- The paper presents MERIT, a novel IR-level transformation that aligns and melds instruction sequences to eliminate branch mispredictions.
- It applies a sequence alignment approach and operand-level guarding to merge divergent control flows into straight-line code with minimal overhead.
- Empirical results show up to 32x speedups and a 48% reduction in branch mispredictions when combined with profile-guided optimization.
Eliminating Branches by Melding IR Instructions: An Expert Analysis of MERIT
Motivation and Contributions
Control-flow hazards, primarily caused by branch instructions, remain a significant challenge in modern superscalar and out-of-order pipelines, as even cutting-edge branch predictors often falter on irregular, data-dependent branches. Traditional compiler-level mitigation via if-conversion—replacing branches with predicated instructions—offers diminishing returns on x86, where hardware-level predication is absent and fully speculative execution is penalized due to unsafe memory instructions and instruction overhead.
"Eliminate Branches by Melding IR Instructions" introduces MERIT, a compiler transformation operating at the IR-level that targets these bottlenecks by aligning and melding structurally similar instructions across divergent paths. Rather than speculatively computing both paths and selecting between overall outcomes, MERIT aligns instruction sequences, merges compatible operations, and inserts extraneous, semantically safe instructions where necessary. By selecting operands based on runtime conditions instead of entire result values, MERIT not only broadens the conversion domain (handling branches with complex memory semantics) but also reduces instruction overhead compared to classical if-conversion. The transformation is implemented as an LLVM pass and can be combined with profile-guided optimization (PGO) for selective deployment.
MERIT leverages a sequence alignment approach—adapted from the Smith-Waterman algorithm for molecular biology—to align IR-level instruction sequences of two divergent branches. The transformation consists of:
- Instruction Sequence Alignment: Structural matching of operations, regardless of operand differences, identifying compatible operations and aligning them in the IR.
- Extraneous Instruction Insertion: Filling alignment gaps with safe, side-effect-free instructions, such as guarded memory accesses to compiler-allocated dummy locations, preserving both correctness and memory safety.
- Operand-Level Guarding: Instead of introducing new select nodes after result computation, MERIT selects operands and then executes the operation once, drastically minimizing superfluous computation and runtime select chains.
A key technical nuance is MERIT's semantic safeguarding: alignment and extraneous code insertion are subject to program analysis to ensure that inserted instructions do not violate memory safety or observe side effects. For instance, conditional stores in eliminated branches are redirected to isolated safe memory, and arithmetic extraneous instructions are supplied with neutral or semantically correct operands.
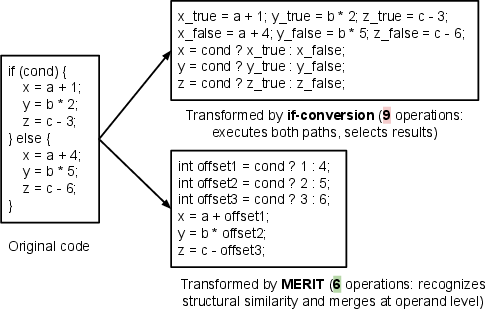
Figure 1: MERIT can reduce dynamic operations by 33% relative to if-conversion by recognizing structural similarity and performing operand-level merging.
This structural melding ensures that resultant code is straight-line, branchless, and semantically equivalent, unlocking additional backend optimizations such as scheduling, vectorization, and register allocation due to the absence of explicit control dependencies.
Implementation Details
MERIT is realized as an LLVM-14 IR-level pass, inserted after early canonicalization and simplification. By running above the backend and before aggressive code motion or lowering, MERIT operates on high-level IR, increasing generality and cross-architecture applicability.
Profile-guided optimization is a critical facility: transformation sites can be filtered by function, file, or source-line granularity. This is essential because MERIT's benefit-to-cost ratio is highly workload-dependent; branches that are already highly predictable or not on the critical path can experience slowdowns from added select and extraneous instructions. The pass thus exposes CLI options and data-driven inclusion/exclusion lists to enable optimal targeting.
Quantitative Evaluation
Microbenchmarks
MERIT is evaluated on a broad spectrum of 102 benchmarks, including SPEC2017, microbenchmarks, PyPerformance, and TPC-H.
- On branch-heavy microbenchmarks, MERIT achieves a geometric mean performance of 1.51x over hardware speculation, dwarfing the 1.06x for early if-conversion. In some cases (e.g., highly unpredictable branches in string uppercasing), peak speedups reach 32x.
- IPC is increased by 24.4% on average relative to hardware-branching baselines (Figure 2), with a 2.1% improvement observed for if-conversion.
- Dynamic instruction overhead is incurred (on average 17.8% for microbenchmarks), but is amply offset by the reduction in wrong-path execution.
- In microbenchmarks, MERIT achieves 48% branch misprediction reduction vs. 7.2% for if-conversion, a substantial improvement in eliminating control-flow stalls.
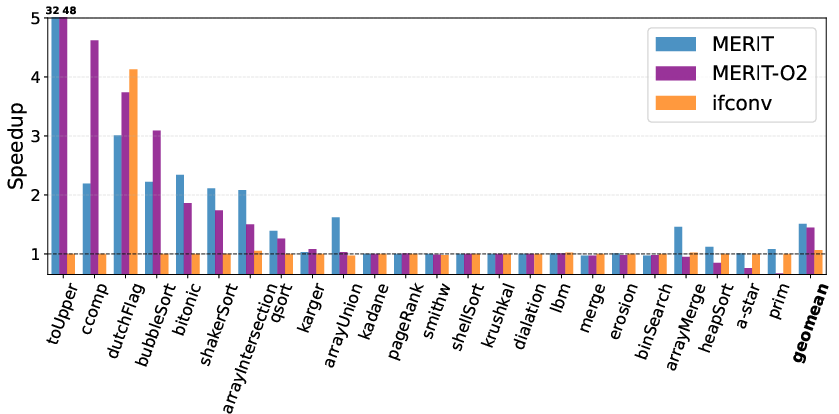
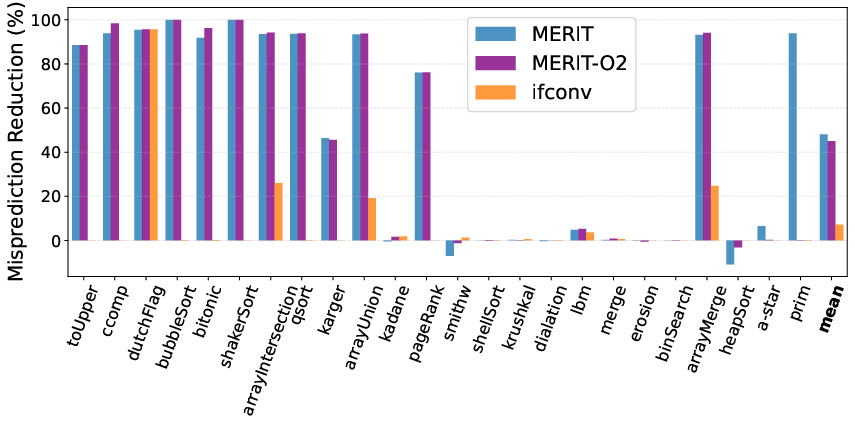
Figure 3: MERIT achieves a performance geomean of 1.51, while if-conversion’s geomean is 1.06.
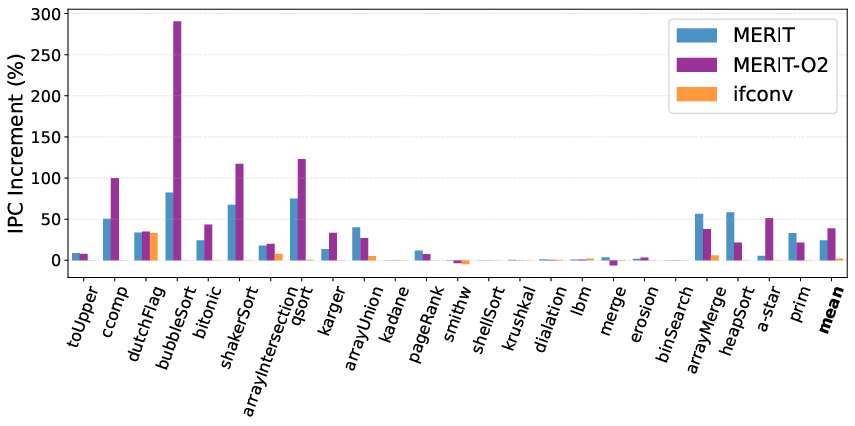
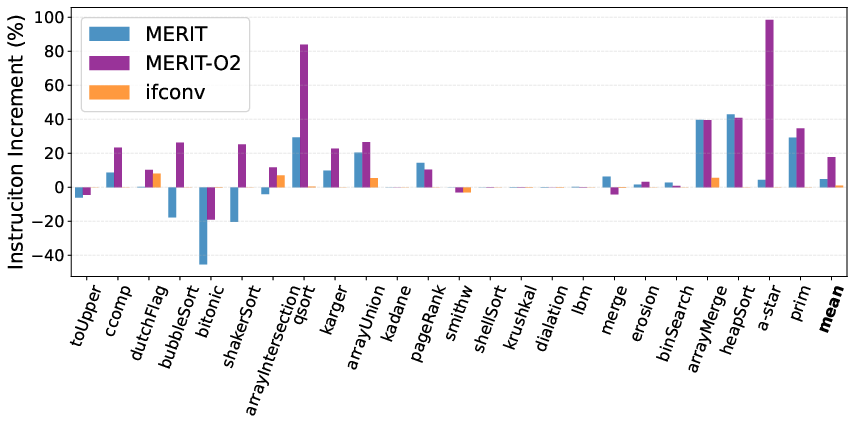
Figure 2: MERIT delivers a 24.4% average IPC improvement, whereas if-conversion realizes only 2.1%.
- On SPEC2017, indiscriminate MERIT incurs performance loss (geomean 0.97), but with PGO-based exclusion of unprofitable sites (MERIT-PGO), minimal overhead (1.01 geomean) or small speedups are consistently achieved (Figure 4).
- Similarly, TPC-H queries on SQLite show that naive MERIT can hurt (geomean 0.84), but with selective PGO, all slowdowns are eliminated, and positive geomean improvement (1.01) is realized (Figure 5).
- On CPython, the effect is more nuanced: selective PGO is less effective cross-benchmark due to coarse granularity, but task-specific interpreters can exploit MERIT via PGO for their own critical paths (Figure 6).
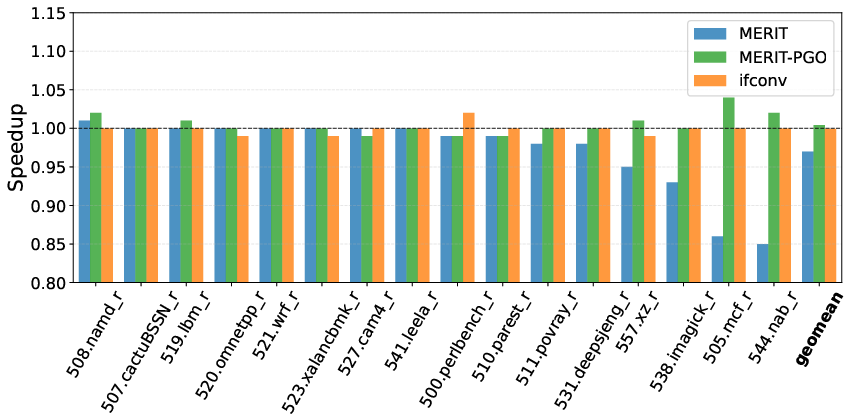
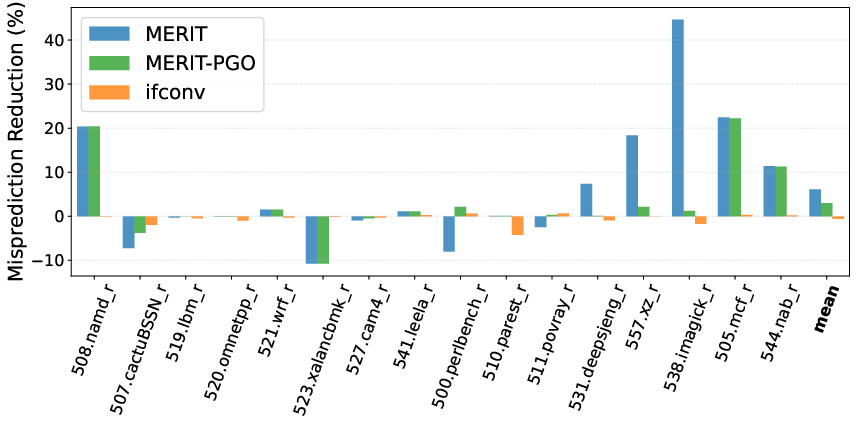
Figure 4: On SPEC2017, MERIT achieves a geomean of 0.97, MERIT-PGO 1.01, and if-conversion 1.0.
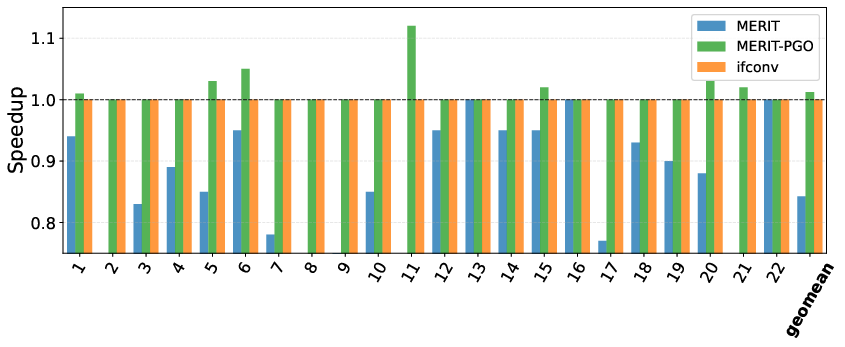
Figure 5: On TPC-H (SQLite), MERIT scores 0.84 geomean, MERIT-PGO 1.01, and if-conversion 1.0.
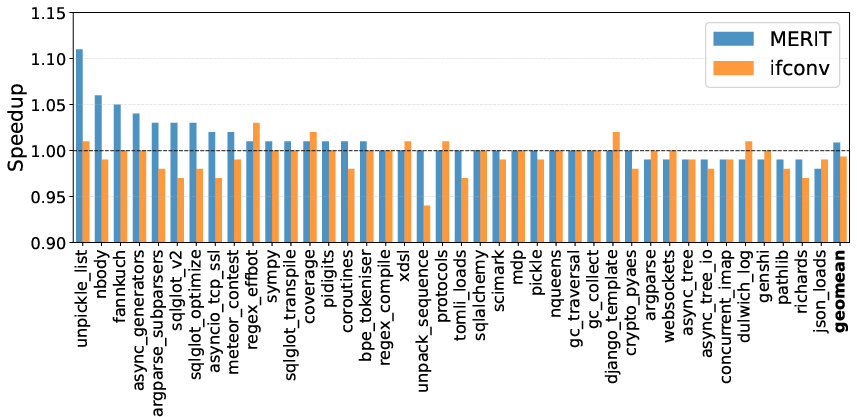
Figure 6: Across PyPerformance, MERIT achieves a 1.01 geomean compared to if-conversion’s 0.99.
Contradictory and Notable Claims
- Blind application of MERIT can degrade performance and IPC due to increased instruction count when branches are not predictability bottlenecks—highlighting MERIT’s critical dependence on intelligent site selection and cost modeling (Figure 7).
- IPC does not always correlate with performance in complex workloads, as execution of extraneous instructions can reduce total dynamic instruction count and wall-clock time, but lead to apparent IPC decline.
- If-conversion is highly conservative for memory-unsafe branches: it shows trivial or no speedup in many benchmarks, confirming its limited practical utility on CISC ISAs without hardware predication.
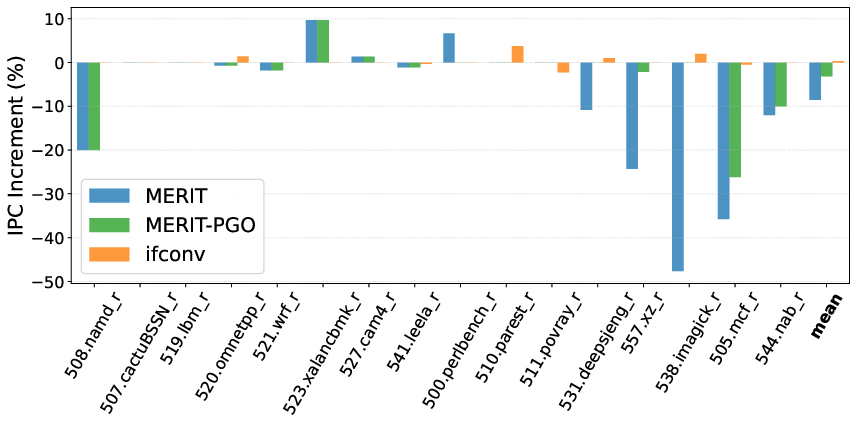
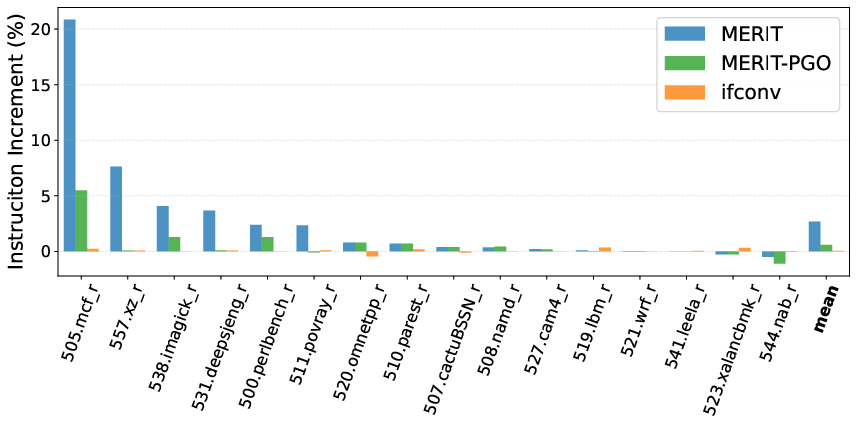
Figure 7: Naive MERIT can lead to 8.5% IPC degradation, mitigated to 3.2% with PGO, while if-conversion slightly improves IPC by 0.3%.
Practical and Theoretical Implications
MERIT generalizes control-flow to data-flow transformation on mainstream ISAs, enabling aggressive branch elimination without hardware extensions. Unlike prior GPU-centric methods (e.g., DARM), it leverages alignment and semantic analysis at the IR level, extending applicability to complex patterns, including those with conditional memory operations.
This transformation can be deployed as a backend-independent optimization, paving the way for more predictable and regular code generation, improved vectorization and instruction scheduling, and possibly new program analysis and security techniques sensitive to explicit data flow.
However, effectiveness is throttled by the absence of a robust cost model and downstream pass coordination. Aggressive backend optimizers can inadvertently reverse or impair MERIT’s transformations. The authors propose LLM-based cost models or incorporating offline branch-misprediction profiling as promising next steps to further unlock MERIT’s performance envelope.
Future Directions in AI-Assisted Compilation
A notable speculative avenue is the coupling of MERIT IR transformations with LLM-driven heuristics, using execution-aware code models (e.g., [TRACED, (2402.00000)]) to predict instruction interactions, misprediction frequency, and cost-benefit outcomes at compilation time. Such hybrid systems may automate branch elimination decisions beyond human-tuned heuristics or limited profiling data.
Moreover, integrating MERIT with profile-driven feedback that monitors branch behavior in production would allow continuous refinement, potentially turning branch elimination into a zero-cost, highly nuanced backend optimization.
Conclusion
MERIT rethinks branch elimination by operating above the machine level, leveraging instruction sequence alignment, semantic analysis, and operand-level merging to transform control-flow-heavy regions into straight-line code—even on architectures lacking native predication support. Empirical results indicate that, when coupled with profile-guided filtering, MERIT can eliminate mispredictions and substantially accelerate workloads that are otherwise bottlenecked by unpredictable control transfers.
The approach highlights the growing relevance of statically informed data-flow transformation in the compiler stack, but also exposes the limits of existing cost-modeling and optimizer integration, suggesting a broader research challenge at the intersection of compiler design, AI, and high-performance architecture. Further refinement and AI-assisted heuristics are poised to drive the next generation of branch elimination and instruction-level transformation techniques.
Reference:
"Eliminate Branches by Melding IR Instructions" (2512.22390)

