- The paper introduces LibContinual, a library that standardizes evaluation of continual learning algorithms under realistic data and memory constraints.
- It consolidates 19 methods across diverse strategies, revealing significant performance drops in online, resource-aware, and category-randomized settings.
- Empirical results emphasize that memory-efficient PTM-based approaches and expert routing effectively mitigate catastrophic forgetting in non-stationary environments.
LibContinual: A Unified Framework for Realistic Continual Learning
Motivation and Key Contributions
Continual Learning (CL) aims to enable models to acquire new knowledge sequentially without catastrophic forgetting of previous knowledge. However, the state of CL research has become fragmented, characterized by inconsistent implementations, variable evaluation protocols, and typically idealized assumptions regarding data access, memory, and the semantic structure of tasks. The paper "LibContinual: A Comprehensive Library towards Realistic Continual Learning" (2512.22029) addresses these challenges by introducing LibContinual, a modular and extensible library designed to provide a unified, reproducible evaluation platform for CL algorithms.
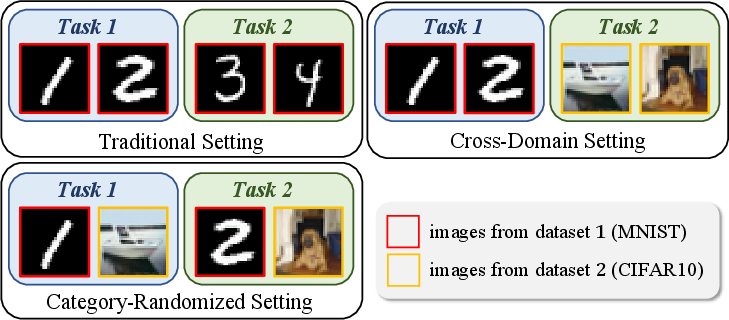
LibContinual not only standardizes the implementation and evaluation of 19 prominent CL methods across five major family types but also systematically investigates three key assumptions that pervade prevailing CL evaluations: (1) multi-epoch, offline data availability; (2) unrestricted, inconsistently measured memory resources; and (3) the artificial semantic coherence of task partitions. The library’s architecture, benchmarks, and evaluation protocols promote rigorous comparisons and enable the identification of real-world applicability gaps between CL algorithms.
Library Architecture and Supported Paradigms
LibContinual is built on a high-cohesion, low-coupling modular architecture that promotes extensibility and experiment transparency. The workflow separates the major lifecycle elements into Trainer, Model, Buffer, and DataModule modules, all governed by a configuration interface. This explicit decoupling allows for flexible integration of various backbones (including both classic CNNs and modern Vision-LLMs), diverse classifier heads, memory buffers, and task/data partitioning strategies.
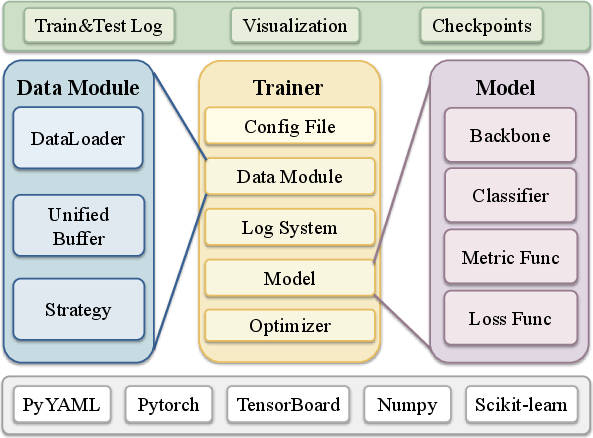
Figure 1: The LibContinual architecture decouples core components, enabling clear extension points for backbone, buffer, and algorithm modules.
The framework natively supports multiple paradigms:
A Unified Taxonomy and Algorithmic Spectrum
By consolidating 19 representative algorithms, LibContinual spans the principal strategies for combating catastrophic forgetting:
- Regularization-based (EWC, LwF): Parameter or function-space constraints to preserve prior knowledge.
- Replay-based (iCaRL, BiC, LUCIR, OCM, ERACE): Storage and rehearsal of raw inputs or derived features.
- Optimization-based (GPM, TRGP): Constrained parameter updates, e.g., via gradient subspace projection.
- Representation-based (L2P, DualPrompt, CodaPrompt, RanPAC, RAPF): Adaptation on top of pre-trained encoders, often using prompts or feature projections.
- Architecture-based (API, InfLoRA, MoE-Adapter4CL, SD-LoRA): Structural modularity, parameter-efficient fine-tuning (PEFT), mixture-of-experts, and adapters.
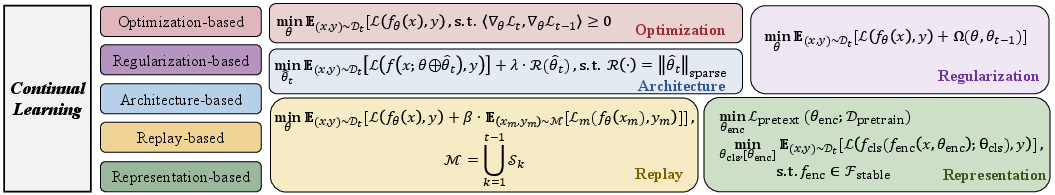
Figure 3: Algorithmic taxonomy covering regularization, replay, optimization, representation, and architecture-based CL approaches.
The framework further introduces a storage-centric taxonomy—classifying algorithms by their memory footprint into image-, feature-, model-, parameter-, or prompt-based storage.
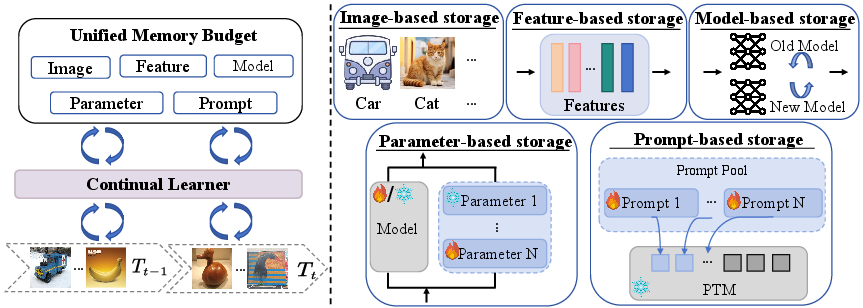
Figure 4: Categorization of memory/storage mechanisms in continual learning strategies.
Revisiting CL Assumptions: Protocol and Empirical Findings
1. Data Access Paradigm: Online versus Offline Learning
LibContinual exposes the performance collapse of training-from-scratch CL methods under a single-pass (online) learning regime. Classic replay or regularization schemes fail to maintain prior task knowledge, exhibiting near-chance accuracy, whereas PTM-based methods (e.g., prompt-based approaches) with frozen, high-quality feature backbones sustain high accuracy even without rehearsal.
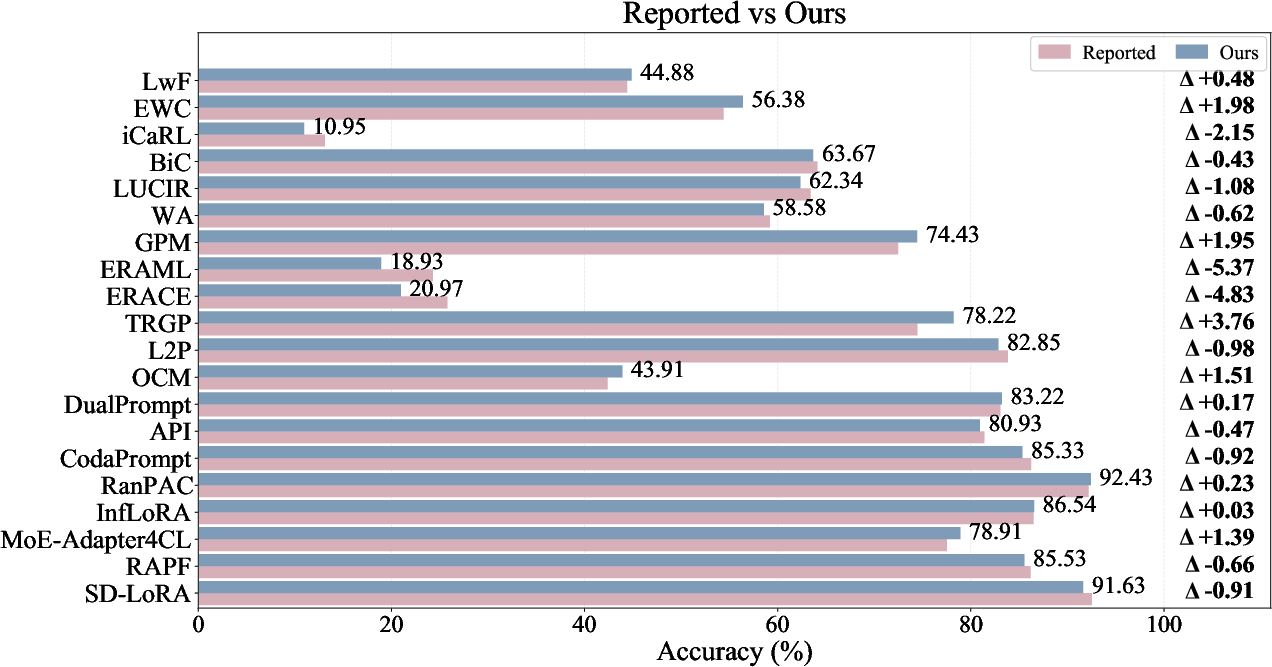
Figure 5: Reproducibility validation—original versus LibContinual-reproduced accuracies show close agreement and support for the unified implementation.
2. Consistent, Resource-aware Memory Analysis
The library quantifies all auxiliary storage beyond the backbone—across replay buffers, feature caches, model snapshots, parameter expansions, and prompt tokens—in a unified metric (MB). Strikingly, PTM-based methods can achieve strong performance with <20MB of memory, while traditional approaches depend on large-scale replay buffers and exhibit diminishing accuracy returns with increased storage.
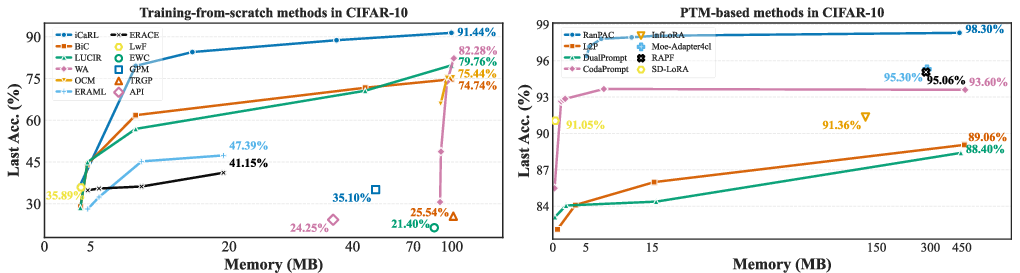
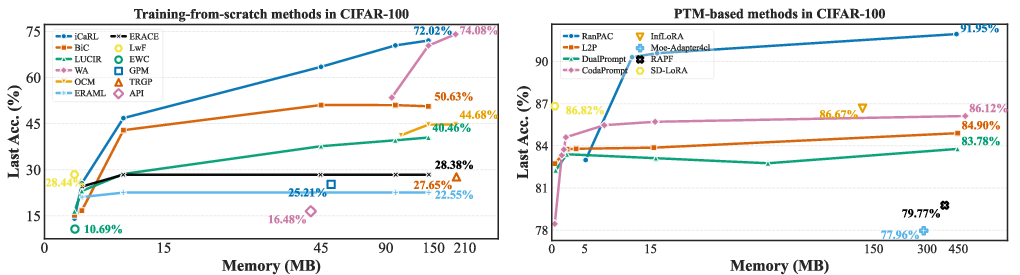
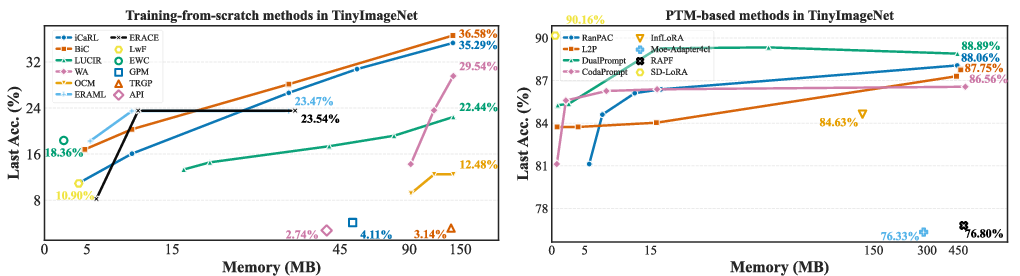
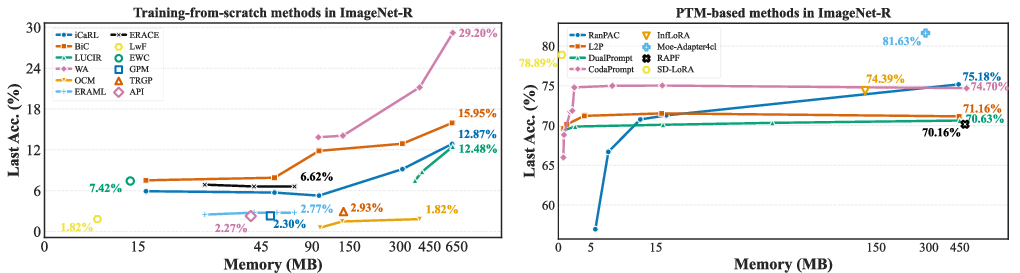
Figure 6: Last accuracy versus memory usage—PTM-based methods (e.g., CodaPrompt, RanPAC) dominate in accuracy-efficiency tradeoff across all tested datasets.
3. Robustness to Semantic Task Structure
Category-randomized experiments, which forcibly mix classes from different domains within each task, reveal that many high-performing methods on standard benchmarks suffer dramatic degradation without intra-task homogeneity. PTM/prompt-based approaches (RanPAC, DualPrompt, CodaPrompt) exhibit performance drops up to 29 percentage points when stripped of semantic regularity, indicating reliance on task-level context for effective adaptation. In contrast, replay and certain architecture-based methods (MoE-Adapter4CL) remain robust, the latter even improving due to its capacity for implicit sub-task specialization.
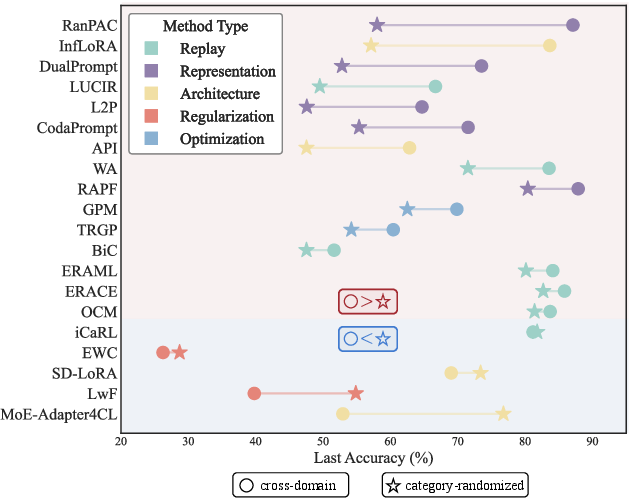
Figure 7: Visualization of performance shifts from cross-domain to category-randomized settings, highlighting method-specific robustness or sensitivity to semantic coherence.
Key Numerical Results
- Online CL Performance: Training-from-scratch methods perform at or near random guess levels (e.g., EWC at 10% on CIFAR-10), while PTM-based methods exceed 80% accuracy.
- Memory Efficiency: RanPAC and CodaPrompt yield >90% accuracy with <20 MB memory; L2P, despite 440 MB prompts, underperforms them.
- Category-randomized Impact: Performance drops for prompt-based (−17% to −29%) and representation-based methods; replay approaches exhibit minimal impact or minor improvements.
- MoE-Adapter4CL: Uniquely demonstrates a performance increase (+24%) in category-randomized settings due to its expert routing mechanism.
Implications and Future Directions
This research establishes that most mainstream CL methods are evaluated under conditions that do not reflect real-world continual learning: repeated task exposure, unconstrained memory, and artificially grouped tasks inflate apparent progress. By providing a reproducible, modular platform and rigorous protocols, LibContinual baseline experiments force new scrutiny onto claims of algorithmic efficiency, scalability, and robustness.
Practically, the results indicate that resource-aware designs—such as memory-efficient PTM adaptation and expert routing—are essential for scalable CL. Theoretically, they emphasize the necessity for methods resilient to data stream disorder and minimal rehearsal, as found in genuine non-stationary environments.
LibContinual is thus positioned as a catalyst for:
- Evaluating true online learning ability, beyond synthetic multi-epoch benchmarks.
- Resource-constrained inference and lifelong model deployment via unified, transparent memory accounting.
- Robust, context-independent continual learning research, as future CL systems must operate without predefined semantic regularities.
Emerging research should target intelligent memory utilization, automatic task compositionality, cross-modal continual learning, and robust adaptation without dependence on privileged information or semantic shortcuts.
Conclusion
LibContinual constitutes a rigorous, extensible benchmark that spotlights the limitations of conventional CL evaluation. Its unified platform reveals that practical continual learning—especially under realistic constraints of data, memory, and semantics—remains unsolved for most algorithmic families except for those that efficaciously leverage pre-trained knowledge and adapt memory efficiently. The library and its insights will shape future development of efficient, robust, and genuinely scalable lifelong learning strategies.