communication
- Sector: Healthcare, Finance, Enterprise
- Action: Share a global basis bank across clients; exchange only lightweight router parameters or sparse coefficients for personalization.
- Tools/products: Federated learning plugin where the server hosts U/V, clients learn/update routers, optionally with secure aggregation of frame metrics.
- Assumptions/dependencies: Requires careful privacy review; basis bank may encode global knowledge and must be handled as model IP; client-server versioning of basis banks.
- New academic benchmarks for conditional computation
- Sector: Academia
- Action: Use DSC to study the interplay between routing signal S, contraction, and generalization; replicate MoE comparisons at fixed active-parameter budgets.
- Tools/workflows: Open-source training recipes (as in the paper) for WikiText-103 and larger corpora; ablation suites for K, M, λ_frame, and z-loss.
- Assumptions/dependencies: Reproducibility depends on deterministic Top-K and seed control; differences in kernels can affect latency gains.
Long-Term Applications
The following items require further research, scaling experiments, systems co-design, or standardization before broad deployment.
- Foundation-model pretraining with DSC across layers
- Sector: Software, Cloud/AI Infrastructure
- Opportunity: Pretrain large LLMs using DSC in FFN/attention projections to achieve MoE-level quality with lower bandwidth pressure and improved stability.
- Potential products: “DSC-First” architectures in open or enterprise LLMs; mixed DSC/MoE hybrids that minimize all-to-all communication.
- Dependencies: Large-scale distributed training support (sharding of U/V banks, collective operations for Top-K/Gather), custom kernels for multi-node bandwidth efficiency, validation on trillion-token regimes.
- Hardware–algorithm co-design for vector-compositional adapters
- Sector: Semiconductors, Systems
- Opportunity: Create ASIC/FPGA/ISA extensions that accelerate Top-K routing, batched Gather, and rank-1 projection/expansion (einsum fusion), turning DSC’s memory pattern into coalesced, cache-friendly operations.
- Potential products: Triton/TensorRT fused kernels; on-die “basis bank” SRAM with prefetch; new instructions for magnitude-gated simplex ops.
- Dependencies: Collaboration between framework and hardware teams; standardized operator definitions.
- Certified robustness via spectral bounds
- Sector: Safety/Assurance, Regulated Industries
- Opportunity: Leverage DSC’s Lipschitz bounds (via unit-norm atoms and contraction) to develop robustness certificates or tighter worst-case guarantees for safety-critical NLP and multimodal systems.
- Potential products: Verification toolchains that compute/track per-layer spectral budgets; safety audits for regulated deployments.
- Dependencies: Extending local bounds to network-level guarantees; integration with formal verification tools.
- Multimodal DSC for vision, speech, and diffusion models
- Sector: Vision, Robotics, Media/Creative
- Opportunity: Apply DSC to attention/FFN layers in ViTs, ASR encoders, or diffusion UNets to get dynamic high-rank updates at lower bandwidth cost, enabling real-time or on-device multimodal inference.
- Potential products: “DSC-Adapters” for Stable Diffusion/ViT backbones; Jetson-class robotics stacks with DSC-enabled language-vision planning.
- Dependencies: Architecture-specific placement of ΔW; empirical validation on large-scale multimodal datasets; kernel support for 2D/temporal tensors.
- Compute-aware controllers that dial adaptation at inference time
- Sector: MLOps, Edge/IoT
- Opportunity: Treat S and K as tunable dials given energy/latency budgets; implement adaptive policies that trade accuracy for battery or cost in real time.
- Potential products: Schedulers that modulate K, γ⃗, or logit-range to stay within SLA/energy envelopes.
- Dependencies: Policy learning or heuristics for dynamic budgets; monitoring infrastructure; user-configurable QoS.
- Marketplace and reuse of shared basis banks
- Sector: Platform/Marketplace, Enterprise
- Opportunity: Distribute pre-trained basis banks for domains (legal, medical, code), with customers fine-tuning only routers for their data.
- Potential products: “Basis Packs” and router-tuning services; IP/licensing models around basis reuse.
- Dependencies: Standard formats/versioning; evaluation protocols to prevent leakage or bias; governance for domain-specific banks.
- Privacy-preserving, communication-efficient federated learning
- Sector: Healthcare, Finance, Public Sector
- Opportunity: Transmit only sparse coefficients or router deltas per round, while the basis bank evolves slowly or centrally; reduces bandwidth and attack surface.
- Potential products: DSC-enabled FL SDKs with secure aggregation of router statistics and frame metrics.
- Dependencies: Differential privacy for routing signals; policy compliance for model component sharing.
- Policy frameworks emphasizing bandwidth-efficient AI
- Sector: Policy/Regulation, Sustainability
- Opportunity: Introduce procurement and reporting standards that include “active parameters per token” and “inference bandwidth per token” alongside FLOPs, incentivizing bandwidth-frugal designs like DSC.
- Potential tools: Green-AI labeling schemes; public benchmarks for bandwidth-normalized performance.
- Dependencies: Multi-stakeholder agreement on metrics; standardized measurement harnesses.
- Continual and online learning with controlled plasticity
- Sector: Enterprise, Robotics
- Opportunity: Update routers online while keeping the shared basis stable, enabling rapid adaptation with bounded spectral change to mitigate catastrophic forgetting.
- Potential products: Live-adapting copilots and agents with per-context routing personalization.
- Dependencies: Theoretical/empirical work on stability–plasticity trade-offs under DSC regularization; drift detection.
- Personalized LLMs with compact user profiles
- Sector: Consumer Apps, Productivity
- Opportunity: Represent user personalization as a small set of router weights or sparse coefficient profiles over a shared basis, enabling fast, privacy-conscious personalization on device.
- Potential products: “Profile-at-the-edge” personalization kits for mobile assistants and writing tools.
- Dependencies: Secure storage of profiles; efficient on-device training (few-shot) and quantized U/V banks; UX for privacy controls.
Notes on feasibility across items:
- Many applications presume well-optimized Gather/TopK and einsum fusion; without kernel optimization, latency gains may be smaller.
- Stability depends on unit-norm projection, contraction (∑|ẑ| < 1), and router regularization (λ_aux, λ_budget, λ_frame, λ_z). Poor tuning can cause signal collapse or under-utilization.
- Results to date are on a modest setup; scaling to very large LLMs requires systems and distributed training advances to preserve the memory-traffic advantage.
Glossary
- Auxiliary Load Balancing: A regularization term that encourages uniform expert usage across a batch during routing. "Auxiliary Load Balancing ($\mathcal{L_{aux}$):} Ensures uniform probability mass distribution over the batch."
- Causal Language Modeling: A training objective where the model predicts the next token given previous tokens in sequence. "we employ a causal language modeling objective (Next Token Prediction) with a context window of ."
- Channel-Wise Spectral Relaxation: A stability scheme that bounds the update by scaling each output channel independently. "Case 2: Channel-Wise Spectral Relaxation (Algorithm \ref{alg:dsc_final).}"
- Cross-Channel Coherence: A measure of similarity between basis vectors across channels; minimizing it promotes diversity. "To promote basis diversity, we minimize the Cross-Channel Coherence."
- Dynamic Sparse Dictionary Learning: Learning a sparse combination of shared basis atoms to construct context-dependent weights. "not as a selection of experts, but as Dynamic Sparse Dictionary Learning applied to the weight space."
- Dynamic Subspace Composition (DSC): The proposed framework that composes sparse basis atoms to form dynamic weight updates. "We propose Dynamic Subspace Composition (DSC), a framework that approximates context-dependent weights via a state-dependent, sparse expansion of a shared basis bank."
- Equiangular Tight Frame (ETF): A frame where pairwise inner products between unit vectors are equal in magnitude, maximizing spread in a subspace. "This approximates an Equiangular Tight Frame (ETF) by minimizing the off-diagonal energy of the Gram matrices."
- einsum: A tensor operation that performs generalized Einstein summation for compact, efficient linear algebra expressions. " "
- Flash Attention: An optimized attention implementation that reduces memory and increases speed for transformer models. "Flash Attention (via scaled_dot_product_attention) where applicable to ensure competitive baselines."
- Frame Potential: A scalar quantifying the mutual coherence of a set of vectors; lower values indicate more uniform, diverse frames. "we introduce a regularization objective that minimizes the frame potential of the basis bank"
- Frame-Theoretic Regularization: Regularization based on frame theory to encourage diverse, well-spread basis atoms. "Frame-Theoretic regularization and spectral constraints provide rigorous worst-case bounds on the dynamic update."
- Gram Matrix: A matrix of inner products between vectors; its off-diagonal entries capture pairwise coherences. "This approximates an Equiangular Tight Frame (ETF) by minimizing the off-diagonal energy of the Gram matrices."
- Iso-Active Parameter protocol: An evaluation protocol that fixes active parameter counts to fairly compare sparse and dense models. "We adopt a strict Iso-Active Parameter protocol."
- LayerNorm: A normalization technique applied per layer to stabilize training and routing. "$\mathbf{\tilde{x} \gets \text{LayerNorm}(\mathbf{x})$ \Comment{Stability Normalization}"
- Lipschitz constant: A bound on how much a function can change in response to input changes; used to guarantee stability. "We provide analytical bounds on the Lipschitz constant of the DSC layer."
- Logit Range Constraint: A regularization term that keeps router logits in a non-saturating regime to preserve gradients. "Logit Range Constraint ($\mathcal{L_{z}$):}"
- LogSumExp: A numerically stable operation for computing the log of a sum of exponentials, often used in softmax-related losses. "$\mathcal{L}_{z} \gets (\LogSumExp(\mathbf{r}))^2$"
- Magnitude-Gated Simplex Interpolation: A mixing scheme that separates direction (simplex) from magnitude, allowing contraction toward zero for low confidence. "employing a Magnitude-Gated Simplex Interpolation to ensure continuity at the identity."
- Mixture-of-Experts (MoE): An architecture that routes inputs to a subset of specialized expert modules to increase capacity efficiently. "Mixture of Experts (MoE) models scale capacity but often suffer from representation collapse and gradient instability."
- Mixture-of-LoRAs (MoLoRA): A parameter-efficient technique routing tokens to low-rank adapters instead of full expert matrices. "Recent approaches in Parameter-Efficient Fine-Tuning (PEFT), such as Mixture-of-LoRAs (MoLoRA) \cite{zadouri2024pushing}, attempt to mitigate storage costs by routing tokens to distinct low-rank adapter matrices."
- Overcomplete regime: A setting where the number of basis vectors exceeds the dimensionality, making strict orthogonality impossible. "Strict orthogonality is impossible in the overcomplete regime ()."
- Probability simplex: The set of nonnegative vectors that sum to one; used to constrain directional mixing coefficients. "We mitigate this by separating the mixing coefficients into a directional component (on the probability simplex) and a radial magnitude."
- Representation collapse: A failure mode where the router overuses few experts, reducing diversity and capacity. "representation collapse, where the router converges to a trivial solution, utilizing only a fraction of available experts"
- Residual trajectory: A path of incremental updates added to a base model, modeling changes as residuals. "models the weight update as a residual trajectory within a star-shaped domain centered at the identity mapping."
- Signal Preservation Regularization: A constraint ensuring the router maintains sufficient activation strength to avoid collapsing to zero. "Signal Preservation Regularization ($\mathcal{L_{budget}$):} To prevent the router from defaulting to the zero-mapping solution (), we enforce a minimum activation budget."
- Softplus: A smooth, non-saturating activation function used to ensure non-vanishing gradients for routing scores. "To ensure non-vanishing gradients, we utilize $\zeta(x) = \Softplus(x)$."
- Spectral ball: The set of matrices whose operator (spectral) norm is bounded by a radius; ensures update boundedness. "In both cases, is strictly contained within a spectral ball defined by the scaling parameters."
- Spectral norm: The largest singular value of a matrix; bounds how much the matrix can stretch a vector. "the spectral norm of each basis atom is bounded: ."
- Spectral Stability: A property indicating bounded operator norms and Lipschitz behavior to prevent gradient explosions. "Spectral Stability: We provide analytical bounds on the Lipschitz constant of the DSC layer."
- Star-Shaped Domain: A set where any point can be scaled towards the center (origin) while staying in the set; used to model reachable updates. "a residual trajectory within a Star-Shaped Domain"
- Top-K routing: Selecting the K highest-scoring experts or basis atoms for sparse computation. "Standard Top-K routing induces discrete jumps in the optimization landscape."
- Unit-norm basis atoms: Basis vectors constrained to have norm at most one for stability and bounded updates. "a shared bank of unit-norm basis atoms"
- Welch bound: A lower bound on the frame potential that characterizes optimal incoherence among vectors. "By approximating the Welch bound, we maximize the spectral utilization of the subspace"
- Z-Loss (Router Z-Loss): A regularization penalty on the router’s log-partition to prevent logit drift and saturation. "Router Z-Loss ($\lambda_{z$):} (Prevents logit drift)"
Collections
Sign up for free to add this paper to one or more collections.